基于BERT的水稻表型知識圖譜實體關系抽取研究
2021-06-09 10:25:08袁培森李潤隆徐煥良
農業機械學報 2021年5期
袁培森 李潤隆 王 翀 徐煥良
(1.南京農業大學人工智能學院,南京 210095;2.國網江蘇省電力有限公司信息通信分公司,南京 210024)
0 引言
植物表型組學數據分析是近年來植物學、信息科學領域研究的交叉熱點,其本質是對植物基因數據的三維時序表達,以及地域分布特征和代際演進規律[1]。表型組學指利用生物的遺傳基因組信息對生物的外部及內部表型數據進行研究的一門綜合性學科[2]。植物表型組學不僅研究植物的外在形狀,還研究其內部結構、物理和生化性質以及遺傳信息。亟需研究建立植物表型組學數據完整知識庫的智能計算方法[3]。
中國是世界上水稻產量最大、消費最多的國家[4],水稻的培育及研究是中國糧食安全戰略的重要內容[5]。水稻表型組學研究是植物生物學的研究熱點,水稻表型數據的高通量、高維、海量的數據特征對數據的快速檢索和知識的有效提取提出了更高的技術要求[6]。
知識圖譜將知識轉化為圖,利用計算機進行推理分析,實現從感知智能到認知智能的飛躍,是人工智能領域的一項重要技術[7]。知識圖譜是一個具有結構化特征的語義知識庫,采用符號的形式描述數據中的實體及之間的關系[8],利用對語義的抽取和分析,并結合數據科學、人工智能等學科的前沿技術和方法,在學科知識庫構建領域獲得了廣泛關注。
對知識圖譜系統的構建包括2個核心步驟:實體抽取、實體間關系的構建,其中實體關系的構建需要關系的抽取技術。關系抽取任務的研究目標是自動對兩個實體和之間聯系所構成的3元組進行關系識別[9]。關系抽取能夠提取文本數據中的特征,并提升到更高的層面[10]。
實體關系的抽取方法可以分為3類:基于模板、基于傳統機器學習和基于深度學習的方法[11]。基于模板的關系抽取方法是早期基于語料學知識及語料的特點,由相應領域的專家和研究人員手工編寫模板,這種方法需要耗費大量專業人力,可移植性較差。基于傳統機器學習的關系抽取方法主要包括使用核函數[12]、邏輯回歸[13]以及條件隨機場[14]等,是一種依賴特征工程的方法。HASEGAWA等[15]使用聚類方法計算上下文的相似性。趙明等[16]采用本體學習,使用有監督的、基于依存句法分析的詞匯-語法模式對百度百科植物語料庫進行關系抽取,在非分類的關系抽取任務中表現較好,為構建植物領域知識圖譜奠定了基礎。
基于深度學習的關系抽取方法包括遞歸神經網絡模型[17]、卷積神經網絡模型[18]、雙向轉換編碼表示模型(Bidirectional encoder representation from transformers, BERT)[19]等。深度學習能夠實現語義特征的自動提取,從而使模型能夠對不同抽象層次上的語義進行分析[20]。BERT為典型的深度學習模型[19],通過自動學習句中特征信息、獲取句子向量表示,能夠對水稻表型組學數據進行關系抽取。在水稻知識圖譜構建中,區分水稻表型組學實體之間的復雜關系與水稻表型組學知識庫的構建有關。因此,研究水稻表型組學的關系抽取十分重要。
本文使用爬蟲框架獲取水稻表型組學數據,根據植物本體論提出一種對水稻的基因、環境、表型等表型組學數據進行關系分類的方法。使用詞向量、位置向量等算法提取句中特征,在獲取水稻表型組學實體關系數據集的基礎上構建基于雙向轉換編碼表示的關系抽取模型,并將本文方法與卷積神經網絡(Convolutional neural network,CNN)[21]、分段卷積神經網絡(Piece wise CNN,PCNN)[18]進行對比,以期實現句子級別的關系抽取。
1 水稻表型組學關系數據集
1.1 關系數據獲取
