基于改進YOLO v3的自然場景下冬棗果實識別方法
2021-06-09 09:48:22劉天真滕桂法苑迎春劉智國
農業機械學報 2021年5期
劉天真 滕桂法 苑迎春 劉 博 劉智國
(1.河北農業大學信息科學與技術學院, 保定 071001; 2.保定學院信息工程學院, 保定 071000;3.河北省農業大數據重點實驗室,保定 071001; 4.石家莊學院計算機科學與工程學院, 石家莊 050035)
0 引言
隨著果園機械化、信息化管理的推進,果實識別作為機械化采摘、果實產量預測等果園精細化管理的關鍵技術,已成為近年來的研究熱點[1]。河北省是棗種植主產區,冬棗是河北省優勢棗種之一,其種植面積大、產量高,具有重要的經濟價值[2-3]。冬棗園果實密集、枝葉遮擋嚴重、環境復雜,為實現冬棗的機械化采摘,冬棗果實的精準識別與檢測至關重要。
近年來,針對棗類果實的識別檢測問題,許多學者基于傳統機器視覺技術進行了研究[4-6],其中針對靈武長棗采用的基于最大熵彩色圖像分割方法和基于幾何特征的圖像分割算法獲得了較高的準確率。利用傳統機器視覺技術對蘋果、柑橘等常見果實進行識別檢測[7-10]多數采用基于果實顏色和紋理等特征的圖像分割改進方法,其識別準確率高,但檢測速度不足。
傳統機器視覺方法在自然場景下的魯棒性、實時性較差,難以滿足果園信息化管理和機械化采摘的要求。卷積神經網絡在目標檢測方面體現出強大的優勢。卷積神經網絡方法分為兩類:一類基于區域建議方法,采用先生成建議框、再分類的two-stage檢測模型,以RCNN[11-13]系列模型為代表,其檢測精度高,泛化能力強,但檢測時間較長,不能滿足實時性需求[14-15];另一類用單一的卷積網絡直接獲得預測目標位置和分類的端到端的one-stage檢測模型,以YOLO[16-18]系列模型為代表,因其具有檢測實時性、高精度等優勢而得到廣泛應用。研究學者針對深度模型進行了一系列研究[19-23],針對自然場景下的水果果實,采用改進的YOLO系列模型進行自動化識別,獲得了較高的可靠性和檢測效率。
然而,在自然光線變化、枝葉遮擋或果實密集、果實不同成熟期等實際情況下,需要對卷積神經網絡作進一步改進,以便較好地解決實際問題、提升果實檢測效率。與蘋果、柑橘、芒果等果實相比,冬棗果實果型小、產量大,成熟期集中,冬棗果樹枝葉較密[24]、果實重疊、枝葉對果實遮擋嚴重,并且不同成熟期冬棗果實混雜、果實顏色差異明顯[25],這些均增加了識別的難度。本文利用YOLO v3模型在目標檢測方面的優勢,針對冬棗果實的特征引入注意力模塊(SE)對YOLO v3進行改進,并選擇最優閾值對冬棗進行檢測,分別采用不同復雜情況的冬棗數據集來驗證本文模型的有效性。
1 冬棗果實檢測模型
1.1 YOLO v3模型
YOLO v3是對深度卷積神經網絡YOLO的改進,利用多尺度檢測和殘差網絡實現目標檢測,在目標檢測方面具有實時性、泛化能力強、精度高等優勢[13],是目前最先進的目標檢測方法之一,能夠從圖像中快速分類檢測目標。
YOLO v3模型包括Darknet層和YOLO層兩部分,Darknet是YOLO v3的特征提取層,YOLO層是目標檢測層。模型采用尺寸為416×416×3的圖像作為輸入,利用Darknet層提取圖像特征,得到3個尺寸(52×52×256、26×26×512、13×13×1 024)的特征圖,在YOLO層中進行檢測。每個網格檢測出B個目標檢測框及其置信度c,即產生5個預測值(x,y,w,h,c),其中(x,y)是目標坐標,(w,h)是目標檢測框的寬度和高度,最后通過設置置信度閾值對預測結果進行取舍。
