基于輕量級卷積神經網絡的植物葉片病害識別方法
2021-07-02 08:55:10賈鶴鳴郎春博姜子超
計算機應用 2021年6期
賈鶴鳴,郎春博,姜子超
(1.三明學院信息工程學院,福建三明 365004;2.福建省農業物聯網應用重點實驗室(三明學院),福建三明 365004;3.西北工業大學自動化學院,西安 710129;4.東北林業大學機電工程學院,哈爾濱 150040)
(?通信作者電子郵箱lang_chunbo@163.com)
0 引言
植物病害的產生對農業生產有一定負面影響。如果不及時發現植物病害,就會增加糧食的風險[1],特別是對一些主要的糧食作物,如玉米、水稻、小麥等,它們是滿足人民生活需要、推進生產力發展的關鍵。因此,探求一種智能化、低成本、高準確的方法來實施植物病害檢測有著重要的現實意義。機器學習中的特征提取和模式識別有助于識別植物病害的類型和嚴重程度。通過植物葉片圖像的顏色、形狀和大小等特征對植物健康狀況進行自動質量分析,是提高生產力的一種準確可靠的方法[2-3]。
以往的許多研究工作都考慮了圖像的識別問題,并采用一種特殊的分類器將圖像分為健康圖像和病變圖像。一般來說,植物葉片是植物病害識別的第一手資料,因為大部分病害的癥狀最先出現在葉片上。在過去的幾十年里,主要病害的識別和分類技術在植物中得到了廣泛的應用,包括K近鄰(K-Nearest Neighbor,KNN)[4]、支持向量機(Support Vector Machine,SVM)[5]、Fisher線性判別(Fisher Linear Discriminant,FLD)[6]、人工神經網絡(Artificial Neural Network,ANN)[7]、隨機森林(Random Forest,RF)[8]等。眾所周知,經典方法的疾病識別率很大程度上取決于各種算法的病變分割和手工設計的特征,如七不變矩、尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)、Gabor 變換、全局-局部奇異值和稀疏表示[9-11]等。然而,人工設計的特征需要昂貴的資源條件和專業的知識,同時具有一定的主觀性。況且從被提取的目標上很難確定哪些特征是最優的、魯棒的疾病識別特征。此外,在復雜的背景條件下大多數方法都不能有效地將葉子和相應的病變圖像從背景中分割出來,導致實驗得到的結果不能有效地用于預測疾病的發生。因此,由于病害葉片圖像的復雜性,植物病害圖像的自動識別仍然是一項具有挑戰性的工作。
近年的深度學習技術,特別是卷積神經網絡(Convolutional Neural Network,CNN),正在迅速成為克服上述挑戰的首選方法。由于卷積神經網絡的尺度不變性,使得它解決的圖像問題不受尺度限制,進而在識別和分類方面表現出突出的能力。例如,Mohanty等[12]訓練了一個深度學習模型來識別14 種作物和26 種作物病害。Ma 等[13]利用深度CNN對黃瓜霜霉病、炭疽病、白粉病和目標葉斑病這4 種病害的癥狀進行識別,識別準確率達到了93.4%。Kawasaki 等[14]提出了一種基于CNN 的黃瓜葉病識別方法,達到了94.9%的準確率。同樣,本文也利用CNN 對植物葉片病害特征進行提取,提出了一種基于VGG-16(Visual Geometry Group-16)的輕量級卷積網絡。首先,在原有網絡中引入深度可分離卷積(Depthwise Separable Convolution,DSC)[15]和全局平均池化(Global Average Pooling,GAP)[16],代替標準卷積運算操作并對網絡末端的全連接層部分進行替換。同時,批歸一化的技術也被運用到訓練網絡的過程,以改善中間層數據分布并提高收斂速度[17]。改進后網絡在植物葉片病害數據集PlantVillage 上的實驗結果表明,所提出的輕量級卷積網絡在識別精度與效率方面有了明顯的提高,適用于植物葉片病害識別的任務,具有較強的工程實用性以及較高的研究價值。
1 卷積神經網絡
1.1 卷積神經網絡基本理論
卷積神經網絡是一種通過多層網絡互聯并相互傳遞數據信息的常見深度學習模型。每一層都具有獨特的特征來處理輸入數據并將其發送到下一層。卷積神經網絡從輸入待處理圖像到輸出分類結果的過程,包括:用于獲取數據并進行預處理的輸入層、提取圖像高級特征的卷積層、降采樣的池化層、提高模型非線性的ReLU 激活層、整合卷積層提取的高級圖像特征的全連接層、在模型最后部分輸出各類別預測概率的Softmax層。
1.1.1 輸入層
圖像輸入層是CNN 體系結構中的重要組成部分,其將2-D 和3-D圖像作為主要處理對象。

