基于形態流的石油鉆井水流異常檢測
2021-07-02 08:55:16李衍志
計算機應用 2021年6期
李衍志,范 勇,高 琳
(西南科技大學計算機科學與技術學院,四川綿陽 621010)
(?通信作者電子郵箱17828100385@163.com)
0 引言
石油是生產汽油、煤油、柴油等化學物質的重要原料,同時其副產物也是有著廣泛的用途[1]。發掘石油原料的同時也伴隨著大量的具有污染性的氣體來到地面。為了保護環境、保障安全生產,必須對超過排放標準的氣體進行無害化處理。這些污染性氣體中威脅性最大的就是硫化氫(H2S),其含量高、無色無味且含有劇毒、不溶于水,不能溶解在鉆進排水管道的水流中[2]。由于這些污染氣體大多不溶于水或者只有部分能溶于水,且井內氣體含量越高內部氣壓就越高,井內氣壓變化,排水管道口的水流形態就會變化。污染氣體含量越高水流形態變化越明顯。異常樣本從當前幀和上一幀的對比可以看到,圖像中水流的量明顯變大,水流的形態變化也很明顯;正常的樣本從前后兩幀的對比可以看出,雖然形態和水流量上都有一定的變化,但是變化不大。從異常樣本和正常樣本的對比來看,正常樣本和異常樣本形態上都有變化,但是異常樣本的形態變化更為劇烈。現在生產過程中都是人工在后臺監測水流的變化情況,但是人工監測存在視覺疲勞和一個人難以同時監測多個點的問題,因此很難避免造成監測不到位和人力資源浪費的問題。基于人工智能技術,使用計算機代替人工監測是其解決方法。目前在機器視覺領域關于監測石油鉆井水流形態變化是否異常的研究較少,該項研究主要存在以下兩大難點:1)水流數據表示方面,水流的形態是不固定的,普通的特征提取方式難以同時表述水流形態在空間和時間上的變化過程;2)水流異常的表現形式也不固定,無法一一列舉所有的情況,這也就給異常檢測和判別帶來了困難。
針對水流數據表示方面的問題,在以往的其他視頻異常數據檢測任務中常用的是軌跡特征和光流特征。其中,軌跡特征計算復雜且耗費計算資源,因此光流是眾多研究者常用的方法,文獻[3-4]等都對光流進行了研究。一方面,雖然現有計算資源已經比較強大,但是在實際應用中,有些計算需要在前端完成,前端配置一般不高,所以從算法上進行優化是其解決方法。另一方面,光流特征雖然在一定情況下具有優越性,但是其要求所描述的物體運動緩慢、一定時間內形態基本不變,所以光流不適用于水流異常數據檢測。其他的諸如紋理特征、顏色特征、尺度不變特征變換(Scale Invariant Feature Transform,SIFT)特征等都只能對單幅圖像提取特征,不能描述水流在時間軸上的變化。所以需要一種針對水流的新特征提取方法,該方法需要同時從二維空間和時間兩個維度描述水流的變化過程。
在水流的異常數據檢測判別方面,以往關于視頻的異常事件檢測的方法可以分為全監督的方法和非全監督的方法兩個大類。非全監督的方法可以分為基于重建的方法、基于預測的方法和基于生成對抗網絡的方法。全監督的方法在使用時需要預先列舉所有的異常情況[5-7],然而水流的異常是偶然發生的,具有不確定性,不能完全列舉所有的異常情況,所以全監督的方法不具有實際應用價值。非全監督的方法中:基于重建的方法,重建過程計算復雜,時間復雜度高[8-9],不能滿足水流數據實時檢測的需求;基于預測的方法根據預測值與真實值之間的差異來判別異常[10],但是水流形態幾乎每一幀都在變化,因此要想學習到一個預測模型很困難;基于生成對抗網絡的方法[11-13],首先通過對抗訓練學習到正常水流數據的某種表示模式,測試時再根據當前水流數據幀是否符合這種表示模式來判是否異常。目前為止在異常視頻數據檢測公共數據集中性能表現最好的是文獻[11]的方法,但是該方法生成器采用的是全卷積網絡(Fully Convolutional Network,FCN)結構,沒有充分利用到融合層的數據信息。
