基于BPSO-SVR的循環流化床鍋爐燃燒系統建模
2021-06-27 08:01:26金鵬
機械設計與制造 2021年6期
關鍵詞:模型
金 鵬
(遼寧工程職業學院電氣工程系,遼寧 鐵嶺 112008)
1 引言
在鍋爐運行中,由于燃料中含有氮,以及空氣中的氮在高溫下氧化等原因,鍋爐燃燒勢必要釋放出一部分氮氧化合物NOx。在如今節能減排背景下,在鍋爐負荷穩定前提下,降低NOx排放量濃度成為當前人們的關注熱點[1]。建立合理的鍋爐燃燒系統NOx排放量濃度模型是提高鍋爐熱效率的有效方法[2]。然而,鍋爐燃燒系統是一個多輸入變量、非線性、強耦合的復雜系統,經典的機理建模方法不能勝任復雜、非線性的系統建模。目前,很多大型供熱系統都采用DCS分布式監控系統,建立了熱力數據集控系統數據庫。這為通過機器學習算法建立鍋爐NOx排放量濃度模型提供了數據樣本支持。文獻[1-4]提出采用人工神經網絡建立鍋爐預測模型,然而,神經網絡存在模型訓練時間較長、易于陷入局部最優值現象。文獻[5-6]通過支持向量機(SVM)算法建立鍋爐預測模型,但對于大樣本建模,SVM存在訓練時間過長,容易產生過度擬合的問題[7]。文獻[8]將支持向量機回歸(SVR)應用于鍋爐建模中,但鍋爐預測模型的各輸入變量存在耦合性,精細調節鍋爐參數較為困難。
提出一種改進的SVR鍋爐燃燒系統建模方法。將雙態粒子群算法(binary-state particle swarm optimization,BPSO)與SVR相結合,利用雙態粒子群算法在線調節SVR預測模型的參數,提高SVR建模精度及泛化性。
2 支持向量回歸理論
支持向量機算法(support vector machine,SVM)是一種分類算法,其本質是尋找一個最優分類面使樣本分隔[9]。
