基于FPGA 的SoC 接口在CNN 加速器中的研究
2021-06-27 03:25:44夏冰潔王琴
電子設計工程 2021年12期
關鍵詞:設計
夏冰潔,王琴
(上海交通大學電子信息與電氣工程學院,上海 200240)
集成電路的概念出現后,集成電路設計從早期簡單邏輯門的集成,逐漸地發展到了知識產權(Intellectual Property core,IP 核)的集成,人們對于更加微型且集成了更多功能的芯片要求越來越高。需求刺激了新技術的發展,新技術又刺激產生了新一輪的需求。到目前為止,已經實現了在一方小小的芯片上集成十幾個IP 的功能。
當涉及多個IP核同時運作時,對數據流的控制就顯得尤為重要。為了使數據能夠有條不紊地在各個IP 核之間流通,如何協調各個IP 之間的關系、對多個IP 進行全局控制成為了最重要的研究課題。
1 整體架構搭建
在卷積神經網絡加速器的整體框架中,針對卷積神經網絡計算量大、數據流動復雜等特點,在Vivado 2018.3 中搭建了一個整體的數據通路框架,其基本的數據流程如圖1 所示。
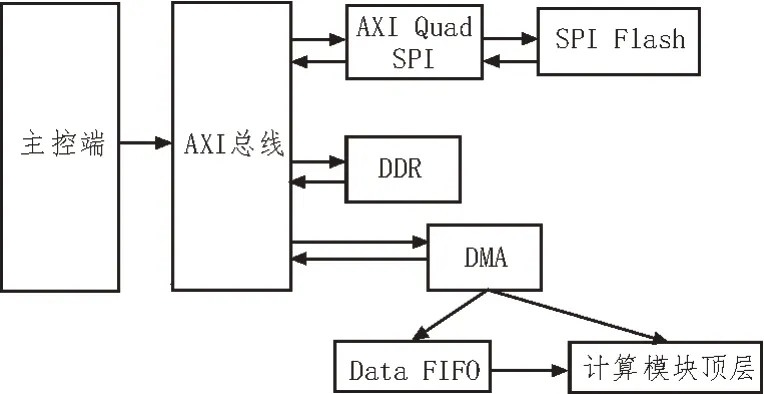
圖1 基本數據流程
目前,對SoC 接口設計的研究面較為廣泛,但多數研究仍然集中在已經普及使用的AXI 總線協議對應的接口設計。在對自定義IP 的研究方面,雖然許多功能因為經常被調用而被封裝成了IP,但因為缺乏通用的協議而限制了對它的使用。
如圖1 所示,基本數據流框架是指首先在主控端中編寫接口的驅動代碼,這些代碼經過AXI 總線與FPGA 進行通信,先通過AXI Quad SPI 這個接口轉接IP 操控SPI Flash 內的數據,并將其中的數據輸出至AXI總線。接著,主控端的C代碼繼續操控連在AXI總線上的DMA,利用DMA對DDR進行配置,就能將AXI總線上的數據讀取至DDR 中。然后,當需要將DDR內數據輸出至計算模塊時,再將DDR的地址配置進讀寫通道,將DDR 內對應地址中的數據讀取出來,經由Data FIFO 輸入計算模塊頂層,供加速器算法使用。
1.1 SPI Flash至AXI總線通路設計
AXI Quad SPI是一個用于接口轉換功能的IP。該IP 的一端以AXI4 Lite協議為接口,另一端則以SPI協議為接口。因此,這個IP實現了從AXI Lite協議到SPI協議的接口轉換功能。通過引入AXI Quad SPI 接在SPI Flash 和AXI 總線之間,可以將AXI Quad SPI 和SPI Flash 兩者視為一個以AXI 協議為接口的Flash存儲器,整體框架如圖2所示。

圖2 AXI Quad SPI與SPI Flash整體框架
1.2 DDR到AXI總線通路設計
在整體框架中,通過引入AXI DMA 這一IP,可以實現控制板上外圍設備。如圖3 所示,AXI DMA 通過配置外圍設備的讀寫通道,來對外設進行數據流的讀寫,在此處引入AXI DMA,可以利用其接在AXI總線上的S_AXI_Lite 實現與總線之間的數據交流。此處,為了能使數據流從SPI Flash 進入DDR,可以利用軟件工具開發包(Software Development Kit,SDK)內的C 代碼對該DMA 進行配置。將DDR 的基地址配置進讀入數據的通道,就可以利用DMA 實現將AXI 總線上的數據讀取至DDR 對應地址內的操作。

圖3 從AXI到DDR數據通路
1.3 DDR到計算模塊通路設計
基于計算模塊本身的算法設計,其接口是自定義形成的,因此需要對該計算模塊的算法外加一個頂層,以保證計算模塊IP 能夠以AXI 協議為接口,準確地卡在DMA 模塊和先進先出存儲器(First Input First Output,FIFO)模塊之間,如圖4所示。