本文關系數據集主要來自國家水稻數據中心(http:∥www.ricedata.cn/)以及維基百科中文語料庫。數據爬取使用可對網頁的結構性數據進行獲取以及保存的框架Scrapy[22],實現水稻數據中心本體系統以及維基關系數據集的爬取。對爬取的水稻表型數據進行清洗處理,獲得了用于關系分類處理的水稻表型組學關系數據集,數據集詳情如表1所示。

表1 數據集來源分布
1.2 關系數據分類
在水稻表型組學關系數據的分類問題上,本文參照了植物本體論(Plant ontology)[23]對植物表型組學的分類,通過關系分類將水稻的解剖結構、形態、生長發育與植物基因數據聯系起來,從而對水稻表型組學數據進行分類。
本體[24]指的是在某一領域內的實體與其相互間關系的形式化表達,本體論是概念化的詳細說明,它的核心作用是定義某一個領域內的專業詞匯以及他們之間的關系[25]。
植物本體論[23]是一種結構化的數據庫資源,是用來描述植物解剖學、形態學等植物學的結構性術語集合,它將植物的內部解剖結構、外表形態結構等表型組學數據與植物基因組學數據聯系起來,使用關系來描述基因、環境、表型之間的聯系。如今植物本體論的描述范圍從最開始的水稻單個物種擴大到了22種植物,對這些植物的基因或基因模型、蛋白質、RNA、種質等表型和基因數據進行描述。本文依據其分類規則,將水稻表型組學數據分為7類:①is a,用來表示父術語以及子術語之間的關系,表示對象O1是O2的子類型或亞型。②has part,用來表示對象O1的每個實例都有一部分O2的實例。③has a morphology trait,表示O1通過O2的形態特征表現出來。④develop from,表示O1從O2發育而來,O2的世系可以追溯到O1。⑤participate,表示實體O1的每個實例都參與開發O2的某些實例。⑥regulate,O1對O2有調節或調控作用。⑦other,表示其他關系。
分類完成后的關系抽取數據集示例如表2所示。表2中,ddu1(Dwarf and disproportionate uppermost-internode1)為使用甲基磺酸乙酯誘變粳稻品種蘭勝而成的矮化突變體的品種名稱;SPL5(Spotted leaf 5)為經γ射線輻射誘導粳稻品種Norin 8而成的水稻類病變突變體的品種名稱;FLW1(Flag leaf width NAL1)為劍葉寬度基因。最后,將數據集按8∶2分為訓練集和測試集。

表2 關系抽取數據集示例
1.3 關系數據存儲
水稻實體及關系采用圖方式進行建模以及數據存儲,本文使用圖數據庫Neo4j[26]存放實體和關系數據。Neo4j的核心概念是節點和邊,節點用來存儲實體,使用圓形圖例表示,邊用來存儲關系數據結構中實體之間的關系,使用帶箭頭的線表示。不同實體以及關系的相互連接形成復雜的數據結構,實現對某個實體進行關系的完整增刪改查等功能。
對收集的數據集進行預處理,提取2 021個實體和2 689條關系,通過Cypher語言[27]進行快速的查詢工作。圖1為Neo4j數據庫存儲的水稻表型組學關系示例。由于實體名稱較長,圖1中的“12號染…”為12號染色體;“等位基因…”為等位基因STV11-S。
2 水稻表型組學關系抽取模型構建
2.1 向量化表示
本文BERT關系抽取模型使用詞向量、位置向量以及句子向量相結合的輸入向量序列,不僅能簡單獲取詞語語義上的特征,而且能夠對深層次語義進行表示和抽取。
2.1.1詞向量
本文使用BERT模型中的詞嵌入方式來動態產生詞向量,即將詞轉化為稠密的向量。通過這種詞嵌入方式,該模型能夠根據上下文預測中心詞的方式來獲得動態的語義特征,以解決傳統詞嵌入模型產生的多義詞局限性,可以產生更精確的特征表示,從而提高模型性能。
BERT的詞向量生成方法如下:給定語句序列s=w0,w1,…,wn。其中w0=[CLS]、wn=[SEP]表示句子的開始以及結束。模型將原有的序列映射為具有固定長度的向量來表示語義關系。
2.1.2位置向量