支持向量回歸(Support Vector Regression,SVR)是一種回歸擬合算法,是在SVM的基礎上引入不敏感損失函數[9],尋找一個最優面使樣本距離最優面的誤差最小[9]。就是利用樣本集做回歸擬合,利用訓練樣本{(xi,yi)=i=1,…,n}擬合出回歸函數f(x)。式中:xi—輸入樣本;yi—輸出樣本,回歸函數f(x)公式如下[9]:

式中:φ(x)—將向量非線性映射到高維特征空間;w—加權向量;b—偏差值。
不敏感損失函數可定義為[9]:
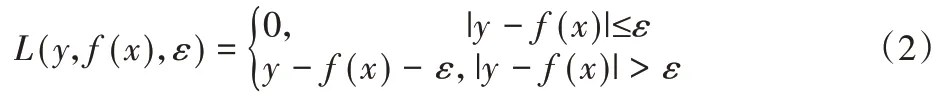
式中:ε—不敏感因子,為樣本實際值與預測值的差值界限。
在引入Lagrange乘子α、α*,松弛變量δ、δ*,并進行對偶轉換后,求解w、b描述為以下不等式約束問題[9]:
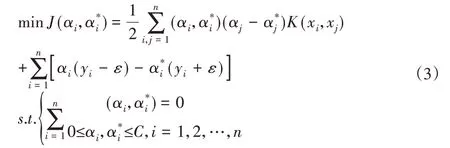
式中:C—懲罰因子,此時,回歸函數為[9]:
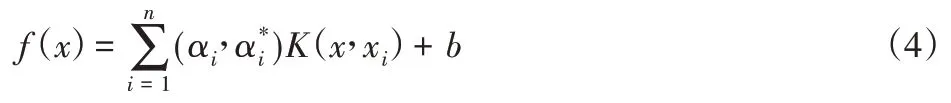
式中:K(x,xi)—核函數,選取RBF核函數,公式為[9]:

式中:λ—核函數寬度。
3 基于BPSO的SVR參數優化
由前文可知,推導出SVR模型需求出C、ε、λ。由于鍋爐建模中的各輸入量中存在關聯性、耦合性,導致C、ε、λ也存在關聯性和耦合性。精細調節參數較浪費時間。采用雙態粒子群算法(BPSO)在線調節這3個參數。首先,采用混沌算法初始化粒子群的位置,使粒子隨機、均勻地分布在解集空間[10]。其次,采用BPSO算法在解集空間內搜索C、ε、λ的全局最優解。
3.1 雙態粒子群算法
雙態粒子群算法將粒子群分為兩個不同行為狀態的子群,探索狀態群體和捕食狀態群體[11-12]。