綜上所述,針對目前將人工智能技術應用到石油鉆井水流異常檢測上的研究較少,以及視頻異常事件檢測相關研究存在缺陷不能直接應用在石油管道水流異常監測上的問題,本文提出了一種基于形態流的石油鉆井水流異常檢測算法。在水流數據表示和特征提取方面,該算法為了克服光流存在的缺陷結合實際水流形態的變化提出了形態流;在異常檢測算法層面,為了提高異常檢測精度對現有的GANomaly 算法[1]進行了改進。實驗結果表明,本文算法在水流異常檢測任務中,檢測精度達到95%,在時間效率上也能滿足實際的需求。改進后的異常檢測網絡在公共數據集上也取得了優于同類算法的精度,當異常類別為1 時檢測精度相較最好的GANomaly算法提升了19個百分點。
1 水流異常檢測流程
水流異常檢測流程如圖1 所示,需要注意的是在該應用中,水流分割僅僅是作為異常檢測方法中特征提取的預處理步驟,是整體方法的一部分;同時,對圖像進行分割然后再進一步提取形態流特征是訓練階段和測試階段共有的部分。如圖1 所示,在訓練階段需要通過學習得到兩個映射:一個是形態流特征重建映射x→f1()x;另一個是重建結果和對應的形態流特征在進行L2 距離最小化學習時得到的最小化映射f3(x)。兩個模型預訓練好之后,將正常數據依次輸入兩個模型,然后根據最后輸出的L2距離建立高斯模型。高斯模型用于表示正常數據的L2距離的最小化結果分布,高斯模型的閾值則結合異常樣本和正常樣本共同確定。在測試階段,提取完形態流特征之后,首先將形態流特征輸入重建模型得到重建結果;然后,將重建結果和對應的形態流特征同時輸入最小化模型得到輸出的L2 距離值;最后將該距離值輸入高斯模型,當高斯模型輸出的概率值小于高斯模型的閾值時判定該數據幀異常。
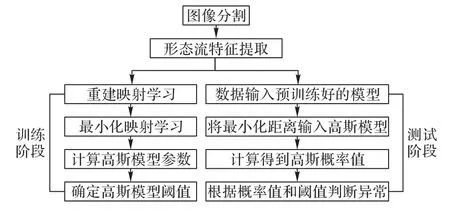
圖1 水流異常檢測流程Fig.1 Flow chart of abnormal water flow detection
2 形態流特征提取
2.1 水流分割
特征提取是水流異常檢測任務中的重要一環,一種好的特征表示方法能決定最終檢測結果的好壞。形態流特征提取的第1 步就是對圖像中感興趣的區域進行提取,即分割出圖像中的水流。作分割的目的是為了克服如圖2 所示水流數據樣本中背景和噪聲的干擾,只保留對水流異常檢測有用的信息。

圖2 水流數據樣本Fig.2 Water flow data samples
水流的分割不同于普通物體例如熊、桌子、板凳這類有固定形態物體的分割,因為水流是沒有固定形態的;同時它也不同于火焰的分割,火焰的顏色基本都是暗紅色或者黃中透紅,而水流受到水中介質的影響顏色是不固定的。因此,水流的分割不能簡單地通過HSV(Hue,Saturation,Value)、RGB(Red,Green,Blue)等顏色空間來實現,也不能根據物體形態的特有屬性來實現。深度學習的出現解決了場景和模式兼容的問題。需要同時考慮到模型不能太過簡單影響分割效果,也不能太過復雜有了效果沒有時間效率,例如deeplab[14]、AdaptSegNet(Adaption of Semantic Segmentation)[15]、區分特征網絡(Discriminative Feature Network,DFN)[16]等算法時間效率就不高。綜合各種因素最后選擇了U-Net 神經網絡[17]來作水流分割。
