弱監(jiān)督對抗數(shù)據(jù)增強的細粒度視覺分類算法
2021-06-11 03:53:58司學飛張起貴
電子設計工程 2021年11期
司學飛,張起貴
(太原理工大學信息與計算機學院,山西晉中 030600)
細粒度視覺分類(FGVC)任務著重于將對象的子類別與同一類別區(qū)分開,例如鳥類、汽車和飛機模型。由于高級圖像識別、智能農業(yè)技術、智能零售和智能交通等的廣泛應用,近來FGVC 引起了廣泛的關注。與傳統(tǒng)的圖像分類任務不同,F(xiàn)GVC 極具挑戰(zhàn)性,僅靠最新的粗粒度卷積神經網絡(CNN),例如VGG、ResNet 和Inception,很難獲得準確的分類結果。正如最近的研究表明,F(xiàn)GVC 的關鍵步驟是在多個對象部位中提取更具區(qū)分性的局部特征。但是,很難定義對象的各個部分,并且各個對象之間的差異也很大。此外,標記這些對象的零件需要額外的人工費用。在這項工作中,文中利用弱監(jiān)督學習,僅通過圖像級注釋來定位對象的區(qū)別性部位。文中不是關注區(qū)域邊界框,而是通過卷積生成的注意力圖來表示對象的部分或視覺模式。文中還提出利用雙線性注意力模型和以對抗數(shù)據(jù)擴充為導向的數(shù)據(jù)增強方法來增強注意力集中過程。與其他本地化模型相比,該模型可以更輕松地定位大量對象部位(超過20 個),從而獲得更好的性能。此外,還提出聯(lián)合優(yōu)化方法解決因自然圖像的長尾分布[1]而導致的訓練問題。
1 相關工作
1.1 細粒度視覺分類
細粒度視覺分類一直是計算機視覺領域研究的熱門話題之一。為了解決大規(guī)模圖像分類問題,提出了卷積神經網絡(CNN)。但是經過研究發(fā)現(xiàn),這些基本模型只能實現(xiàn)中等性能,如果沒有特殊設計,其很難集中精力于目標部位的細微差別。
為了更多關注局部特征,許多方法都依賴于部位位置或屬性的注釋。Part R-CNN[2]擴展了R-CNN[3]來檢測對象,并在幾何先驗條件下定位它們的部位,然后從姿勢歸一化表示中預測出細粒度的類別。文獻[4]提出了一個反饋控制框架Deep LAC,以反向傳播比對和分類錯誤進行本地化。為了減少大量的位置標注成本,僅通過圖像級注釋的方法引起人們的關注。文獻[5-6]提出了雙線性池化[5]和改進的雙線性池化[6],其中使用外部乘積在每個位置組合了兩個特征,并考慮了它們成對的相互作用。MPN-COV[7]通過矩陣平方改善了二階合并,并實現(xiàn)了最新的準確性。