捕食狀態:在粒子群迭代初期,所有粒子處于捕食狀態。捕食狀態的粒子群行為狀態與普通粒子群算法一樣。設粒子規模為M,搜索空間維數為D,種群的最大迭代次數為T,種群中粒子i(0≤i≤M)的位置為xi,速度為vi。粒子i根據自己的個體最優值pid和全局最優值pgd在D維空間中搜索得出最優解,粒子i按式(6)和式(7)更新下一代的速度和位置[11]。
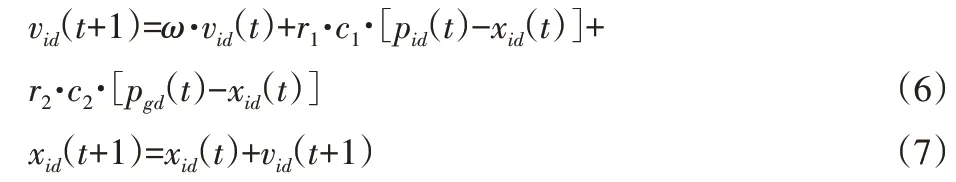
式中:t—粒子的迭代次數;
c1,c2—粒子i的學習因子;
r1,r2—(0,1)間的隨機數;
ω—粒子i的慣性權重,如式(8):
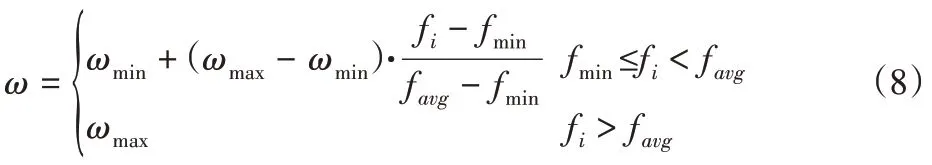
式中:ωmax、ωmin—慣性權重的最大值和最小值;fi—粒子的適應度;favg—粒子群適應度平均值;fmin當前為粒子群最小適應度。
從式(8)可以看出,當粒子i的適應度較小時,粒子以較大的慣性權重快速搜索,當粒子i的適應度逐漸接近粒子群適應度平均值時,粒子以較小的慣性權重精細搜索[8]。
探索狀態:在粒子群尋優過程中,若算法陷入局部最優值,保留一部分優良粒子以捕食狀態搜索。其余大部分粒子轉為探索狀態,在全部解集空間內重新初始化,繼續尋優,這部分粒子位置為式(9),速度更新和位置更新公式為式(10)、式(11)[11]:
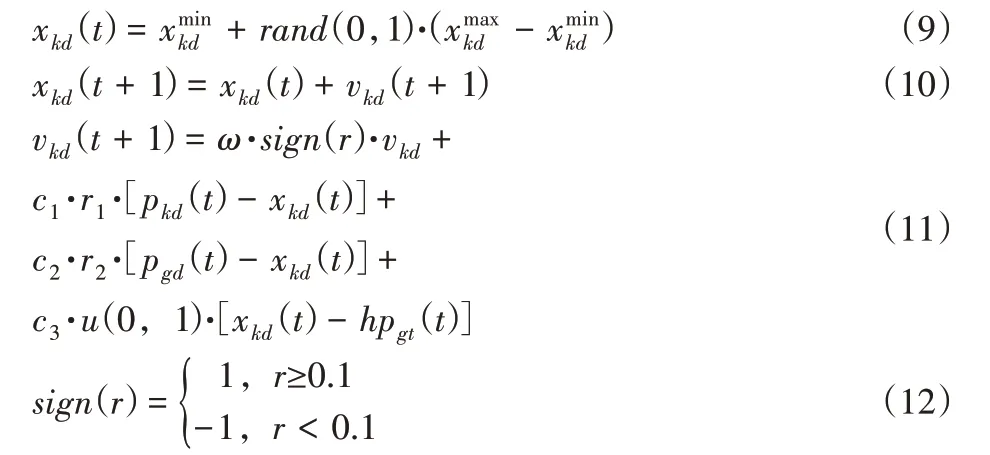
式中:sign(r)—符號函數;
c3—(0,1)之間隨機數;
u(0,1)—高斯分布函數;
hpgd—搜索狀態的粒子在解集空間內的全局最優值。
3.2 SVR參數尋優
算法流程:
(1)設置粒子群初始化參數。
(2)利用混沌映射式(13)初始化粒子位置和速度,生成C、ε、λ的初始位置序列。
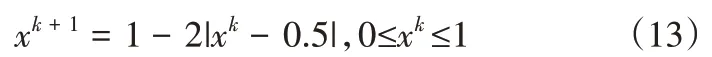
