基于改進(jìn)YOLOv3的船舶目標(biāo)檢測(cè)算法
2021-07-02 01:59:06盛明偉秦洪德武萬(wàn)琦
導(dǎo)航與控制 2021年2期
盛明偉,李 俊,秦洪德,崔 壯,武萬(wàn)琦
(哈爾濱工程大學(xué)船舶工程學(xué)院,哈爾濱150001)
0 引言
21世紀(jì)是海洋的世紀(jì),我國(guó)對(duì)海洋資源的重視程度正日益提高。國(guó)家基金委八大學(xué)部公布的信息科學(xué)部?jī)?yōu)先發(fā)展領(lǐng)域的第一條即是海洋目標(biāo)信息的獲取、融合與應(yīng)用,其主要研究方向?yàn)?1)海上目標(biāo)探測(cè)、識(shí)別理論及方法;2)水下目標(biāo)探測(cè)機(jī)理和識(shí)別方法;3)水下通信與海空一體信息傳輸;4)海洋目標(biāo)環(huán)境觀測(cè)與信息重構(gòu);5)異質(zhì)異構(gòu)海量數(shù)據(jù)處理與信息融合理論與關(guān)鍵技術(shù)。在國(guó)防建設(shè)以及交通運(yùn)輸領(lǐng)域,船舶是不可或缺的交通工具,因此船舶檢測(cè)技術(shù)具有相當(dāng)重要的研究意義。船舶檢測(cè)技術(shù)是海洋獲取海面船舶信息的重要方法,其應(yīng)用領(lǐng)域十分廣泛。自進(jìn)入信息化時(shí)代以來(lái),計(jì)算機(jī)技術(shù)的發(fā)展越來(lái)越迅速,生產(chǎn)向著智能化、網(wǎng)絡(luò)化方向發(fā)展,計(jì)算機(jī)在港口或船舶上的應(yīng)用越來(lái)越多。傳統(tǒng)船舶檢測(cè)技術(shù)多是在選擇出的候選區(qū)域中提取出傳統(tǒng)特征,再根據(jù)簡(jiǎn)單的分類(lèi)器進(jìn)行船舶分類(lèi)識(shí)別,例如SVM分類(lèi)器[1]等,候選區(qū)域的選擇方法多采用不同尺寸的滑動(dòng)窗口獲得。傳統(tǒng)特征包括HOG特征、Harr特征、SIFT特征[2]等,多為淺層特征,在目標(biāo)分類(lèi)上的識(shí)別準(zhǔn)確率較低。同時(shí),傳統(tǒng)的船舶檢測(cè)技術(shù)在產(chǎn)生候選區(qū)域時(shí)的計(jì)算耗時(shí),檢測(cè)速度達(dá)不到實(shí)時(shí)要求,檢測(cè)效率低下。
近年來(lái),深度學(xué)習(xí)[3-4]在船舶目標(biāo)檢測(cè)中的應(yīng)用日益增多。相比傳統(tǒng)特征,深度特征的語(yǔ)義信息豐富,特征表達(dá)能力更強(qiáng)。基于深度學(xué)習(xí)的船舶檢測(cè)技術(shù)在識(shí)別精度和速率上不斷獲得了提高,應(yīng)用也逐漸增多。Bian等[5]提出了以全景圖像為載體對(duì)船舶進(jìn)行檢測(cè),針對(duì)復(fù)雜的海洋環(huán)境,作者改進(jìn)了Canny邊緣檢測(cè)算法,先對(duì)海天線進(jìn)行了檢測(cè),再對(duì)海洋區(qū)域進(jìn)行了船舶檢測(cè),但是檢測(cè)的速度相對(duì)較慢。王嘯雨[6]采用了一種改進(jìn)的SSD算法檢測(cè)船舶,為了解決VGG16網(wǎng)絡(luò)提取出的特征不充分的問(wèn)題,使用語(yǔ)義信息更為豐富的Res-Net50深度殘差網(wǎng)絡(luò)替換了SSD原網(wǎng)絡(luò)中的VGG16網(wǎng)絡(luò)。此種方法雖然提高了船舶的檢測(cè)精度,但計(jì)算耗費(fèi)大、速度慢,依然具備改進(jìn)的空間。李輝[7]提出了一種基于Faster R-CNN的船舶檢測(cè)方法,為確保在大雨、濃霧等惡劣天氣下的檢測(cè)效果,將Faster R-CNN算法與基于天空區(qū)域分割的暗通道先驗(yàn)去霧算法進(jìn)行了結(jié)合,實(shí)現(xiàn)了對(duì)可疑船舶的監(jiān)控。該方法有效解決了惡劣天氣下的檢測(cè)問(wèn)題,但沒(méi)有實(shí)現(xiàn)實(shí)時(shí)性。Chen等[8]提出了一種基于海上監(jiān)視視頻的Gauss混合模型艦船目標(biāo)檢測(cè)算法,該算法減少了背景中雜波的影響,提高了艦船檢測(cè)的準(zhǔn)確率,但在誤檢率方面仍然具備改進(jìn)空間。夏婷等[9]提出了角點(diǎn)檢測(cè)與光流法,并通過(guò)背景補(bǔ)償對(duì)運(yùn)動(dòng)目標(biāo)進(jìn)行了檢測(cè)。Redmon等提出了YOLOv3算法,該算法是對(duì)YOLOv2[10]算法的一系列改進(jìn)。以Darknet-53[11]為特征提取網(wǎng)絡(luò)并在不同尺度上預(yù)測(cè)邊界框,具有較好的檢測(cè)效果與檢測(cè)速度,但其對(duì)復(fù)雜環(huán)境的視頻多目標(biāo)檢測(cè)同樣會(huì)出現(xiàn)誤檢和漏檢等問(wèn)題。
目 前,R-CNN[12]、 Fast R-CNN[13]、 Faster RCNN[14]、 SSD[15]、 YOLO(Yolo Only Look Once)[16]等算法較為主流。在單階段算法中,YOLOv3算法以其檢測(cè)精度高、識(shí)別速度快而聞名。YOLOv3算法是在YOLOv2算法的基礎(chǔ)上參考 ResNet[17]和 SSD的網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行的改進(jìn),其在性能上優(yōu)于SSD、YOLOv1、YOLOv2算法。與 R-CNN系列算法相比,YOLOv3算法物體識(shí)別的精確度和召回率低。因此,本文選用YOLOv3算法作為基礎(chǔ)網(wǎng)以進(jìn)行改進(jìn),在不引入較多參數(shù)的情況下以進(jìn)一步提高其檢測(cè)精度,用于船舶檢測(cè)。本文的工作主要包括以下幾點(diǎn):1)采用mixup方法對(duì)數(shù)據(jù)集進(jìn)行數(shù)據(jù)增強(qiáng);2)在Darknet-53骨干網(wǎng)絡(luò)提取出特征圖之后,引入了注意力機(jī)制;3)在測(cè)試時(shí)加入了顯著性檢測(cè),對(duì)低置信度目標(biāo)進(jìn)行了邊界框優(yōu)化。
1 基于YOLOv3的目標(biāo)檢測(cè)算法
YOLOv3算法是YOLO系列算法的進(jìn)階版本,如圖1所示。在骨干網(wǎng)絡(luò)上,YOLOv3算法采用Darknet-53網(wǎng)絡(luò)提取特征。Darknet-53由23個(gè)殘差結(jié)構(gòu)和5個(gè)下采樣組成,性能優(yōu)于Darknet-19,并且其沒(méi)有采用YOLOv2算法中的池化層,而是以卷積層進(jìn)行替代來(lái)達(dá)到下采樣的效果。在邊界框數(shù)量上,YOLOv2算法在每個(gè)grid cell上會(huì)預(yù)測(cè)5個(gè)邊界框,而YOLOv3算法則在每個(gè)grid cell上預(yù)測(cè)3個(gè)邊界框。在類(lèi)別預(yù)測(cè)上,YOLOv3算法已改進(jìn)為多標(biāo)簽分類(lèi)。這是因?yàn)樵谝恍?fù)雜場(chǎng)景中,一個(gè)目標(biāo)可能會(huì)對(duì)應(yīng)多個(gè)標(biāo)簽。例如,當(dāng)檢測(cè)類(lèi)別中包括貓、動(dòng)物兩個(gè)類(lèi)別時(shí),如果一張圖片中出現(xiàn)一只貓,則檢測(cè)結(jié)果中該目標(biāo)應(yīng)該包含貓和動(dòng)物兩個(gè)標(biāo)簽。在檢測(cè)層上,YOLOv3算法采用特征金字塔結(jié)構(gòu)(Feature Pyramid Networks,FPN)進(jìn)行多尺度融合,生成了3個(gè)特征圖,以對(duì)目標(biāo)進(jìn)行預(yù)測(cè)。在其他方面,YOLOv3算法則沿用了YOLOv2算法的做法。