1.2 改進的YOLO v3模型
對檢測冬棗果實分析可知,自然場景受光線、遮擋等因素干擾,冬棗果實情況復雜。針對YOLO v3模型對因受部分遮擋和受光線影響而使冬棗果實錯檢、漏檢和置信度較低情況,可以通過增強感受野,加強有效特征提取的方法有效提高檢測效果。
SE Net(Squeeze and excitation networks)[26]是基于加權特征圖思想提出的一種網絡結構,其核心是SE結構,如圖1所示。
SE結構主要由擠壓(Squeeze)和激發(Excitation)兩個操作組成,Squeeze操作先將輸入的特征圖做全局平均池化(Global average pooling)[27]計算,得到特征通道的全局分布特征,去除特征通道中的空間分布特征,也賦予網絡全局感受野,然后進入3層的全連接網絡,該網絡的隱含層為ReLU激活函數,輸入層和輸出層神經元數相同。Excitation操作為Sigmoid激活函數計算。輸入的特征圖經過Squeeze和Excitation處理后輸出一個向量,向量中的元素作為原輸入特征圖的各層權值,該值用于衡量其重要程度。最后Scale操作將輸出向量與原輸入特征圖相乘,得到施加權值后的特征圖,來強化有效特征,弱化低效或無效特征,使提取的特征具有更強的指向性,從而提高檢測結果。
鑒于SE Net在通道方向上的特征校正能力,本文提出一種將其嵌入YOLO v3的模型結構,為了區分其他嵌入SE Net的YOLO v3模型[28-29],本文稱為YOLO v3-SE模型,模型結構如圖2所示。
YOLO v3模型網絡深度為102層,其中Darknet特征提取層是準確檢測目標的關鍵,包含75層。YOLO v3-SE是在YOLO v3模型的第37、52層分別輸出Scale3、Scale2兩個尺寸的特征圖后嵌入SE結構,使Darknet增至77層,SE結構作為YOLO v3-SE模型的第38、54層。YOLO v3 和YOLO v3-SE模型的網絡結構及各層參數對比如圖3所示。
YOLO v3-SE為提升模型對高分辨率圖像的處理能力,采用512×512×3作為輸入圖像尺寸,兩個SE層分別將前一層輸出的尺寸為64×64×256、32×32×512的特征圖作為輸入,全局平均池化后得到尺寸為1×1×256、1×1×512的特征圖,經過全連接網絡后仍為1×1×256、1×1×512,再由Sigmoid激活函數處理后得到1×1×256和1×1×512的權值,將權值與原輸入特征圖相乘,得到輸出特征圖為64×64×256、32×32×512。
YOLO v3模型的第85、95層為route[18]層,用于將淺層特征與深層特征上采樣后進行拼接融合,這種多尺度融合預測的思想使網絡性能更強。本文模型沿用route層結構,route層信息如表1所示。

表1 route層信息
嵌入SE結構后,YOLO v3-SE模型在第87層為route層,將第86層(32×32×256)與第54層(32×32×512)連接,構成尺寸為32×32×768的特征圖。同樣,第97層route層得到的特征圖尺寸為64×64×384。
2 模型訓練與閾值選取
2.1 數據集制作
