高分辨率遙感影像深度遷移可變形卷積的場景分類法
2021-06-25 02:03:06施慧慧徐雁南滕文秀
測繪學報 2021年5期
施慧慧,徐雁南,滕文秀,王 妮
1. 南京林業大學南方現代林業協同創新中心,江蘇 南京 210037; 2. 南京林業大學林學院,江蘇 南京 210037; 3. 馬薩諸塞大學阿默斯特分校地球科學系,美國 馬薩諸塞州 01003; 4. 安徽省地理信息智能感知與服務工程實驗室,安徽 滁州 239000; 5. 滁州學院地理信息與旅游學院,安徽 滁州 239000
隨著遙感技術和對地觀測技術的快速發展,來自衛星、無人機等對地觀測海量數據不僅含有豐富的紋理、空間信息,還包含了海量場景語義信息,因此高分辨率遙感影像的信息提取已經逐步從像素層的光譜解譯、結構層的基元紋理分析以及面向對象的分割處理發展向規則知識、語義識別和場景建模等影像高層理解與認知方向發展[1]。高分辨率遙感影像分類從傳統像素級和對象級分類漸漸轉向場景語義級分類[2-4]。
目前,已有場景分類方法可概括為兩類:①基于底層特征和中層特征的方法。早期基于傳統的底層特征或者手工特征,通過提取紋理、顏色、形狀等特征進行圖像分類。與早期方法相比,基于BoVW模型[5]的中層特征方法通過手工制作的底層特征構建圖像直方圖,對圖像聚類分析,雖簡單高效,但表達能力有限。②深度學習模型方法。卷積神經網絡(convolutional neural network,CNN)一經提出,便憑借其強大的特征提取能力很快成為眾多領域學者關注的焦點[6-8]。針對高分辨率場景分類問題,大量深度學習模型網絡被構建,如GoogleNet、VggNet和ResNet等,使得深度學習在場景分類中的準確率不斷得到提高。同時遙感的一個重要里程碑仍然是對來自于不同傳感器和地理區域的未知數據進行分類的模型的可移植性[9],遷移學習則可以有效解決這些問題[10],基于具有1500萬張已標注高清圖片和22 000多種場景類別的ImageNet[11]圖像庫,可以讓計算機具有跨領域學習的能力,同時使得信息可以得到高效重復利用[12]。文獻[13]首次將深度學習卷積網絡應用于高分辨率遙感影像場景分類問題,將ImageNet圖像數據上預訓練的深度卷積神經網絡模型遷移至遙感場景數據集,得到較好的分類效果。文獻[14]采用兩個小尺度遙感影像場景數據集測試了不同深度的卷積神經網絡分類性能,有效解決了高分辨率遙感影像數據量大、信息復雜、特征信息提取難度高等難題[15]。