圖1 YOLOv3算法的網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.1 Diagram of network structure based on YOLOv3
YOLOv3算法的網(wǎng)絡(luò)一共包含了107層:1)從0層開(kāi)始直至74層為Darknet-53,其包含了52個(gè)卷積層和23個(gè)殘差層。2)從75層至106層為yolo層,其總共3個(gè)尺度。小尺度yolo層輸出大小為13×13×S的特征圖;中尺度yolo層在85層進(jìn)行上采樣操作,并在86層進(jìn)行特征融合操作,將85層和61層的特征拼接在一起,可輸出大小為26×26×S的特征圖;大尺度yolo層在97層進(jìn)行上采樣操作,并在98層進(jìn)行特征融合操作,將97層和36層的特征拼接在一起,可輸出大小為52×52×S的特征圖。將3個(gè)尺度分別在82層、94層、106層進(jìn)行分類(lèi)和位置回歸。當(dāng)網(wǎng)絡(luò)過(guò)深時(shí),會(huì)丟失大量的圖片細(xì)節(jié)信息,采用3個(gè)尺度預(yù)測(cè)可以更好地檢測(cè)小目標(biāo)。其中,S的表達(dá)式如下

式(1)中,B為每個(gè)單元格預(yù)測(cè)的邊界框數(shù)量,C為類(lèi)別數(shù)。
2 船舶目標(biāo)檢測(cè)網(wǎng)絡(luò)模型
針對(duì)傳統(tǒng)檢測(cè)算法受復(fù)雜多變的海域環(huán)境條件影響而出現(xiàn)的魯棒性差、目標(biāo)識(shí)別能力不高的問(wèn)題,為了獲得對(duì)目標(biāo)更精確的檢測(cè)結(jié)果,本文對(duì)YOLOv3算法進(jìn)行了改進(jìn)。首先,采用mixup方法進(jìn)行了數(shù)據(jù)增強(qiáng);其次,在檢測(cè)層引入了注意力機(jī)制以加強(qiáng)特征;最后,在檢測(cè)時(shí)加入了顯著性檢測(cè),用以提高檢測(cè)精度。
2.1 mixup數(shù)據(jù)增強(qiáng)方法
mixup是一種數(shù)據(jù)增強(qiáng)方法,其采用對(duì)不同類(lèi)別進(jìn)行建模的方式實(shí)現(xiàn)數(shù)據(jù)增強(qiáng),而通用數(shù)據(jù)增強(qiáng)方法則是針對(duì)同一類(lèi)做出變換。mixup方法將兩張圖片通過(guò)不同的比例進(jìn)行融合,合并之后的圖像標(biāo)簽包含2張輸入圖像的所有標(biāo)簽,如圖2所示。

圖2 mixup圖像Fig.2 Images of mixup
本文通過(guò)mixup方法對(duì)VOC2007數(shù)據(jù)集進(jìn)行了數(shù)據(jù)增強(qiáng):第一步,從訓(xùn)練集中讀取一張圖片;第二步,隨機(jī)讀取另一張圖片并進(jìn)行resize處理,將其改成與第一張圖片相同的格式大小;第三步,對(duì)圖片進(jìn)行融合,融合比例為λ,將兩張圖片對(duì)應(yīng)的像素直接相加;第四步,將所有新生成的圖像與原數(shù)據(jù)集圖像合并在一起,組成增強(qiáng)后的數(shù)據(jù)集。mixup方法的計(jì)算公式如下

在式(2)、 式(3)中,λ為融合比例,xi、yi為第i個(gè)數(shù)據(jù)集圖像的橫縱坐標(biāo),xj、yj為第j個(gè)數(shù)據(jù)集圖像的橫縱坐標(biāo),為mixup數(shù)據(jù)增強(qiáng)后圖像的橫縱坐標(biāo)。
2.2 網(wǎng)絡(luò)模型改進(jìn)
YOLOv3算法是全卷積網(wǎng)絡(luò),包含75個(gè)卷積層,經(jīng)過(guò)了5次下采樣。隨著網(wǎng)絡(luò)的加深,特征的語(yǔ)義信息更加豐富,但是細(xì)節(jié)信息逐漸減少,可采用FPN進(jìn)行多尺度融合。本文引入了通道注意力機(jī)制和空間注意力機(jī)制,將其與FPN進(jìn)行了結(jié)合,選擇性地關(guān)注了所有有用的信息,而忽略了其他可見(jiàn)信息。
深層特征包含了全局上下文感知信息,適合定位突出信息正確的地區(qū)。淺層特征包含了空間結(jié)構(gòu)細(xì)節(jié),適合于邊界的定位。FPN可以將高級(jí)語(yǔ)義信息傳遞給淺層,但中間的許多上采樣層增加了很多噪音。因此,在進(jìn)行特征融合之前,在深層特征上添加了通道注意模塊,以獲取豐富的上下文信息,用于增強(qiáng)特征。對(duì)于淺層特征,本文采用空間注意模塊增加了對(duì)位置信息的關(guān)注。改進(jìn)模型的網(wǎng)絡(luò)模型結(jié)構(gòu)如圖3所示。
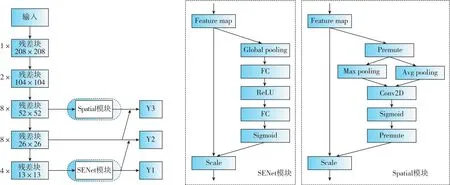
圖3 改進(jìn)模型的網(wǎng)絡(luò)模型結(jié)構(gòu)Fig.3 Network structure of improved model
圖3顯示,SENet模塊采用了通道注意力機(jī)制[18]。SENet模塊的核心思想是通過(guò)網(wǎng)絡(luò)并根據(jù)損失來(lái)學(xué)習(xí)特征權(quán)值,使有效的特征圖具有較大的權(quán)值,無(wú)效或效果較差的特征圖權(quán)重較小。如圖4所示,SENet模塊通過(guò)通道注意力機(jī)制為每個(gè)通道分配了權(quán)重:1)使用一個(gè)全局平均池化層將H×W×C特征圖壓縮成了1×1×C特征圖,擴(kuò)大了感受野;2)加入了兩個(gè)FC全連接層,建模通道間的相關(guān)性,并輸出和輸入特征同樣數(shù)目的權(quán)重;3)通過(guò)Sigmoid激活函數(shù)和Scale操作進(jìn)行歸一化和特征加權(quán)。
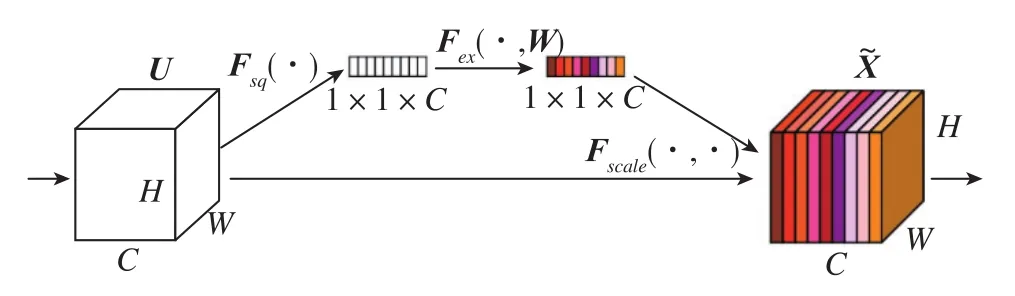
圖4 SENet模型結(jié)構(gòu)Fig.4 Model structure of SENet
在Spatial模塊上采用空間注意力機(jī)制[19]。如圖5所示,首先做一個(gè)基于通道的全局最大池化和全局平均池化,然后將這2個(gè)結(jié)果基于通道進(jìn)行融合;其次,經(jīng)過(guò)一個(gè)7×7的卷積層,生成單通道特征圖;之后,利用Sigmoid函數(shù)進(jìn)行歸一化;最后,通過(guò)Scale操作進(jìn)行特征加權(quán)。