其中:Input代表圖像輸入層,該層對給定圖像I進行預處理操作,進而得到滿足要求的圖像V作為后續卷積層輸入;D代表輸入圖像通道數。
1.1.2 卷積層
該層按照一定的規則在輸入圖像V=m×n上移動卷積內核窗口k。內核窗口k每次滑動的距離由步長Sd決定,具體計算過程如下:

其中:Fm表示圖像特征信息;Rl表示激活函數,主要用來改善模型的非線性。
1.1.3 批歸一化層
該層通過改善中間層的數據分布,進而影響模型優化器的梯度下降過程以實現提高模型收斂性能的目的。它采用了來自前一層卷積的特征圖Fm并將其激活歸一化,該過程可以定義為:

其中:N(·)表示歸一化函數;ax表示特征圖中統一進行均值與方差計算的坐標軸信息;M表示決定均值與方差之間變化的動量率。
1.1.4 池化層
對從批歸一化層獲得的每個特征圖Fm+1執行最大池化操作,以減小圖像大小。步幅Sd的值通常由用戶手動選擇。池大小Ps必須按以下方式賦給該層:

1.1.5 全連接層
全連接層主要作用是歸整前面網絡層獲取的圖像信息,將原本稀疏連接的方式轉化為完全連接的形式,如式(5)所示:
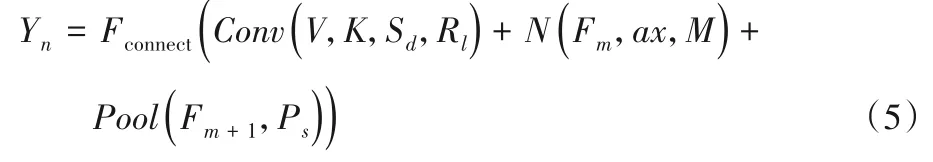
1.1.6 Softmax層
該層主要設計用于對全連接層的輸出進行分類和預測,并輸出每個類別的模型預測結果,其計算式如下:

