基于神經網絡的再生混凝土配合比設計優化方案研究
2021-06-27 07:19:36張應遷
四川水泥 2021年6期
王 壹 張應遷 陳 源
(四川輕化工大學,四川 自貢 643000)
0 引言
在目前大多數建筑行業中,依舊采用傳統的混凝土配比方法。即使用“保羅米公式”求出水灰比列,然后通過查表來得出用水量以及需要混合的水泥比例,再通過查表得知需要混入的砂石含量比率,通過絕對體積法來計算出砂石的用量;同時還有使用絕對密度法來對砂石的使用含量進行推算的。[1]雖然使用的推算方法不同,但是這些方法都有一個共性,就是需要依靠經驗性的表格來對水泥混凝土的配比進行查找。而在現代的建筑工程要求中,傳統的水泥混凝土已經遠遠不能夠達到現在的建筑標準。而傳統的水泥混凝土配比表格,對更為復雜的再生混凝土無法進行原料配比。因為再生混凝土中除了對水泥的使用還有更多的復合材料以及工業廢棄物中的硅灰和粉煤灰,這些材料在傳統的水泥混凝土配料表中都是找不到的,因而查表法無法使用。
1 人工智能神經元網絡
神經元網絡(ANN)是由大量的基本信息原件來進行信息整合以及信息模擬的數據信息處理系統,模仿人類大腦對不同神經元的整合以及通過復雜的神經元網絡來對信息進行處理的過程。[2]其實從本質上講,人工神經元網絡更類似于一種數學公式;不過,這種數學公式不再基于傳統的數學模型基礎,而是建立于數學網絡基礎上,對數據進行運算,對于傳統的數學模型無法通過建模來解決的數據問題,人工神經元網絡可以進行很好的處理運算;就比如說對于無規則也不能用簡單數學公式來進行描述的問題,傳統的數學模型方法是不能進行解決的,但是人工神經元網絡系統卻可以對這些問題進行很好的數據整理、分類,并且加以處理,然后通過不斷的擬合模擬,得出最優結論;而對于再生水泥混凝土的配比結構問題,恰好符合人工神經元網絡中數據的無規則性以及原始性。所以本文將通過人工神經元網絡來對再生混凝土的最優配比進行研究。[3]
2 實驗數據分析
與傳統的普通水泥混凝土相比,再生混凝土的物理抗壓性、承重性、坍塌度以及保水性都有很強的優勢。然而,這些特性需要通過很復雜的因素均衡來實現。對再生混凝土最優配比的方案研究,就是想要尋求在再生混凝土的配比過程中對各個因素的協調。以求在再生混凝土的使用過程中,各項指標達到最優。根據網絡以及國際中的一些實驗數據,再生混凝土的強度,耐久性以及各種工程特性主要與以下一些因素有關。[4]大致包括用砂量、再生骨料的摻雜、用水量、附加用水量、骨料壓碎的指標、原骨料的用量、減水劑的使用以及超細摻合料如硅灰和煤粉灰。
這里提到了再生骨料,大致類似于傳統的水泥混凝土中水泥砂石的使用。對再生混凝土起到了基礎硬度與強度的保證作用。同時,就好像傳統水泥的吸水性一樣,再生骨料中大量的粘附砂漿也會對配比原料中的水分進行大量的吸收。且由于再生骨料配比含量并不確定,所以對水的配比使用含量也是不確定的,所需要再根據再生骨料使用量的多少來確定附加水的用水量。在建筑工程建造過程中,我們不可能只對企業要求的建筑施工強度這一單一因素進行控制,建筑建造的質量同時還應該包括其他因素,比如混凝土的坍落度、保水性以及黏力、聚合度。只有這一系列的建筑因素達到國家標準要求并且遠超于傳統的混凝土建筑標準,再生混凝土才具有在正常的建筑施工過程中進行使用的意義。
但是就上文所提到的內容,對于影響再生混凝土強度以及各種工作特性的因素復雜而多變。很難通過簡單的數學模型以及幾個數學公式來進行表達模擬。這也就是造成再生混凝土不能夠像傳統混凝土一樣廣泛的推廣使用的重要原因之一,同時也不可能擁有經驗性的配料表來用于日常施工中進行查表操作。其實這也是本文所研究的方向,想要通過對實驗數據的擬合整理來填補國內再生混凝土使用配比過程的行業空白。同時不斷完善國內的建筑工程水平與質量。[5]