圖5 空間注意力機(jī)制模塊Fig.5 Module of spatial attention mechanism
將經(jīng)過(guò)SENet模塊、Spatial模塊輸出的特征和從Darknet-53網(wǎng)絡(luò)中提取的尺度為26×26的特征進(jìn)行特征融合。如圖6中的 “Five convs”卷積塊所示,為了加強(qiáng)特征,在 “Five convs”卷積塊中引入了殘差連接,Predict模塊由3×3卷積層和1×1卷積層構(gòu)成。多尺度檢測(cè)步驟為:1)將從SENet模塊輸出的13×13×1024特征圖輸入改進(jìn)的FPN結(jié)構(gòu),即 ARFPN(Attention-Residual-FPN),經(jīng)過(guò)“Five convs”卷積塊提取特征,再經(jīng)過(guò)Predict模塊生成通道數(shù)為S的13×13尺度的特征圖;2)對(duì)層4進(jìn)行上采樣,先對(duì)層2進(jìn)行降維,再將兩者融合,經(jīng)過(guò) “Five convs”卷積塊和Predict模塊生成通道數(shù)為S的26×26尺度的特征圖;3)對(duì)層5進(jìn)行上采樣,并對(duì)從Spatial模塊輸出的特征圖進(jìn)行降維,再將兩者相加,經(jīng)過(guò) “Five convs”卷積塊和Predict模塊生成通道數(shù)為S的52×52尺度的特征圖。
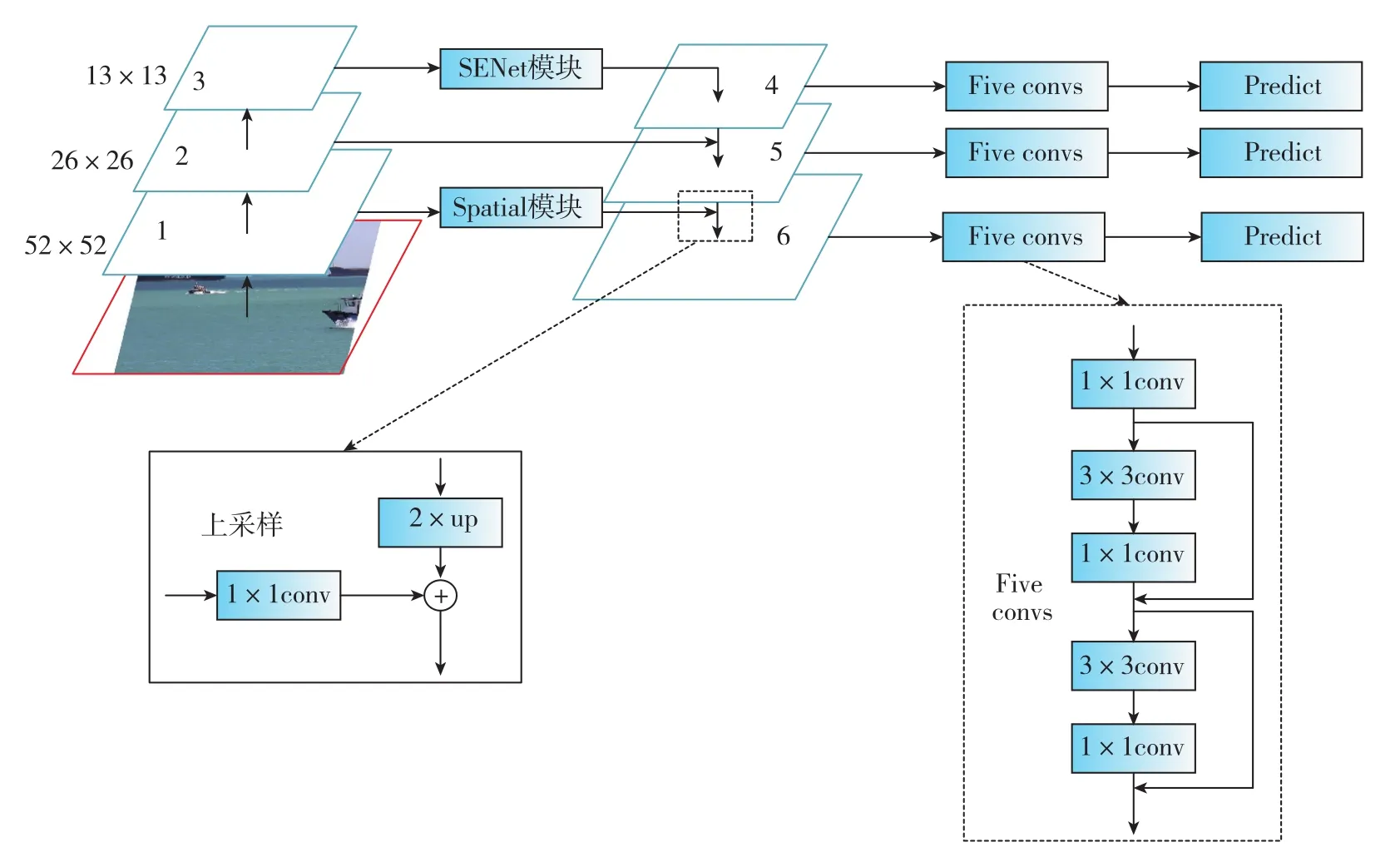
圖6 ARFPN結(jié)構(gòu)Fig.6 Structure of ARFPN
Liu等[20]提出了一種基于提議的實(shí)例分割框架下的路徑聚合網(wǎng)絡(luò)(PANet),通過(guò)自底向上的路徑增強(qiáng),利用準(zhǔn)確的低層定位信號(hào)增強(qiáng)了整個(gè)特征層次,從而縮短了低層與頂層特征之間的信息路徑。FPN結(jié)構(gòu)的主要工作原理為通過(guò)融合高低層特征提升目標(biāo)檢測(cè)的效果,FPN結(jié)構(gòu)尤其可以提高小尺寸目標(biāo)的檢測(cè)效果。自底向上路徑增強(qiáng)的引入主要考慮到了網(wǎng)絡(luò)淺層特征信息對(duì)于實(shí)例分割而言非常重要。自適應(yīng)特征池將單層特征轉(zhuǎn)換為多層特征,每個(gè)ROI需要和多層特征進(jìn)行ROI Align操作,隨后將得到的不同層的ROI特征融合在一起,得到最終特征。針對(duì)原有的分割支路(FCN),全連接融合引入了一個(gè)前背景二分類(lèi)的全連接支路,通過(guò)融合這兩條支路的輸出,可以得到更加精確的分割結(jié)果。YOLOv3算法輸出的13×13特征圖只包含了深層特征,難以通過(guò)其獲得準(zhǔn)確的定位信息。本文考慮到了網(wǎng)絡(luò)淺層特征信息的重要性,去掉了PANet網(wǎng)絡(luò)中自適應(yīng)特征池、回歸框分支和全連接融合等側(cè)重實(shí)例分割的結(jié)構(gòu),在改進(jìn)的FPN結(jié)構(gòu)之后引入了PANet網(wǎng)絡(luò)中的自底向上的路徑增強(qiáng),如圖7所示,即ARPAN(Attention-Residual-PANet)。
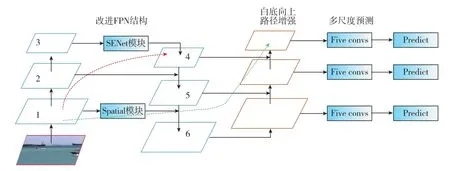
圖7 ARPAN網(wǎng)絡(luò)結(jié)構(gòu)Fig.7 Network structure of ARPAN
2.3 損失函數(shù)改進(jìn)