其中,F(Xi)可以計算全連接層Yn返回的每個類別的概率。
1.2 VGG網絡
VGG 網絡(VGGNet)是由牛津大學視覺幾何小組和谷歌的DeepMind的研究人員開發的一種深度CNN,致力于研究網絡深度和CNN 性能之間的聯系[18]。通過反復堆疊小尺寸卷積層和池化層,建立了一個網絡深度為16~19 的深度卷積神經網絡模型,并探索了深度對網絡性能的影響。與之前最先進的網絡架構相比,VGGNet 的錯誤率明顯下降,在2014 年ILSVRC(ImageNet Large Scale Visual Recognition Challenge)競賽中獲得第二名,在定位項目中獲得第一名。在VGGNet 的所有研究中都使用了3×3 卷積內核和2×2 池內核,通過不斷深化網絡結構來提高性能。
圖1 給出了具有5 個卷積模塊的VGG 網絡結構,每個卷積模塊通常包含2~3 次卷積運算。其中,Input、Conv、Pool、FC、Softmax 分別代表輸入層、卷積層、池化層、全連接層和分類層。
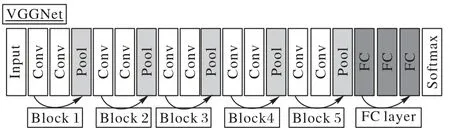
圖1 VGG網絡框架示意圖Fig.1 Schematic diagram of VGG network framework
2 輕量級卷積神經網絡
針對傳統CNN 參數較多、易過擬合的問題,分別采用深度可分離卷積和全局平均池化策略替換其標準卷積以及全連接層部分。此外,批歸一化的方法也被分別用于調整中間層數據分布和防止模型過度擬合。
2.1 深度可分離卷積
深度可分離卷積完整過程的第一步是深度卷積部分,也叫通道卷積(圖2(b))。給定與特征圖中具有相同通道數的過濾器數量,并以通道為單位分別進行卷積運算,如式(7)。
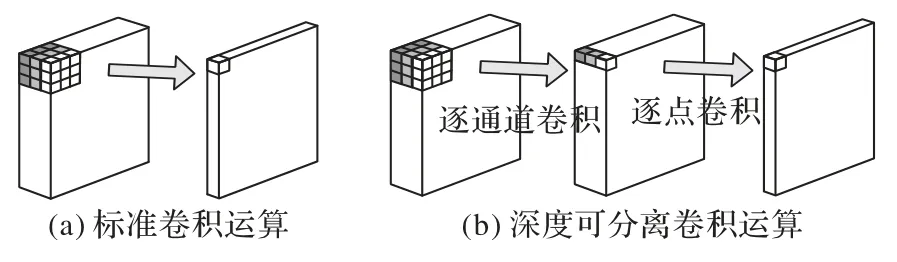
圖2 深度可分離卷積與標準卷積對比Fig.2 Comparison between depthwise separable convolution and standard convolution
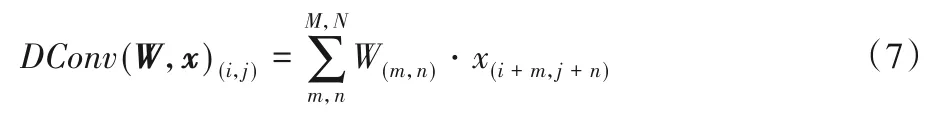
深度可分卷積的第二步是將第一步輸出的特征圖與通道數和深度卷積相同且大小為1×1 的卷積核相結合。逐點卷積核的個數在這部分中就代表著提取特征的個數,該操作組合了特征圖的各維度,因此減小了通道數量,其具體計算過程如式(8)所示:
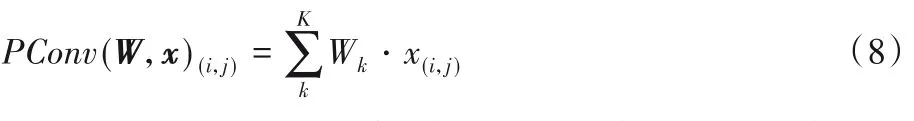
其中:W是卷積核的權重矩陣,并且是可訓練的;x表示輸入到卷積層的特征圖,(i,j)表示元素的坐標索引;m、n和k是卷積核的3個維度。
2.2 全局平均池化
為了解決傳統網絡易過擬合的問題,在卷積神經網絡的結構中引入了全局池化層來代替全連接層,將卷積層輸出的多個特征圖以自身為單位進行映射,映射結果為一個特征點。多個特征點便得到了與上述特征展開相似的一維向量,而后傳入Softmax層中進行分類。

2.3 批歸一化
批歸一化層的主要目的是解決網絡深入化導致的中間數據分布不均影響模型學習效率的問題。具體來說,對于具有n維輸入的層x=(x1,x2,…,xn)。
首先,對每個單元所表示的特征進行歸一化,使其具有0均值和1標準差。

其中:E[xi]是每個單元的平均值;表示標準偏差。通過引入參數γi和βi對激活值進行移動和縮放來解決原有表征改變的問題,變換式如下:

該變換在Wxn的每個維度中獨立使用,具有一對獨立學習參數γn和βn,xn和W分別表示輸入數據集和權重矩陣。
2.4 算法架構與分析
圖3 給出了VGG16 網絡的架構示意圖,可以看到隨著特征提取的進行,特征圖的尺寸由于池化層的作用而不斷減小,維度由于卷積核個數的增多不斷增加。算法逐步提取出更多且更高級的圖像特征信息,以更好地勝任分類識別任務。此外,改進卷積神經網絡的算法各層級信息如表1 所示,其中:“3,3”代表卷積核大小;“DSConv”代表深度可分離卷積;“64/S1”代表卷積核個數與卷積步長。以第一層“3,3 DSConv,64/S1”為例,該層參數由逐通道卷積與逐點卷積兩部分組成(如2.1 節介紹),首先逐通道卷積部分參數為“卷積核大小×輸入通道數”即“32×3”,其次逐點卷積部分為“點卷積核大小×輸入通道數×卷積核個數”即“(1×1×3)×64”。同理可得第二層參數,區別在于輸入通道數由3 變為64。從表1 中可以明顯看出,加入全局平均池化策略后節省了傳統全連接層大量的參數,如果不采用GAP 方法改進該部分,則全連接fc1層的參數為8×8×512×4 096=134 217 728。

