基于計算機的法語語料庫構建及其語言評估研究
2021-06-27 03:25:54宋元元
電子設計工程 2021年12期
宋元元
(西安翻譯學院,陜西西安 710105)
隨著計算機信息技術水平的不斷提升,處于計算機時代背景下,計算機系統也已經不單純應用于專業學術場合,而是逐步滲透到社會工作、生活的各領域。但是,在普及應用計算機的過程中,如何更好掌握計算機用語對于人們的語言學習至關重要[1]。在計算機技術領域中,不規范語言翻譯表現方式導致計算機無法實現統一翻譯,導致閱讀理解困難。以及計算機用語過于生活化,也衍生了大量多義詞和新詞語,再加上網絡用語過于泛濫,很多時候人們會不知所云。計算機系統語料庫源于拉丁語,同源法語單詞“Corps”[2]。語料庫在語言上表示對于某類語言情況所匯集的有限話語集合。而法語教學中也經常會聽到學生抱怨,聽不懂表達詞語,也找不到合適的詞匯[3]。而這些都是由于學生未能充分掌握法語詞匯及運用技巧,所以提出基于計算機的法語語料庫,并運用于學生的語言評估,旨在能夠建立計算機領域內的法語語料庫,并搭設學生可以在計算機平臺實現法語自學的平臺。
1 法語語料庫的構建原則
1.1 采集代表性法語語料
在建立法語語料庫時,第一步就是需要采集語料,并且保證語料庫的語料具有代表性。選定明確的抽樣范圍并進行分層抽樣、等距離抽樣方式,保證可以選取具有代表性的語料[4]。
1.2 定期更新語料庫
新聞作為具備一定時效性的語言,每年都會出現諸多實時新詞。所以在構建法語語料庫時,也需要確保可以不斷更新語料庫,將原本已經失去存在活力的語言刪除,才能夠真正保障語料庫具備使用意義[5]。
1.3 運用新型軟件分析數據
通過運用AntConc3.3.4w 等多種統計分析軟件,目前,該軟件作為廣泛應用的一種數據分析軟件,對法語語料庫構建來講尤為適用[6]。經過運用該軟件統計小型法語語料庫,并對新聞中所發生的常用詞匯和具體習慣進行總結,從而形成新型詞匯表,并劃分不同難易程度的四類詞匯等級,如圖1 所示。

圖1 語料庫分析軟件
2 關鍵技術
2.1 語料存儲
在計算機系統中,建立法語語料庫需要建立XML 文件存儲格式標注。一般情況下完成存儲式XML 標注,作為能夠運用字節偏移量加以表示的對齊位置關系,XML 文檔可以基于各關鍵詞領域,標識對應位置,并明確標注的章、節、段、句、詞等主體信息。需要分開存儲生語料及XML 標注,以便后續對計算機法語語料庫進行系統擴充,也會出現同一語料庫作為多個XML 的文檔標注,但是不同XML 文檔卻實現了差異化功能[7]。譬如a.xml 標注表示雙語對齊,b.xml 表示句法,c.xml 表示數據挖掘,這樣不僅可以有效節省存儲空間,與此同時也可以最大化保護文檔產權。對于XML 標注集可以劃分為篇章、段落、句子、詞語,如圖2所示。

圖2 語料存儲標注功能
2.2 雙語詞典
建立計算機法語語料庫平臺,主要包括通用型、領域內兩類詞典,在程序編寫中參照權威語言詞典用書,作為通用型機型詞典,而領域內則采用國外經典文書索引校對文本。在計算機雙語詞典的平臺存儲格式方面,運用XML 格式能夠實現快速查找。
2.3 特征語塊
特征語塊定義包括:1)字符串內的句號;2)表現文本中的均勻分布文段內,突然存在的特殊句段以及具體的標記特點;3)字符串內的換行符結束段落;4)特征及多個段落、句子集合特征語塊;5)細化特征語塊,確保可以縮小語塊操作范圍;6)對分句處理協調過程中,能夠自動更正誤差并保證語塊對齊[8]。
3 法語語料庫構建實現
3.1 建設目標
在建設法語語料庫平臺時,為了保證語料可以在計算機各方面全面覆蓋,并且對各類翻譯風格充分體現,定位原始語料作為計算機詞典、工具書、計算機軟件、法語對照和網絡用語。
為了能夠對齊篇章、句子和段落,實現自動對齊語句,保證達到90%左右的對齊率,運用可拓展語料參數標記,便于自動式檢索語句[9]。
3.2 平臺建設方案
在建設該平臺時,設計的平臺結構組成包括降噪處理、提取特征語塊、提取目錄樹、標注關鍵詞和分詞、統計詞頻信息并編撰詞典、對齊分段、及時過濾停用詞,如圖3 所示。