YOLOv3算法中的損失函數(shù)包括分類(lèi)損失、定位損失和置信度損失[21]。在 YOLOv3算法中,使用預(yù)測(cè)值與真實(shí)值之間的誤差平方和來(lái)計(jì)算定位損失。但在進(jìn)行檢測(cè)結(jié)果指標(biāo)評(píng)測(cè)時(shí),使用IOU來(lái)判斷目標(biāo)是否被正確檢測(cè)。故在YOLOv3算法中,定位損失大小與IOU大小不是絕對(duì)的負(fù)相關(guān)關(guān)系。如果使用IOU[22]作為損失函數(shù)又會(huì)出現(xiàn)以下問(wèn)題:1)出現(xiàn)預(yù)測(cè)框和真實(shí)框不重疊情況時(shí),IOU一直為0,無(wú)法通過(guò)梯度優(yōu)化網(wǎng)絡(luò);2)如圖8所示,當(dāng)IOU相交時(shí),即便IOU值確定,也不能反映兩個(gè)框是如何相交的。
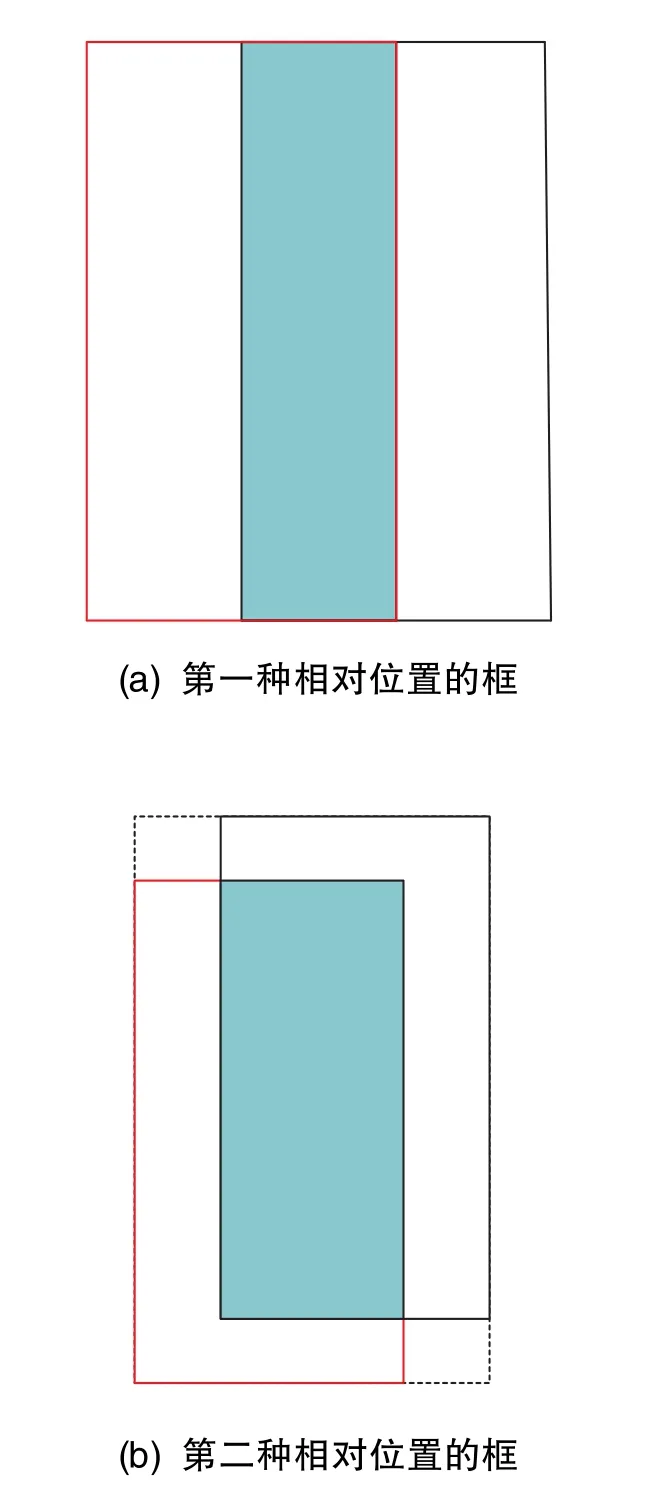
圖8 相同IOU=0.33時(shí)兩種不同相對(duì)位置的框Fig.8 Two boxes in different relative positions when IOU is 0.33
一個(gè)好的目標(biāo)框回歸損失應(yīng)考慮以下三個(gè)幾何因素:重疊面積、中心點(diǎn)距離和長(zhǎng)寬比,因此本文采用 CIOU[23]替代 IOU作為定位損失函數(shù)。CIOU損失函數(shù)能夠最小化預(yù)測(cè)框與真實(shí)框之間的中心點(diǎn)距離,從而使得函數(shù)快速收斂。另外,CIOU考慮了長(zhǎng)寬比對(duì)邊界框回歸的影響,因此加入了懲罰項(xiàng)用于對(duì)長(zhǎng)寬比進(jìn)行考量。對(duì)于預(yù)測(cè)框A和真實(shí)框B,CIOU的計(jì)算公式如下
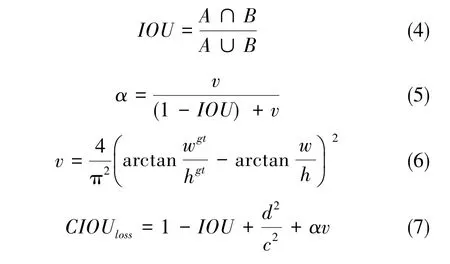
在式(4)~式(7)中,IOU為預(yù)測(cè)框 A 和真實(shí)框B的交并比,α為正樣本權(quán)衡參數(shù),v為用來(lái)衡量寬高比的一致性參數(shù),wgt、hgt分別為真實(shí)框的寬和高,w、h分別為預(yù)測(cè)框的寬和高,d為預(yù)測(cè)框和真實(shí)框中心點(diǎn)之間的直線距離;c為預(yù)測(cè)框和真實(shí)框的最小外包圍框的對(duì)角線距離。
2.4 顯著性檢測(cè)
YOLOv3算法通過(guò)訓(xùn)練出的網(wǎng)絡(luò)模型對(duì)圖片進(jìn)行檢測(cè),檢測(cè)出的置信度評(píng)分是判斷邊界框是否可用的依據(jù)。通常,當(dāng)IOU大于0.5時(shí),認(rèn)為該邊界框是可用的;當(dāng)IOU小于0.5時(shí),則認(rèn)為該邊界框不可取。為了進(jìn)一步提高檢測(cè)效果,在檢測(cè)時(shí)可結(jié)合顯著性檢測(cè)技術(shù)[24]來(lái)修正低置信度(即IOU小于0.5)的目標(biāo)位置。
對(duì)于低置信度的邊界框應(yīng)進(jìn)行如下的修正:1)選出低置信度的目標(biāo)邊界框;2)以其中置信度大于0.2的邊界框的1.25倍范圍作為顯著性檢測(cè)的區(qū)域;3)使用顯著性檢測(cè)FT算法生成顯著性圖;4)將顯著性值突出區(qū)域的外矩形包圍區(qū)域作為最終的目標(biāo)位置。如圖9所示,紅色框內(nèi)為改進(jìn)YOLOv3算法模型的訓(xùn)練流程,藍(lán)色框內(nèi)為檢測(cè)流程。