U-Net 原有研究使用交叉熵作為損失函數不能真實地表述生成數據與標簽圖像之間的對應重合關系。因此,本文中使用了圖像分割領域更為常用的Dice 作為損失函數,Dice coefficient 可以評估兩個樣本的相似性,用于衡量兩個樣本的重疊程度,比交叉熵作為圖像分割的損失函數更合適。訓練過程中Dice損失函數定義如下:

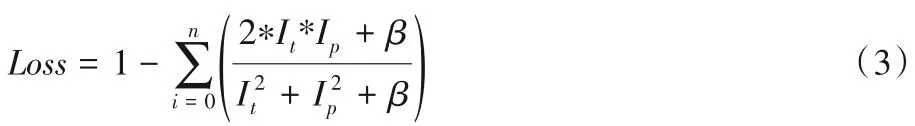
式中:Ip表示訓練過程中神經網絡的輸出圖像;It表示對應的標簽;Loss表示損失;i,j表示像素點的坐標位置。式(3)中,i=0,n表示參與計算的圖像數量,β表示一個非0 常數。因為在實際情況中偶然會發生突然噴射后短暫的一兩個數據幀中無水流,即可能存在Ip和It同時為零的情況,所以為了保證訓練的繼續進行,必須加上一個非零常量β,保證分母部分不為零。通過多次實驗可知,β取值為1×10-5時可以取得良好的分割效果。從式(3)也可以看出,當標簽和實際的預測值越接近時損失越小。樣本的水流分割結果如圖3所示。

圖3 不同樣本的水流分割結果Fig.3 Water flow segmentation results of different samples
2.2 形態流特征提取
目前,常用于視頻異常檢測的人工設計特征有紋理特征、顏色特征、光流特征、軌跡特征等。因為光流可以從時間域和空間域兩個層面來準確刻畫視頻圖像隨時間的變化,相較于顏色特征和紋理特征等包含了更豐富的信息,所以現在的研究中普遍都采用了光流作為輸入。本文也首先考慮了使用光流作為輸入的特征,相鄰兩個數據幀原圖和光流特征圖像分別如圖4、圖5所示。

圖4 兩個相鄰數據幀Fig.4 Two adjacent data frames

圖5 光流計算結果Fig.5 Optical flow calculation result
如圖5 所示,光流特征的計算結果很混亂,并不能看出水流在時間軸上的變化,也不能看出水流的空間形態。這是由光流特征本身的計算條件所限制的,即光流計算時假設了計算目標運動時緩慢的時間是短暫的,物體形變不大[3-4,18],但是水流形態時時刻刻都在發生變化,且變化程度相對較大。因此需要新的特征表示方法(形態流)來描述水流形態的變化。因為本文是通過水流形態在時間軸上的變化來表示視頻中水流的變化,所以取名為形態流。
形態流特征的提取,也借鑒了光流描述視頻數據變化的思路。形態流特征和光流一樣都是從時間域和空間域兩個層面來描述視頻數據變化。不同之處在于,形態流特征考慮了人工進行異常數據判斷過程,從水流形態的變化上來刻畫數據。形態流特征提取的依據在于工業生產中專業人員根據監控視頻中水流形態的變化過程來判別水流是否異常,而水流的形態體現在圖像中就是目標區域(水流區域)像素點的位置分布。一個視頻序列的形態流特征提取流程如下:設原有的視頻序列為I0,I1,…,In,則經過分割后的視頻圖像序列為-I0,其中I0表示第一幀,In表示最后一幀。雖然水流的形態是不固定的,在短時間內也會發生形態上的變化,但是在短時間內的同一場景下正常的水流數據形態變化并不劇烈。也就是說,在正常數據中相鄰的兩個數據幀,形態變化較大,但是在分割后的數據上相鄰兩幀之間對應位置上還是有很大一部分像素點是重合的。所以如果是正常的水流數據,經過分割后相鄰兩個數據幀相異部分較少,而在包含異常數據幀的數據中相鄰兩幀之間的相異部分則很大,這也為從時間軸上描述水流形態的變化提供了基礎。
