基于AI算法的無線網絡鄰區關系優化研究與實踐
2021-06-18 01:05:58李張錚董帝烺中國聯通福建省分公司福建福州350000
郵電設計技術 2021年5期
李張錚,陳 鋒,董帝烺(中國聯通福建省分公司,福建福州 350000)
0 引言
在無線網絡優化工作中,鄰區優化是降低掉話率、提升移動網絡質量、改善用戶感知的最基本且最有效的手段。目前基站鄰區優化有2 種方式:自動鄰區關系(ANR)和非自動鄰區關系(下文簡稱非自動鄰區關系網絡為傳統網絡)。具備自動鄰區關系的網絡可自動優化鄰區關系,不需人工干預;傳統網絡鄰區關系需優化人員手工優化。這些網絡鄰區的數目眾多,優化工作量非常大;需要優化鄰區的確定與個人優化經驗有很大的關系,稍有不慎就可能造成鄰區漏配或冗余鄰區,存在較大的優化風險。規避上述問題,提高鄰區優化的效率和精度已成為網絡優化的關鍵。考慮到在ANR 網絡中,自動鄰區關系已成為小區SON 功能的標配,無需人員操作網絡便可自動識別和添加鄰區,如何利用ANR 鄰區關系來優化傳統網絡鄰區已成為網絡運營智能化的重要課題。
機器學習技術作為人工智能的重要組成部分,是國家發展戰略重點扶持的目標和當下各行業關注應用的焦點。為了推動傳統網絡鄰區優化的智能化,提升網絡運營智能化水平,特開展基于機器學習算法的鄰區關系優化的研究。
1 傳統無線網絡鄰區關系優化難點
在傳統網絡優化中,鄰區關系優化一直以來是一個難點。由于鄰區關系數量多、影響大、技術要求高、優化手段匱乏等等方面的因素,使得鄰區關系優化在傳統網絡中存在一些挑戰。
1.1 鄰區關系數量多,導致優化耗時耗力
以福州聯通為例,W 現網有小區25 000 個,用每個小區有20~25 條鄰區來計算,所配置的鄰區個數至少50萬條以上,網優人員每周提取MR數據,使用廠家工具進行同頻、異頻鄰區核查,根據核查結果,確定需要優化的鄰區,并進行相應操作,鄰區優化的工作量非常大。
1.2 鄰區關系影響面大,直接關系網絡口碑