卷積神經網絡模型對大型、未知形狀變換的建模存在固有的缺陷,這種缺陷是因為標準卷積神經網絡卷積核為方形,在特征圖譜上的固定位置進行采樣,對于復雜不規則的目標或者大小不一的目標檢測是不合理的。文獻[16]提出了一種可變形卷積方法,提升了CNN的形變建模能力,首次證明了學習密集空間變換對復雜的視覺任務是有效的。文獻[17]基于VggNet模型采用可變形卷積層得到圖像特征進行圖像語義分割方法,表明引入可變形卷積的分割方法可有效克服遙感影像中分割對象的復雜結構對分割結果的影響。可見在圖像分割中引入可變形卷積的CNN模型在性能上得到了較大提升。而在遙感場景分類中同樣面對同種物體在圖像中可能呈現出不同的形態、大小、視角變化甚至是非剛性形變的問題,在分類任務上采用固定方形的卷積核對具有復雜目標的特征識別是不合理的,僅使用傳統的深度特征無法學習到對遙感場景幾何形變具有穩健性的特征表示。基于以上分析,本文提出了一種場景分類方法,利用大型自然場景數據集ImageNet上訓練的模型提取遙感影像深度特征,然后引入可變形卷積層,增強空間采樣位置能力進而提高場景分類精度。
1 原理與方法
本文提出的深度遷移可變形卷積神經網絡(deep transfer deformable convolutional neural networks,DTDCNN)模型結構如圖1所示。該結構主要分為兩大部分:①利用大型自然場景數據集ImageNet對基礎模型進行訓練得到預訓練模型;②在對目標數據集進行訓練時,首先利用預訓練模型中全連接層(fully connected layer,FC)前的模型提取特征作為圖像特征表達,然后添加可變形卷積層進一步學習遙感影像的幾何形變信息,提高感受野對目標物體的有效感受范圍以得到最終圖像特征,最后輸入到分類器進行分類。
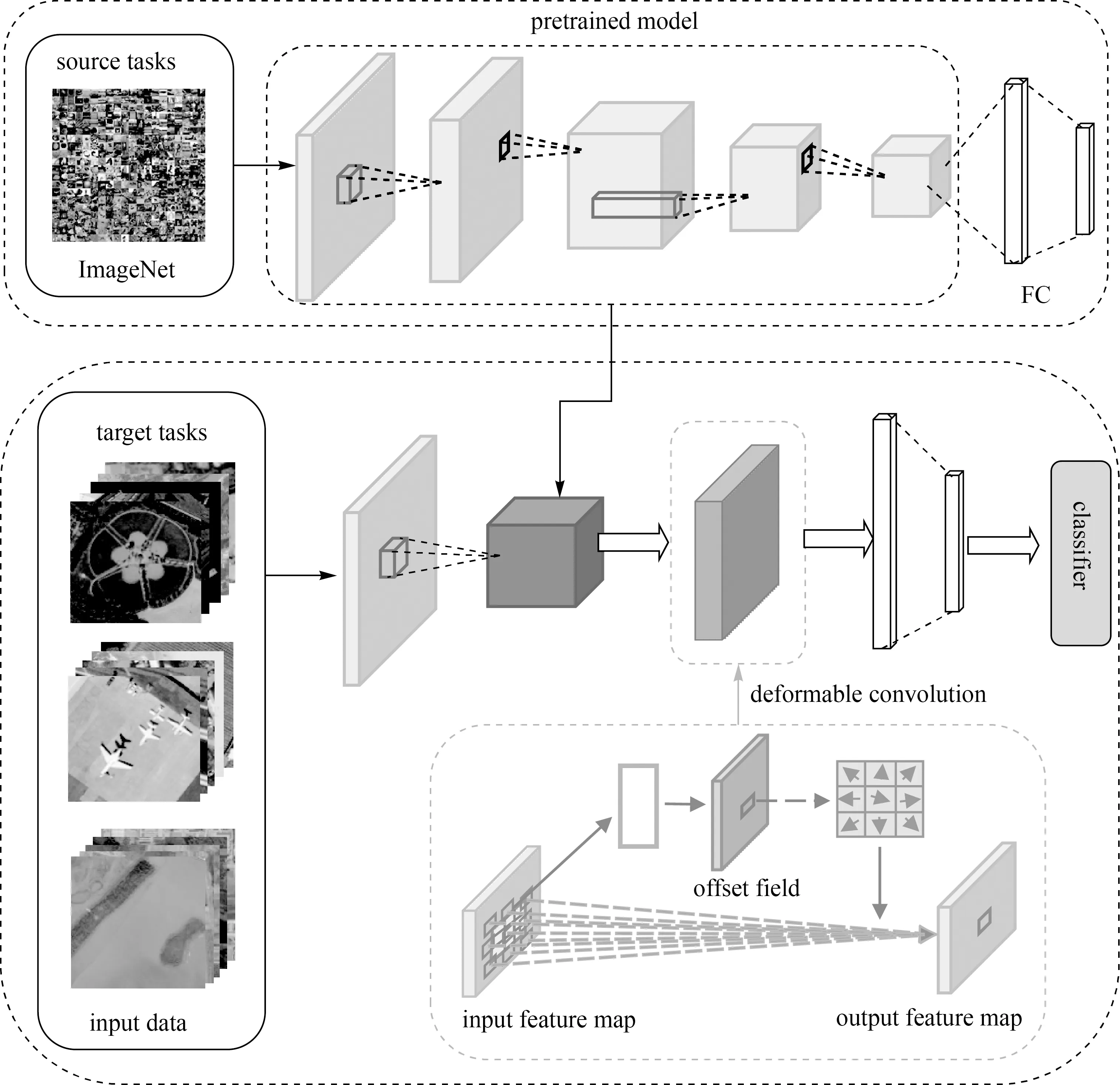
圖1 DTDCNN模型結構Fig.1 Structure diagram of DTDCNN model
1.1 深度特征提取
卷積神經網絡作為深度學習的一個重要算法,在模式分類領域有著出色表現。經典卷積神經網絡主要包括卷積層、池化層和全連接層,其中卷積層通過計算輸入影像中的局部區域與濾波器的點積輸出特征[18]。本文中遙感影像場景分類數據是三通道的,每個卷積核的尺寸為r×s×e,其中e為通道數,本文中e=3,卷積操作如式(1)所示
(1)
式中,f(·)為逐元素運算的激活函數(activation
function);s和r是感受野的空間尺寸;b為偏置項;a(t-1)、a(t)分別為t-1層和t層的響應;w為權值。