空間轉換網絡(ST-CNN)[8]旨在通過幾何變換和圖像對齊來實現(xiàn)準確的分類。該方法還可以同時定位目標的多個部位。文獻[9]提出的遞歸注意卷積神經網絡(RA-CNN)遞歸地預測一個關注區(qū)域的位置并提取相應的特征,而該方法僅關注一個局部部分,因此將3 個尺度特征(即目標的3 個部位)組合在一起,預測最終類別。文獻[10]提出了MultiAttention CNN(MA-CNN),同時定位多個部位。但是,對象部位的數(shù)量有限(2或4),限制其準確性。文中提出了將注意力層與特征層結合起來的雙線性注意力池,其注意力區(qū)域的數(shù)量更容易增加,并提高了分類準確性。
此外,在FGVC任務中引入了度量學習。文獻[11]提出的多注意多類別(MAMC)損失將正特征拉近錨點,同時將負特征推開。文獻[12]提出的PC 結合成對的混淆損失和交叉熵損失來學習具有更泛化的特征,從而防止過擬合。在該模型中,提出了注意力正則化損失來規(guī)則化注意力區(qū)域和相應的局部特征,從而提高了目標部分的定位和分類準確性。
1.2 數(shù)據(jù)增強
文中的數(shù)據(jù)增強方法專注于圖像的空間增強。在此之前,已經提出了隨機空間圖像增強方法,例如圖像裁剪和圖像丟棄,并被證明可以有效地提高深度模型的魯棒性。Maxdrop[13]的目的是刪除最大激活的功能,以鼓勵網絡考慮不太突出的功能。缺點是Maxdrop 只能刪除每個圖像的一個區(qū)分區(qū)域,從而限制了性能。Hide-and-Seek[14]通過從訓練圖像中隨機遮掩若干正方形區(qū)域來提高CNN 的魯棒性。但是,很多擦除區(qū)域都是不相關的背景,否則可能會擦除整個對象,特別是對于較小的目標。為了克服這些問題,文中考慮了數(shù)據(jù)分配策略,提出對抗性數(shù)據(jù)增強,引用弱監(jiān)督學習領域強有力的網絡模型,生成對抗網絡(Generative Adversarial Nets,GAN)以共同優(yōu)化數(shù)據(jù)增強和深度模型訓練,在線生成部位數(shù)據(jù)以提高深度模型的魯棒性。
2 算法原理及聯(lián)合優(yōu)化