設句子為s=w0,w1,…,wn,實體為i1與i2,則對于每一個單詞wi,計算其與i1、i2的相對距離,即i-i1和i-i2,使得該句子可以根據兩個實體生成兩部分的位置向量,并且能體現距離和實體的關系。本文使用的位置向量維度為50。
2.1.3句子向量
句子向量按照句子的數目進行標記,對于第1條句子的每個單詞添加向量v1,給第2條句子中的每個單詞添加一個向量v2。
2.1.4輸入表示
BERT模型的輸入示例如圖2所示。圖2中的BERT模型輸入的句子為“稻是谷類,原產中國與印度”,模型生成每個詞的詞向量,根據每個詞與實體之間的距離生成句向量,根據句子的條數生成對應的句向量,將此作為BERT模型的輸入。
2.2 BERT關系抽取模型構建
BERT是以Transformer的編碼器為基礎的雙向自注意力機制表示模型,能夠對所有層基于上下文進行雙向表示。BERT模型使用雙向自注意力機制來進行構建,使用Transformer的編碼器來進行編碼,并且使用遮擋語言模型以及下一句預測兩個方法來更有效地訓練模型。
2.2.1雙向自注意力機制
BERT使用雙向自注意力機制[28]進行構建。雙向自注意力機制是注意力機制中的一種,注意力機制在自然語言處理領域的多個任務得到了實際應用。注意力機制可以描述為一個查詢Q到相應鍵值對〈K,V〉的一個映射過程[29],可描述為
At(Q,K,V)=Sf(Sm(Q,K))V
(1)
式中At——注意力機制函數
Sf——Softmax函數
Sm——相似度函數
注意力值的計算過程可分為3部分:①首先計算查詢Q和每個鍵K之間的相似度S,獲得權重,使用的相似度計算函數有點積、拼接以及感知機。②使用Softmax函數進行權重歸一化。③將權重以及鍵值對中的值V進行加權,獲得最終的注意力值。自注意力機制即檢索自身的鍵值對進行加權處理,Q=K=V,將序列進行重新編碼,獲得更具整體性的特征序列[30]。自注意力機制的結構圖如圖3所示。
自注意力機制將輸入序列通過向量映射的方式輸入到嵌入層,注意力層進行查詢向量和值向量的相似度計算,Softmax層使用函數加權后將序列輸出。BERT所用的多頭自注意力機制在輸入到注意力層之前對查詢Q、鍵K以及值V進行多次線性變換,線性變換的次數即為多頭,多頭自注意力機制可以獲得多種序列的子特征,進而獲得較長序列中的相隔較遠的向量特征[31]。
2.2.2Transformer編碼器
BERT使用Transformer編碼器進行編碼,Transformer[32]通過對語義信息以及位置信息的分析來完成自然語言處理任務,其框架為編碼器加解碼器結構。其中,編碼器框架使用了層疊結構,每一層有兩部分:進行加權處理的多頭注意力機制和進行前饋化網絡的全連接層,在兩部分之間使用殘差進行連接然后進行標準化。解碼器的層數與編碼器相同,同時在每一層之內還添加了一個進行計算翻譯效果的部分。Transformer編碼器結構圖如圖4所示,圖中N×表示編碼器或解碼器包含的層數。
Transformer編碼器由3部分組成:①首先對輸入句子進行向量化,將詞嵌入到編碼器中。②編碼器接受向量序列,隨后使用自注意力機制對序列進行處理,通過對序列中所有單詞之間建立聯系來進行序列編碼,處理后的序列通過殘差網絡進行求和與歸一化。③自注意力機制結束以后,輸入到全連接的前饋網絡中,輸出標準化后的向量。
BERT模型使用多個Transformer編碼器進行編碼,編碼器輸出后進入到一個全連接層與激活函數構成的分類層并輸出相應的概率[33]。圖5是對水稻表型進行編碼示例,輸入的句子為“產量性狀是與植物可收獲產物相關的性狀”。
BERT模型在使用過程中,僅需要在編碼器后面加上一層全連接層就能夠完成關系抽取任務。在后期的微調部分中,設之前遮蓋處理后的輸出向量為C,使用Softmax分類器完成關系分類的概率Pr為
Pr=Sf(CWT)
(2)
式中W——向量矩陣