經過多次卷積導致特征數據量不斷增加,故在卷積后須添加池化層,通過計算局部區域上的聚合值,沿著特征圖的空間維度進行下采樣操作,在減少參數數量的同時能較好地保留原始有用信息,防止過擬合問題發生[19]。經過特定的第t層的池化層后,第t層第o個特征圖在空間位置(i,j)處的元素可表示為
(2)
式中,u×v大小的區域成為池化鄰域,也稱為池化感受野,通常情況下u=v。
最后,基于卷積和池化操作的特征進行壓縮,所得壓縮特征與全連接層所定義權重參數相乘,將輸入圖像分類為基于數據集的各類別,第t層的每個神經元和第t-1層的每個神經元都連接,即每個神經元的輸入是上一層所有神經元的輸出線性組合。全連接層第i個神經元的值可表示為
a(t)=f(a(t-1)w(t)+b(t))
(3)
多項研究表明,在大型自然圖像數據集ImageNet上學習到的圖像特征對遙感圖像也有很好的適用性[20-22],因此,本文利用預訓練模型提取遙感場景的深度特征,將該深度特征作為整個遙感場景特征的一部分。
1.2 可變形特征學習
由于傳統二維卷積核通常首先在輸入的影像特征圖上采用網格R進行采樣,并且在每個采樣點處乘上權值k并求和,因此僅使用傳統的深度特征無法學習到對遙感場景幾何形變具有穩健性的特征表示。以二維3×3卷積核采樣為例R={(-1,-1),(-1,0),…,(0,1),(1,1)},對于輸出特征圖y上的位置P0為
(4)
式中,Pn為網格R中所列位置的枚舉,固定了感受野的大小與步長,則無法對易產生變形的物體特征進行準確描述,使得傳統CNN在一定程度上限制了建模能力。
因此,本文利用可變形卷積(deformable convolution)增加模型對于物體幾何變化的適應能力[23],學習對影像中幾何形變穩健的深度特征,具體的,通過對卷積采樣點添加偏移量{Δpn|n=1,2,…,N},其中N=|R|,使得式(4)變形為
(5)
式中,pn表示卷積窗口中任意一個像素點;k(pn)表示像素點pn的權重;x表示輸入層像素點的集合;Δpn表示像素點pn的偏移量,且通常為小數形式。因此式(5)通過雙線性插值變換之后變為
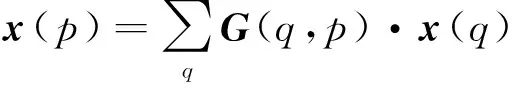
(6)
式中,p表示任意一個位置p=p0+pn+Δpn;q則表示特征圖中的空間位置;G(·,·)表示雙線性插值核,二維卷積則可分解成2個一維內核
G(q,p)=g(qx,px)·g(qy,py)
(7)
式中,g(a,b)=max(0,1-|a-b|)。
標準卷積在對稀疏住宅場景進行特征提取時的采樣點是固定的(圖2(a)),而本文通過引入可變形卷積層會根據影像中目標的尺度和形狀進行自適應調整(圖2(b)),可以高效地提取不同形狀、不同方向的穩健特征,從而增強對影像中的場景辨別能力。圖2中圓點表示讀取圖像特征圖中的激活單元點,箭頭后單元點表示分別對應于前面特征圖上突出顯示的單元點,可變形卷積收斂后的單元點與物體位置的相關性則更高,可以更高效地利用對象特征。