表1 改進網絡的各層級信息Tab.1 Information of different levels of improved network
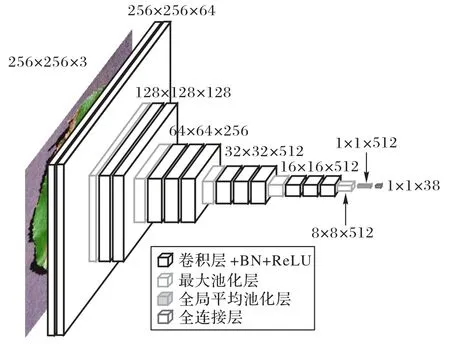
圖3 輕量級卷積神經網絡架構Fig.3 Architecture of lightweight convolution neural network
為解決傳統網絡進行植物葉片病害識別過程產生的過擬合問題,本文采用深度可分離卷積與全局平均池化策略分別代替標準卷積運算與全連接層進行網絡優化。具體來說,深度可分離卷積通過將標準卷積運算拆分為逐通道卷積與逐點卷積以減少卷積層部分參數。如果輸出通道的數量為o,那么標準卷積層所需的總參數為m×n×k×o。深度可分離卷積運算的參數則由逐通道與逐點卷積兩部分組成,為m×n×k+k×o,它們之間的比例是。而在時間復雜度方面,深度可分離卷積同樣具有一定的優勢,設M和K分別表示特征映射和卷積核的大小,Cin和Cout分別表示輸入和輸出通道的數目,則標準卷積的時間復雜度是O~(M2×K2×Cin×Cout),深度可分離卷積的復雜度可表示為O~(M2×K2×Cin+M2×Cin×Cout),當輸出通道數較大時,方法之間的復雜度差異更加明顯。因此,本文采用深度可分離卷積來替代傳統的標準卷積運算以減少卷積層部分復雜度,防止過擬合現象產生。之間的對應關系,另一個優點在于對特征圖求均值的操作不需要額外的參數,與大量參數構成的全連接層相比能夠避免訓練集過度擬合的現象發生。此外,全局收斂對空間信息進行了總結,因此所構造的特征向量對于輸入圖像的空間平移具有更強的魯棒性。在植物葉片病害識別中,使用全局平均池比全連接操作有更好的識別效果,因為GAP 可以實現對于數據的降維和參數的壓縮,有效地防止過擬合發生并增強模型泛化能力。由于在GAP 中不需要對參數進行優化,因此可以有效地克服過擬合并減少參數訓練的時間。此外,批歸一化操作的引入有效地解決了網絡中間層數據分布不均的問題,按特征維度求均值與標準差進而進行歸一化的操作改善了特征分布情況,對收斂速度與精度均產生了較好的影響。
3 植物葉片病害識別實驗
而對于傳統算法中參數量龐大的全連接層部分,本文采用全局平均池化策略對其進行優化。全局平均池化層對卷積層輸出的特征向量逐通道求取特征均值,通道數對應分類器所需的類別數。其優點之一是增強了提取的特征映射和類別
3.1 數據集及預處理
本文將深度學習模型架構在植物葉片圖像上進行了訓練,然后對該模型未見過的圖像進行疾病分類和識別。該研究使用 了PlantVillage[19]的公共 數據集。PlantVillage 擁 有54 306 張圖像,其中包括14 種農作物上的26 種常見病害,共38類。選取原始數據集中部分圖像進行展示,如圖4所示,分別為:蘋果瘡痂病、黑腐病、銹病、健康葉;玉米灰斑病、銹病、枯葉病、健康葉;番茄靶斑病、菌斑病、黃曲葉病、健康葉。

圖4 植物葉片病害數據集部分圖像Fig.4 Some images of plant leaf disease dataset
通過整理數據可以發現,植物葉片數據存在對比度較低、樣本分布不平衡等問題,這會在一定程度上影響訓練的速度以及收斂精度。因此,分別利用直方圖均衡化以及數據擴充技術加以改善(如圖5 所示)。在本文研究中利用Python 腳本語言編寫程序,采用隨機旋轉角度、隨機縮放原圖、隨機水平/垂直翻轉操作實現樣本數據的增強。在對少量樣本數據類數據擴充的同時也對大量樣本數據類進行刪減操作,最終使得各類樣本數據均為1 500張。