文中詳述了該細粒度視覺分類算法的原理,包括弱監(jiān)督的注意力學習,基于對抗性的數(shù)據(jù)增強和聯(lián)合優(yōu)化。該方法原理結構如圖1 所示。
2.1 弱監(jiān)督注意力學習
該模型的第一部分采用雙線性注意力網絡[15]。將特征圖F與注意力圖A進行逐元素相乘,生成M個部位特征圖Fk,如圖2 所示。
文中主干網絡采用Inception v3,首先,分別生成特征圖集和注意力圖集。通過將每個注意力圖與特征圖逐元素相乘來生成部位特征圖。然后,通過卷積提取特征,最終特征矩陣包含所有這些部位特征。
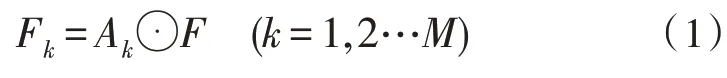
其中,⊙表示兩個張量逐元素相乘。然后,通過特征提取函數(shù)g(·)進一步提取判別性局部特征,例如全局平均池化(GAP),全局最大池化(GMP)或卷積,以獲取關注特征fk∈R1×N。
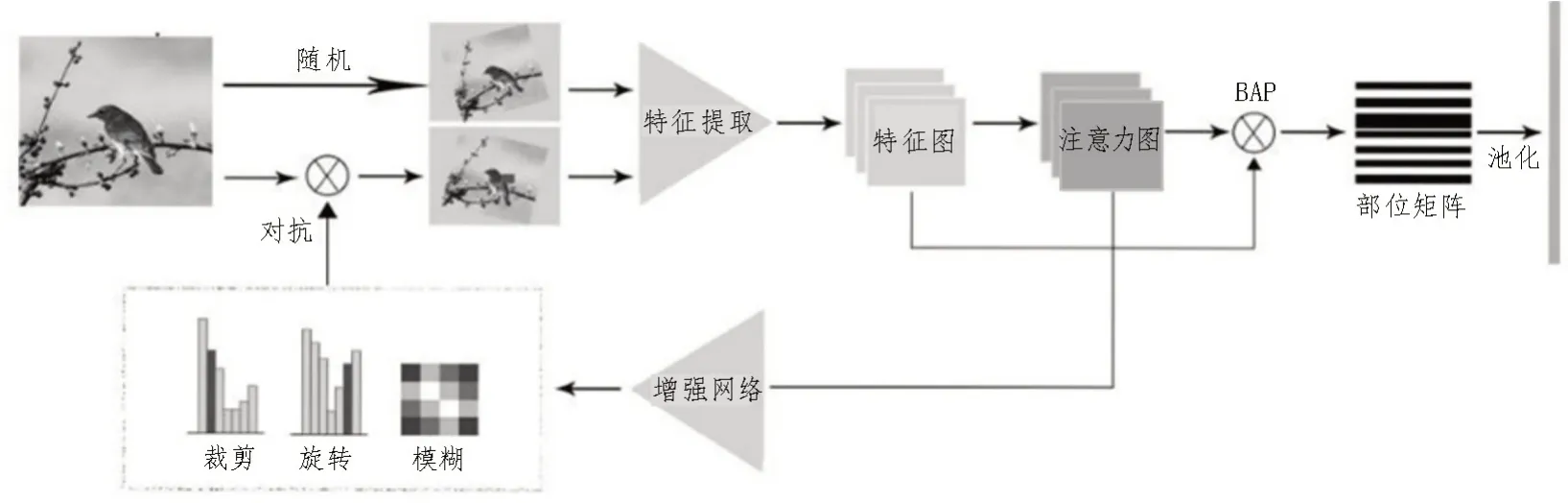
圖1 整體原理圖
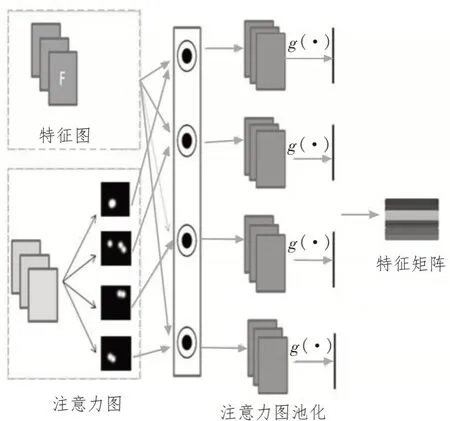
圖2 雙線性注意力模型

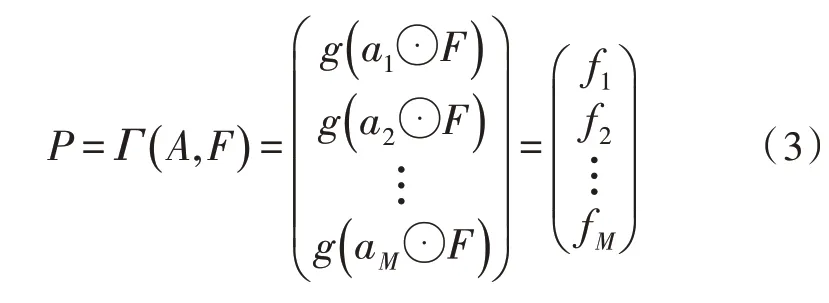
目標的特征由部位特征矩陣P∈RM×N表示,它們是由部位特征fk堆疊而來。用Γ(A,F)表示注意力圖A和特征圖之間的雙線性池化,其可用式(3)表示為:
2.2 對抗數(shù)據(jù)增強
從靜態(tài)分布中采樣的隨機數(shù)據(jù)增強幾乎不能遵循動態(tài)訓練狀態(tài),可能會產生許多無效的變化,文中建議利用對抗學習共同優(yōu)化數(shù)據(jù)擴充和網絡培訓。主要思想是學習一個生成“硬”增強的增強網絡G(·|θG),可能會增加分類網絡的損失。同時分類網絡D(·|θG) 嘗試從對抗性增強中學習,同時評估質量。生成器充當增強網絡,輸出一組擴充操作。在數(shù)學上,增強網絡G通過最大化期望,輸出對抗性增強τa(·)與隨機對抗τr(·)相比可能增加D的損失。
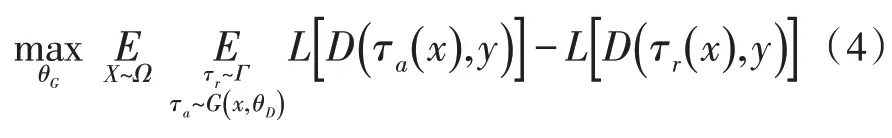
其中,Ω是訓練圖像集,Γ是隨機增強空間,L(·,·)是預定義的損失函數(shù),y是圖像注釋,G的生成要同時滿足輸入圖像X和目標網絡D的當前狀態(tài)。