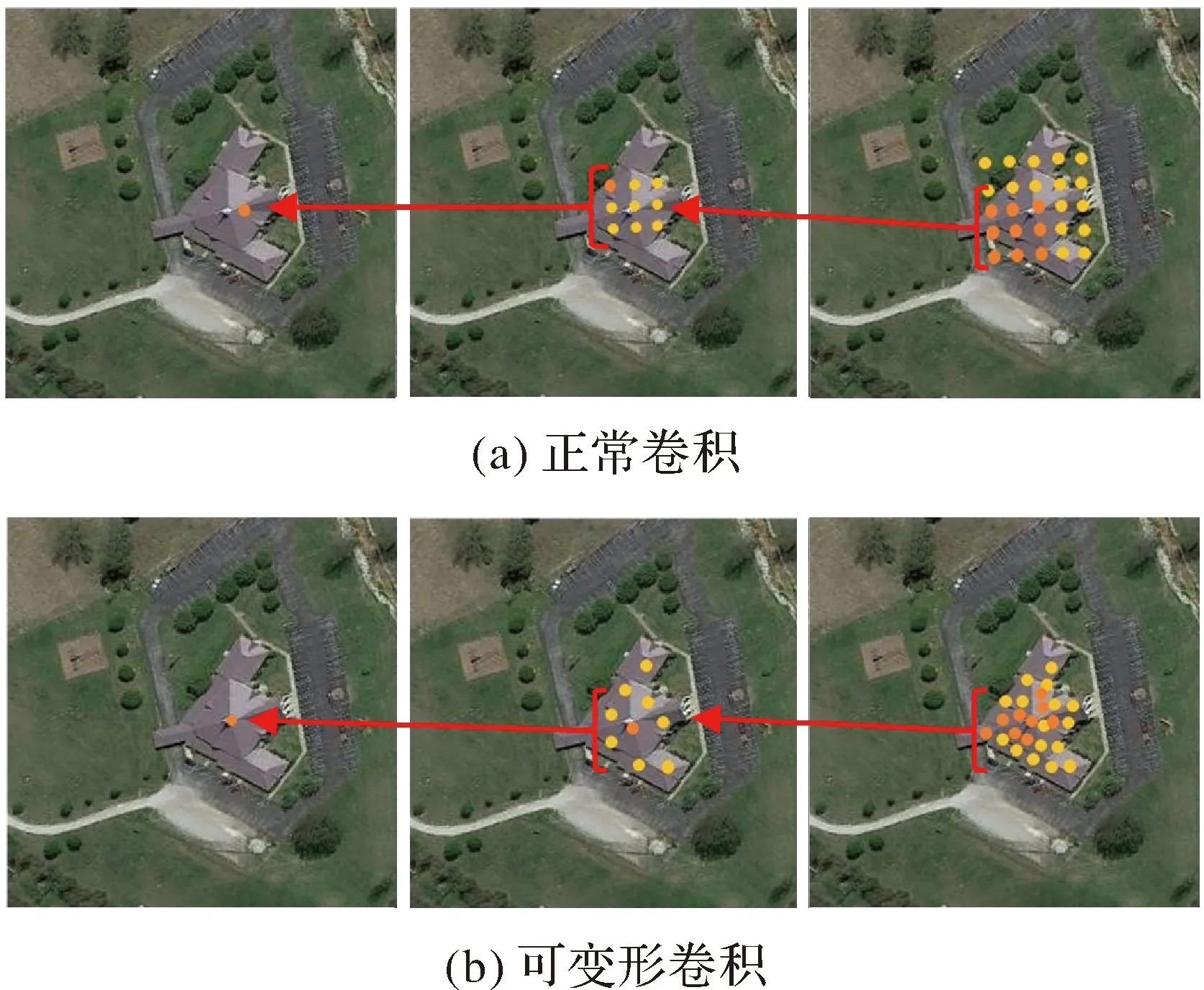
圖2 采樣位置Fig.2 Sampling position
為了學習對遙感場景幾何形變具有穩健性的特征表示,本文在預訓練模型的基礎上添加了可變形卷積層,聯合傳統場景深度特征以及可變形場景深度特征對整個場景影像進行特征表達,提高模型的穩健性的泛化能力。
1.3 模型優化
深度學習算法中損失值用來度量模型在分類時預測值和真實值之間的差距,也是用來衡量模型泛化能力好壞的重要指標,損失函數合理性則決定模型的擬合能力。對于遙感影像場景分類任務,本文采用交叉熵損失函數,表示為
(8)
式中,t為每批次樣本數;yh為第h個樣本的編號;ch是樣本的目標類。利用隨機梯度下降(stochastic gradient descent,SGD)方法對該損失函數進行優化,通過從樣本中抽取一組進行訓練得到函數局部最優值,再按照梯度方向不斷進行更新、再抽取訓練、更新,最終獲取全局最優損失值。本文中隨機梯度下降的學習率使用固定大小值,初始學習率大小設置為0.002,速度衰減因子設為0.9。
2 試驗分析
2.1 試驗設置
2.1.1 參數設置與試驗環境
本文試驗環境為Windows10 64 bit操作系統,CPU為Core i5-7500@3.40 GHz,16 GB內存,GPU為Nvidia GeForce GTX 1060,6 GB顯存。深度學習工具采用PyTorch 1.3.1,編程語言采用Python 3.7.3,集成開發環境使用PyCharm。參數設置上,訓練速率衰減周期設置為100 epoch;批處理(batch)大小設置為64。本文主要試驗部分基于ResNet-50[24]作為基礎模型進行預訓練,增加網絡的特征提取性能。
2.1.2 評價指標
對于精度檢驗,分類任務中多采用總體精度(OA)和混淆矩陣[25]進行試驗結果評價。總體精度為
(9)
式中,N為測試樣本總數;T為正確分類的圖像。該種衡量方法可以較好地反映出分類方法在整個測試圖像上的性能。為了更加直觀地評估模型性能,本文將添加精準率(Precision)和召回率(Recall)進一步進行模型評價。精準率與召回率主要基于試驗結果中所得到的真正例(TP)、假正例(FP)、真負例(TN)和假負例(FN)進行描述,即
(10)
2.2 試驗結果與分析
2.2.1 AID數據集分類試驗結果與分析
