基于遷移學(xué)習(xí)的機場場面目標檢測與跟蹤技術(shù)研究
2021-06-28 12:23:54李彥冬夏正洪
電子測試 2021年2期
李彥冬,夏正洪
(中國民用航空飛行學(xué)院,四川廣漢,618300)
0 引言
機場場面監(jiān)視是民航安全運行中的重要一環(huán),一直以來都是民航關(guān)注的一個重要問題。傳統(tǒng)的機場場面監(jiān)視主要利用場監(jiān)雷達和多點定位等基于電磁波的技術(shù)手段對場面目標的位置和身份進行識別。這種方式對于目標的位置信息能夠較好地進行判斷,然而對于目標的類型,尤其是一些非合作目標的身份,缺少魯棒的判斷能力。
從2012年開始,深度學(xué)習(xí)技術(shù)逐漸成為人工智能領(lǐng)域的一個研究熱點[1]。近年來,針對深度學(xué)習(xí)技術(shù)的研究在圖像理解、語音識別、自然語言處理、圍棋對弈、自動駕駛等領(lǐng)域都取得了超越傳統(tǒng)方法的突破性成果[2]。深度學(xué)習(xí)技術(shù)是一種以數(shù)據(jù)驅(qū)動的機器學(xué)習(xí)方法,可以通過大量的數(shù)據(jù)對機器學(xué)習(xí)模型進行訓(xùn)練,從而讓模型獲得對于數(shù)據(jù)模式的識別能力。然而,在很多實際的應(yīng)用場景中,數(shù)據(jù)的獲取比較困難,小樣本環(huán)境是深度學(xué)習(xí)技術(shù)在實際應(yīng)用中通常會遇到的問題,遷移學(xué)習(xí)技術(shù)是解決小樣本問題的方式之一[3]。
本文以深度學(xué)習(xí)技術(shù)為研究對象,在模型訓(xùn)練數(shù)據(jù)不足的情況下,采用遷移學(xué)習(xí)的策略研究對于機場場面目標的視頻識別與跟蹤方法。實驗結(jié)果表明,基于遷移學(xué)習(xí)的策略,本文中的深度學(xué)習(xí)模型對于場面中的目標具有較好的檢測與識別能力。
1 基于深度學(xué)習(xí)技術(shù)的目標檢測
目標檢測是計算機視覺領(lǐng)域的一個基礎(chǔ)而重要的問題,其研究目標是從圖像或視頻場景中準確定位潛在物體的位置,并且對目標物體的類別進行準確的識別。傳統(tǒng)的目標檢測算法主要通過從圖像中提取大量的潛在目標框,然后對各個框圖內(nèi)的目標進行特征提取與識別。這種識別方式的缺陷有兩點:(1)通常圖像目標框的數(shù)量會比較龐大,逐個處理會影響目標檢測的速度;(2)傳統(tǒng)方法采用人工設(shè)計特征(如:LBP, SIFT等)對目標框的特征進行提取,這些特征通常具有較弱的判別和泛化性能。
深度學(xué)習(xí)是近年來興起的一種機器學(xué)習(xí)方法,其主要特點是對于目標特征的提取不再基于人工設(shè)計特征,而是基于層層相連的深度數(shù)學(xué)模型。通過大量數(shù)據(jù)的的訓(xùn)練,原本參數(shù)隨機初始化的深度網(wǎng)絡(luò)能夠?qū)W習(xí)到數(shù)據(jù)中潛在的特征,從而完成特征的提取。眾多研究表明,這種通過學(xué)習(xí)方式獲得的目標特征相比于傳統(tǒng)的人工設(shè)計特征具有更好的表達能力。深度學(xué)習(xí)模型作為一種數(shù)據(jù)驅(qū)動的數(shù)學(xué)模型,對數(shù)據(jù)量的要求比較高,因此,對于一些數(shù)據(jù)量相對有限的特定應(yīng)用場景,通常采用遷移學(xué)習(xí)的策略。遷移學(xué)習(xí)的思路是先通過在大型數(shù)據(jù)集上對深度學(xué)習(xí)模型進行訓(xùn)練,讓模型的訓(xùn)練誤差達到收斂,確定模型中的參數(shù)值,然后通過針對特定小樣本數(shù)據(jù)集的訓(xùn)練,對模型參數(shù)進行微調(diào)更新,從而讓模型對于小樣本數(shù)據(jù)集具有特征提取與判別的能力。通過遷移學(xué)習(xí)策略,解決了小樣本數(shù)據(jù)集對于深度模型的訓(xùn)練支持不足的問題,有效地擴展了深度學(xué)習(xí)技術(shù)在特定場景的應(yīng)用。
2 基于遷移學(xué)習(xí)的場面目標檢測
針對機場場面視頻數(shù)據(jù)集相對環(huán)境比較單一,訓(xùn)練樣本較少的特點,本文利用基于遷移學(xué)習(xí)的場面目標檢測模型訓(xùn)練方案進行面向場面目標的檢測模型訓(xùn)練(如圖1所示)。該方案主要分為:構(gòu)建深度學(xué)習(xí)模型、構(gòu)建訓(xùn)練數(shù)據(jù)集和模型訓(xùn)練三個主要部分。