分類器充當鑒別器有兩個作用:1)評估生成質量;2)通過最小化期望試圖向對抗數(shù)據(jù)學習。
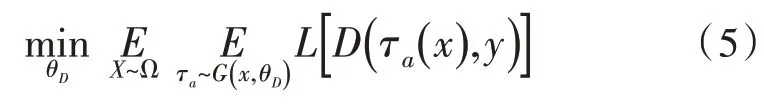
對抗性增強τa(·)可以比隨機增強τr(·)更好地反映D的弱點,從而可以更高效地訓練網絡。
G和D的聯(lián)合訓練是一項艱巨的任務。增強操作通常是不可區(qū)分的,這會阻止梯度在反向傳播中從D流動到G。為解決此問題,提出了獎勵和懲罰策略來創(chuàng)建G的基本信息。因此,可以隨時更新G以遵循D的訓練狀態(tài)。
2.2.1 對抗策略
預訓練增強網絡非常關鍵,這樣它才能在聯(lián)合訓練之前獲得增強分布感。對于每個訓練圖像,總共采樣m×n個增強,每個增強都來自一對高斯。然后,將增強轉發(fā)到目標網絡以計算損失,該損失表示增強的“難度”。將m×n的損失累積到相應的縮放和旋轉箱中。通過將bin 的總和標準化為1,生成兩個概率向量:Pm∈Rm和Pr∈Rn,分別逼近縮放比例和旋轉分布的真值。
除了縮放和旋轉外,增強網絡更重要的是生成遮擋操作,細粒度識別目標部位的位置彼此高度相關。通過遮擋圖像的某些部分,可以激勵特征提取網絡學習可見部分和不可見部位更牢固的關系。與旋轉和縮放不同,要遮擋深層特征而不是圖像像素。具體地,增強網絡生成指示,要遮擋特征的哪一部分的掩碼,從而使主干網絡具有更多的估計誤差。遮擋塊以最低分辨率生成,然后按比例放大,以應用于主干網絡的特征提取層。
2.2.2 獎懲策略
獎勵和懲罰策略的核心思想是,根據(jù)目標網絡的當前狀態(tài)來更新增強網絡的預測,同時通過對比參考評估其質量。為每個圖像采樣了一對增強:對抗增強τa和隨機增強τr。如果對抗增強比隨機增強難,將通過增加采樣bin 或旋轉縮放的概率來獎勵增強網絡。否則,將通過相應地降低概率來懲罰它。用公式表現(xiàn)出來,令表示增強網絡的預測分布,P∈Rk表示要尋找的真實分布。k是旋轉或裁剪的數(shù)量,i是采樣數(shù)量。如果對抗性增強τa與參考值τr相比造成更高的目標網絡損失,通過獎勵更新P:
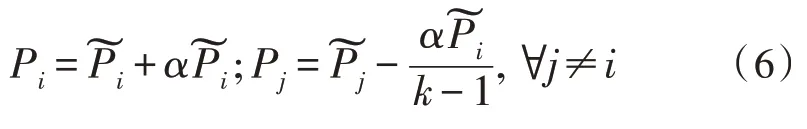
相反,如果τa比τr導致更低的目標網絡損失將通過懲罰更新P:
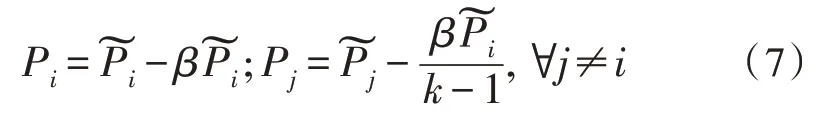