AID數據集是用于航空場景分類的大型數據集,具有較大的組內差異,援助目標是提高遙感圖像場景分類的技術水平[26]。2017年由武漢大學和華中科技大學發布,由Google Earth影像上采集的不同分辨率、不同地區的影像,每幅影像大小為600×600像素,包含30類場景,每個類別包含220~420張影像,整個數據集共10 000張影像(圖3)。

圖3 AID數據集示例Fig.3 Example images of AID dataset
本文所提出的方法在AID數據集(50%訓練集比率,每個類別110~210張訓練樣本)上進行試驗得到結果見表1,在采用本文所提出的基于遷移可變形卷積的網絡模型方法后精度提高了4.25%,Kappa系數提高了0.04,同時對模型的計算力(flops)和參數量(params)進行計算,本文方法僅添加了較少參數量使得模型性能得到了較好提升。最終得到分類精度如圖4所示,從初始精度上看兩種方法就有很大的差距,本文所提模型比普通模型精度提高近20%,模型可以更快收斂。從整體上看所提方法都較原始方法精度有較大提高。具體的,根據圖5所示的兩個混淆矩陣可發現,基礎模型在池塘和河流,體育場和體育館,度假村和公園等都產生了較為嚴重混淆現象。這些場景都基于相似特征的基本組成單元,僅在空間分布、密度等方面產生區別,易產生混淆現象,是場景分類中的一大難點。但基于DTDCNN模型,由于該模型中對目標采用非方形卷積核進行特征提取,可以發現體育館較體育場僅多出周圍建筑物,原始模型則不能將其區分開,通過所提方法添加了一層過濾器,大大提高了目標數據集的分類性能。而對于具有較為相同幾何特征的場景,模型即使對場景具有很好地識別效果,但分類上部分未能得到較好的提升。但總體上大部分場景的分類精度都得到不同程度的提高,表明所提方法可以有效減少混淆現象。

表1 比較模型在AID數據集上的OA、Kappa、精準率、召回率和模型計算力與參數量
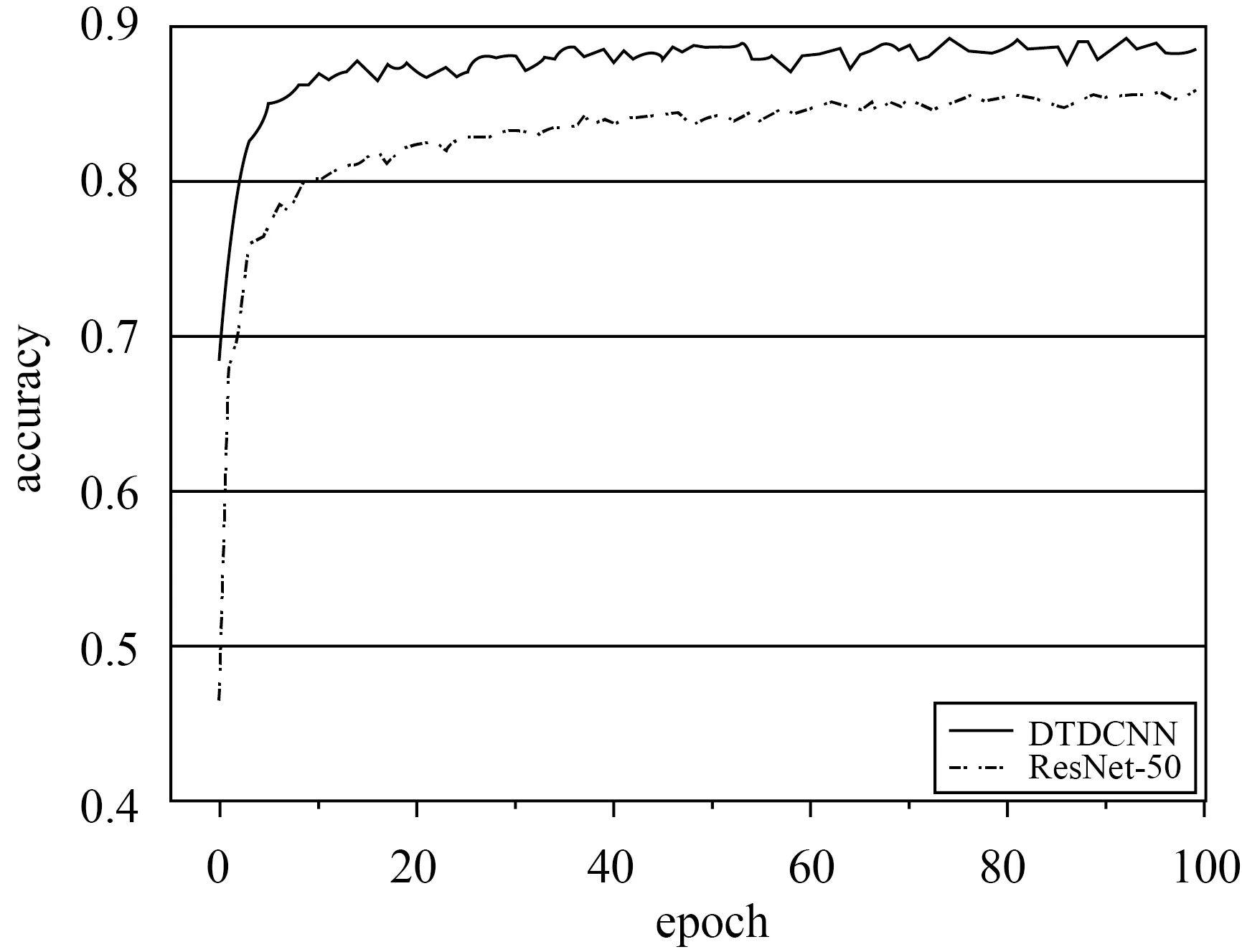
圖4 AID數據集分類精度變化曲線Fig.4 Classification Accuracy Variation Curve of AID dataset
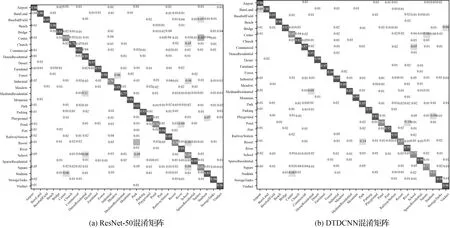
圖5 AID數據集混淆矩陣結果Fig.5 Classification confusion matrix of AID dataset
2.2.2 UC-Merced數據集分類試驗結果與分析