鄰區設置不當,會導致干擾增大、容量下降和性能惡化,嚴重影響用戶感知,引發的掉話等問題會導致用戶投訴,給運營商網絡口碑帶來負面影響,影響NPS 得分。鄰區設置不當主要有2 種表現方式:鄰區漏配和冗余鄰區。鄰區漏配會引起干擾增大,降低用戶的通話質量甚至掉話,從而引起容量及覆蓋能力下降;冗余鄰區一方面將會由于切換的過多會導致信令負荷加重;另一方面由于終端測量能力的限制,會降低測量的精度、增加測量時延。同時信號較多會造成干擾,容易出現掉話,影響速率的提升,從而影響用戶感知。
1.3 鄰區關系優化手段缺乏,對技術要求高
傳統的鄰區關系優化手段有2 種:基于路測軟件分析和基于廠家的鄰區核查工具平臺。
a)路測軟件分析。基于導頻的小區切換關系來定位鄰區關系合理性,該方法的局限性是路測范圍有限,覆蓋面不足,無法開展全網的精細鄰區優化,且路測方法耗時耗力。
b)基于廠家的鄰區核查平臺。通過采集UE 上報的測量報告、話統呼叫記錄、事件進行匯總分析,判斷鄰區漏配和冗余。該方法有較高的精確性,但受限于廠家License配額和優化人員的技術水平。
2 基于XGBoost算法的小區切換占比預測
隨著運營商移動用戶數的不斷增加,良好的用戶網絡體驗保障對無線網絡運營提出了更高的要求。影響無線網絡質量的因素很多,其中鄰區關系是一個關鍵因素,它是小區移動性管理的直接承載者。做好鄰區關系優化,始終是網優工作的重點。
本文通過利用XGBoost 機器學習算法學習ANR現網鄰區關系數據,建立小區間切換次數占比模型預測出傳統網絡小區的鄰區關系。該模型可在開站鄰區配置、鄰區核查、用戶投訴分析等網優日常工作中起到積極作用。
2.1 訓練集和測試集樣本生成
2.1.1 樣本的采集
提取某省聯通2 個行政區LTE 網絡3 天的兩兩小區切換次數報表,匯總每個小區鄰區的切換次數占比降序排列,取每個小區占比前50 名的鄰區作為樣本,切換占比為樣本標簽,同時關聯網絡工參相關字段(見表1),形成最終樣本。