圖3 法語語料庫平臺建構方案
3.2.1 降噪處理
由于平臺在加工語料處理時,通常會不同程度地產生一定噪音,譬如漏掉標點符號或產生不必要的換行符,以及不可識別字符。
3.2.2 提取特征語塊
在法語語料平臺中,標記提取特征語塊,主要是實現文章結構的大致標記,為該類特征結構提供了分段便利性,并且準確對齊分句的關鍵前提就是能夠提取特征語塊。一般情況下,在互譯文章中可以選擇特殊標記,譬如章標題或范例,并運用已知資源獲得相應的特征詞塊位置。
3.2.3 提取目錄樹
如今在建設法語語料庫時,作為基本電子化書,詳細目錄是為了對所處位置信息能夠快速查看,并且可以有效改善用戶在使用過程中的自主感官,提取目錄樹可以為用戶應用該語料庫,形成更高層次的視角提供方便。目錄樹能夠提供法語、漢語相對應的查找功能,并且以各個章節標點為依據,譬如章、節等字符標識。但同樣也需要注意該步驟需要做好XML 標記,標記語料所在位置,才能保證不會在日后處理過程中發生遺漏。
3.2.4 標注關鍵詞和分詞
經過完成領域內法語詞典查找,并運用最優化匹配模式,完成對應中文和法語的領域詞匯,及時做好相應標記,確保法語、中文兩大標記文檔,均能夠成功識別相應的領域詞所在具體位置,并根據對應信息及時完成統計領域主要詞頻[10]。
3.2.5 統計詞頻信息并編撰詞典
對于通常是原文的法語文本,經譯文翻譯形成的中文文本,統計通篇詞頻的過程中,成功將停用詞過濾掉。統計詞頻后,一旦發現兩類接近的中文和法語詞頻,同時又無法找到詞典中對應翻譯的情況下,則可以運用計算機之間存在的兩個向量間的相似性計算方法,并確認是否作為互譯詞對[11-12]。
3.2.6 對齊分段
與詞頻相結合可以滿足既定范圍中的單詞詞頻差值和閾值,成功標記相應錨點從而成功對齊相應分段。分段代碼示例如下[13]:

3.2.7 及時過濾停用詞
停用詞指輔助類功能詞句,譬如漢語里的的、得、地、是等,通常會高頻率地出現在部分文章中,甚至可能占據較大占比,對于語料庫的對齊、查找速率造成嚴重影響,也增加了對齊噪音,所以統計詞頻時就需要進行提前過濾處理[14]。
4 法語語料庫語言評估實現
構建法語語料庫在應用于語言評估過程中,具體的分析內容及研究的語言學內容之間存在較大相關性,通過定量分析語料庫數據,可以保證用戶在應用中,更針對性地選定語料庫的具體范圍、內容、程度以及具體數量,并對關系用詞的容許性、區分關鍵語義名詞作合理解釋[15-18];也可以建立法語語料庫,準確定位法語學習者在學習過程中的相關語言問題,如圖4 所示。
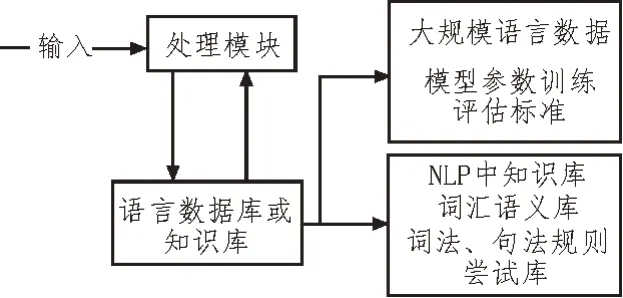
圖4 語料庫語言評估架構
1)在法語語料庫的詞匯量方面,詞匯量密切相關語言能力,越是豐富的詞匯量也就形成越強的語言學習及運用能力,同時還要注意詞匯量達到的可信度及應用過程中的題材因素。
2)詞匯詞級具體分布情況很大程度上反映了將用戶具備的詞匯掌握及運用能力,能夠運用高級詞匯的用戶自然也掌握了更豐富的詞匯。
3)法語語料庫能夠為使用者提供便捷的操作手段,并定期檢測和評估法語語言學習的掌握度。
5 結束語
建構法語語料庫已經成為目前法語學習中的關鍵組成。基于計算機程序,構建法語語料庫,實現橫縱不同組合,對不同個體或群體學生的法語詞匯掌握能力進行語言評估,發現該法語語料庫的構建能夠有效提高學生對法語詞匯的掌握及運用能力。