UC-Merced數據集是一個廣泛的手動標記的地面真值數據集(圖6),用于定量評估[2]。該數據集每幅影像大小為256×256像素,涵蓋了21類不同場景類別。每一類場景包含100張影像,共2100張影像。該數據集由于類間差距小,類內差距大,具有較大的挑戰性,在遙感影像場景分類領域極具代表性,廣泛用于場景分類研究[27]。

圖6 UC-Merced數據集示例Fig.6 Example images of UC-Merced dataset
本文所提出的方法在該數據集上進行試驗(80%訓練集比率,每類別80張作為訓練樣本,20張作為測試數據)得到結果見表2,在采用本文所提出的基于遷移可變形卷積的網絡模型方法后精度提高了1.9%,Kappa系數提高了0.021。最終得到分類結果如圖7所示,從中看出兩種方法同樣都很快開始收斂,前20個epoch時添加可變形卷積方法的分類精度相較于初始模型提高較為明顯。根據圖8所示的兩個混淆矩陣可以發現,建筑和中密度住宅區,網球場和中等密度住宅區等都產生了較輕程度的混淆,所提方法較普通模型則有更好的分類效果。同樣與AID試驗結果相似,所提方法精度提高的主要來源是具有相似特征的場景混淆現象的減少。UC-Merced數據集具有較小的類間差距,而同一類別的場景數據具有更大的差異,更好地驗證了所提方法對特征分布不同的場景數據分類的有效性。
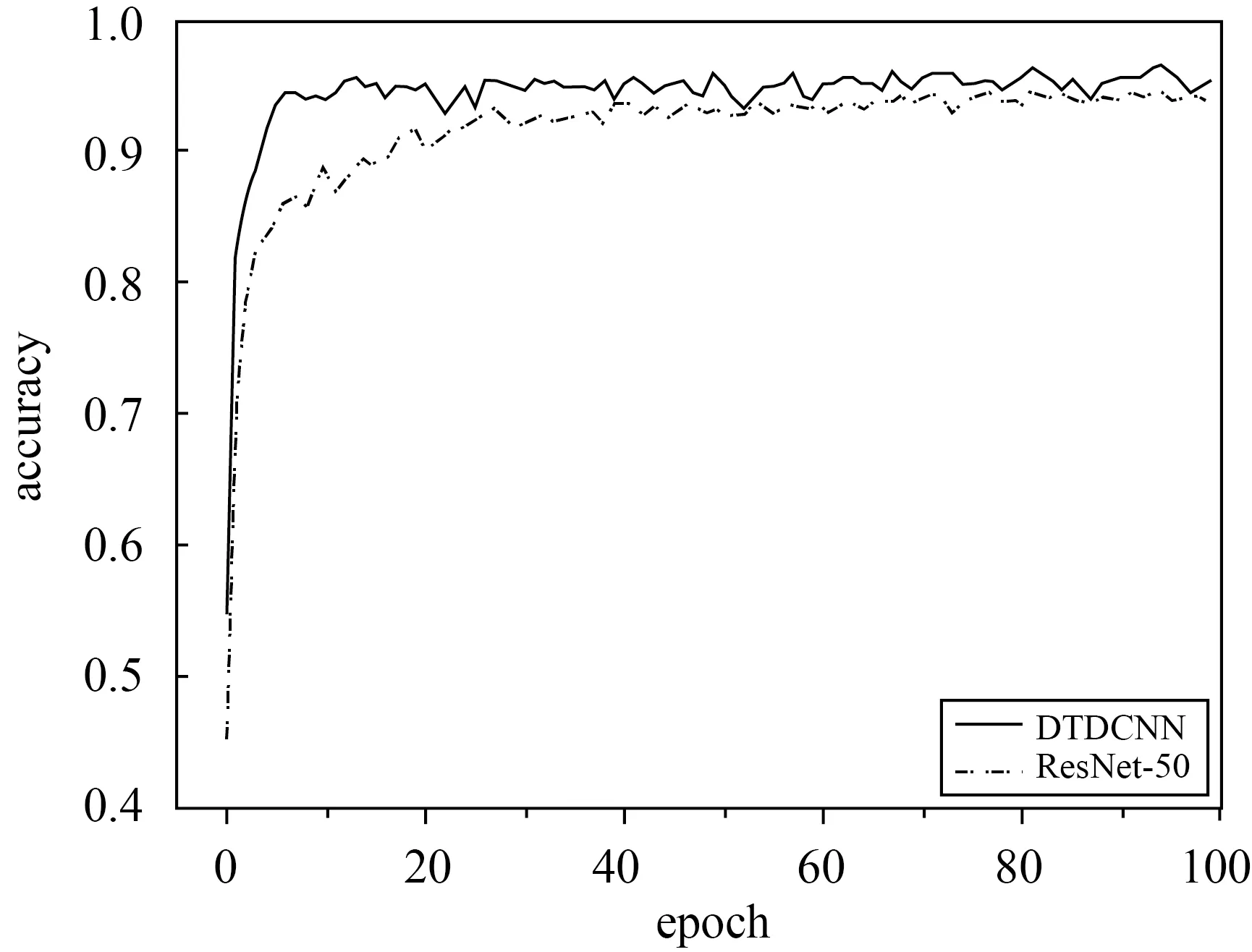
圖7 UC-Merced數據集分類精度變化曲線Fig.7 Classification accuracy variation curve of UC-Merced dataset
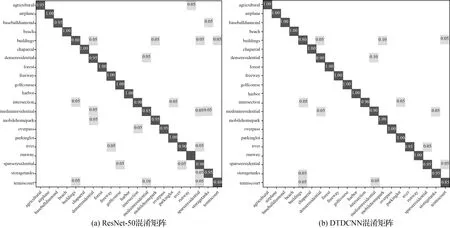
圖8 UC-Merced數據集混淆矩陣結果Fig.8 Classification confusion matrix of UC-Merced dataset
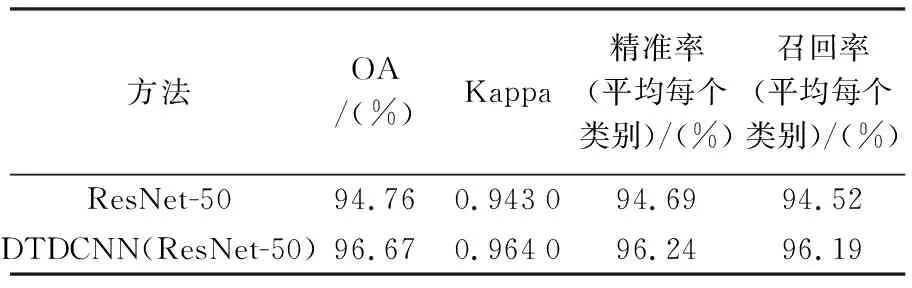
表2 比較模型在UC-Merced數據集上的OA、Kappa、精準率和召回率
2.2.3 NWPU-RESISC45數據集分類試驗結果與分析
NWPU-RESISC45數據集[28]是由西北工業大學創建的遙感圖像場景分類可用基準,比AID和UC-Merced數據集更為復雜,該數據集包含像素大小為256×256,涵蓋45個場景類別,其中每個類別有700張圖像,共計31 500張圖像。該數據集涵蓋了全球100多個具有發展中、轉型中和高度發達經濟體的國家和地區,是目前屬于較大規模的數據集,同時場景影像在平移、空間分辨率、視點、物體姿勢、照明、背景和遮擋方面存在很大差異,具有很大的組內差異性和組間相似性。