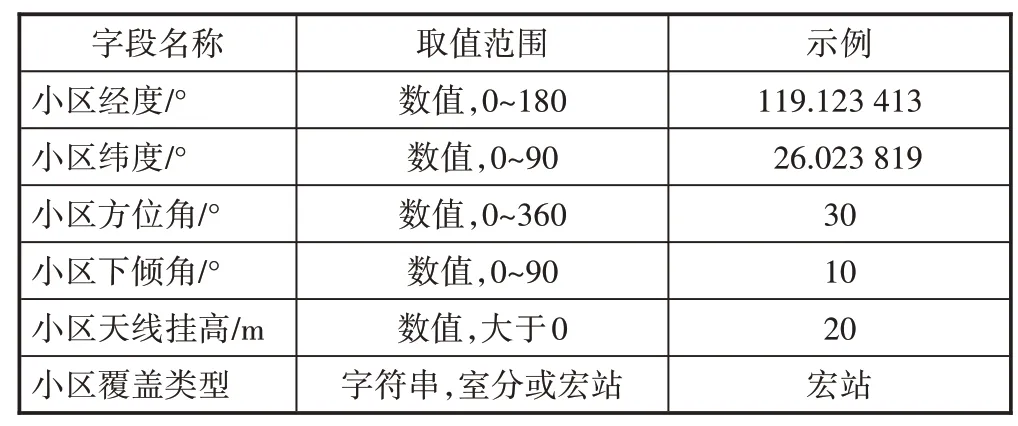
表1 網絡工參字段
2.1.2 樣本劃分為訓練集和測試集
機器學習一般將樣本劃分為訓練集和測試集,訓練集用于模型訓練,測試集用于測試模型性能。本文利用sciki-learn 的train_test_split()函數將樣本劃分為訓練集和測試集,其中參數測試集比例test_size 取0.2,即訓練集和測試集比例為8∶2。
2.2 數據預處理
數據預處理主要是檢查每個特征是否有缺失值或非法字符,對不合理的值進行校正替換。檢查樣本數據發現,覆蓋類型為室分的小區方位角都是0值,這與實際室分小區為全向覆蓋不符,故室分小區的方位角需修正。修正方法如下:若室分小區與宏站鄰小區同經緯度,則室分小區取宏站鄰小區的方位角;若室分小區與室分鄰小區同經緯度,則室分小區方位角取值368°;若室分小區與鄰小區不同經緯度,則室分小區方位角取室分小區與鄰小區連線與正北方向的順時針夾角r(見圖1)。
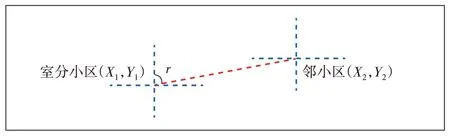
圖1 室分小區方位角定義
設室分小區經緯度(X1,Y1),鄰小區經緯度(X2,Y2),具體小區連線夾角r計算公式如下:
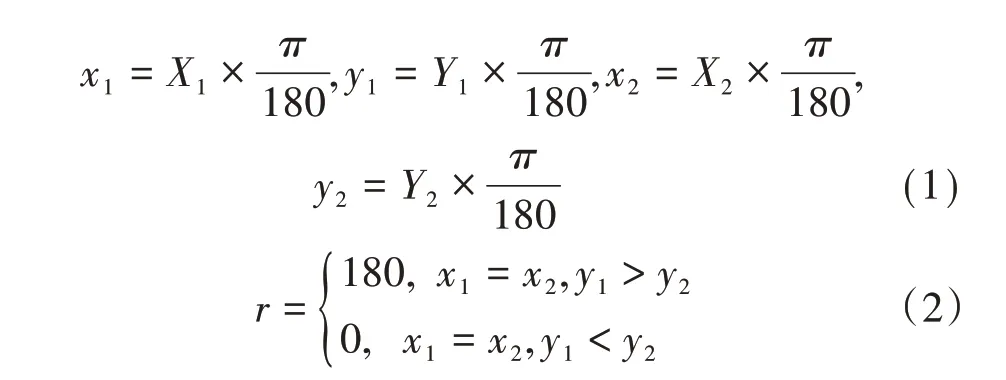
為了便于書寫,令

圖2給出了室分小區方位角特征預處理過程。

圖2 室分小區方位角特征預處理
2.3 特征工程
特征工程是機器學習過程的重要環節,樣本特征的好壞決定了機器學習性能的上限,而模型只是逼近這個上限而已。特征工程的主要內容包括特征構造、特征抽取和特征選擇。本文的原始特征包括本地/目標小區經緯度、本地/目標小區方位角度、本地/目標小區合計下傾角度及本地/目標小區天線掛高10 個維度。為了滿足特征選擇的需要,在此基于本地/目標小區的經緯度構造額外的特征,主要包括haversine距離、兩經緯度的方位角、經緯度PCA 分量,最后進行特征選擇。