圖5 植物葉片病害圖像預處理過程Fig.5 Preprocessing process of plant leaf disease image
3.2 實驗環境及設置
實驗在圖形處理單元(Graphics Processing Unit,GPU)模式下進行,實驗所用計算機的詳細配置為:內存16 GB,Nvidia GTX980Ti顯卡,使用的操作系統為64位Ubuntu 16.04。實驗選用的腳本語言為Python,并安裝OpenCV 圖像處理庫、Pytorch深度學習框架。
實驗以小批量的形式進行,每批同時用32 張圖片進行訓練/測試。損失函數優化器采用隨機梯度下降(Stochastic Gradient Descent,SGD)算法,學習率采用warmup 更新策略(如圖6 所示)。初始學習率為1E-6,最大學習率為1E-2,預熱周期為3 個epoch,動量為0.9,權重衰減系數為1E-3。此外,在優化器的warmup 階段結束后,學習速率的更新方式是,如果當前epoch 的測試精度低于上一個epoch 的測試精度,學習率衰減到原來的1/2。遍歷測試集中的所有圖片一次稱為一個epoch,在訓練階段執行15個epoch。
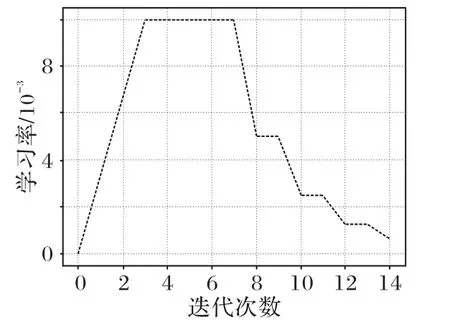
圖6 warmup學習率調整方式示意圖Fig.6 Schematic diagram of warmup learning rate adjustment mode
3.3 實驗結果與討論分析
本節中改進的卷積神經網絡被用于解決植物葉片病害識別問題,實驗可以被分為五部分,分別探究數據集擴充、改進策略加入、不同初始化與激活函數、全局池化類型對測試精度的影響以及與其他植物病害識別技術的對比。
3.3.1 數據集擴充對測試精度的影響
3.1 節介紹了對PlantVillage 數據集的擴充操作,將樣本分布不平衡的原始數據集調整為每類均有1 500 張圖像的數據集。表2 展示了算法改進前后在原始數據集和擴充后數據集上的評估指標值對比情況。本節實驗中選擇的準確度評價指標的計算方法是38 類正確預測樣本數與測試集大小的比值。平均查準率和平均F1 評分為各類別查準率和F1 評分的平均值。