數據除了在時間維度上有形態變化的信息之外,其自身也包含了豐富的形態信息。為了充分利用時域和空間域信息,首先對水流數據進行分割去除背景得到感興趣的水流形態區域;然后,從第一幀開始獲取兩相鄰數據幀,對兩幀圖像按位求異或就可以得到兩個圖像形態在時域上的變化信息。在空間維度上,本文直接使用分割后得到的水流數據來描述水流形態,因此在求取異或之后將當前的數據幀拼接在右側。直接拼接在右側不采用梯形、三角形等方式拼接是為了保證圖像中水流形態不產生變化。按照上述方法,逐幀計算,直到視頻數據的最后一幀。形態流特征如圖6所示。
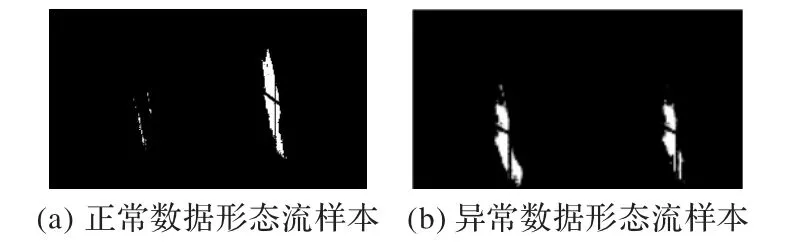
圖6 形態流樣本Fig.6 Samples of shape flow
如圖6 所示,單個樣本中,從左往右看,形態流特征圖左半部分代表數據在時間軸上的變化,右半部分代表當前水流形態。由上述描述可知,左半部分由相鄰兩個數據幀之間求取異或得到,同時正常數據相鄰兩幀之間存在許多重合的像素點,因此正常數據左半部分只有少量相異的像素點(圖中白色部分),異常數據左半部分相異的像素點相對較多。
3 水流異常檢測神經網絡模型
本文中水流異常檢測的神經網包括三個部分的神經網絡:生成器、判別器和分辨網絡。在訓練階段需要同時用到上述的三個網絡,而在實際使用和預測階段則只需要用到生成器和分辨網絡兩個部分。在實驗中,通過生成對抗網絡(Generative Adversarial Network,GAN)的方法進行訓練,生成器部分為重建網絡,負責學習正常數據形態流的重建表示f1(x);判別器負責判別生成數據的真偽;分辨網絡則是學習生成器生成數據和原始輸入數據之間的L2 距離最小化表示f3(x)。其潛在的原理是f1(x)和f3(x)都是通過對正常數據的學習得到的,因此它只適用于正常數據。在測試時如果遇到異常數據,生成器部分的重建網絡得到重建數據就會跟原來的數據產生較大的誤差,分辨網絡就會輸出一個較大的值。測試時如果遇到的是正常數據,那么數據的重建質量就會很高,分辨網絡也會相應輸出一個很小的值。因此判別數據是否異常就可以直接根據分辨網絡輸出的數據大小來判定。判別器學習到的映射f2(x),則是為了保證生成器的重建質量,因為生成器重建的效果越好,異常的判別就會越準確。整體的水流異常檢測神經網絡結構如圖7 所示,歸一化層(Batch Normalization,BN)是殘差結構的一部分。
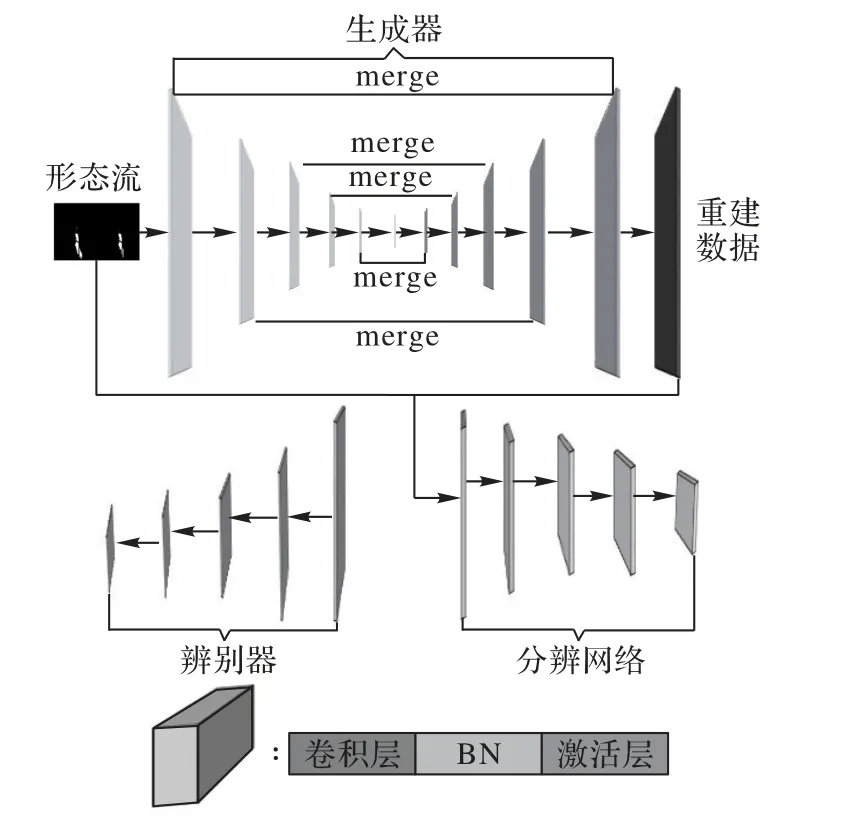
圖7 水流異常檢測神經網絡結構Fig.7 Structure of neural network for water flow anomaly detection
3.1 生成器
生成器用于重建輸入的形態流特征,它的重建數據與前文所述的基于重建的方法[8]有本質上的區別。基于重建的方法,是對整個視頻數據進行學習,從而構建重建字典,字典中的內容是學習到的特征。本文的重建網絡則是通過對形態流的特征進行學習得到重建映射f1(x)。
GANomaly 神經網絡的生成器采用的是全卷積神經網絡[19]的結構。FCN的神經網絡只有使用下采樣的編碼模塊和使用上采樣的解碼模塊兩種模塊,而沒有如圖8 所示的融合層(merge),因此不能學習到圖像更深層次的潛在特征。使用普通的卷積網絡,存在梯度消失和彌散的問題,因此網絡結構層數不能太深,這一點也限制了FCN 對數據特征的提取能力。本文將神經網絡改為殘差網絡的模式,可以加深網絡的層數,進一步加強生成器對數據潛在特征的提取能力[20]。從文獻[10]中可知,充分利用融合模塊可以提取到圖像的深層次信息,學習到更強的重建映射。如圖8 所示,本文在增加融合層(merge)的基礎上,將原始的卷積層改為了殘差塊。每一個殘差塊由一個卷積層、一個BN[21]層以及激活層構成。