2.3.1 haversine距離
haversine 公式是計算球面兩點間距離的一種方法,該方法采用了正弦函數,即使距離很小,也能保持足夠的有效數字。haversine距離計算公式如下:
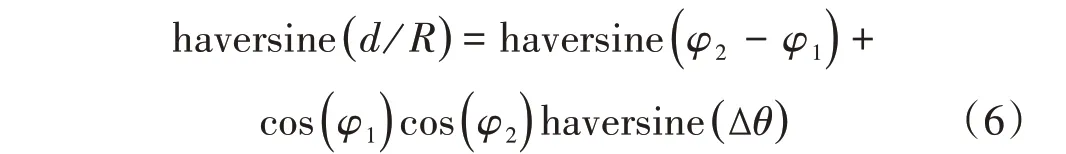

圖3 本地/目標小區haversine距離計算
2.3.2 兩經緯度的方位角
設本地小區經緯度為(lat1,lng1),目標小區經緯度為(lat2,lng2),兩經緯度間的方位角公式計算如下,代碼實現如圖4所示。

圖4 2個經緯度間的方位角計算
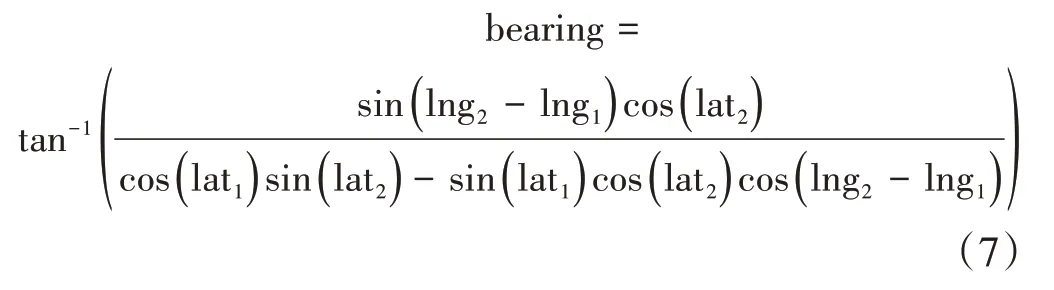
2.3.3 經緯度的PCA分量
主成分分析(PCA——Principal Component Analysis)是最廣泛的數據壓縮算法,主要通過降維可以生成更便于人理解的新特征,加快對樣本有價值信息的處理速度。此處對本地/目標小區經緯度4 個特征采用PCA 進行變換,默認降維后的特征數仍為4(見圖5)。

圖5 本地/目標小區經緯度的PCA變換
2.3.4 特征/目標相關性分析
特征選擇不僅具有減少特征數量(降維)、減少過擬合、提高模型泛化能力等優點,而且還可以使模型獲得更好的解釋性,增強對特征和特征值、特征和目標之間關系的理解,加快模型的訓練速度獲得更好的預測性能。此處采用pandas 的相關系數計算函數corr()來分析特征和目標間的相關性(見圖6和表2)。
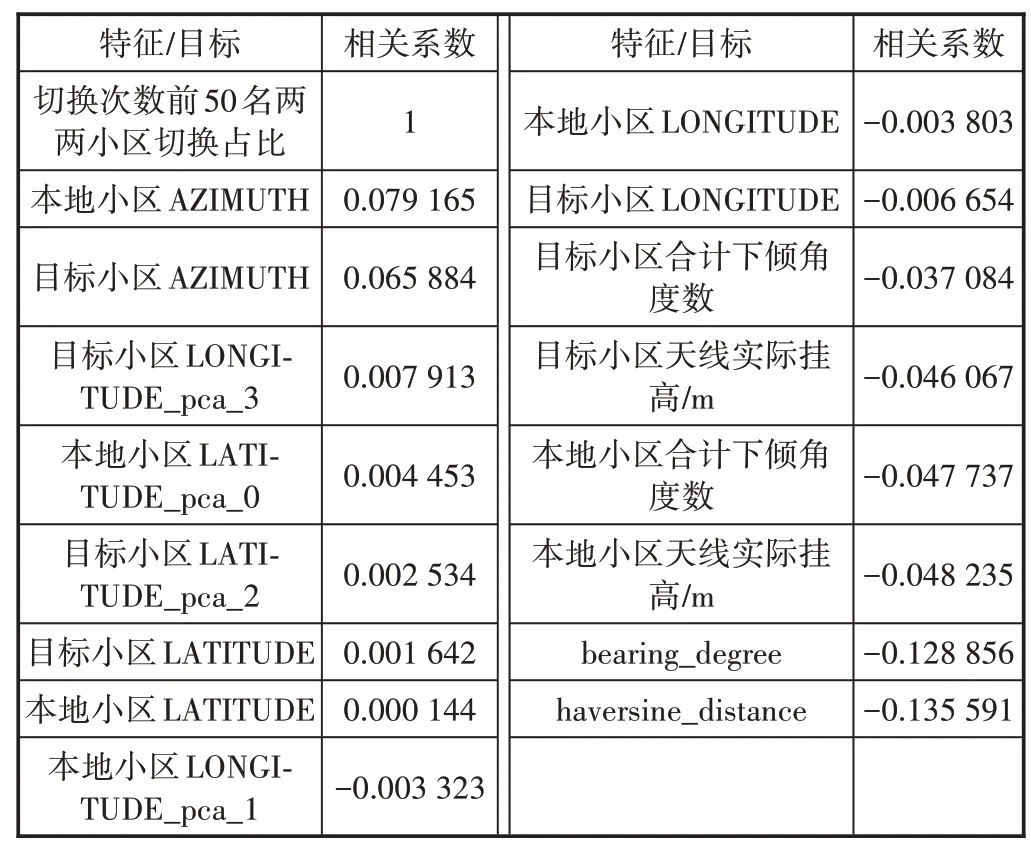
表2 特征和目標間的相關系數值
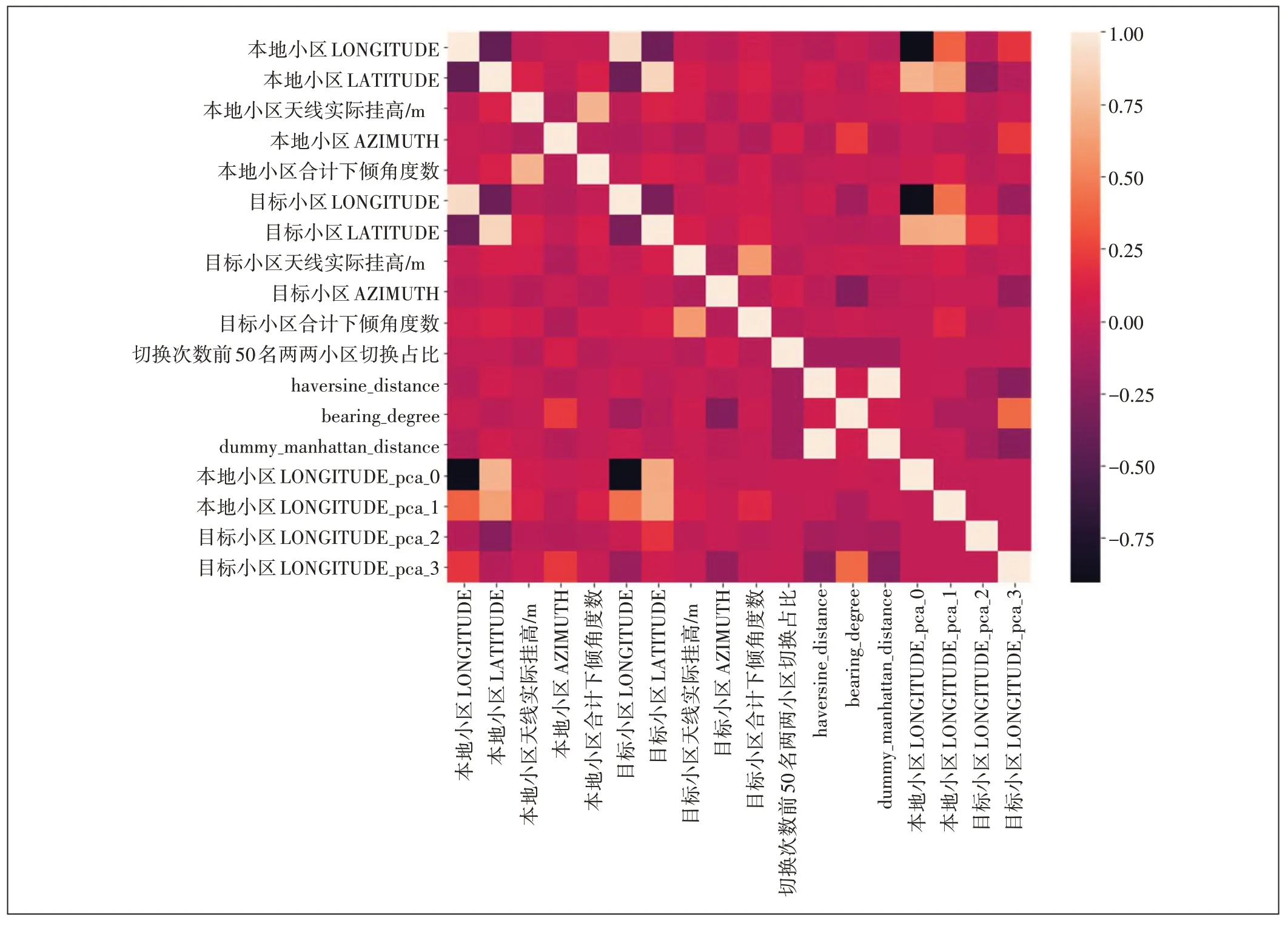
圖6 特征和目標間的相關性熱力圖
從熱力圖上可以發現,部分特征間的相關性過高,這將造成特征間的多重共線性,影響模型效果,這里剔除相關系數大于0.8 的特征(包括本地小區LATITUDE,本地小區LATITUDE_pca_0,本地小區LONGITUDE),保留與目標相關性最大的特征。