其中,0<α,β≤1 是控制獎勵和懲罰量的超參數(shù)。增強網絡不斷在線更新,而不受獎勵或懲罰,從而產生旨在增強目標網絡的對抗性增強。
聯(lián)合訓練流程如算法1、2 所示。
算法1:小批量訓練方案
輸入:小批量X,增強網絡G,判別網絡D
輸出:G,D
1)將X隨機等分為X1、X2、X3;
2)使用X1訓練D;
從格拉斯哥到盎散克之旅顯然是虛無的,從象征意義上來說,所謂的空間轉換根本不存在,盎散克就是格拉斯哥,或者說是格拉斯哥的反烏托邦版本。貧困、失業(yè)、疾病、壓迫和衰落,這些困擾格拉斯哥的社會問題在盎散克同樣存在,甚至被加以夸大變形,正如科林·曼羅夫所說的那樣,“它關注的都是大城市的問題:政治、社會、藝術和權力機構。”(Manlove 1994:198)
3)根據(jù)算法2 使用X2對G和D進行對抗性縮放和旋轉訓練;
4)根據(jù)算法2 使用X3對G和D進行對抗性分層遮擋訓練。
算法2:單個圖像訓練方案
輸入:圖像X,增強網絡G,判別網絡D
輸出:G,D
1)前向學習D獲得網橋特征f;
2)根據(jù)f前向學習G得到分布P;
3)從P中采樣一個對抗性增強
5)隨機增強x得到
8)更新D。
2.3 網絡結構
傳統(tǒng)意義上,通過輸入層即前饋網絡的第一層如圖3(a)所示,將潛在分布提供給生成器。文中完全省略了輸入層,而是從一個學習到的常量開始,從而偏離了這種設計如圖3(b)所示。給定一個在潛在輸入空間Z中的潛在分布z,一個非線性映射網絡f:Z→W首先產生w∈W(圖1(b),左)。為了簡單起見,設置了兩者的維數(shù)在512 之內,并且映射f是使用8層MLP 實現(xiàn)的。綜合網絡g由18 層組成,每種分辨率為兩層(42-1 0242)。使用單獨的1×1 卷積將最后一層的輸出轉換為RGB。
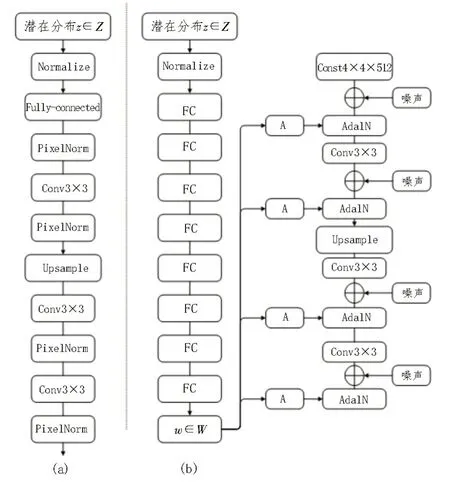
圖3 增強網絡結構圖
3 實 驗
3.1 數(shù)據(jù)集及實驗設置
文中在CUB-200-2011、Stanford Cars 和FGVC Aircraft 數(shù)據(jù)集上全面評估了算法性能,表1 中顯示了3 個數(shù)據(jù)集的統(tǒng)計信息。
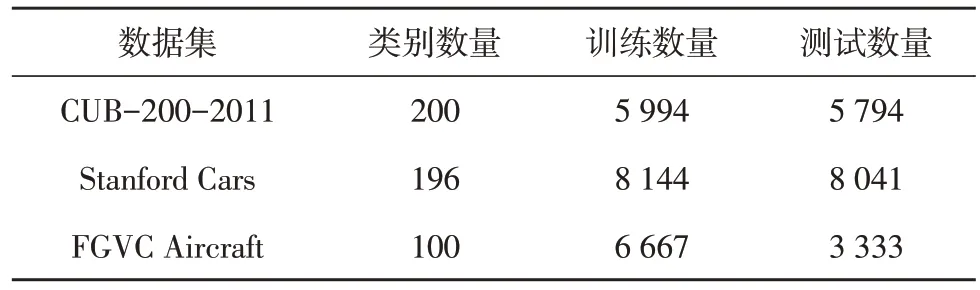