本文圖像采集地點分別為河北省滄州市的滄縣紅棗樹教育基地和南顧屯村冬棗園,采集日期集中在2019年8月底至10月初,分別在晴天及陰天、白天和傍晚進行采集。實驗選用佳能數碼相機、手機等設備,采集了大量冬棗果實圖像,作為冬棗圖像數據集。從圖像中選取不同光線、不同遮擋情況、不同成熟期混雜的冬棗圖像1 000幅作為冬棗果實檢測實驗所用數據集,并使用圖像標注工具LableImg對冬棗目標進行標注,得到VOC格式的xml文件。在標注時采取人工可觀測的冬棗果實全標注方式,即圖像中所有遮擋情況的冬棗果實均按可見大小來標注,按人眼觀測結果進行識別。
將標注的冬棗果實數據集劃分為訓練集、測試集、驗證集,按8∶1∶1進行隨機分配,分別包括800、100、100幅圖像,包含冬棗果實目標分別為8 586、1 327、1 288個。
2.2 運行條件
模型訓練和測試均在同一臺計算機進行,硬件配置為Inter Core i7-8700K CPU@3.70 GHz,GeForce GTX 1080Ti GPU,16 GB運行內存,軟件環境為64位Windows 10系統,TensorFlow深度學習框架。
訓練時批處理集尺寸(Batchsize)為8個樣本,初始學習率(Learning rate)為0.001,權值衰減(Decay)為0.9。為防止過擬合,設置在訓練100輪時沒有產生損失值下降即結束訓練。訓練時使用K-means聚類計算當前數據集的錨點預訓練值。
2.3 訓練損失值對比
采用相同訓練集、驗證集和測試集分別在YOLO v3-SE和YOLO v3兩模型上進行訓練,對比迭代損失值變化曲線,如圖4所示。
由圖4可以看出,兩模型在前6 000次迭代擬合速度快,損失值迅速變小,然后緩慢下降,最終穩定在最小值,模型訓練完成。其中,YOLO v3經過6.2 h、32 720次迭代穩定在極值,YOLO v3-SE模型經4.7 h、24 800次迭代穩定在極值。可見,YOLO v3-SE模型比YOLO v3模型收斂速度更快,損失值更小,說明本文模型訓練的效率更高。
2.4 評估指標及閾值
選取準確率P、召回率R、平均檢測精度(mAP)以及調和平均數F作為評價指標。
在使用模型進行實際檢測時,需要設置置信度閾值來對檢測目標進行取舍。因此,在模型檢測時,置信度閾值選取比較關鍵。
在訓練結束后設置不同置信度閾值得到多組評估指標,對比結果見圖5。由于F是綜合P、R的評估指標,選取F為主要參考值。由圖5可見,閾值為0.55時,F取得最大值86.19%,此時mAP維持在較高值82.01%,而P為88.71%,R為83.80%,也處于較高水平,說明模型性能最優。所以最終選取置信度閾值0.55作為模型檢測實驗所用參數。
3 結果與分析
3.1 檢測總體效果對比
對YOLO v3-SE和YOLO v3模型在相同訓練集和驗證集上分別進行訓練,并在相同測試集上進行檢測,得到各評估指標、檢測結果的置信度以及檢測速度等。在檢測效果圖中,統一用黃框表示假負例FN,即應檢出而未檢出的目標冬棗果實,藍框表示假正例FP,即錯檢的目標冬棗果實。
3.1.1評估指標對比
通過訓練和測試,YOLO v3-SE和YOLO v3兩模型的PR曲線如圖6所示,評估指標如表2所示。
從圖6可以看出,YOLO v3-SE的PR曲線覆蓋范圍更大,說明mAP更大,P、R也比YOLO v3有明顯提升。從表2可以看出,YOLO v3-SE和YOLO v3兩模型的P均處于較高水平,而YOLO v3-SE的R為83.80%,比YOLO v3模型的R,提升了4.36個百分點,mAP從YOLO v3的77.23%提升到YOLO v3-SE的82.01%,提升了4.78個百分點,F從YOLO v3的83.81%提升到YOLO v3-SE的86.19%,提升了2.38個百分點。可見本文模型的mAP和F都有明顯提升,比YOLO v3檢測效果更好。