圖9 改進(jìn)YOLOv3算法模型的訓(xùn)練和檢測(cè)流程圖Fig.9 Training and testing flowchart of improved YOLOv3 model
3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集及訓(xùn)練過(guò)程
本文分別在VOC2007數(shù)據(jù)集和自建船舶數(shù)據(jù)集上進(jìn)行了測(cè)試。VOC2007數(shù)據(jù)集包含了20個(gè)目標(biāo)類(lèi)別。其中,訓(xùn)練集有5011張,測(cè)試集有4952張。在本文自建的船舶數(shù)據(jù)集中,原始圖片中的一部分為從VOC2007和VOC2012數(shù)據(jù)集中提取出的船舶圖片,另一部分圖片為從7個(gè)在岸上拍攝的新加坡船舶視頻和從7個(gè)在船上拍攝的新加坡船舶視頻中每隔20幀提取一張視頻圖片進(jìn)行手工標(biāo)注而獲得。通過(guò)旋轉(zhuǎn)、添加噪聲及改變亮度,一共獲得了訓(xùn)練集圖片4708張、測(cè)試集圖片708張,訓(xùn)練時(shí)間為16h。
在進(jìn)行模型訓(xùn)練時(shí),從訓(xùn)練集中劃出十分之一作為驗(yàn)證圖片,劃出十分之九作為訓(xùn)練圖片。將訓(xùn)練劃分為2個(gè)階段:第1個(gè)階段凍結(jié)網(wǎng)絡(luò)的前185層,訓(xùn)練50個(gè)epoch,學(xué)習(xí)率為1×10-3;第2個(gè)階段解凍全部網(wǎng)絡(luò),訓(xùn)練到網(wǎng)絡(luò)自動(dòng)停止,初始學(xué)習(xí)率設(shè)為1×10-4。如果每3個(gè)epoch的驗(yàn)證損失不下降,學(xué)習(xí)率將變?yōu)樵瓉?lái)的十分之一;如果每10個(gè)epoch的驗(yàn)證損失不下降,則停止訓(xùn)練。
3.2 VOC2007數(shù)據(jù)集測(cè)試結(jié)果與分析
本文在Spyder中使用python3.6進(jìn)行了算法編程,深度學(xué)習(xí)框架為 tensorflow-GPU1.13.1、Keras2.1.5,實(shí)驗(yàn)平臺(tái)使用的是 Ubuntu16.04系統(tǒng)、i7-8750H CPU@2.20GHz×12處理器、15.5GiB內(nèi)存,GeForce GTX 1060 6G顯卡用于加速卷積神經(jīng)網(wǎng)絡(luò)模型的訓(xùn)練過(guò)程。
表1顯示了本文改進(jìn)算法與原YOLOv3算法的網(wǎng)絡(luò)訓(xùn)練參數(shù)量。YOLOv3-base為原YOLOv3算法的網(wǎng)絡(luò)模型,YOLOv3-ARFPN和YOLOv3-ARPAN為本文對(duì)YOLOv3網(wǎng)絡(luò)進(jìn)行改進(jìn)的兩種網(wǎng)絡(luò)模型。YOLOv3算法的網(wǎng)絡(luò)總參數(shù)為61576342個(gè),本文改進(jìn)算法YOLOv3-ARFPN的網(wǎng)絡(luò)總參數(shù)為62100728個(gè),比YOLOv3算法增加了524386個(gè)參數(shù),參數(shù)增加約 0.85%;改進(jìn)算法 YOLOv3-ARPAN由于額外增加了18個(gè)卷積層,故網(wǎng)絡(luò)總參數(shù)為 77445880個(gè),比 YOLOv3算法增加了l5869538個(gè)參數(shù),參數(shù)增加約25.77%。