表1 數(shù)據(jù)集參數(shù)設置
使用PyTorch 框架進行實驗,GPU 型號為GTX1080Ti。選擇Mix6e 圖層作為特征圖。注意,圖是通過1×1 卷積核獲得的。采用GAP 作為特征池函數(shù)g(·)。RMSProp[16-18]用于優(yōu)化網絡。對圖像進行預處理,將注意力圖的聚焦點M初設為3。對抗訓練包括3 個階段。首先,訓練鑒別器的幾個紀元,學習速率為0.000 25。然后,凍結鑒別器,并使用它訓練學習率為0.000 25的裁剪旋轉網絡和遮擋網絡。一旦對它們進行了預訓練,就將這兩個網絡的學習率降低到0.000 05,并共同訓練這3 個網絡。驗證精度達到穩(wěn)定水平后,主干網絡的學習率下降到0.000 05。
在CUB-200-2011 數(shù)據(jù)集上對去掉增強網絡的主干網絡進行單獨訓練。主干網絡以Inception v3 為骨干,使用隨機梯度下降(SGD)訓練模型,其動量為0.9,迭代次數(shù)為80,重量衰減為0.000 01,最小批量為16。初始學習率設置為0.001,每兩個周期后指數(shù)衰減為0.9。
3.2 對比實驗及分析
首先,對比具有增強網絡的完備模型和原始模型在3 個數(shù)據(jù)集上的訓練過程中,不同時期對測試集圖像產生的平均注意力圖數(shù)量M的變化,并進行了實驗。如圖4 所示,隨著訓練時長的增加,原始模型可在圖像上學習到的平均最多聚焦點為15個,完備模型在增強網絡的激勵下可將平均最大聚焦點個數(shù)提升至32個,甚至更高。說明該模型可以挖掘更多圖像的區(qū)別特征。然后,在Stanford Cars 數(shù)據(jù)集上進行了關于注意圖數(shù)量M有效性的實驗,表2 顯示隨著M的增加,分類準確率也會提高。當M達到32時,性能逐漸趨于穩(wěn)定,準確率達93.2%。特征池模型使得設置任意數(shù)量的對象部分變得很容易。可以通過增加注意力圖的數(shù)量來獲得更準確的結果。再對比了文中方法與現(xiàn)有一些方法的準確性,并分析衡量了該模型的性能。
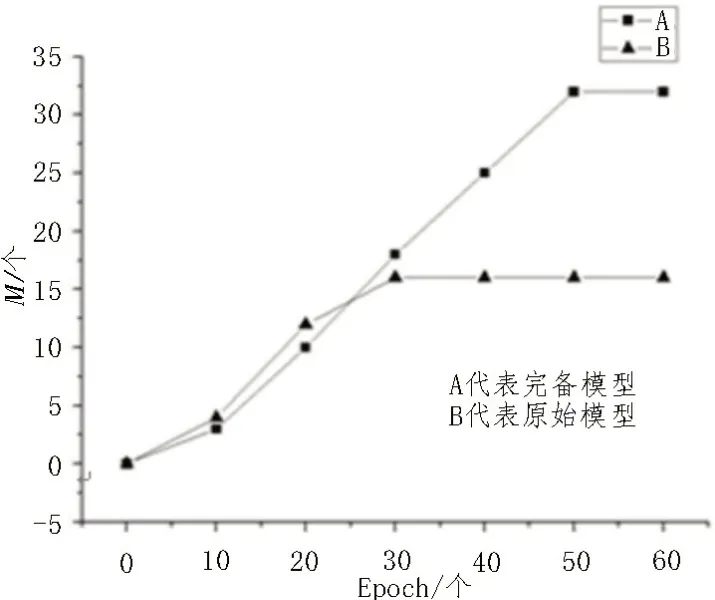
圖4 兩種模型生成注意力圖數(shù)量對比

表2 注意力圖數(shù)量的影響評估