(3)按式(6)、式(7)、式(14)更新粒子位置、速度和適應度。
將SVR訓練集樣本實際值yi與預測值的均方根誤差作為PSO適應度函數,適應度函數如式(14)。可見,fi越小,SVR訓練結果越好。

式中:n—訓練集樣本數量。
(4)若連續迭代5次適應度的變化率Δf均出現Δf≤1e-5,即認為算法陷入局部極值,轉(5);否則,轉(7)。
(5)按適應度排序粒子,性能較好的30%個粒子留在捕食狀態,按式(6)、式(7)、式(14)更新速度、位置和適應度。其余粒子轉為探索狀態,按式式(10)、式(11)、式(14)更新速度、位置和適應度。
(6)分別計算捕食狀態的和探索狀態的全局最優值,比較后更新全局最優值。
(7)算法達到最大迭代次數,尋優結束,求得C、ε、λ全局最優解。
(8)輸出C、ε、λ,建立最優化SVR預測模型。
4 循環流化床鍋爐燃燒系統建模
4.1 數據預處理
以某石化廠的一臺容量為130t/h的循環流化床鍋爐為研究對象。在集控系統數據庫中選取此鍋爐連續運行的550組熱力數據,采樣間隔為5min。將影響NOx排放濃度的主要數據(鍋爐負荷、爐膛密相區溫度、一次風流量、一次風溫度、二次風總流量、風機入口溫度、煙氣溫度、煙氣含氧量)作為建模的輸入樣本,NOx排放量濃度作為輸出樣本。鍋爐NOx排放濃度預測模型結構圖,如圖1所示。
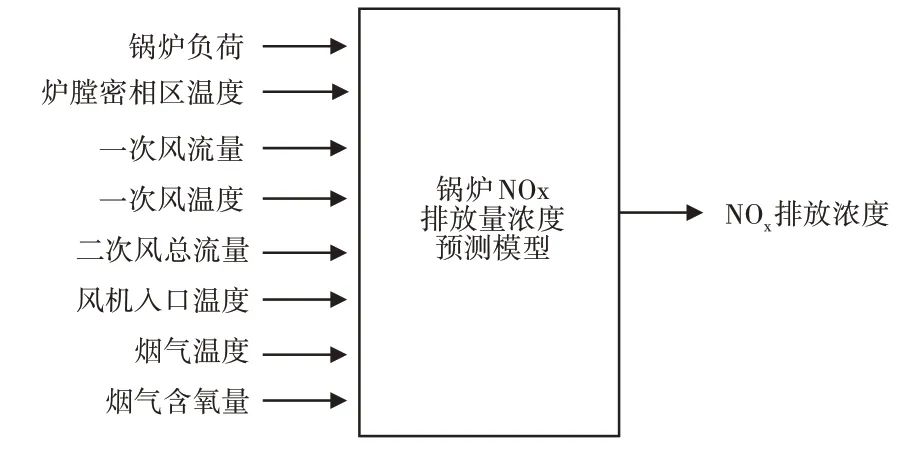
圖1 鍋爐NOx排放預測模型Fig.1 Prediction Model of Combustion System of CFB Boiler
建模前要對原始數據進行預處理,包括異常數據剔除和數據歸一化處理。
4.1.1 異常數據剔除