表2 擴充數據集前后算法性能指標對比Tab.2 Comparison of algorithm performance indexes before and after extending dataset
從表2 中可以看出,使用數據增強操作處理后的數據集進行實驗,傳統網絡和改進后網絡在各指標上均有所提升,提升比例約為1 個百分點。例如原始模型的測試精度從97.281%提升至98.304%;平均查準率從97.294%提升至98.306%;平均F1 評分從97.367%提升至98.301%。對于特征信息獲取方面,通過隨機縮放、旋轉、翻轉等操作對原始數據進行增強,得到的擴充數據集能夠幫助模型學習到更加魯棒且更具判別性的特征,這類特征的泛化性能更好,進而在訓練集上進行測試同樣得到了更高的精度。對于數據分布方面,擴充后的數據集中各類訓練樣本數量相同、分布均勻,這使得模型對于各類別的學習過程不會偏向某一類或某幾類,得到的模型泛化能力較強,進而在指標結果中得以體現。
3.3.2 改進策略對測試精度的影響
本節將從測試精度和訓練時間兩個方面分析改進策略對實驗結果的影響。測試精度反映了模型解決當前植物病害分類問題的能力,訓練時間反映了模型獲得解決當前問題能力所花費的成本。
圖7 顯示了傳統模型和改進模型在擴展數據集上的精度和損失的比較結果。可以看出,改進模型的收斂精度優于原模型(迭代停止時更高的測試精度以及更低的測試損失),這是因為深度可分離卷積和全局平均池化策略的結合有效地減少了模型的參數量,避免了模型對當前訓練樣本的識別能力較好而測試樣本的識別較差的過擬合現象發生,提高了其泛化和適應新樣本的能力,進而在測試集上獲得了更好的收斂精度,而原始模型由于其龐大的參數量導致其在測試集上的泛化性能較差,并不能在學習過程中獲得更具判別性的圖像特征。從收斂速度方面來看,改進后算法在第8個epoch 開始收斂,而原始算法在第7 個epoch 開始收斂,盡管收斂速度較慢于傳統模型,但綜合精度與速度可以發現,改進后的模型有效地避免了測試集過擬合的現象發生,能夠在解空間內獲得更為優異的參數。
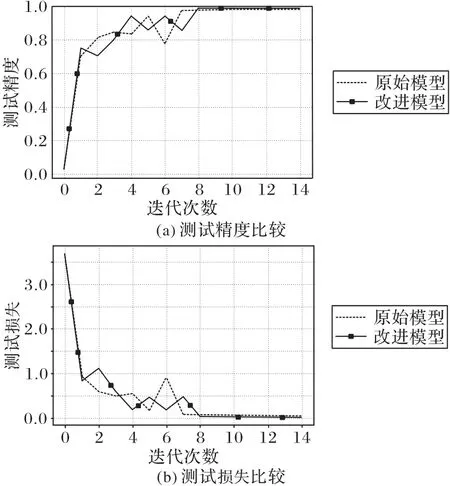
圖7 擴展數據集上傳統模型和改進模型的性能比較Fig.7 Performance comparison between traditional model and improved model on extended dataset
表3 給出了不同改進策略組合對模型測試結果的影響,包含骨干網絡分別結合深度可分離卷積與全局平均池化后的測試精度與測試損失。從表3 中可以看出,對標準卷積運算和全連接層的改進都帶來了性能的提升,而后者的效果更為明顯。這是因為導致傳統網絡過擬合現象產生的關鍵在于參數量龐大的全連接層,對此部分進行優化能更好地解決該問題。但通過逐通道卷積與逐點卷積相結合的方式代替標準卷積運算的操作也能夠在一定程度上減少卷積層部分的參數量,并獲得較高的測試精度,這也從側面說明了本文方法將兩者結合的可行性與有效性。觀察實驗結果可以發現,深度可分離卷積與全局平均池化策略的結合使模型在測試階段獲得了最高的精度與最低的損失,進一步驗證了所提方法的可靠性與高效性。
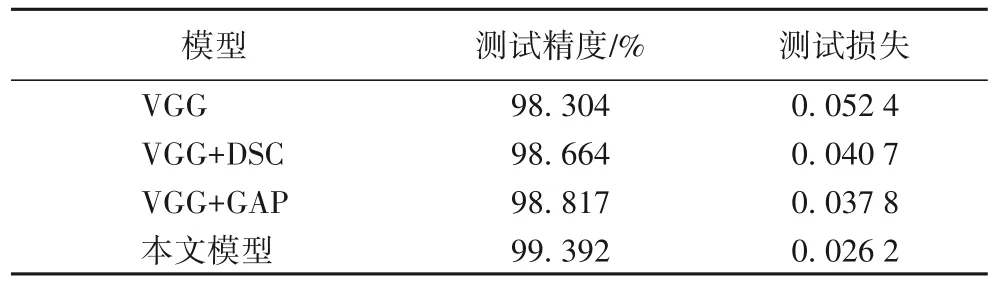
表3 不同改進策略組合的測試結果Tab.3 Test results of different combinations of improvement strategies
表4 給出了網絡改進前后參數量及運行時間的比較,可以看出改進后的網絡參數量遠小于改進前參數量,這是由于全連接層占據了原始網絡的絕大部分參數,而采用的全局平均池化策略替換了原有的全連接層,減少了網絡的主要參數;此外,深度可分卷積部分將標準卷積分成逐通道卷積和逐點卷積兩部分,進一步降低了原卷積層部分的參數,極大改善了復雜網絡的易過擬合特性,在參數量較少的同時,提高了測試精度。從程序運行時間方面看,在每批訓練32 個樣本的情況下,原始模型需要586 s 的時間,而改進模型僅需要233 s。程序總時間上的差別更加明顯,訓練15 個epoch 花費的時間相差109.615 min,體現了改進后模型在訓練成本方面的優異性。綜合來看,改進后的模型參數量顯著降低,其成效不但體現在防止過擬合進而提高測試精度方面,同樣體現在訓練所需的時間成本方面,具有很強的工程實用性。

表4 算法改進前后參數量及運行時間比較Tab.4 Comparison of parameter number and running time before and after improvement
3.3.3 初始化類型與激活函數對測試精度的影響
在本節中,針對不同初始化方法與激活函數類型的模型進行性能測試,進一步優化模型。網絡參數的初始化方式對于模型的學習過程以及最終的測試精度均有一定的影響:較好的初始化值能夠加快優化算法對其數值調整的速度,進而提高收斂速度;而較差的初始化值不但會減緩優化的進程,甚至會導致算法陷入局部最優。具體來說,本文將初始化類型分為高斯初始化和Xavier初始化,激活函數類型分為ReLU 和PReLU。
實驗結果如表5 所示,可以發現使用Xavier 初始化方法與PReLU 激活函數均能帶來性能的提升,而且這兩種改進方式的結合使得測試精度進一步提高。