2.3.5 特征標準化
特征標準化就是將某列特征的值縮放到均值為0,方差為1 的狀態,計算公式為標準化的好處是提升模型精度和加快收斂速度。此處使用scikit-learn自帶的StandardScaler()類進行轉換。
2.4 模型訓練
2.4.1 基于交叉驗證的回歸預測模型選擇
機器學習中常用的回歸預測模型有線性回歸、KNN、隨機森林、GBDT 和XGBoost 等。這里分別使用這幾個模型進行交叉驗證打分,選出最好的模型。這些模型的參數都取默認值,交叉驗證參數取5,評估標準為平均絕對誤差MAE。實驗結果表明,最好的模型為XGBoost,平均cross_val_score 得分最高為-0.03(見圖7)。下面就使用XGBoost模型進行建模訓練。

圖7 基于交叉驗證的回歸模型選擇
2.4.2 XGBoost算法原理概述
XGBoost 算法近年來在工業界和各類數據挖掘競賽中大放異彩,取得良好的預測效果。與傳統的Boosting 算法如GBDT 比較,XGBoost 算法優點在于:GBDT只利用了一階導數的信息,而XGBoost對損失函數做了二階泰勒展開,并且在目標函數中加入了正則項,用來權衡目標函數和模型的復雜程度,防止過擬合;Boosting 是串行過程,不能并行化且計算復雜度較高,也不適合高維稀疏特征,而XGBoost 在特征粒度上可進行并行化計算且考慮了訓練數據為稀疏值的情況。該算法原理如下:
XGBoost 算法的目標函數包含損失函數L和正則化項Ω:
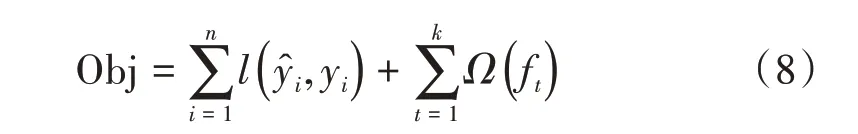
根據第t步的新模型的預測值ft(xi),此時的目標函數可寫成:
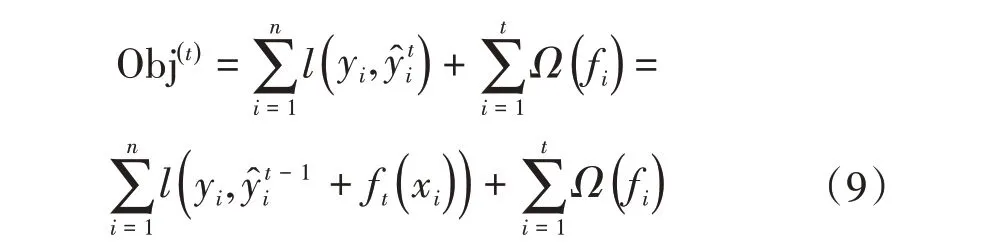
利用泰勒公式將目標函數進行泰勒二階展開,得