對于本文的關系多分類問題,類別標簽y∈{1,2,…,M}。給定測試樣本x,Softmax函數預測類別c∈{1,2,…,M}的條件概率為
(3)
式中wc——權重
wi——第i類權重
p——概率
BERT模型輸出關系類別以及其對應的概率。另外,BERT模型在預訓練部分使用了遮擋語言模型以及下一句預測兩個方式來訓練模型。
2.2.3遮擋語言模型
遮擋語言模型(Masked language model)[19]指的是在進行BERT模型訓練時,由于進行的注意力機制是多頭而不是單向的,如果按照CNN等模型的訓練方式進行訓練,則BERT模型的訓練將成為一個先獲得后文再進行預測的任務,無法正確獲取語義特征,因此進行雙向注意力機制訓練時,BERT使用了遮擋語言模型,將輸入的詞進行隨機遮蓋,從而使得雙向編碼器能夠真正對前后文進行預測[19]。本文對15%的詞進行遮擋,并且遵循以下規律:①被遮擋的詞有80%的概率被替換成屏蔽符號[mask]。②10%的概率被換成隨機詞。③10%的概率保持原有單詞不變。這樣后期微調部分的向量輸入不會與遮蓋處理中的向量差距太大。
2.2.4下一句預測
下一句預測(Next sentence prediction)[19]使BERT模型能夠學習下一句和上一句的內在聯系,BERT模型在數據集中隨機選取句子S1,對于其下一句S2,有50%的概率將S2替換為無關的句子S3,以此來學習句子間的關系。
3 關系分類結果與分析
3.1 試驗環境
選擇Intel Corei5-8250u處理器@1.6 GHz,8 GB內存,1 TB硬盤,Windows 10操作系統。
3.2 參數設置
BERT模型的參數設置如表3所示。為防止模型訓練后期的波動,學習率衰減采用了文獻[34]中的推薦值,設置為2×10-5。

表3 BERT模型參數設置
梯度下降算法(Gradient descent optimizer)[35]能夠幫助模型進行目標函數的最大化或最小化計算,一個優秀的梯度下降算法能夠減少損失函數的值。常用的梯度下降算法有隨機梯度下降(Stochastic gradient descent,SGD)[35]、自適應力矩估計(Adaptive moment estimation,ADAM)[36]、解耦權重衰減的自適應矩估計(Adaptive moment estimation with decoupled weight decay,ADAMW)[37]等,本文選擇ADAMW算法。
3.3 數據集
根據植物本體論進行實體關系數據的分類,共獲得7大類、2 689條關系數據,類型有:is a、has part、has a morphology trait、develop from、participate、regulate、other。各個關系類型的數量及分布如表4所示。

表4 水稻表型組學關系數據集的數量分布
3.4 算法性能評估指標
使用精度(Precision,P)、召回率(Recall,R)、F1值(F1)作為評價指標,將BERT與傳統的卷積神經網絡模型[21]與分段卷積神經網絡模型[18]進行對比。
3.5 BERT模型關系分類結果
本部分對梯度下降算法[35]、批尺寸[38]和表2中的關系進行了試驗分析測試。
3.5.1梯度下降算法
對于BERT關系抽取模型,本文進行了梯度下降算法的對比,選擇批(Batch)尺寸為8,3種梯度下降算法在BERT模型上的結果如圖6所示。
由圖6可以看出,ADAMW的精度、召回率和F1值比SGD和ADAM高,SGD最低,3個指標均在60%左右。ADAM和ADAMW都在94%以上。
3.5.2批尺寸
選擇批尺寸分別為8、16、32、64進行試驗,選擇ADAMW作為梯度下降算法,其在BERT模型上的結果如表5所示。
由表5可知,批尺寸為8時,ADAMW算法的精度達到了95.11%,召回率為96.61%,F1值為95.85%。相比批尺寸為16、32、64,精度分別提高了0.52、0.63、0.88個百分點;F1值分別提高1.04、0.22、1.23個百分點。