圖4 從DDR到計算模塊數據通路
針對從DDR 中取出至Data FIFO 的數據,計算模塊以AXI4 Stream 接口協議接收這部分數據,然后將數據送入計算模塊內。為了能構成一個回路,再將計算模塊連回DMA 以留出設計余地,以便實現計算模塊中的數據再次通過DMA 傳輸回DDR 中的過程。
1.4 主控端驅動設計
如圖5 所示,在該項目的設計中,選用的是Xil_MemCpy(參數1、參數2、參數3)函數。參數1 是一個基地址,參數2 也是一個基地址。將參數1 基地址開始往后的參數中3 個字節的數據拷貝到參數2基地址下。
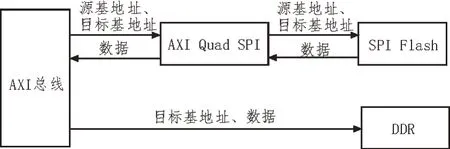
圖5 Flash傳輸數據至DDR
2 硬件數據流優化設計
對于PingPong 操作中所用到的兩塊FIFO 而言,它們循環往復地進行讀或寫的操作。對其進行簡單的分類,可以分為4 種工作狀態:
1)idle狀態:兩塊FIFO均為既不讀也不寫的操作;
2)start狀態:FIFO1 讀入數據,FIFO2 無操作;
3)Ping 狀態:FIFO1 讀入數據,FIFO2 寫出數據;
4)Pong 狀態:FIFO1 寫出數據,FIFO2 讀入數據;
將以上4 種狀態的轉換展現在狀態機轉換圖中,如圖6 所示。

圖6 PingPong狀態機轉換流程
針對FIFO 的內部邏輯而言,需要對控制信號分別進行控制。Data_valid 信號代表FIFO 內部是否存在數據,當FIFO 內存在數據時,Data_valid=1;當FIFO 內沒有數據時,Data_valid=0。當FIFO 內部沒有數據并且此時要將數據讀入FIFO,Data_valid 信號由0 置為1;當FIFO 內部已有數據并且此時要將數據寫出至計算模塊,Data_valid 信號由1 置為0。FIFO 內的邏輯控制流程如圖7 所示。

圖7 FIFO內邏輯控制流程
3 實驗結果與分析
通過在Vivado 2018.3 平臺中進行綜合仿真,所得出的時序結果如表1 所示。該工程的時鐘周期為10 ns,時鐘頻率為100 MHz,最長延遲為5.5 ns。

表1 Vivado仿真時序報告
資源報告如表2 所示。
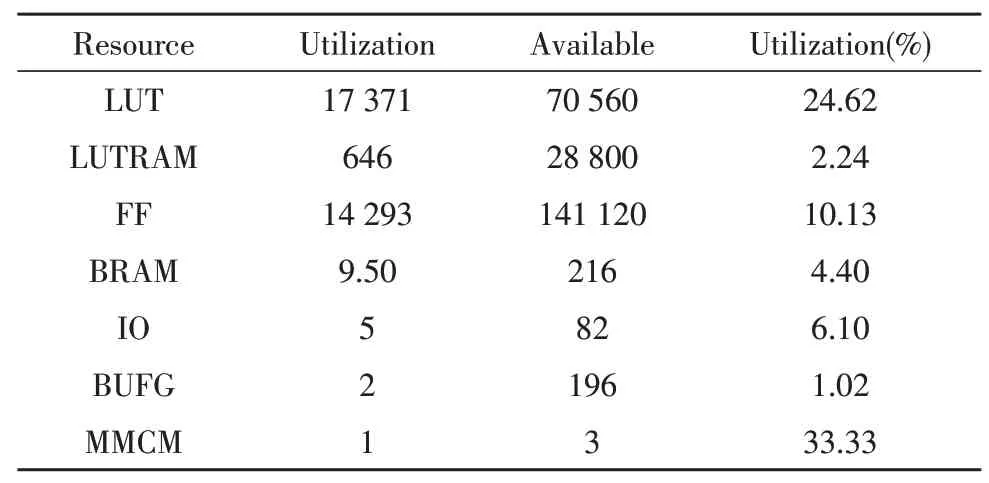
表2 Vivado仿真資源報告
除了上述時序報告和資源報告外,這個工程的帶寬是3 200 Mbits,即在1 s 內,有3 200 Mbits 的數據進入計算模塊被處理。
32 bits×100 MHz=3 200 Mbits
按照計算模塊的需求,不同的卷積層會用到不同大小的數據量。對于一個普通的具有8 層卷積的CNN 加速器而言,根據每一層所給出的數據量,可得到輸入用時,如表3 所示。

表3 每層卷積輸入數據量和輸入用時
4 結束語
文中依托一個典型的CNN 加速器結構,主要實現了在Vivado 2018.3 中設計底層硬件數據流通路,并對進入計算模塊算法部分的數據的通路進行優化。在這個項目中,選擇了DMA 訪問來控制對外圍存儲設備的讀寫,并在計算模塊的頂層加入一個PingPong 的FIFO 來對進入計算模塊的數據進行流水化操作。最終實現了對數據流架構的優化,使得時鐘周期達到10 ns,并依次給出了資源報告和每層卷積的輸入用時。該項目對基于FPGA 的SoC 接口設計具有參考意義,提供了一種SoC 接口設計方法,為未來的研究提供了一個參考方向。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