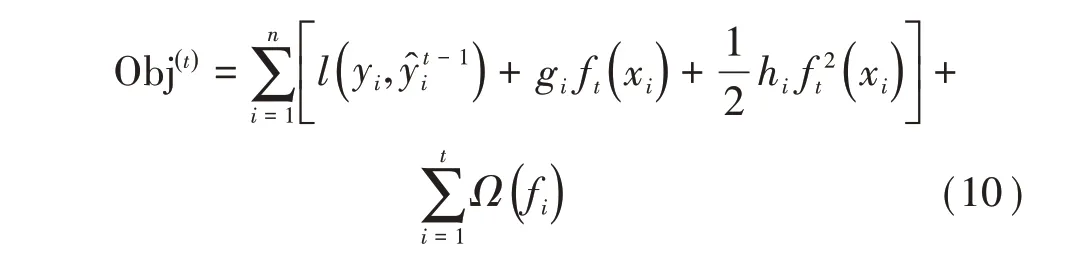
其中gi為損失函數一階導數,hi為損失函數的二階導數。當損失函數取平方損失時,目標函數近似為:
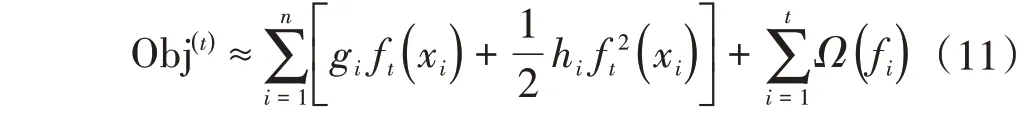
進一步地,基函數取為決策樹模型ft(x)=ωq(x),q(x)表示樣本x所在的葉子節點,同時設決策樹葉子節點數為T,該值決定了決策樹的復雜度,值越大模型越復雜,此時目標函數的正則項表示為:
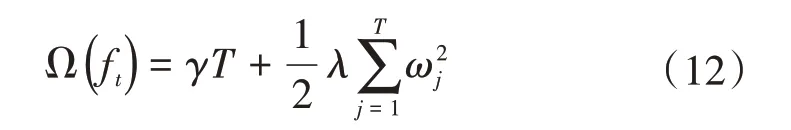
由于每個樣本xi最終都是落在葉子節點上,且每個葉子節點都會包含多個樣本,因此遍歷所有樣本xi求損失函數等價于遍歷所有葉子節點求損失函數,設第j個葉子節點包含的樣本集合為Ij={i},則損失函數為:
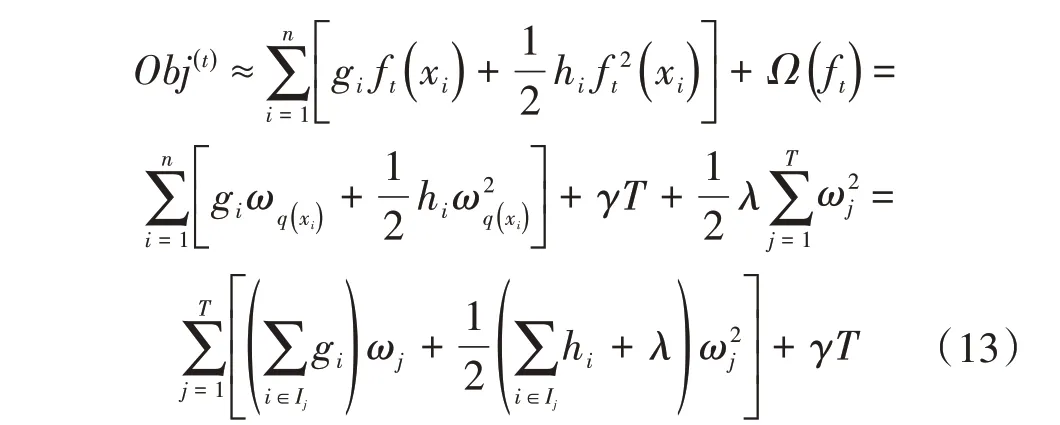
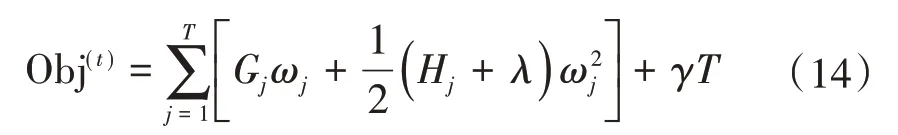
接著對ωj求一階導數,并使之為0,得葉子節點j對應的權值和最優目標函數為:
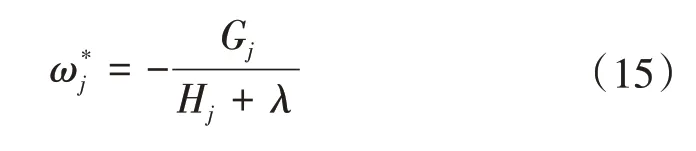
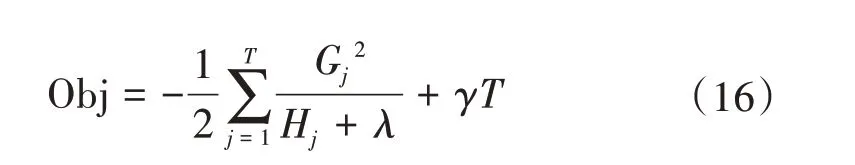
2.4.3 基于網格搜索的XGBoost模型超參數調整
XGBoost 模型的超參數分2 類:第1 類負責控制模型的復雜度,第2類用于增加隨機性,從而使得模型在訓練時對噪聲不敏感。下面介紹調參重點關注的超參數:
a)eta,學習率,默認為0.3,范圍為[0,1]。
b)gamma,最小劃分損失,它是對于一個葉子節點,當對它采取劃分之后,損失函數的降低值的閾值,默認為0。
c)max_depth,每棵子樹的最大深度。其取值范圍為[0,∞],0 表示沒有限制,默認值為6。該值越大,則子樹越復雜;值越小,則子樹越簡單。