如表3 所示,通過對比可知,文中方法在CUB-200-2011 和FGVC-Aircraft 這兩個數(shù)據(jù)集上的表現(xiàn)優(yōu)于現(xiàn)有方法,在Stanford Cars 上的表現(xiàn)接近現(xiàn)有最先進方法的精度。總體而言,文中的方法在細粒度視覺分類任務中表現(xiàn)良好,具有較高的性能。同時,通過對實驗流程的監(jiān)控,發(fā)現(xiàn)在增強網絡的鼓勵下,主干網絡注意力圖的聚焦點M由初始值3 最大可增加至32。說明該方法可以使網絡關注更多的圖像部位特征。由于鑒別器是通過隨機數(shù)據(jù)增強進行預訓練的。然而,隨著訓練的繼續(xù),分布變得更平坦,這意味著增強網絡可以跟蹤目標網絡的訓練狀態(tài),并生成有效的數(shù)據(jù)增強。
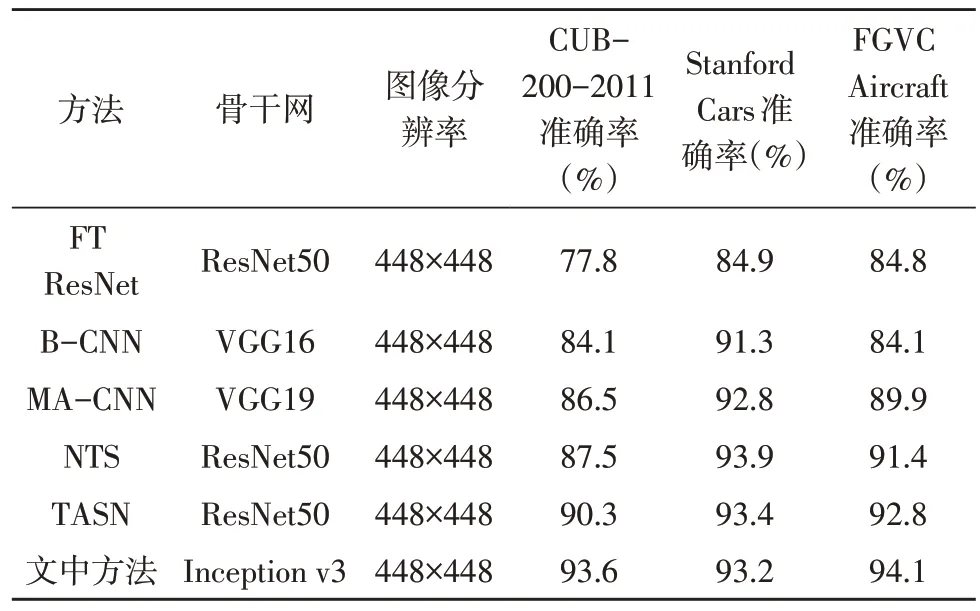
表3 文中方法與已有方法準確率對比
3.3 數(shù)據(jù)增強可視化
如圖5 所示,在CUB-200-2011 和Stanford Cars數(shù)據(jù)集中通過隨機數(shù)據(jù)增強和注意力引導數(shù)據(jù)增強來可視化增強的圖像。直觀地說,隨機數(shù)據(jù)擴充在訓練數(shù)據(jù)中引入了很多背景。注意引導的數(shù)據(jù)增強由于對象部件位置的引導而在裁剪或刪除時更有效。
圖5(a)中隨機裁剪將包含比例較高的背景作為輸入圖像,注意裁剪能準確地定位物體的位置。圖5(b)中注意力下降與隨機下降比較。隨機遮擋可能會從圖像中擦除整個對象,或者只是擦除背景。注意遮擋對于擦除有區(qū)別的對象部分和促進多重注意更為有效。

圖5 注意引導數(shù)據(jù)增強與隨機數(shù)據(jù)增強實驗結果對比
4 結論
文中提出了弱監(jiān)督對抗數(shù)據(jù)增強網絡。將弱監(jiān)督學習與生成對抗網絡(GAN)相結合。弱監(jiān)督學習提供對象的空間分布,增強網絡提供對抗數(shù)據(jù)擴充、鼓勵主干網絡的注意力學習過程。促進模型挖掘更多的具有圖像區(qū)別性的部位特征,以此保證其優(yōu)良的性能。在細粒度視覺分類方面達到了較高的準確率,但是聯(lián)合訓練的穩(wěn)定性也是有待解決的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