所查閱的文獻中進行了20 組不同環境條件影響下的再生混凝土的實驗。通過對環境因素、配料因素以及含水量因素等各種因素的變量控制。在混凝土充分混合以后,首先對混凝土的密度以及保水量進行觀測記錄。然后對混凝土的黏度以及晾曬完成以后的建筑強度、硬度進行數據記錄。在進行標準養護以后,對其立方體的抗壓強度進行測試。在對再生混凝土的測試中,根據現場測量數據結果可分為:良好、較好、一般、較差、很差的大致等級劃分。為了更便于人工神經元網絡進行數據模擬,這些數據可以量化為1.0、0.8、0.5、0.2、0.1,來對應不同的等級強度。以便于在人工神經元網絡對其數據進行分析整合的過程中能達到更好的擬合效果。下面就是文獻中的參考數據表格:
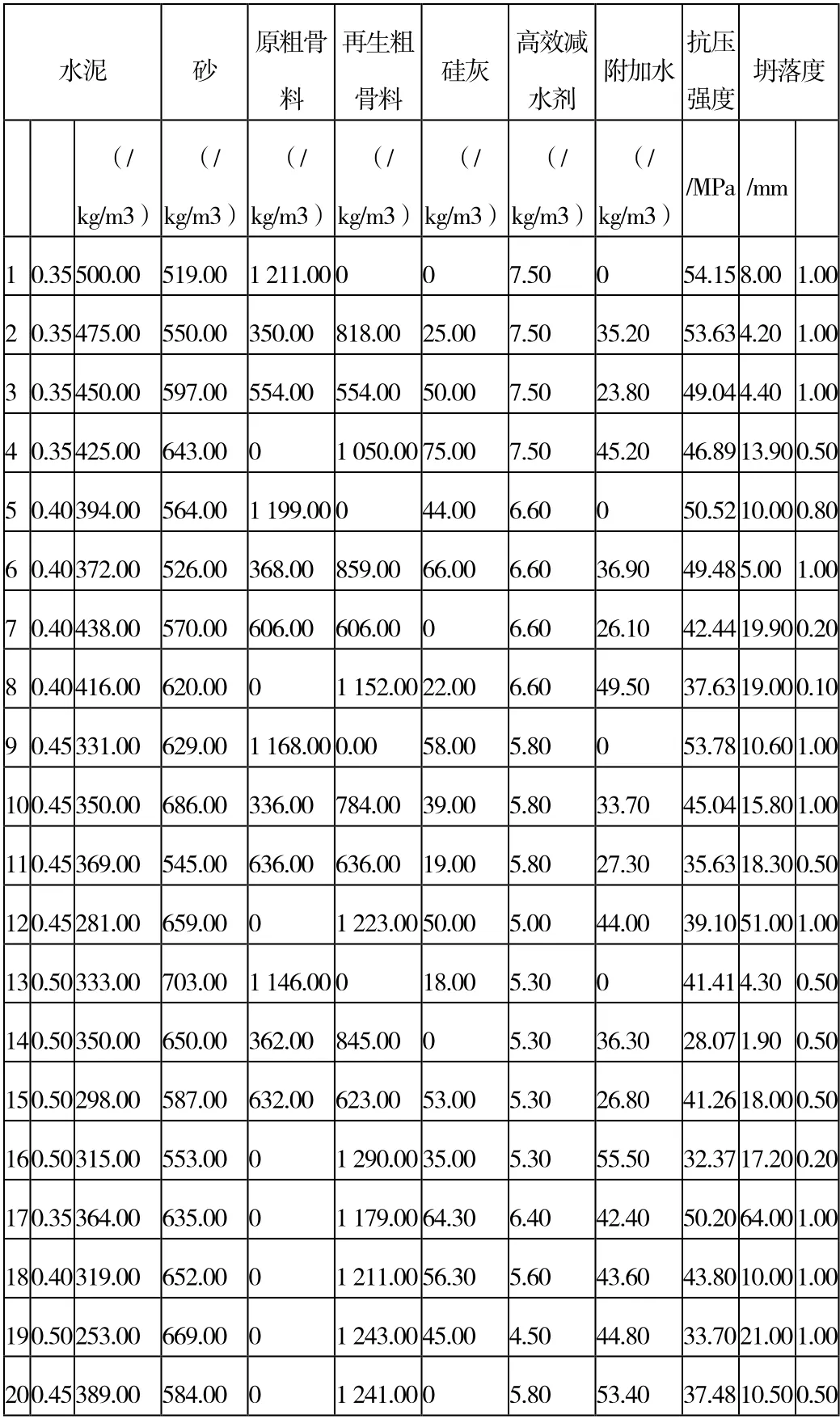
再生混凝土的試驗參數
3 網絡模型構建以及實驗過程
人工神經元網絡中目前應用較為廣泛的應當是BP 神經元網絡。BP 神經元網絡是基于誤差反向傳播算法的多層是前向性神經元網絡。BP 神經元網絡主要包括輸入層、輸出層、隱含層以及各單元之間的相互聯系。輸入、輸出層一般都為一層,而想要對數據擬合達到更好的效果,就要不停地對數據進行反復的模擬處理。BP 神經元網絡中通過增加隱含層的層數來不斷的反復進行數據模擬這一過程,從而達到實驗目的。輸出標準是以通過調整權值Wij,來使得誤差信號達到最小。當誤差達到不能夠再減小的最小程度時,就說明數據的擬合已經找到了最優解。然后對所擬合的數據結果進行整理輸出。
4 結語
由于本實驗過程中對于數據來源選取范圍較小,以及參考資料中數據范圍可變性不大。導致實驗數據存在一定的誤差。可能與實際施工過程中的預期效果存在一定比例的偏差。但是基本實驗原理是沒有問題的,同時,對于數據的模擬過程也可以很好地說明,人工神經元網絡是很適合用于再生混凝土最優配比問題的求解過程的。在此實驗的基礎上,可以根據人工神經元網絡的數據模擬結論,在以后工地施工的實踐過程中,通過不斷的改變再生骨料的投放比例以及用水量的大小,來對操作結果進行觀察,同時將這些數據量化輸入到本文所建立的神經元網絡模型中進行調試,如果能夠通過數據擬合獲得更好的再生混凝土材料配比結果,則可以進行現場實驗來進行實際檢驗,通過對材料硬度、黏力聚合度、保水量以及坍落度等一系列的標準檢測,來驗證人工神經元網絡擬合結果,并通過反復的實驗擬合以后得出最佳的配比方案。為以后施工建設中的再生混凝土配比,以及再生混凝土的應用質量探尋更好的技術革新方向,使得再生混凝土技術不斷發展。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
現代裝飾(2022年5期)2022-10-13 08:48:04
建材發展導向(2022年10期)2022-07-28 03:04:00
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
建材發展導向(2021年7期)2021-07-16 07:08:04
水利規劃與設計(2020年1期)2020-05-25 08:01:30
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小哥白尼(趣味科學)(2019年3期)2019-06-17 11:57:44
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