表5 不同批尺寸在BERT模型上的對比
3.5.3不同關系類型的處理結果
本試驗批尺寸為8,BERT模型使用ADAMW算法對本文數據集上的不同關系抽取結果進行對比,結果如表6所示。
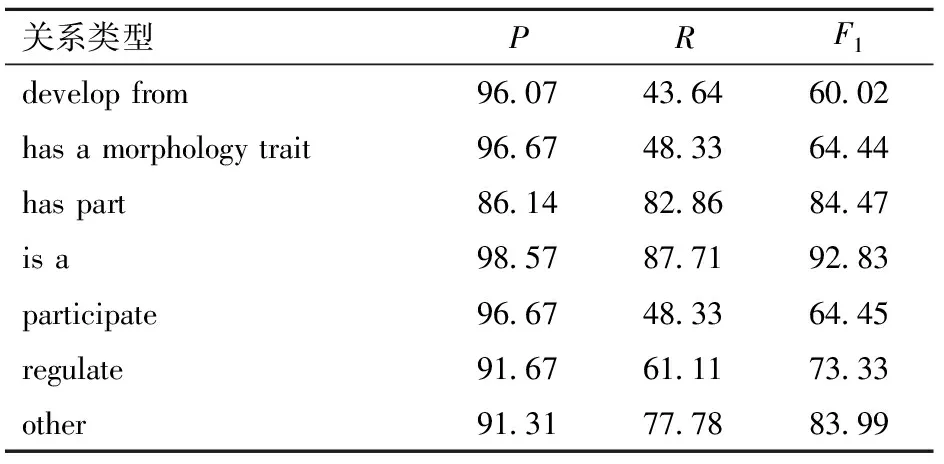
表6 BERT模型對不同關系的處理結果
由表6可知,BERT模型對于不同關系的F1值都不低于60.02%,但是對于不同關系的處理效果也不同。其中,對于has part、is a、other、regulate關系分類效果較好,其F1值都不小于73.33%,而對于develop from、participate、has a morphology trait的分類效果相對較差。在7種關系中,is a關系類型的測試結果最佳,其F1值達到了92.83%,是develop from類型的1.546 7倍。develop from、has a morphology trait和participate 分類效果較差的原因是這3個關系類別的數據庫中關系數較少,且數據集中各個類別的分布不均衡。其解決方法有:①通過增加這3個類別實體關系數據使BERT模型提取更多有效的語義和詞匯特征。②將各個關系數據的條數進行調整,保持各個類別實體關系數據的數量均衡。
3.6 模型對比
本文將CNN[21]、PCNN[18]與BERT模型進行對比,CNN和PCNN模型的參數設置如表7所示。

表7 CNN和PCNN模型參數設置
CNN在批尺寸為16時,使用SGD算法時獲得最高精度、召回率與F1值,精度為81.79%,召回率為82.35%,F1值為82.07%。PCNN的批尺寸為16,使用SGD算法時,獲得最高精度、召回率與F1值,精度為85.95%,召回率為81.67%,F1值為83.66%。BERT模型在隱藏層數量為1 536、最大序列長度為80、學習率衰減為2×10-5、訓練輪數為5、批尺寸為8、梯度下降算法為ADAMW時,關系抽取的精度、召回率與F1值達到最優,精度為95.11%,召回率為96.61%,F1值為95.85%。
BERT在精度、召回率以及F1值上都明顯高于其他兩種模型,其F1值是CNN的1.17倍、PCNN的1.15倍。
綜上所述,在使用BERT模型進行水稻表型組學數據關系抽取時,BERT模型能夠根據上下文預測中心詞的方式來獲得動態的詞向量,使用自注意力機制獲得雙向的語義特征,大幅度提高了關系抽取的質量。
4 結束語
本文基于植物本體論提出基于水稻表型組學的關系分類方法,將水稻表型的實體關系分為7類,使用詞向量、位置向量以及句子向量進行句子特征抽取,構建BERT模型,并將BERT模型與CNN、PCNN模型進行對比。結果表明,BERT模型的精度、召回率與F1值分別為95.11%、96.61%和95.85%,達到了預期分類效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
青少年科技博覽(中學版)(2022年6期)2022-12-27 19:44:27
今日農業(2021年21期)2021-11-26 05:07:00
軍事文摘(2021年22期)2021-11-26 00:43:51
今日農業(2021年14期)2021-10-14 08:35:40
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
文苑(2020年6期)2020-06-22 08:41:52
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2019年22期)2019-12-07 05:29:00
光學精密工程(2016年6期)2016-11-07 09:07:19