對于重建網絡的損失函數,目前大多是將特征匹配損失應用在異常檢測中[22]。由文獻[23]可知,特征匹配減少,GAN訓練就會不穩定。因此本文根據特征匹配的原則來定義損失函數。實際計算中首先令f為一個函數,該函數是判別器的中間層輸出,然后計算輸入x和生成器的輸出G(x)之間的L2距離,具體如式(4)所示。
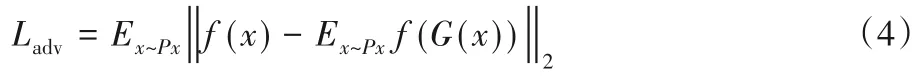
式中:Px為數據分布;Ladv代表生成器的損失。
3.2 分辨網絡
分辨網絡在訓練過程中,最小化生成器生成的數據G(x)和原始輸入數據x(形態流)之間的L2 距離。本文算法與GANomaly的不同之處在于,原分辨網絡與生成器的編碼部分擁有相同的結構,而本文中不要求兩者相同。改進的原因在于要保證GAN 訓練過程比較穩定,生成器網絡層數就不能設計得太深,否則會出現梯度不穩定的問題[21]。因此GANomaly原有的分辨網絡層數不深,也就導致了網絡的分辨能力不強。本文的分辨網絡與生成器編碼部分不同,為了提高分辨網絡的分辨能力加深了網絡的層數。同時,殘差網絡將梯度變化由原來的乘法運算優化為加法運算,能夠解決神經網絡訓練過程中梯度不穩定的問題,因此本文中使用了殘差網絡的結構來加深網絡的深度。設形態流的數據分布為Px,則改進后的神經網絡損失函數如式(5)所示。
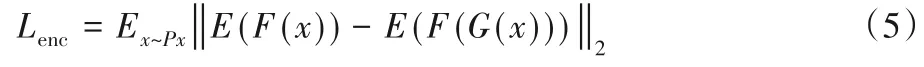
式中:F(x)為形態數據輸入分辨網絡得到的特征;F(G(x))為生成器的輸出G(x)輸入分辨網絡得到的特征。
3.3 判別器
判別器是生成對抗網絡的重要組成部分,負責判別生成器生成數據的真偽。即:生成器負責生成重建數據,判別器則負責判別生成的數據與原來的數據是否一致,并將判別的結果返回給生成器,以便監督生成器生成和原圖更加一致的數據。在損失函數方面,直接使用了文獻[24-25]的損失函數,如式(6)所示。

其中x、G(x)代表不同輸入數據。
3.4 數據訓練與異常檢測
訓練時,首先將形態流特征輸入生成器中進行數據重建,然后由判別器判別真偽;然后,同時將形態流和判別器輸出送到分辨網絡中進行訓練。訓練過程中使用的損失函數為上述三個部分神經網絡損失函數的結合,其具體表達式如式(7)所示。

訓練階段只用到了正常數據的原因有兩個:其一是異常偶有發生且不是固定的,因此難以完全列舉:其二是本文中訓練網絡是為了得到f1(x)和f3(x)兩個映射,最終是根據是否偏離正常數據的高斯模型來判定是否異常。
在進行異常檢測時,需要提前訓練好分割網絡、生成器以及分辨網絡。首先,需要將原始的視頻數據送入分割網絡分割出水流;然后,再按照前文所述的步驟提取形態流特征x;接著,將數據輸入生成器中得到重建結果G(x);最后,將x輸入分辨網絡獲取輸出的距離值,并將距離值輸入建立好的高斯模型得到輸出異常的概率值,當輸出的概率p<ε(高斯模型的閾值)時判定該數據異常,當輸出的概率值p≥ε時判定數據為正常數據。相較于GANomaly 中直接通過輸出的距離閾值來判別是否異常,本文算法更具有統計意義,高斯模型的計算式如式(8)所示。
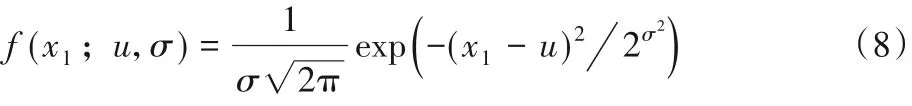
式中:x1代表輸入的距離值;σ代表統計的方差;u代表統計的均值。
高斯模型的閾值ε通過多次計算F1得分得到,其計算式如式(9)所示。

式中:真正例(True Positive,TP)代表異常樣本被檢測為異常;假正例(False Positive,FP)代表正常的樣本被檢測為異常;假負例(False Negative,FN)代表異常樣本被檢測為正常樣本。從上述計算式可以看出,FP和FN兩者越接近于0,F1得分越高,即誤檢和漏檢越少,F1值越接近于1。在選擇閾值ε時,通過多次隨機設定ε的值然后計算其F1得分,最終選取得分最高的值。