基于本文所提出方法對更具有挑戰性的大型場景數據集NWPU-RESISC45(圖9)上進行場景分類試驗(20%訓練集比率,每類別140張作為訓練樣本,560張作為測試數據)得到結果見表3,可見在采用本文所提出的基于遷移可變形卷積的網絡模型方法后精度提高了4.83%,Kappa系數提高了0.041 1。在更具有挑戰性的數據集上可變形卷積的優勢更為明顯,不僅在初始精度上有非常明顯的提升,在整體上精度都得到了明顯提升(圖10)。由圖11所給出的混淆矩陣可以看出,宮殿與教堂場景由于存在相似建筑風格而導致產生混淆現象較為嚴重,露天體育場與田徑場同樣由于相似的結構也產生了混淆現象,但相對于ResNet-50模型本文所提出的添加可變形卷積層的方法都對易產生混淆現象的場景辨別有不同程度的提高,如籃球場和網球場、島嶼和河流等場景都減少了混淆現象的發生。

圖9 NWPU-RESISC45數據集示例Fig.9 Example images of NWPU-RESISC45 dataset
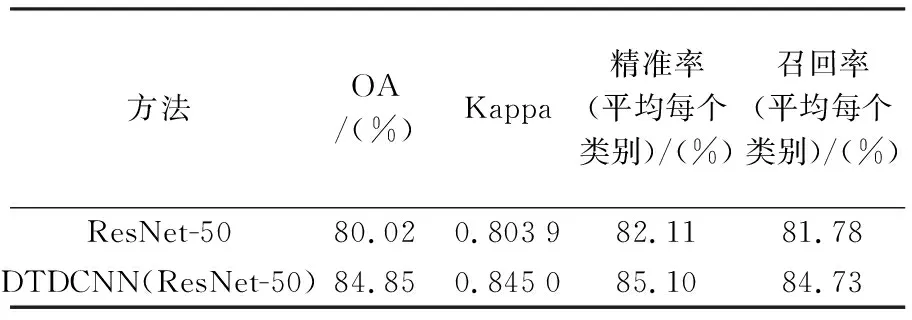
表3 比較模型在NWPU-RESISC45數據集上的OA、Kappa、精準率和召回率
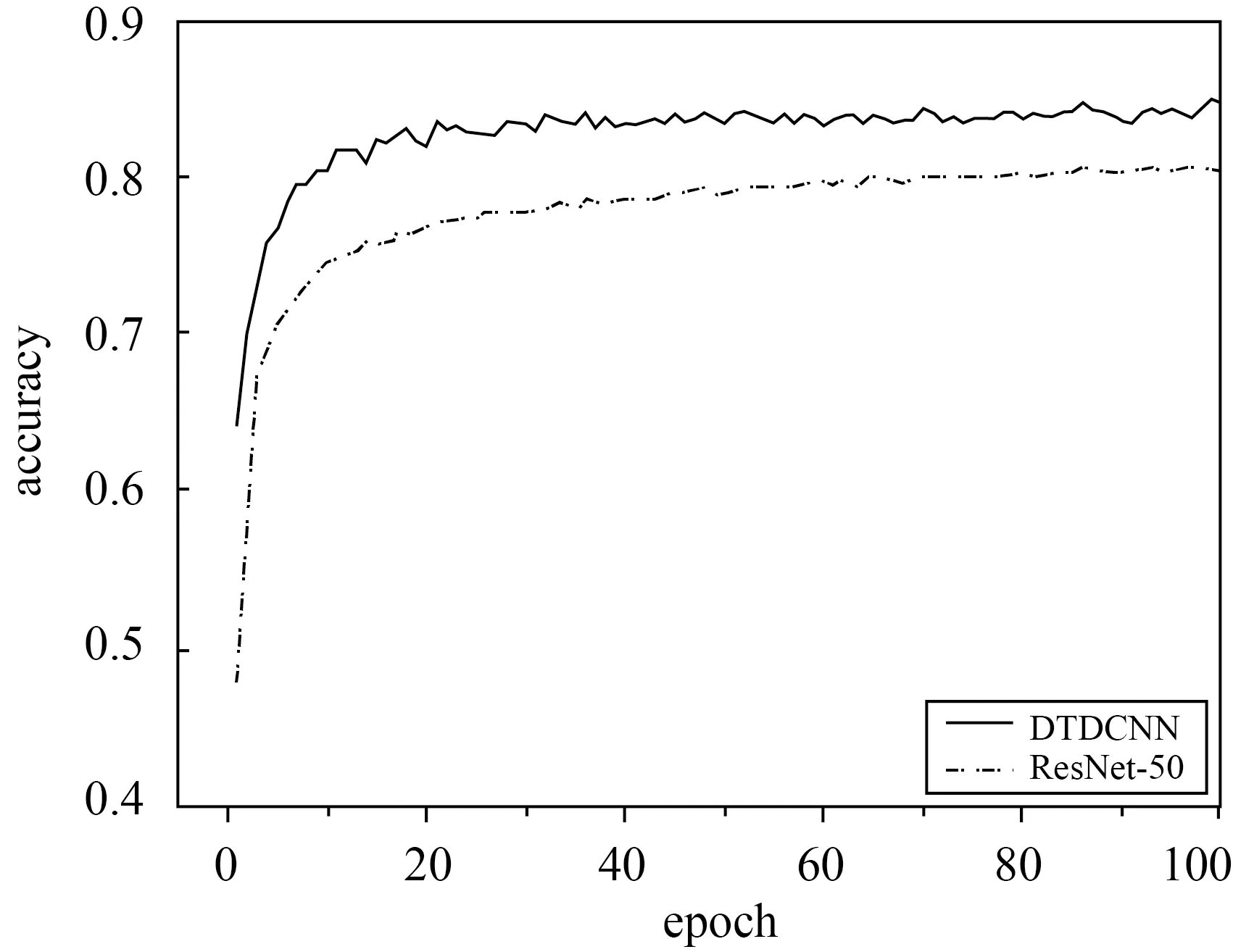
圖10 NWPU-RESISC45數據集分類精度變化曲線Fig.10 Classification accuracy variation curve of NWPU-RESISC45 dataset
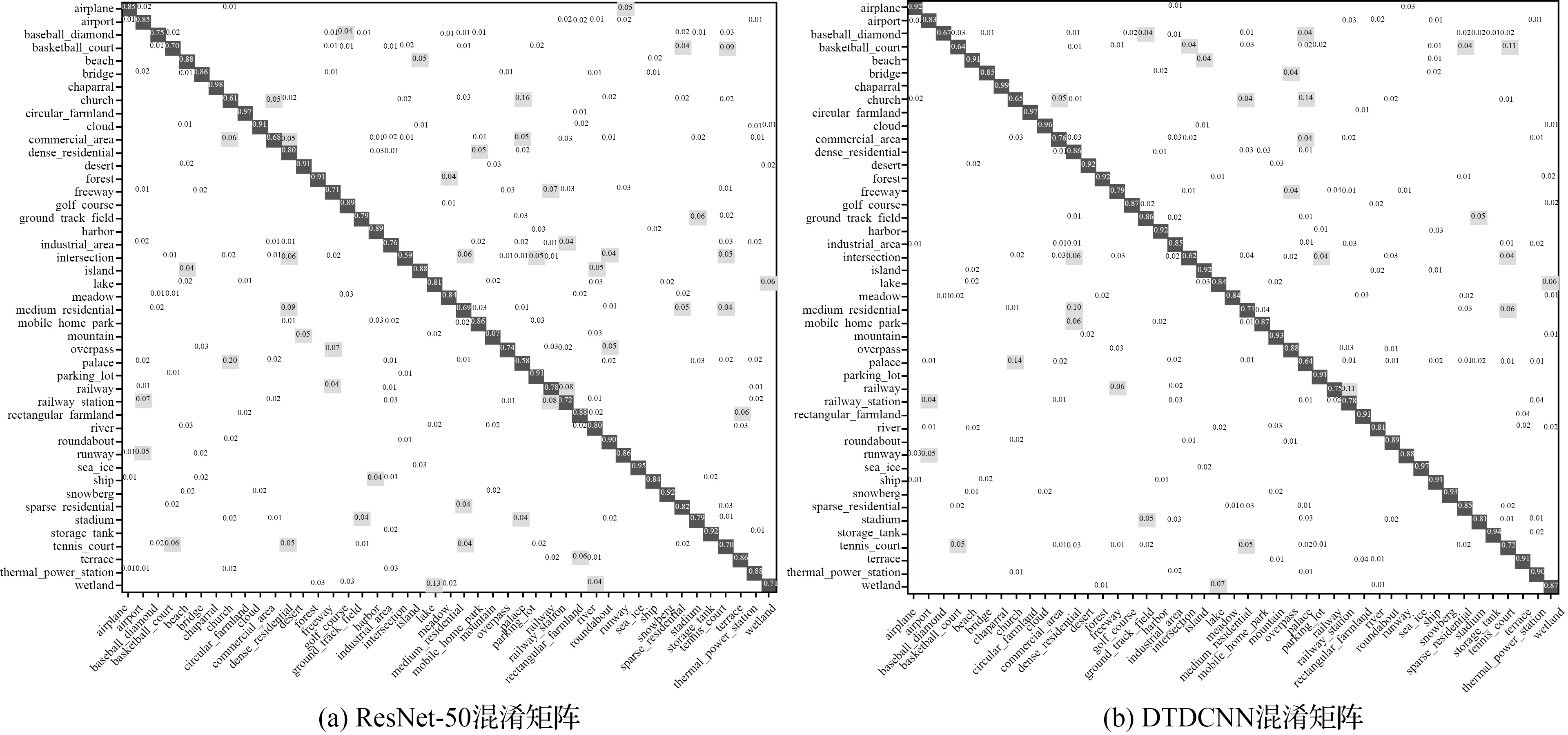
圖11 NWPU-RESISC45數據集混淆矩陣結果Fig.11 Classification confusion matrix of NWPU-RESISC45 dataset
2.2.4 與其他方法對比結果
綜上所述,基于3個具有不同挑戰性的場景數據集分類試驗結果可以看出: 利用遷移學習的基礎模型在高分辨率遙感場景分類上已經具有一定的泛化能力,而本文所提出的DTDCNN模型在基礎網絡模型上添加具有偏移量的采樣模塊,更好地學習目標特征,有效解決了同類物體不同位置、不同類具有相似特征等容易產生混淆的現象,提高了目標數據集分類精度。與近年其他場景分類方法進行對比,為方便比較模型整體性能,選擇了與本文在數據集的選擇和試驗設置較為接近的研究方法,結果見表2。