在鍋爐運行過程中,只有鍋爐平穩運行時產生的穩定數據才能反映鍋爐的真實運行狀態,才能用來建模。建模時選取的數據是集控系統數據庫中一個連續時間段的數據,數據中可能存在鍋爐起爐、鍋爐停爐、設備通信故障等情況產生的波動性的異常數據,這些異常數據會降低建模的準確性,建模前要剔除這些異常數據。由于數據較多,人工篩選、剔除異常數據較為繁瑣,以拉以達準則剔除異常數據。拉以達準則為[13]:設待測數據X={x1,…xn},數據平均值xavg,標準差,若滿足式(15),則xi為異常數據數據,要從樣本數據中去除。

4.1.2 數據歸一化處理
由于用來建模的樣本數據(如鍋爐負荷、溫度、風量等)的類型、量綱不一致,若是建模前不對數據進行規范化、一致性處理,會導致建模和預測結果偏差較大[13]。采用歸一化式(16)去除數據量綱,將數據轉化到[0,1]間。

式中:xmax、xmin—待處理數據最大值和最小值。
4.2 建模分析
建模過程如下:
(1)選取訓練集、檢驗集:
經過數據預處理后,選取剩余400組標準格式數據作為建模的樣本。采用交叉驗證法(Cross Validation,CV)隨機挑選280組數據作為訓練集樣本,用來訓練預測模型,其余120組作為檢驗集樣本,用來測試預測模型的精度和泛化能力。
在訓練集樣本和檢驗集樣本中,鍋爐負荷、爐膛密相區溫度、一次風流量等8組數據作為預測模型的輸入樣本,NOx排放量濃度作為預測模型的輸出樣本。
(2)訓練預測模型:
依據支持向量機回歸式(2)-式(5)創建SVR預測模型,設置初始化參數。利用BPSO算法在線求解模型參數C、ε、λ的最優值,建立最優化SVR預測模型。
(3)輸出模型預測值:
根據訓練集樣本、檢驗集樣本及SVR預測模型輸出模型預測值(NOx排放量濃度的預測值)。
(4)性能評價:
在檢驗集樣本中,利用NOx排放量濃度樣本的實際值與預測值的均方誤差(MSE)、平均相對誤差(MAPE)來評價預測模型的精確度。MSE和MAPE公式如下:
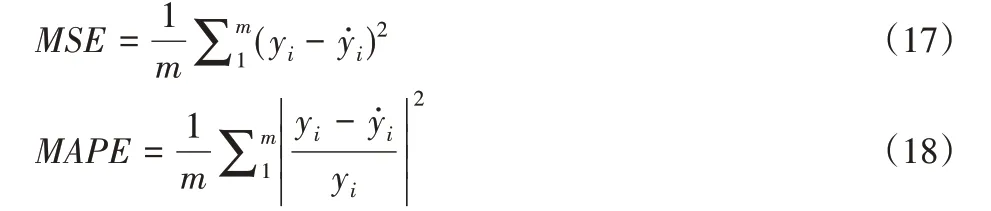
式中:yi—檢驗集樣本實際值;
—檢驗集樣本預測值;
m—檢驗集樣本數量。
建模流程,如圖2所示。
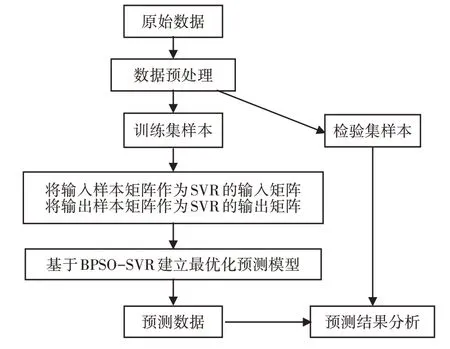
圖2 建模流程圖Fig.2 Modeling flow chart
為驗證基于BPSO-SVR鍋爐NOx排放濃度預測模型的有效性,對比BPSO-SVR預測模型、PSO-SVR預測模型、SVR預測模型、BP神經網絡(BNN)預測模型的預測效果。
利用matlab及libsvm工具箱進行建模分析。算法參數設置如下:粒子群規模M為100,最大次數T為120,學習因子c1、c2均為2;不敏感因子ε搜索范圍為[0,0.001];懲罰因子C搜索范圍為[1,100000],步長為1000;核函數寬度λ搜索范圍為[1,1000],步長為10。BPSO和PSO的適應度曲線,如圖3所示。這4種建模方法預測效果圖,如圖4~圖7所示。這4種建模方法性能指標,如表1所示。
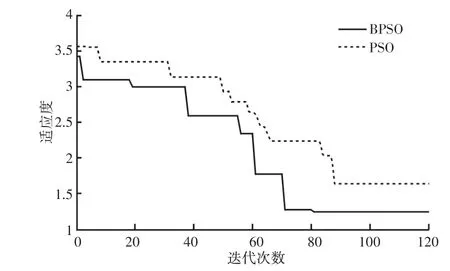
圖3 適應度曲線Fig.3 Fitness Curve
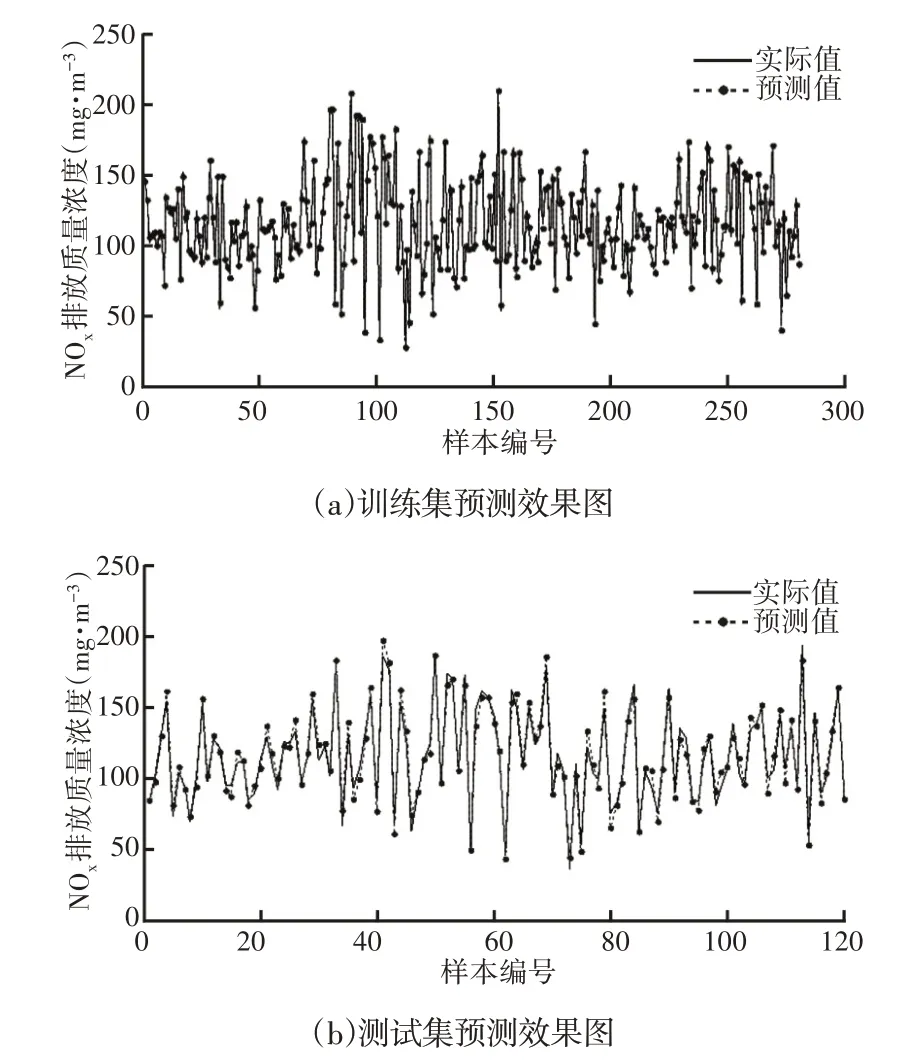
圖4 BPSO-SVR預測效果圖Fig.4 Prediction Effect Diagram of BPSO-SVR

圖5 PSO-SVR預測效果圖Fig.5 Prediction Effect Diagram of PSO-SVR
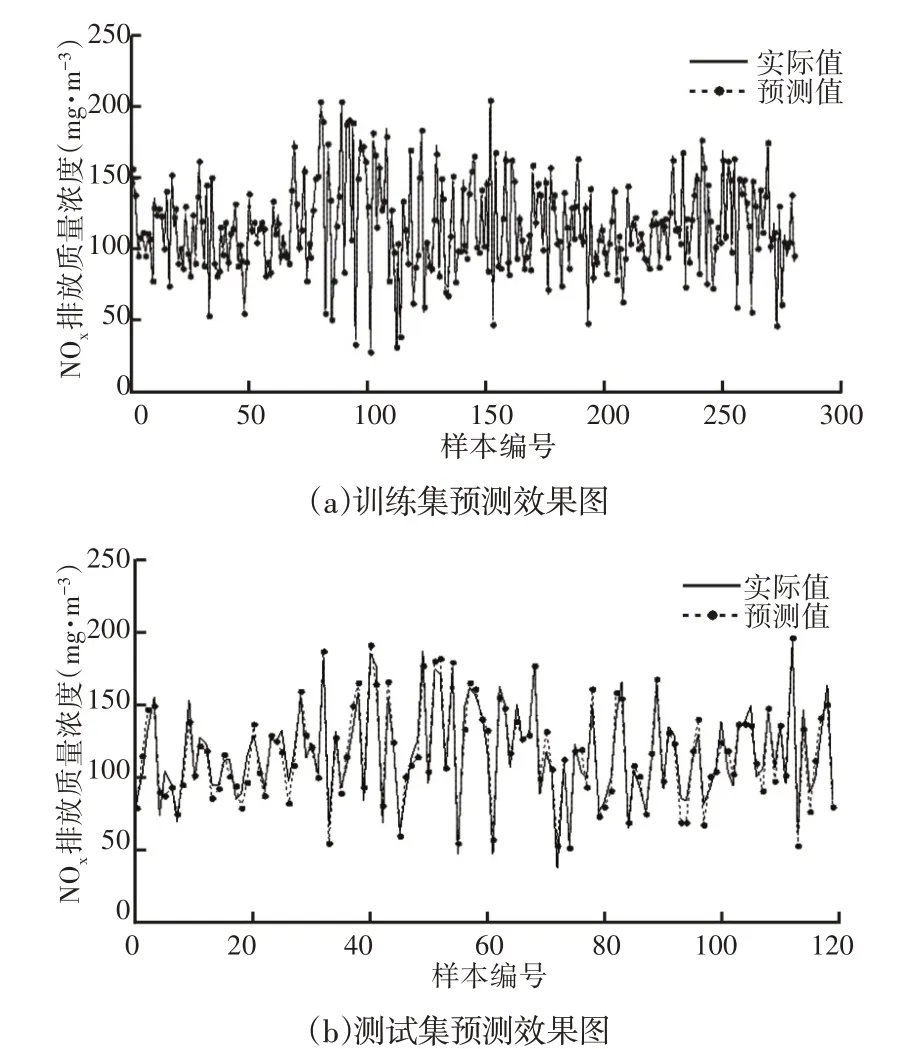
圖6 SVR預測效果圖Fig.6 Prediction Effect Diagram of SVR