表1 本文算法與YOLOv3算法的網(wǎng)絡(luò)訓(xùn)練參數(shù)量Table 1 Network training parameters of the algorithm in this paper and the YOLOv3 algorithm
可使用VOC2007數(shù)據(jù)集中的測(cè)試集來(lái)驗(yàn)證本文方法的檢測(cè)效果。mAP為平均準(zhǔn)確率均值,ΔmAP為改進(jìn)算法與YOLOv3算法的平均準(zhǔn)確率均值的差值,FPS為每秒檢測(cè)圖片的幀數(shù)。如表2所示,本文改進(jìn)算法相比原YOLOv3算法獲得了很大提升,本文改進(jìn)的ARPAN網(wǎng)絡(luò)模型與mixup數(shù)據(jù)增強(qiáng)、CIOU損失函數(shù)、顯著性檢測(cè)相結(jié)合而組成的YOLOv3-mixup-ARPAN-CIOU-Ft算法提升最大,mAP值提高了11.25%。

表2 各種模型在VOC2007測(cè)試集上的mAP值和FPSTable 2 mAP and FPS of various models on VOC2007 test set
在考慮衡量精度與速度的前提下,本文改進(jìn)的ARFPN網(wǎng)絡(luò)模型與mixup數(shù)據(jù)增強(qiáng)、顯著性檢測(cè)相結(jié)合而組成的YOLOv3-mixup-ARPAN-Ft算法效果更好,mAP值提高了11.16%,FPS減少了1.52幀/s。接下來(lái),對(duì)YOLOv3算法與YOLOv3-mixup-ARPANFt算法進(jìn)行對(duì)比分析。圖10(a)顯示了原YOLOv3算法在VOC2007測(cè)試集上的mAP計(jì)算結(jié)果,圖10(b)顯示了本文改進(jìn)的YOLOv3-mixup-ARFPN-Ft算法在VOC2007測(cè)試集上的mAP計(jì)算結(jié)果。從圖10可以看出,在20個(gè)類(lèi)別中,本文算法對(duì) “椅子”的檢測(cè)效果提升最高,相比YOLOv3算法的AP值提高了16%;在20個(gè)類(lèi)別中,本文算法對(duì) “火車(chē)”的檢測(cè)效果提升最小,但也提高了3%。在20個(gè)類(lèi)別的平均準(zhǔn)確率均值(mAP)方面,本文算法相比YOLOv3算法提高了11.16%。
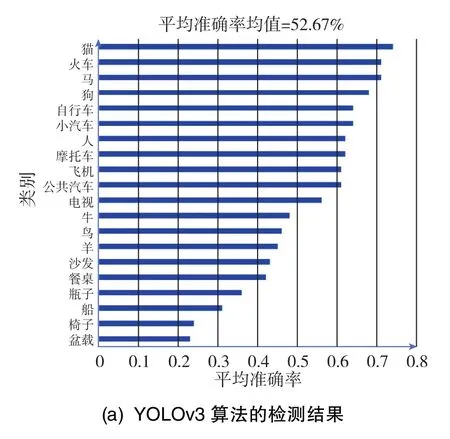

圖10 YOLOv3算法及本文算法在VOC2007上的mAP值Fig.10 mAP of the algorithm in this paper and the YOLOv3 algorithm on VOC2007 test set
圖11為YOLOv3算法與本文各種改進(jìn)模型在VOC2007測(cè)試集上的20種類(lèi)別對(duì)應(yīng)的平均準(zhǔn)確率(AP)的折線圖。從圖11可以看出,在算法2~算法4(對(duì)應(yīng)表2)中,大多數(shù)類(lèi)別的平均準(zhǔn)確率均高于YOLOv3算法。特別地,沙發(fā)、羊、鳥(niǎo)和牛這4個(gè)類(lèi)別的平均準(zhǔn)確率的提升幅度比較大。
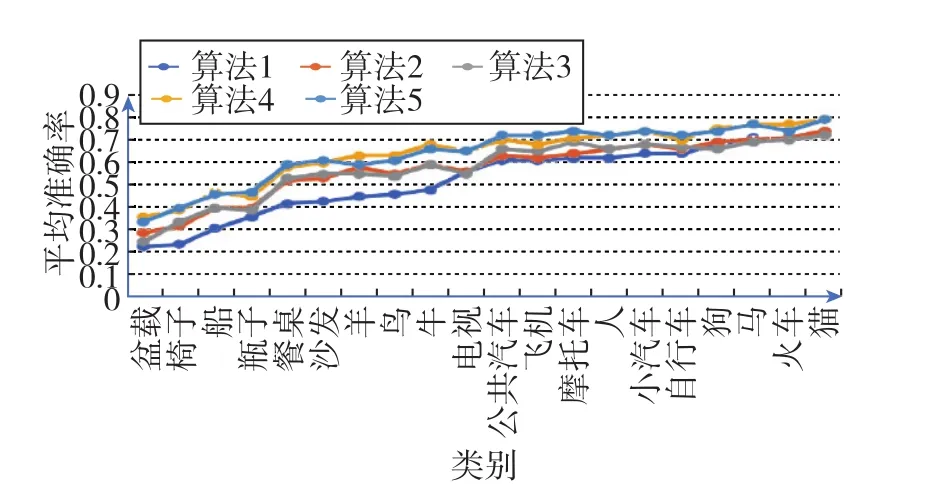
圖11 各種算法在VOC2007測(cè)試集上的平均準(zhǔn)確率Fig.11 Average precision of various algorithms on VOC2007 test set
表2中的算法4在檢測(cè)速度下降較少的前提下,平均準(zhǔn)確率提升較高,因此可結(jié)合圖片對(duì)該算法與原 YOLOv3算法進(jìn)行對(duì)比分析,圖12~圖16為VOC2007數(shù)據(jù)集中的部分測(cè)試圖片。圖12為在本文改進(jìn)算法中算法4與 YOLOv3算法在VOC2007數(shù)據(jù)集上的圖片檢測(cè)結(jié)果。其中,藍(lán)色框?yàn)槟繕?biāo)正確檢測(cè)到的真實(shí)框(GT),綠色框?yàn)槟繕?biāo)正確檢測(cè)到的預(yù)測(cè)框(TP),紅色框?yàn)檎`檢預(yù)測(cè)框(FP),粉色框?yàn)槁z真實(shí)框(FN)。YOLOv3算法只正確檢測(cè)出了一個(gè)目標(biāo),而狗沒(méi)有被檢測(cè)出來(lái);相比之下,本文算法可正確檢測(cè)出人和狗兩個(gè)目標(biāo)。在圖13中,YOLOv3算法漏檢了2個(gè)車(chē)輛以及屏幕中的3個(gè)人;本文算法未檢測(cè)出屏幕中的2個(gè)人,但將其他目標(biāo)全部正確檢測(cè)了出來(lái)。在圖14和圖15中,YOLOv3算法分別出現(xiàn)了對(duì)船和狗的漏檢,而本文算法正確檢測(cè)出了船和狗。在圖16中,YOLOv3算法未檢測(cè)出右邊沙發(fā)上方和旁邊的花盆以及最左邊的沙發(fā);本文算法檢測(cè)出了右邊沙發(fā)上方的花盆,但未檢測(cè)出右邊沙發(fā)旁邊的花盆。左邊沙發(fā)檢測(cè)框的IOU小于0.5,故可判斷為漏檢。由以上分析可以看出,本文算法較YOLOv3算法取得了一定程度的提高。

圖12 測(cè)試圖片1的檢測(cè)結(jié)果對(duì)比Fig.12 Detection result comparisons of test image 1

圖13 測(cè)試圖片2的檢測(cè)結(jié)果對(duì)比Fig.13 Detection result comparisons of test image 2