表2 YOLO v3-SE和YOLO v3模型檢測結果的評估指標對比
3.1.2置信度對比
在模型檢測中,對比兩模型對3幅圖像的檢測效果,如圖7所示,3幅圖像從左到右依次記為P1、P2、P3,相應置信度對比如表3所示。
從表3可以看出,YOLO v3-SE模型在3幅圖像上的正確檢出目標分別為17、19、10個,而YOLO v3模型正確檢出目標為15、15、6個,YOLO v3-SE模型檢測目標的置信度是1的情況明顯更多,絕大多數置信度在0.9以上。從圖7可以看出,YOLO v3-SE模型在比YOLO v3模型多檢出的目標冬棗果實的置信度也在較高水平。對照表3和圖7來看,YOLO v3-SE模型在對應檢測框的置信度比YOLO v3模型更高,并且從YOLO v3模型未檢出、YOLO v3-SE模型檢出的目標來看,置信度也較高,說明本文模型對檢測目標的置信度有一定加強作用,使檢測效果更好,檢測能力更強。

表3 圖7中檢測結果的置信度對比
3.1.3檢測速度對比
實驗選取單幅圖像和批量圖像兩種方式對比檢測速度。檢測時間通常指從待檢測圖像讀入至檢測結果輸出所用的時間。在批量檢測速度的實驗中,記錄兩模型分別對101幅600像素×600像素的圖像檢測所用時間,再分別減去各自在第1幅圖像所用檢測時間,這是因為第1幅圖像檢測時需要載入權重模型而導致耗時較長。
在模型中嵌入其他結構往往使檢測速度降低。對比兩模型對兩種不同尺寸的單幅和批量圖像檢測速度,結果如表4所示。

表4 兩模型圖像檢測速度對比
由表4可見,在中等尺寸和大尺寸圖像的檢測上,YOLO v3-SE模型與YOLO v3模型耗時相差很小,而批量檢測時,YOLO v3-SE模型的檢測速度與YOLO v3模型相差在毫秒級。
從檢測速度對比看,無論是單幅圖像,還是批量圖像,YOLO v3-SE模型與YOLO v3模型差異不明顯。
3.2 自然場景檢測實驗
為檢驗YOLO v3-SE模型在自然場景下的適應性和有效性,根據實際條件進一步檢測模型的效率。以自然場景下拍攝的光線不足、密集遮擋和成熟期混雜等復雜情況下的冬棗果實圖像各50幅,分別組成測試集進行檢測,與YOLO v3模型對比,利用P、R、mAP和F評估本文模型的性能。
3.2.1光線不足情況下的檢測效果對比
為避免密集遮擋對實驗的影響,選取50幅逆光、陰天或傍晚等光線不足情況下的非密集冬棗果實圖像組成測試集,共包含270個冬棗果實目標,使用YOLO v3-SE和YOLO v3模型進行檢測,評估指標如表5所示,檢測效果如圖8所示。
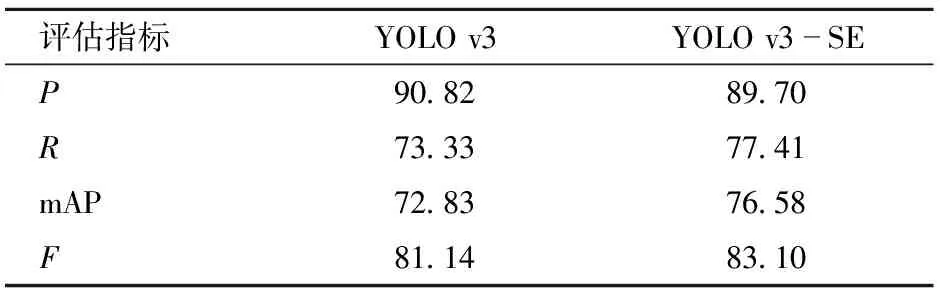
表5 光線不足情況下的冬棗果實測試集評估結果
從表5中可以看出,YOLO v3-SE模型的mAP比YOLO v3模型高3.75個百分點,YOLO v3-SE模型的F比YOLO v3模型高1.96個百分點。YOLO v3-SE模型的R提升明顯,比YOLO v3高4.08個百分點。兩模型檢測結果均保持較高的準確率,但YOLO v3-SE模型在R、mAP和F指標上明顯高于YOLO v3模型,檢測效果更好。
圖8分別選取光線不足情況中的逆光和陰暗兩組圖像進行對比,其中左圖為逆光情況,右圖為陰暗情況。從圖中可以看出,光線不足時,數碼設備拍攝的圖像質量明顯下降,導致被檢測目標的邊緣不清晰、顏色失真、紋理特征缺失,為檢測帶來阻礙。受此影響YOLO v3模型漏檢率較高。綜合來看,本文模型比YOLO v3模型的檢測效果有明顯提升。
3.2.2密集遮擋情況下的檢測效果對比