4 實驗與結果分析
根據實驗數據的不同可以將實驗分為兩個大類:一類是本文實地采集和制作的相關數據集上的實驗;另一類是在公共數據集上的實驗。在實體采集和制作的數據集上的實驗包括:1)水流分割實驗、形態流的驗證實驗;2)針對水流異常數據點檢測的實驗。由于目前沒有水流異常檢測的相關研究,所以也沒有相關水流公共數據集。所以本文為了驗證改進后的GANomaly 算法,在異常數據檢測的公共數據集上對改進后的算法和其他相關算法進行了對比實驗。實驗使用的平臺為Linux 服務器(Linux 8.0),內存為1 TB,訓練和測試都使用了兩塊顯存為12 GB 的Titan v 圖形處理器(Graphics Processing Unit,GPU)。
4.1 評價指標
評價指標中常用的方法是通過概率值來評價一個模型的好壞,其中最常用的是精度(Precision,P),計算方法如式(10)所示。
2018年9月28日,是孔子誕辰2569周年的日子。在這個特殊的日子里,為弘揚傳統文化,踐行“用中和思想,做德能教育”的辦學理念,培養德能兼修、知行合一的中和英才,山西省孝義市中和路小學全體師生相聚操場舉行“祭先師孔圣、承尊師傳統、育得能英才”為主題的紀念孔子誕辰2569周年暨新生開筆典禮活動(以下簡稱祭孔活動)。孝義市教育局政教科科長楊淑琴,山西九五新國學學院常務院長、山西家長學校講師團高級講師呂菊花,山西日報《青少年日記》雜志社編輯楊曉雪參加祭孔典禮。

4.2 實體采集和制作的數據集上的實驗
4.2.1 數據集介紹
實體采集和制作的數據集是通過在石油工廠實地采集獲得,異常的樣本也是有長期工作經驗的專家挑選出來的,專家們判別一個片段是否異常的依據是水流在時間軸上變化的劇烈程度。如圖2 所示,數據的左上角還有采集時間。用于實驗驗證的數據集共包含7 個場景,其中50 000 張訓練數據、2 000張測試數據。訓練數據全部是正常樣本,測試數據中包含1 000張正常數據和1 000張異常數據。正常的數據樣本片段如圖8 所示,異常圖像相較于正常圖像的前后兩幀數據之間的變化較大,具體如圖9所示。

圖8 正常樣本Fig.8 Normal samples

圖9 異常樣本Fig.9 Abnormal samples
4.2.2 水流分割實驗
特征提取是異常檢測的重要內容,水流分割是特征提取的重要一環。本文中通過U-Net 來進行水流分割,常用評判分割結果好壞的指標是交并比(Intersection Over Union,IOU)。為了確定式(3)中β的取值,本文在U-Net 上進行了多次實驗,實驗結果如表1所示。
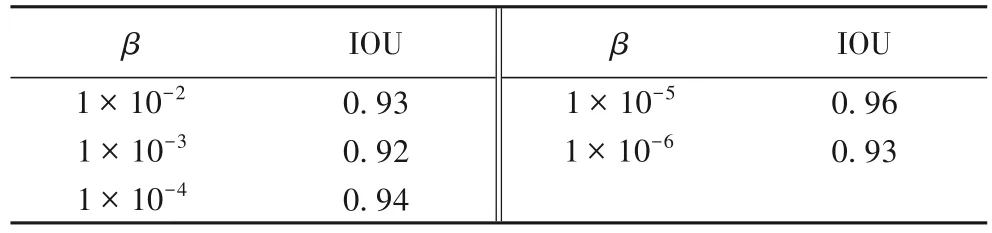
表1 U-Net中不同β值下的IOU對比結果Tab.1 Comparison results of IOU at different β values in U-Net
如表1 所示,β取值為1×10-5時可以獲得更好的分割效果。β取值為1×10-5時,樣本圖像和分割結果如圖3所示。
4.2.3 形態流特征驗證實驗
該實驗用于驗證形態流特征是否有效,參與對比的特征為原圖、分割圖像、光流、形態流。將上述4 種特征分別作為輸入在相同的模型中進行訓練和測試,然后取多次實驗的平均值作為最后結果,以此來驗證形態流特征在水流異常檢測任務中的優越性。GANomaly 和本文算法都使用上述四種特征作為輸入進行了實驗驗證,本文算法的實驗結果如表2 所示,GANomaly上的實驗結果如表3所示。