由表2中可以看出,本文所提方法在各數據集上的精度相比于其他方法精度都具有一定優勢,與MF-WGANs[29]相比,在較大型數據集上表現更為優秀,與Siamese ResNet-50[30]相比則在小型數據集上更占優勢; DCA Fusion[31]采用特征融合策略較好地提高了分類精度,與DTDCNN模型精度較為接近;VggNet-16-EMR[32]基于CNN模型獲得的特征采用EMR和VLAD進行處理后分類,在UC-Merced數據集上表現優秀,但對于其在大尺寸遙感數據集上的表現是未知的。高分遙感場景數據集分類任務對于場景特征的學習和判別尤為重要,本文所提方法通過將預訓練模型與可變形卷積層進行結合,明顯提高了對場景特征的學習能力,與其他方法相比則具有更高的性能。因此總體上說明DTDCNN在場景分類上仍是具有較大潛力,驗證了其在遙感場景分類任務上的有效性。
同時,為驗證DTDCNN在不同模型基礎上是否具有普適性,本文采用該方法基于VggNet-16模型進行試驗,如表4結果顯示,所提DTDCNN模型對于不同數據集得到結果都較原始模型有不同程度的提高,驗證可變形卷積與其他CNN模型組合時優勢仍然存在,說明所提方法具有普適性。
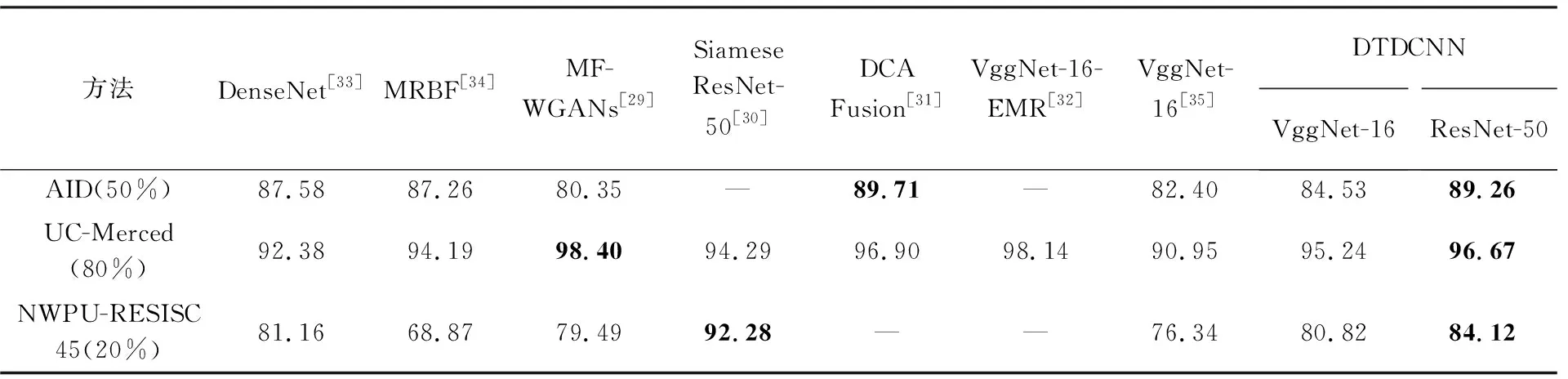
表4 各種方法分類精度
3 結 論
針對現有深度卷積神經網絡對遙感場景影像的幾何形變不具有穩健性等問題,本文提出了一種面向高分遙感影像場景分類的DTDCNN模型。該方法首先基于大型自然場景數據集ImageNet上訓練的深度模型提取遙感影像的深度特征,通過添加可變形卷積層增加了模型對遙感影像中幾何形變穩健深度特征的學習能力,在AID、UC-Merced和NWPU-RESISC45數據集上都取得了較好的結果。該方法僅增加很少的模型復雜度和計算量,在精度上較普通模型有明顯提高,使得模型性能得到較為明顯的提升。根據試驗結果不難發現,精度提升主要來源于一些具有明顯相同特征的場景類別,例如池塘和河流、體育場和體育館、中等密度住宅區和高密度住宅區等,驗證了所提方法在高分辨率遙感場景分類具有較為明顯優勢,同時所提方法在時間性能上也同樣有著較為出色的表現。在接下來的研究中可針對該方法進一步優化提升分類精度,同時也可將該方法應用于高分辨率遙感影像土地利用分類、遙感特征地物的提取[36]等實際問題的解決或結合光譜數據[37]獲取圖像特征進行分類作為下一步研究目標。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中華詩詞(2020年1期)2020-09-21 09:24:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