圖14 測(cè)試圖片3的檢測(cè)結(jié)果對(duì)比Fig.14 Detection result comparisons of test image 3
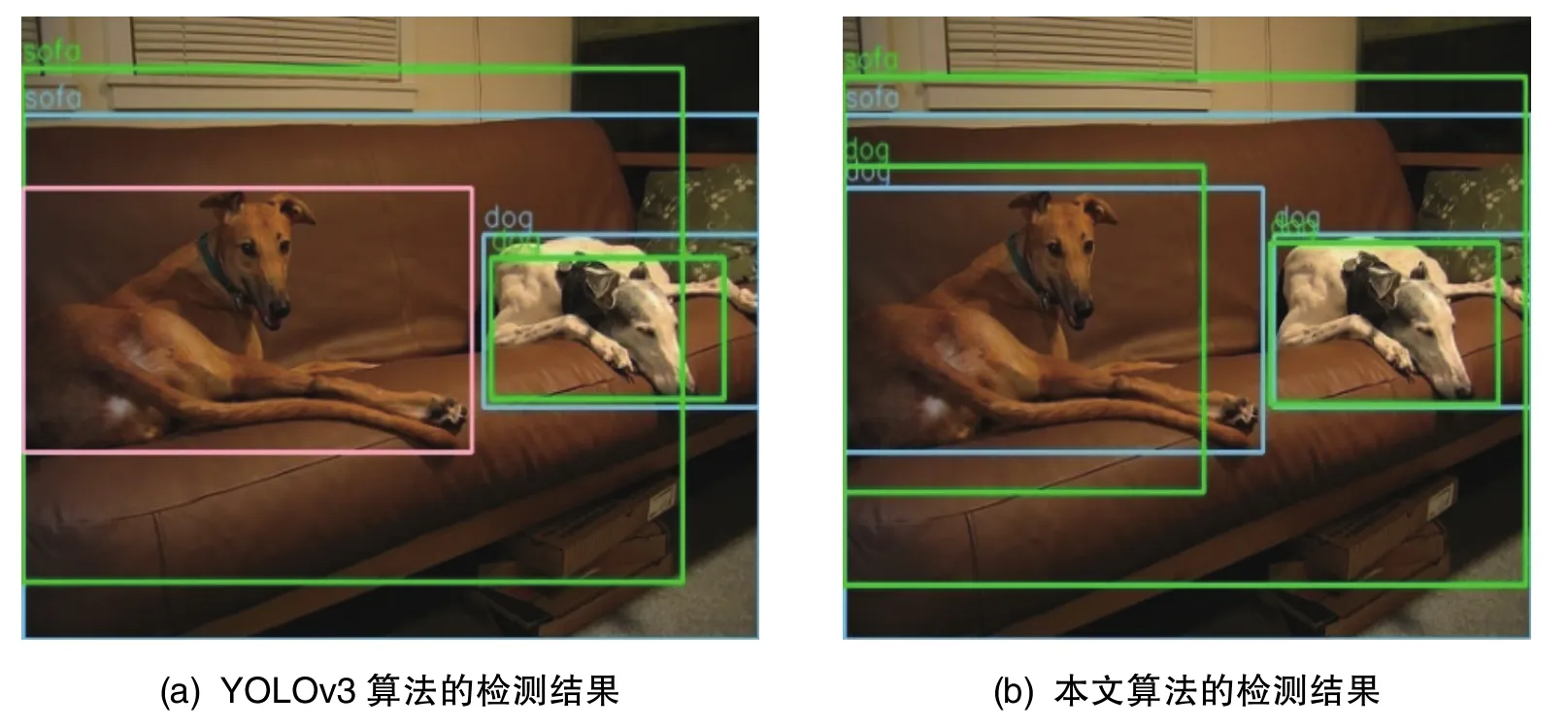
圖15 測(cè)試圖片4的檢測(cè)結(jié)果對(duì)比Fig.15 Detection result comparisons of test image 4

圖16 測(cè)試圖片5的檢測(cè)結(jié)果對(duì)比Fig.16 Detection result comparisons of test image 5
3.3 自建船舶數(shù)據(jù)集測(cè)試結(jié)果與分析
表3顯示了YOLOv3算法與本文算法在自建船舶數(shù)據(jù)集上的測(cè)試結(jié)果。YOLOv3-base為原YOLOv3算法的網(wǎng)絡(luò)模型,其在測(cè)試集上的AP值為83.76%;YOLOv3-ARFPN為在YOLOv3網(wǎng)絡(luò)中引入通道注意力機(jī)制、空間注意力機(jī)制以及在FPN中使用殘差結(jié)構(gòu)的模型,其在測(cè)試集上的AP值為88.37%;YOLOv3-ARFPN-Ft為在YOLOv3-ARFPN進(jìn)行測(cè)試過(guò)程中對(duì)低置信度目標(biāo)進(jìn)行顯著性檢測(cè)的算法,其在測(cè)試集上的AP值為90.29%,與原YOLOv3算法相比,AP值提高了6.53%。增加顯著性檢測(cè)可以適當(dāng)?shù)靥岣叽皺z測(cè)的準(zhǔn)確率,但是也會(huì)降低檢測(cè)速度。由表3可知,YOLOv3-mixup-ARPAN-CIOU-Ft的 AP值最高,為 91.41%,相比YOLOv3算法提高了7.65%。mixup數(shù)據(jù)增強(qiáng)和CIOU損失函數(shù)均可以同時(shí)提高準(zhǔn)確率(Precision)和召回率(Recall), 而 ARFPN、 ARPAN 和 Ft(顯著性檢測(cè))在提高召回率的同時(shí),卻會(huì)降低準(zhǔn)確率。
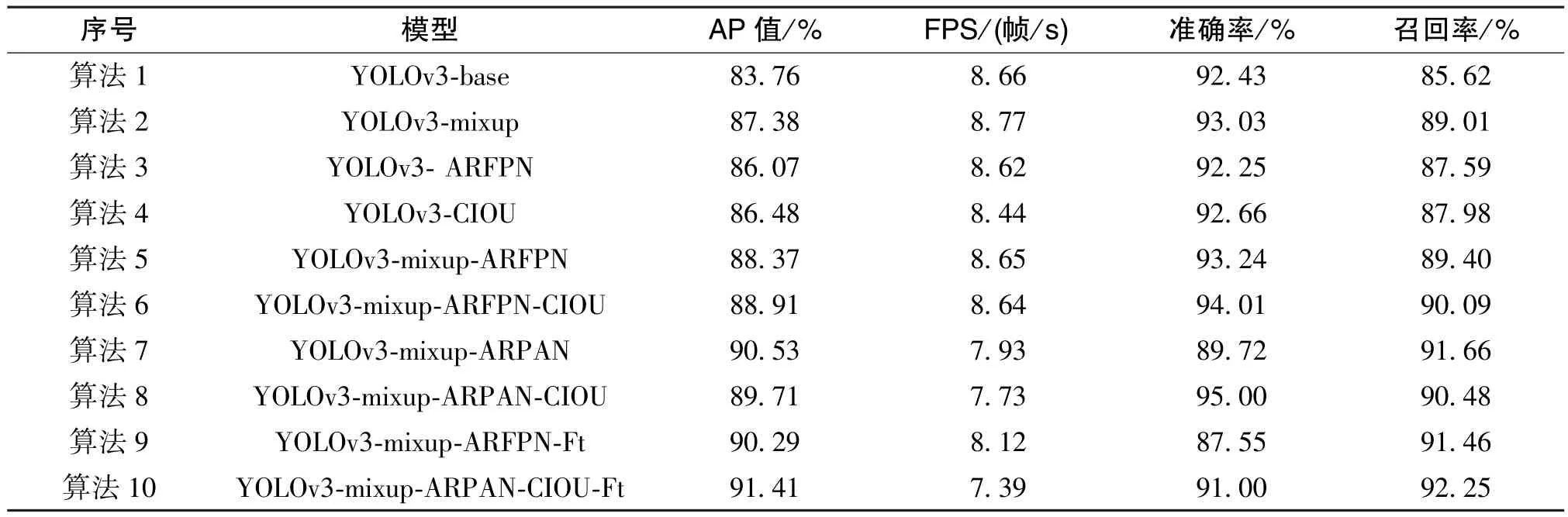
表3 YOLOv3算法和改進(jìn)模型在自建船舶數(shù)據(jù)集上的對(duì)比Table 3 Comparison of YOLOv3 and the improved model on self-built ship data set
TP為正樣本被正確檢測(cè)出船舶的數(shù)量,FP為負(fù)樣本被誤檢為船舶的數(shù)量,ΔTP為本文算法與YOLOv3算法的 TP差值,ΔFP為本文算法與YOLOv3算法的FP差值。ΔTP越大、ΔFP越小,算法的檢測(cè)效果越好。表4顯示了YOLOv3算法與本文算法在自建船舶數(shù)據(jù)集上計(jì)算出的TP、FP結(jié)果。由表4可知,YOLOv3-mixup-ARPAN-CIOU-Ft算法的TP提升最多,比YOLOv3算法的TP提高了135,YOLOv3-mixup-ARPAN-CIOU算法的FP相比YOLOv3算法降低了46。