表2 本文算法采用不同特征作為輸入的檢測精度對比 單位:%Tab.2 Detection precision comparison of proposed algorithm with different features as input unit:%

表3 GANomaly采用不同特征作為輸入的檢測精度對比 單位:%Tab.3 Detection precision comparison of GANomaly with different features as input unit:%
如表2~3 所示,無論是在GANomaly 上還是本文算法上,新提出的形態流相較于其他三種特征都取得了更好的效果。光流特征由于其自身條件的限制,不適用于水流數據的特征提取,因此取得了最差的結果。原始數據和分割后的數據相比,原始數據存在更多背景噪聲的影響,所以它的精度相較分割后的數據較低;同時由于原始數據和分割后的數據不能體現水流數據形態在時間軸上的變化,而形態流同時具備時間域的變化信息和本身的空間信息,所以在水流數據的異常檢測上取得了更好的效果。
從表2~3 的對比可以看出,本文算法在四種特征上相較于原始的GANomaly 檢測精度皆有提升。由此可見,本文所提出的形態流特征,能夠適用于水流異常檢測,相較于其他特征有更好的性能表現。
4.2.4 水流異常檢測實驗
為了驗證本文算法在水流異常檢測任務中的優越性能,在水流數據集中將本文算法與其他的相關異常檢測算法進行了對比驗證。為了得到最好的訓練結果,實驗中對學習率等參數進行了多次的調整和訓練,由于這不是本文的研究重點所以沒有過多地介紹。每次訓練迭代200 次后精度不再提升即停止訓練。由于GAN 訓練的不穩定性,所以在之前多次訓練的情況下取最優結果的參數,又進行了五次的訓練,并取平均值作為最終結果。本文算法最終選取的學習率為0.000 01,batchsize 設置為64,輸入的圖像大小為最低高清圖像標準720×1280。參與對比的算法包括本文改進的算法、GANomaly[11]、EGBAD(Efficient GAN-Based Anomaly Detection)[12]、AnoGAN(Anomaly Detection with Generative Adversarial Network)[13]和孤立森林[26],這五種算法的檢測精度如表4所示。
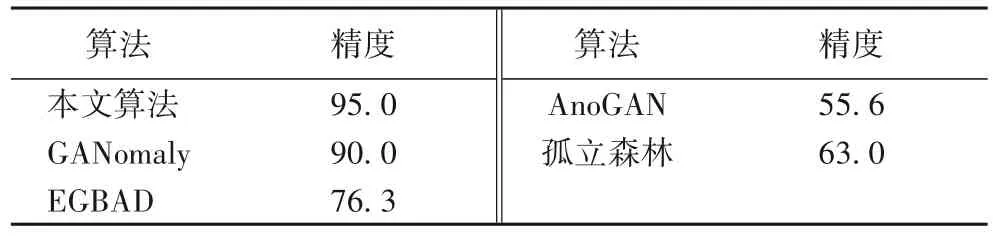
表4 不同算法的水流異常檢測精度對比 單位:%Tab.4 Comparison of water flow anomaly detection precision of different algorithms unit:%
從表4 中可以看出,本文所提算法的檢測精度明顯高于EGBAD[12]、AnoGAN[13]、孤立森林這幾種算法,其檢測精度達到了95.0%,相較于GANomaly 算法提升了5 個百分點。時間效率方面,同時使用兩塊Titan v 的GPU 時,可以達到每秒18 幀的檢測速度。本文算法能適用于如圖10 所示的不同場景,也能克服如圖10(d)所示的霧氣干擾,孤立森林和EGBAD[12]、AnoGAN[13]等算法 在實驗 中均不 能檢測到如圖10(d)所示的帶有霧氣的異常數據幀。

圖10 檢測到的異常片段Fig.10 Anomalies detected
4.3 公共數據集上的實驗
4.3.1 常用公共數據集介紹