表5 初始化類型與激活函數對測試結果的影響Tab.5 Influence of initialization type and activation function on test results
具體來說,Xavier 初始化方法的目標是使得每一層輸出的方差應盡量相等,這與2.3 節中批歸一化方法的作用相類似,即改善中間層的分布情況。因此,引入該初始化方法后的模型獲得了更為優異的初始分布,優化了模型的學習過程。而PReLU 函數通過引入參數改善了傳統ReLU 激活函數負半軸激活值為0 的死區,使網絡所學習的特征更加具有魯棒性與判別性,進一步提高其在測試集上的精度。從結果上看,僅使用Xavier 初始化可以提升精度0.012 個百分點,僅使用PReLU 激活函數可以提升0.007 個百分點,而結合使用的方式可以提高0.035 個百分點。實驗結果表明,改善初始化方法以及激活函數類型均能夠提高模型對于測試樣本的識別性能,而且本文所提模型的性能仍具有一定的提升空間,結合近年來神經網絡改進策略,有一定的潛力達到更高的識別準確率,更具應用前景。
3.3.4 全局池化類型對測試精度的影響
本節探討改進后網絡全局池化部分的不同類型對算法性能所產生的影響。具體來說,改進策略中的全局池化方法分為全局最大池化和全局平均池化,區別在于從給定的特征映射到輸出節點的轉換過程是計算所有元素的最大值還是平均值,分別對應于顯著表達和整體表達。
表6 給出了全局平均池化以及全局最大池化的測試結果,可以看出,相較于最大池化,全局平局池化在當前網絡結構上表現出更好的適應性,得到了更高的測試精度以及更小的測試損失,表明對于當前數據集合,提取其整體特征的效果相較于顯著特征的效果更好,即獲取更具判別性的整體信息意義較大,對樣本局部特征的綜合與總結有助于模型判別目標,但這不足以說明全局最大池化在解決圖像分類問題中的意義和價值,畢竟沒有方法可以普遍適用全部模型以及全部問題,因此需探究不同改進策略對網絡的影響。