表4 自建船舶數(shù)據(jù)集的TP、FP值Table 4 Values of TP and FP on self-built ship data set

圖17 測(cè)試圖片6的檢測(cè)結(jié)果對(duì)比Fig.17 Detection result comparisons of test image 6
由表3、表4可知,從準(zhǔn)確率、召回率、平均準(zhǔn)確率和誤檢等多個(gè)指標(biāo)考慮,算法9的表現(xiàn)更好,在上述幾個(gè)指標(biāo)上均實(shí)現(xiàn)了較大程度的提高。圖17~圖22展示了部分本文改進(jìn)算法中算法9與YOLOv3算法在自建船舶數(shù)據(jù)集上的檢測(cè)結(jié)果。其中,藍(lán)色框?yàn)槟繕?biāo)正確檢測(cè)到的真實(shí)框(GT),綠色框?yàn)槟繕?biāo)正確檢測(cè)到的預(yù)測(cè)框(TP),紅色框?yàn)檎`檢預(yù)測(cè)框(FP),粉色框?yàn)槁z真實(shí)框(FN)。由圖17~圖19可知,YOLOv3算法的檢測(cè)存在漏檢船只,而本文算法可實(shí)現(xiàn)全部的正確檢測(cè)。由圖20~圖22可知,YOLOv3算法出現(xiàn)了漏檢和誤檢船只,而本文改進(jìn)算法在這幾張圖片中均可實(shí)現(xiàn)正確的檢測(cè)。如圖23中的PR曲線所示,本文算法在自建船舶測(cè)試集上的平均準(zhǔn)確率相比YOLOv3算法提高了6.53%。綜上所述,在船舶的檢測(cè)方面,本文算法相比YOLOv3算法獲得了較大程度的提高。

圖18 測(cè)試圖片7的檢測(cè)結(jié)果對(duì)比Fig.18 Detection result comparisons of test image 7
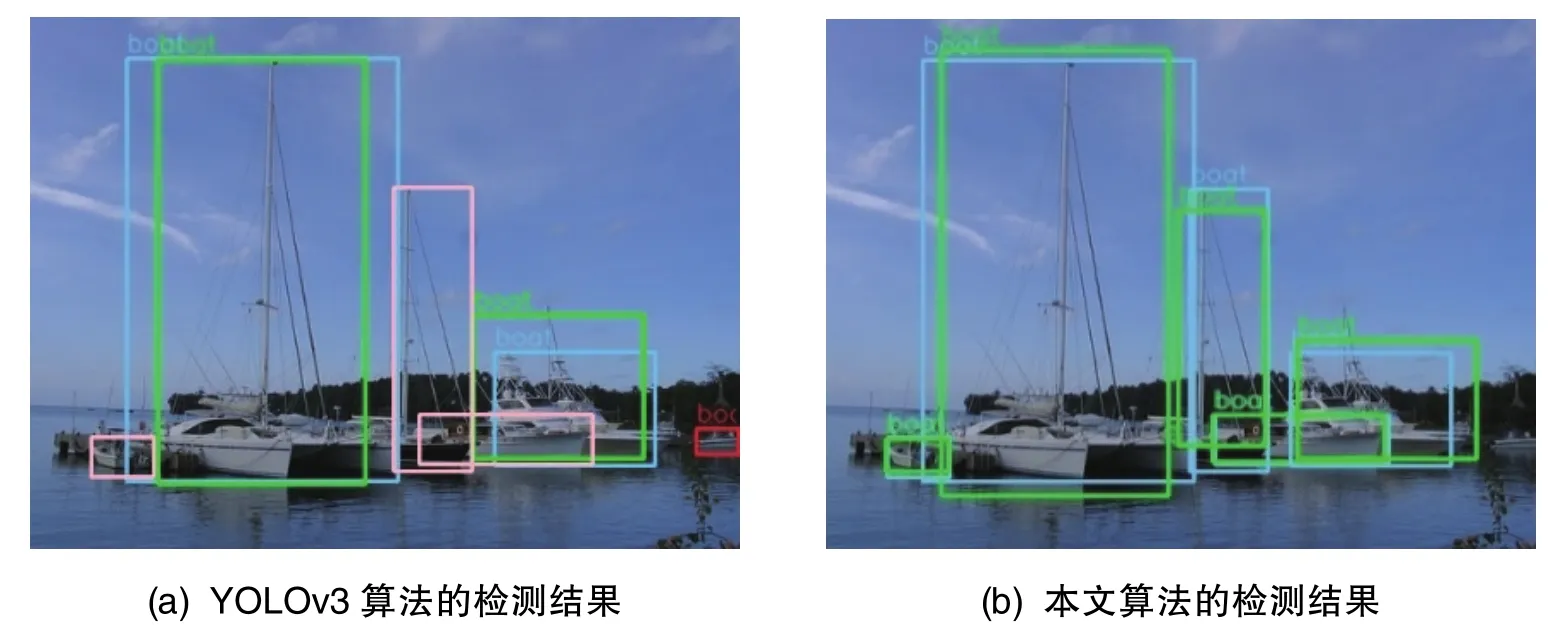
圖19 測(cè)試圖片8的檢測(cè)結(jié)果對(duì)比Fig.19 Detection result comparisons of test image 8

圖20 測(cè)試圖片9的檢測(cè)結(jié)果對(duì)比Fig.20 Detection result comparisons of test image 9

圖21 測(cè)試圖片10的檢測(cè)結(jié)果對(duì)比Fig.21 Detection result comparisons of test image 10

圖22 測(cè)試圖片11的檢測(cè)結(jié)果對(duì)比Fig.22 Detection result comparisons of test image 11

圖23 YOLOv3算法與本文算法在測(cè)試集上的PR曲線對(duì)比結(jié)果Fig.23 Comparison results of the PR curve between the YOLOv3 algorithm and the algorithm in this paper on test set
4 結(jié)論
本文首先通過(guò)mixup方法進(jìn)行了數(shù)據(jù)增強(qiáng),然后通過(guò)Darknet-53主干網(wǎng)絡(luò)提取了船舶特征,引入了注意力機(jī)制過(guò)濾噪聲,將殘差連接與特征金字塔融合進(jìn)行了結(jié)合,并在特征金字塔上引入了自底向上的路徑增強(qiáng),實(shí)現(xiàn)了對(duì)船舶的檢測(cè),最后通過(guò)顯著性檢測(cè)對(duì)低置信度的目標(biāo)框位置進(jìn)行了修正。實(shí)驗(yàn)結(jié)果表明,改進(jìn)算法與YOLOv3算法相比,在網(wǎng)絡(luò)參數(shù)增加較少的前提下,有效提升了船舶檢測(cè)的精確度和魯棒性。但是,本文目前僅將各類(lèi)船舶作為同一個(gè)類(lèi)別進(jìn)行了檢測(cè),未對(duì)船舶進(jìn)行詳細(xì)分類(lèi),故下一步還需對(duì)船舶進(jìn)行更詳細(xì)的分類(lèi),以實(shí)現(xiàn)海上船舶檢測(cè)。
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:07:40
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
船舶(2021年4期)2021-09-07 17:32:22
小哥白尼(趣味科學(xué))(2019年10期)2020-01-18 09:16:22
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