異常事件檢測常用公共數據集是mnist 和cifar10。這兩個數據集原本是用來作為圖像分類的數據,但是由于異常檢測也可以看作二分類問題,即將數據視為正常和異常兩個類別,所以不少研究者也用它們來做異常數據檢測的研究[11-13]。在使用這兩個數據集時,由于進行的是無監督訓練,異常數據是不參與訓練過程的,所以在訓練之前需要將異常的類別選擇好。例如,本文將0 定義為異常類型,那么0 就不參與訓練只參與測試,1~9參與訓練。
4.3.2 公共數據集上不同算法對比
該部分的實驗設計是為了驗證本文算法的通用性,即本文改進后的神經網絡是否可以適用于不同的數據集,同時也可以從側面說明為何本文算法在水流異常檢測中性能表現突出。在mnist數據集和cifar10數據集上進行驗證,參與對比的算法有GANomaly[11]、EGBAD[12]、AnoGAN[13],結果如圖11所示。
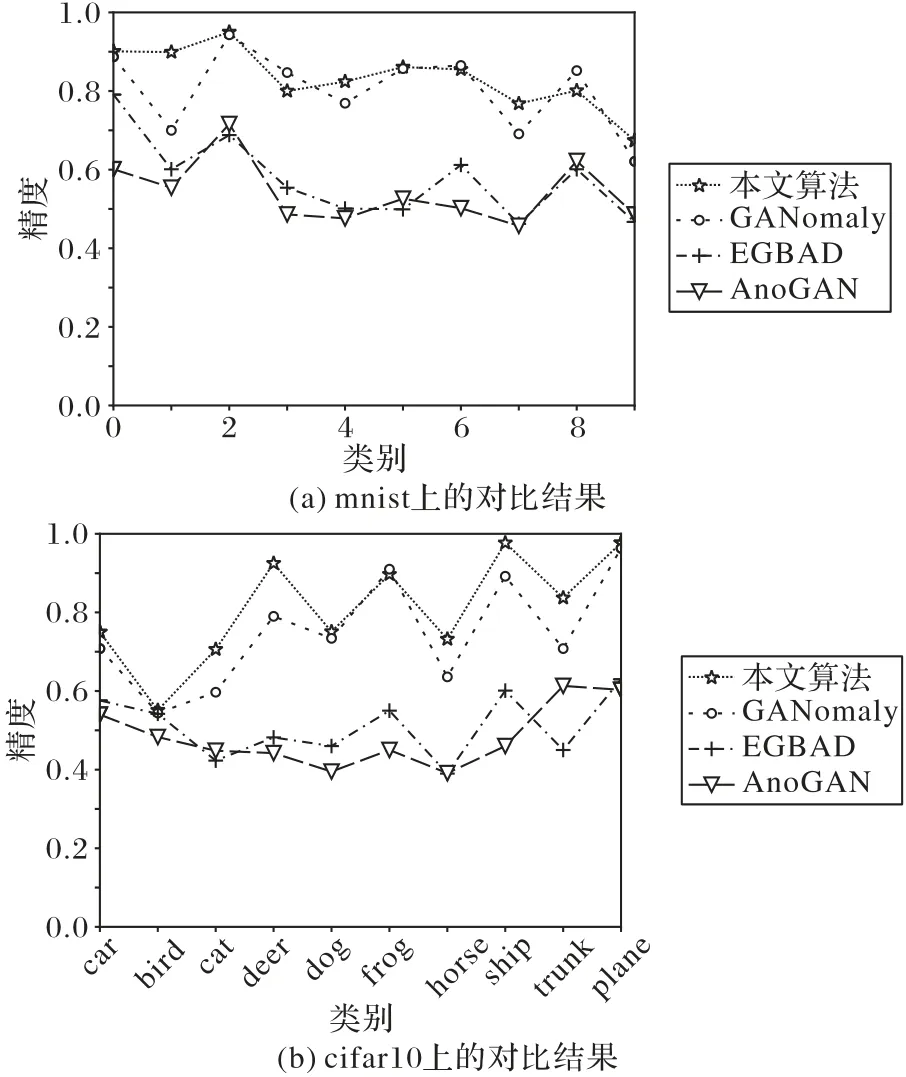
圖11 公共數據集上不同算法的對比結果Fig.11 Comparison results of different algorithms on public datasets
相較于用于對比的三個算法中表現最佳的GANomaly 算法,本文所提算法生成器和分辨網絡都改為殘差網絡結構,網絡深度增加了2 倍,同時加入了特征融合層使得網絡的特征提取和分辨能力大幅提高。實驗過程中神經網絡學習率設置為0.000 1,batchsize 設置為64,輸入圖像的大小設置為640×640。
如圖11 所示,兩個數據集共20 個類別中有8 個類別本文改進后的算法與GANomaly 算法持平,10 個類別的精度高于原來的算法,只有在mnist 數據集中3 和8 這兩個類別精度低于GANomaly算法。類別3和8上,本文算法相對于GANomaly算法低了5 個百分點左右,其可能的原因在于3 和8 的右側很像,本文的神經網絡可能對于具有左右兩部分相似的數據不友好。這一點可以從1 和7 側面印證,從上往下看1 和7 具有一定相似性,所以原來的GANomaly 區分不出來,而本文改進后的神經網絡學習到了數字左側和右側的內容,而1和7從左往右看差別比較大,所以在類別1和7上改進后的算法檢測精度提升了10 個百分點以上。EGBAD[25]、AnoGAN[1]這兩個算法的精度相較于GANomaly 和本文改進的算法在所有類別上的精度都較低。
5 結語
本文從實際出發,通過對水流的異常檢測解決了石油生成過程中的污染氣體監測問題。由于異常偶有發生且表現形式不固定,無法列舉所有異常情況,所以異常數據的獲取困難。為解決這個問題,本文采用了無監督學習的方法,在網絡模型訓練過程中模型通過正常數據隱式地獲取和學習異常。水流異常檢測任務中本文算法精度可以達到95.0%,利用兩塊Titan v的GPU同時計算可以達到18 frame/s的處理速度,滿足實際需求。在算法層面提出了形態流特征,能準確刻畫水流形態的快速變化。在mnist 數據集中異常類別設置為1 時,本文算法檢測精度達到了90.1%,相較于GANomaly 提高了19 個百分點。本文改進的神經網絡算法在公共數據集中有50%的類別優于原始算法,40%和原始算法持平,但是依然存在10%的類別低于原始算法。由實驗分析可知,本文的神經網絡可能對左右對稱的數據不友好,但是由于缺乏類似的樣本和數據因此無法進行進一步的實驗和改進。同時本文只根據前后兩幀的形態變化來提取特征,下一步可以考慮結合連續多幀的形態變化來提升精度。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