d)min_child_weight,子節點的權重閾值。表示對于一個葉子節點,當對它進行劃分之后,它的所有子節點的權重之和的閾值。該值越大,則算法越保守。默認值為1。
e)subsample,對訓練樣本的采樣比例。取值范圍為(0,1],默認值為1。
f)colsample_bytree,構建子樹時,對特征的采樣比例。取值范圍為(0,1],默認值為1。
g)lambda,正則化系數(基于weights 的正則化),默認為1。該值越大則模型越簡單。
h)alpha,正則化系數(基于weights 的正則化),默認為0。該值越大則模型越簡單。
本文利用scikit-learn庫自帶的GridSearchCV 網格搜索算法來調整XGBoost算法超參數(見圖8),候選超參數值集合如下:

圖8 基于GridSearchCV的XGBoost模型超參數調整

最終得到的最佳超參數組合是:{′alpha′:0.85,′colsample_bytree′:0.7,′eta′:0.05,′gamma′:0,′lambda′:5,′max_depth′:18,′min_child_weight′:1,′n_estimators′:200,′subsample′:1}。在測試集上進行評估,平均絕對誤差MAE為0.005 10。
2.4.4 基于ANR 網絡切換占比模型的傳統網絡小區鄰區關系預測
對需優化鄰區關系的傳統網絡小區選取5 km 范圍內的周邊小區,根據切換占比模型特征采集數據,構成樣本輸入模型進行預測。實驗結果表明,對現網真實鄰區關系的命中率為60%,即60%的現網鄰區出現在預測出的占比前50名小區中。
3 總結
傳統網絡小區鄰區優化是網優工作的重點和難點,人工優化方法費時費力。通過引入機器學習算法學習ANR 網絡的鄰區關系建立切換次數占比模型可模擬真實的傳統現網鄰區關系情況,極大程度地提高了鄰區優化效率和用戶網絡口碑。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