圖1 基于遷移學(xué)習(xí)的場面目標檢測模型訓(xùn)練方案
2.1 構(gòu)建深度學(xué)習(xí)模型
目標檢測的深度學(xué)習(xí)模型主要分為精度較高的兩階段模型和速度較快的一階段模型兩個大類。針對場面目標檢測的實時性需求,本文選擇了一階段代表性的YOLO模型作為目標檢測模型進行研究。YOLO是一種端到端的目標檢測模型,針對原始圖像通過骨干卷積網(wǎng)絡(luò)提取特征,然后通過設(shè)計的Neck結(jié)構(gòu)對于特征在多尺度上進行融合,最終在輸出層通過非最大抑制(Non-Maximum Suppresion, NMS)的策略進行檢測框的生成。YOLO模型具有輕量級,運行速度快的特點,在通用數(shù)據(jù)集的測試上也具有一定的目標識別準確度。
2.2 訓(xùn)練數(shù)據(jù)集
在訓(xùn)練數(shù)據(jù)集方面,本文采用了通用的目標檢測數(shù)據(jù)集MSCOCO和實地采集的廣漢機場視頻圖像數(shù)據(jù)集。
MSCOCO數(shù)據(jù)集在目標檢測領(lǐng)域是一個應(yīng)用廣泛的數(shù)據(jù)集,其包含了91個目標類別,超過10萬張用于訓(xùn)練和測試的圖片,對于大型深度網(wǎng)絡(luò)來說是一個常用的數(shù)據(jù)集。但是,由于機場場面的運行具有其具體特點,因此針對機場實地采集數(shù)據(jù),也進行了相應(yīng)的目標標注用于訓(xùn)練。圖2是人工標注的一個樣本圖像。其中,行人以標簽0作為標記,飛機以標簽4作為標記。

圖2 廣漢機場視頻圖像人工標注(4:飛機,0:行人)
2.3 訓(xùn)練模型
在實際的模型訓(xùn)練中,針對輸入圖像X,首先通過目標檢測模型完成網(wǎng)絡(luò)的前向傳導(dǎo):

公式(1)中,f(x)是基于網(wǎng)絡(luò)模型參數(shù)(W, b)的目標檢測模型。模型初始化參數(shù)隨機,通過前向傳導(dǎo)之后,獲得潛在的目標檢測結(jié)果H = [H1, H2, ..., Hn]。目標檢測結(jié)果與數(shù)據(jù)集標簽之間的差異,作為訓(xùn)練的損失E(W, b):