實驗選取50幅冬棗果實密集度較高、遮擋較嚴重、光線充足的圖像組成測試集,共包含1 028個冬棗果實目標,使用YOLO v3-SE和YOLO v3兩模型進行檢測,實驗結果如表6所示,檢測效果對比如圖9所示。

表6 密集冬棗果實測試集評估結果
從表6來看,YOLO v3-SE模型的mAP比YOLO v3高2.38個百分點,YOLO v3-SE的F比YOLO v3高1.75個百分點。圖9中左圖為果實密集多枝葉遮擋,右圖為果實密集多重疊情況,由于選取圖像光線充足,冬棗果實邊界清晰,兩模型檢測準確率均較高。但由于枝葉茂盛,對果實遮擋嚴重,以及果實密集重疊,甚至出現冬棗果實不同部位的遮擋,冬棗果實與枝葉顏色相差不大,會出現錯檢和漏檢情況。圖中YOLO v3出現的錯檢和漏檢情況明顯多于YOLO v3-SE,無論是冬棗果實多重疊還是多遮擋情況,本文模型的檢測效果均優于YOLO v3模型。
3.2.3不同成熟期冬棗的檢測效果對比
分別選取50幅以白熟期、脆熟期和完熟期3個不同時期的冬棗果實圖像組成3個測試集,分別包含冬棗果實目標數量為532、333、400個,使用YOLO v3-SE和YOLO v3模型檢測,各評估指標如表7所示,檢測效果如圖10所示。
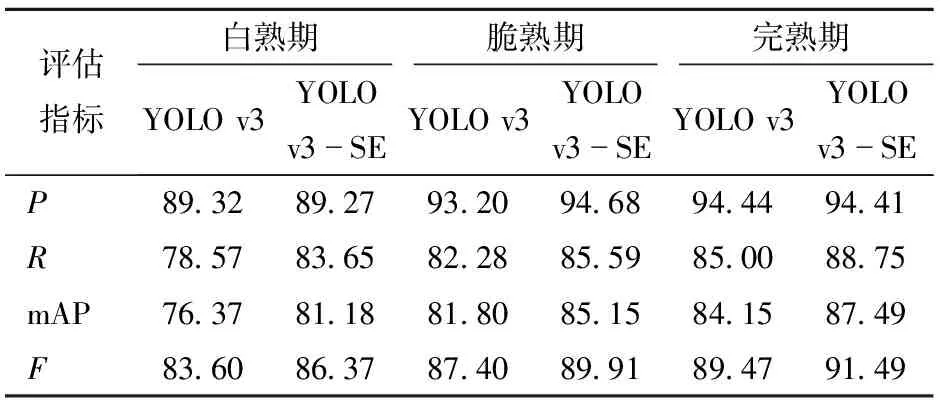
表7 不同成熟期的冬棗果實測試集的評估結果
從表7可以看出,YOLO v3-SE模型的mAP在3個成熟期的測試結果比YOLO v3分別高3.34~4.81個百分點。不同成熟期YOLO v3-SE模型的R比YOLO v3高3~5個百分點,YOLO v3-SE的F也比YOLO v3高2.02~2.77個百分點。
圖10為以3個成熟期為主的測試圖像對比,從左至右為白熟期、脆熟期、完熟期。從圖中可以看出,在光線充足情況下,脆熟期冬棗果實部分變紅、完熟期為全紅色,顏色紋理特征明顯,在光線充足情況下與周圍環境對比清晰。而由于白熟期冬棗果實顏色為青綠色,重疊或遮擋時會呈現出與樹葉較接近的顏色和形狀,在標注時要做到人眼準確、全面地觀測也較困難,所以會導致誤檢、漏檢。綜合3個成熟期的檢測效果,YOLO v3模型的mAP和F明顯低于YOLO v3-SE模型,YOLO v3-SE模型檢測效果更好。
4 結論
(1)提出了基于YOLO v3-SE模型的自然場景下冬棗果實識別方法。實驗表明,YOLO v3-SE模型檢測精度高、速度快,在自然場景下對復雜因素的抗干擾能力強,模型的平均檢測精度達82.01%,綜合評價指標F達86.19%,對單幅圖像和批量圖像的檢測速度與YOLO v3模型無明顯差異。
(2)通過在YOLO v3中嵌入SE Net,增強了特征圖的特征表達能力,與YOLO v3模型相比,YOLO v3-SE的召回率提升了4.36個百分點,mAP提升了4.78個百分點,F提升了2.38個百分點。
(3)通過對比閾值對評估指標的影響,選取0.55作為本文模型檢測的置信度閾值,以保證模型性能最優。
(4)與YOLO v3相比,在光線不足、密集遮擋和冬棗不同成熟期等多種情況下本文模型檢測效果均有不同程度的提升,其中,在光線不足和密集遮擋情況下mAP分別提升了3.75、2.38個百分點,F分別提升1.96、1.75個百分點,在白熟期、脆熟期和完熟期為主的情況下mAP分別提升了3.34~4.81個百分點,F提升了2.02~2.77個百分點,從而驗證了本文模型的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