表6 全局池化類型對測試結果的影響Tab.6 Influence of global pooling type on test results
3.3.5 與其他植物病害識別技術的對比
為客觀而全面地評估所提網絡模型的性能,在本節引入其他學者解決PlantVillage 數據集圖像識別問題的方法進行比較,實驗結果如表7 所示。由表7 中可以發現,本文方法獲得了最高的測試精度以及F1 評分,提升效果為1~2 個百分點,且相較于文獻[20]方法節省了88.5%的參數,兼顧了識別準確率與資源利用率。相較于文獻[20]中采用群智能優化算法對網絡進行優化的策略相比,本文對于優化器方法部分沒有進行改動,僅選擇了標準的SGD 優化算法,但全局平均池化以及深度可分離卷積等策略的引入極大地減少了網絡參數,獲得了相較于改進優化器方法更好的泛化能力與測試精度。與文獻[21]方法相比,本文方法對于過擬合問題的處理采用了GAP 與DSC 策略相結合的方法,比單獨改進卷積方式效果更為明顯,取得了參數量與測試精度間的平衡。
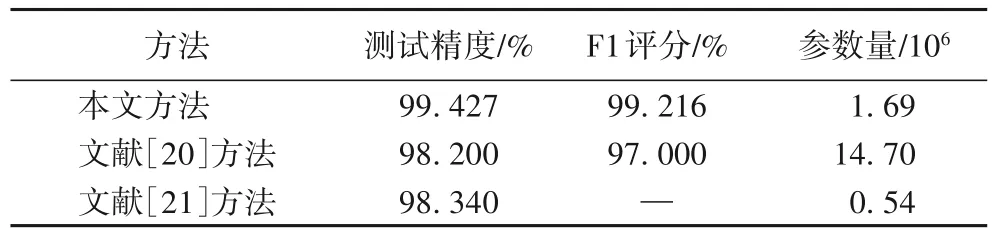
表7 不同方法在PlantVillage數據集上的性能對比Tab.7 Performance comparison of different methods on PlantVillage dataset
此外,為更好地分析本文網絡獲得圖像特征表達的過程,分別將各模塊中卷積層的輸出特征圖可視化,如圖8 所示。由圖8 可以看出,隨著網絡層數的提高,所提取的圖像特征越來越抽象,特征的紋理性逐漸被更高級的語義性所取代;而本文提出的網絡從過程上看獲得了較為豐富的邊緣信息,從結果上看又取得了較高的識別精度,適用于植物葉片病害的識別。
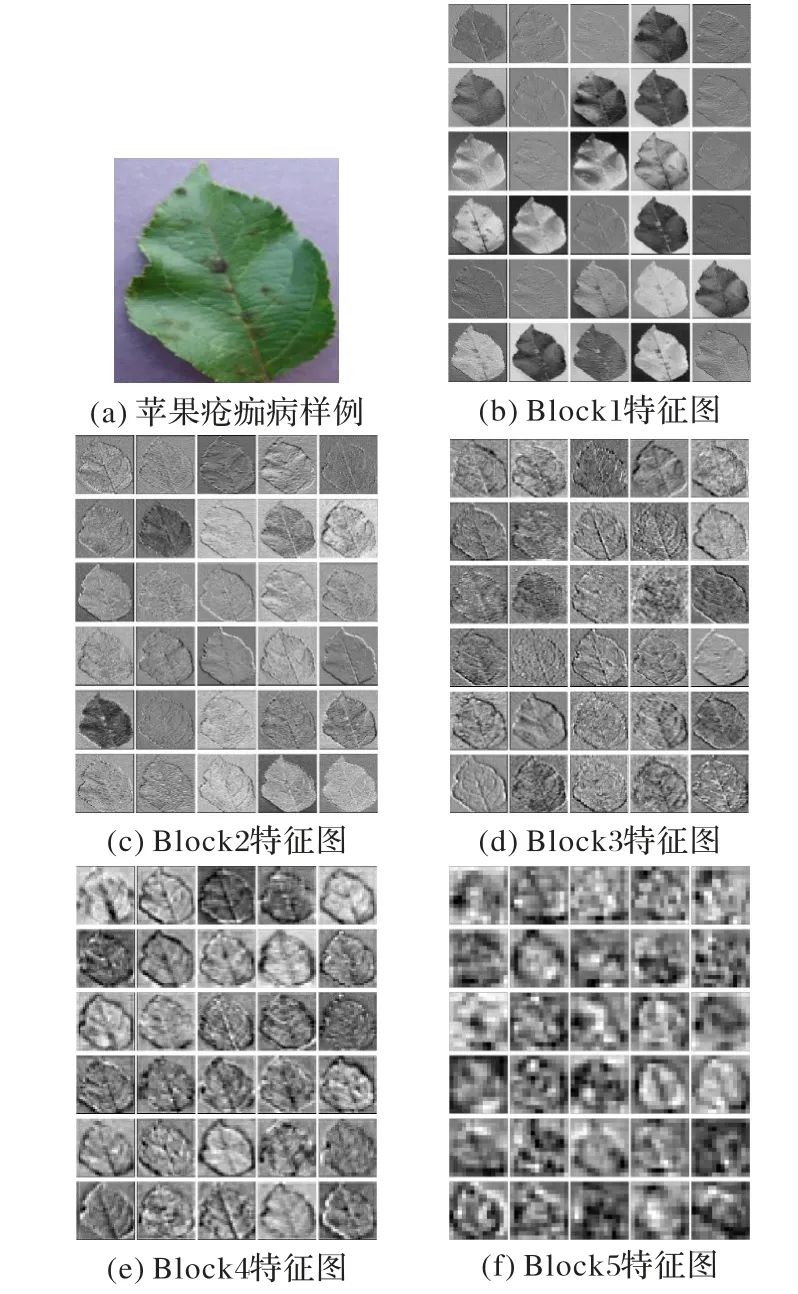
圖8 可視化卷積特征圖Fig.8 Visual convolution feature maps
4 結語
本文提出了一種輕量級網絡模型來解決生產實際中植物葉片病害識別困難、智能化較差的問題。該網絡將深度可分離卷積與全局平均池化相結合,有效地提高了測試精度,減少了程序運行時間。總結來說,改進后的卷積神經網絡不但具有可觀的測試精度,并且運行速度、內存占用量方面也優勢明顯,較好地解決了植物病害圖像識別問題,為后續相關研究提供了可靠的技術支持。在未來將會側重研究調整網絡結構對測試結果的影響。此外,其他植物葉片病害數據集的擴展研究也將被考慮在內,測試并改進現有算法,提高模型對于這類問題的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