對于損失E(W,b),通過梯度下降方法(Stochastic Gradient Descent,SGD)對網(wǎng)絡(luò)參數(shù)(W,B)進行更新:
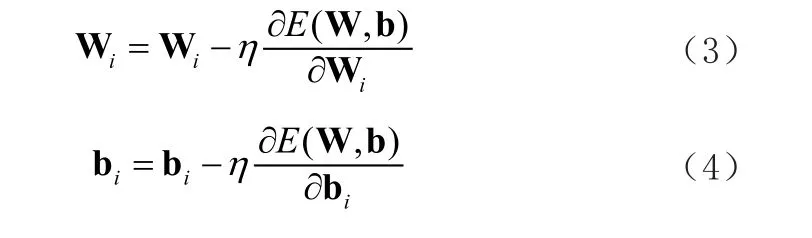
經(jīng)過訓(xùn)練后的網(wǎng)絡(luò)f(W, b)通過更新網(wǎng)絡(luò)的參數(shù),能夠擬合訓(xùn)練數(shù)據(jù)集的特點,從而具備目標檢測的能力。
本文中采用的MSCOCO數(shù)據(jù)集尺度比較大,具有良好的模型參數(shù)訓(xùn)練功能,但是不具備針對特定場景的目標檢測標記。因此,在實際訓(xùn)練過程中,先使用MSCOCO數(shù)據(jù)集對參數(shù)訓(xùn)練到收斂,然后使用人工標注的廣漢機場數(shù)據(jù)集進行遷移訓(xùn)練,從而使模型具有良好的對于機場場面目標的檢測與跟蹤能力。
3 實驗分析
本文使用的深度學(xué)習(xí)硬件平臺主要包括Xeon(R)W-2133處理器(3.6GHz),64GB內(nèi)存和RTX2080Ti顯卡。實驗軟件環(huán)境采用64位Ubuntu18.04操作系統(tǒng)。實驗結(jié)果表明(表1),經(jīng)過遷移學(xué)習(xí)的深度目標檢測模型能夠在廣漢機場對飛機、車輛和人物目標的識別準確率達到82%,跟蹤準確率達到78%。在圖像處理速度方面,由于深度網(wǎng)絡(luò)的運算開銷較大,采用CPU的處理速度較慢,約為3幀/秒。但是,在采用GPU處理之后,圖像處理的速度能夠達到約45幀/秒,可以滿足實時的場面目標檢測與跟蹤需求。

表1 廣漢機場場面目標檢測模型實驗結(jié)果
圖3是三幀視頻在遷移學(xué)習(xí)前后的目標檢測效果對比。從圖中可以發(fā)現(xiàn),僅僅通過在大型數(shù)據(jù)集MSCOCO上訓(xùn)練得到的目標檢測模型并不能夠很好地應(yīng)用于機場場面環(huán)境的目標檢測工作中,出現(xiàn)了較多的飛機漏檢、將VOR導(dǎo)航臺錯判為飛機等目標檢測錯誤。在遷移學(xué)習(xí)后,模型對于機場場面的飛機、行人和汽車都能夠進行較為準確的識別。因此,遷移學(xué)習(xí)在深度目標檢測模型應(yīng)用于具體場景中的時候具有非常關(guān)鍵的作用。

圖3 同一幀視頻在遷移學(xué)習(xí)前(左)與遷移學(xué)習(xí)后(右)的目標檢測效果對比
4 結(jié)束語
本文針對基于遷移學(xué)習(xí)的機場場面目標檢測與跟蹤技術(shù)進行了研究。采用遷移學(xué)習(xí)的策略,使基于大型通用目標檢測數(shù)據(jù)集訓(xùn)練的目標檢測模型具有了針對特定機場場面目標的檢測與跟蹤能力。基于廣漢機場實地采集的視頻圖像分析,該方法具有較好的場面目標檢測與跟蹤性能,并且在GPU計算的條件下,能夠具備實時圖像處理的能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