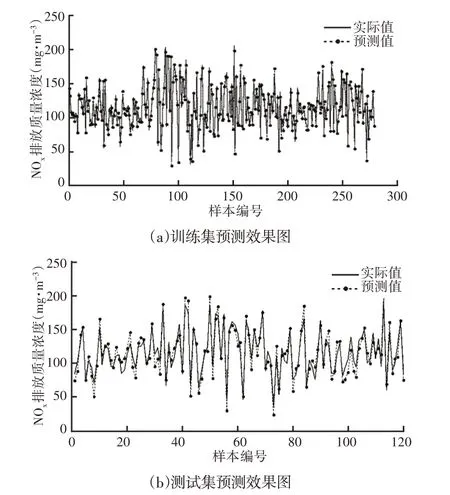
圖7 BNN預測效果圖Fig.7 Prediction Effect Diagram of BNN
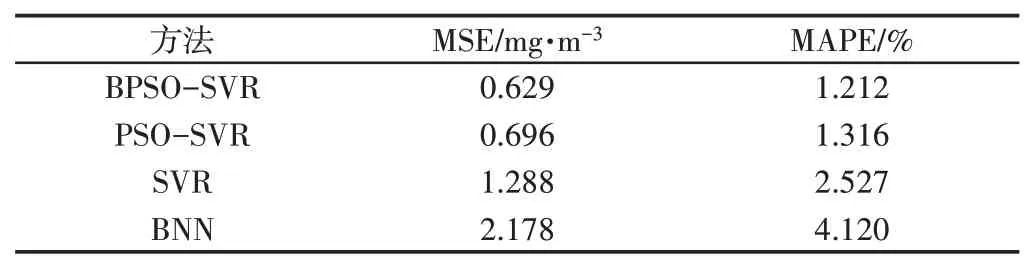
表1 4種建模方法預測結果對比Tab.1 Comparison of Prediction Results of the Modeling Methods
圖3的適應度曲線表明:訓練集迭代計算時,BPSO收斂于81代,最優適應度1.234;PSO收斂于89代,最優適應度1.635;因此,BPSO對解值的搜索速度更快,搜索的解值更優。從圖4~圖7和表1可以看出,BPSO-SVR建模、PSO-SVR建模、SVR建模的預測精度都要高于BNN建模,證明支持向量機回歸的建模精度比BP神經網絡高,即向量機回歸在回歸擬合方面要比BP神經網絡強。而BPSO-SVR預測精度最高,再次證明BPSO搜索的SVR參數更優。另外,從4種算法檢驗集的均方誤差、平均相對誤差的對比結果證明BPSO-SVR預測模型的泛化能力要優于PSO-SVR預測模型和SVR預測模型。
5 結語
由于鍋爐NOx排放預測模型的多輸入量存在關聯性、偶合性。因此,精細調節建模參數比較困難。首先確定用來建立鍋爐NOx排放濃度預測模型的輸入變量和輸出變量;然后,對采集數據進行預處理,篩選出用來建模的樣本;最后,將樣本分為訓練集樣本和測試集樣本,分別利用BPSO-SVR、PSO-SVR、SVR、BNN算法訓練鍋爐NOx排放量濃度預測模型。4種方法的建模對比結果表明BPSO-SVR建模方法具有更高建模精度和更強的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
