基于內存計算的圖書館文獻服務模式構建研究
2021-06-04 03:09:08于芳
微型電腦應用 2021年5期
于芳
(哈爾濱工業大學(威海) 圖書館, 山東 威海 264209)
0 引言
在當前的大數據時代背景下,現代圖書館的文獻逐漸增多,數據處理越來越復雜。文獻服務涵蓋類數據檢索、文獻標準等方面內容,具有總量大、種類多、高價值低密度特性,因此為讀者提供高效精準的文獻服務成為現代圖書館面臨的主要任務[1-2]。采用先進的“計算”收到來實現數據價值的深層次挖掘,成為一種必要的方式[3-5]。目前,人們通過提高單個CPU處理速度在一定程度解決了數據處理問題,但數據的I/O速度成為制約瓶頸[6]。而共享內存試圖通過增加數據庫緩沖池來實現數據處理提升的目的,但受限于數據庫技術和操作系統,難以滿足實際需求[7]。內存計算通過將處理數據一次性存取,避免了對數據的頻繁操作造成的處理時間延長,但在海量數據量下,如何高效、精確查找到所需要的文獻資料,成為目前資料查閱迫切解決的需求[8-10]。目前比較典型內存計算主流框架有Apache 的Hadoop+Spark系統,應用較多的的內存計算產品如SAP HANA等[11]。本文基于圖書館數據信息特征,利用內存計算中Spark系統框架高的容錯機制和實時運算優勢,提出一種基于短句“字符串匹配”和文檔的“相似度匹配”下的混合關聯算法,實現圖書館文獻查閱過程中的準確推薦需求。
1 圖書館推薦服務內存算法
對于圖書館而言,推薦是通過科學合理化建議來幫助讀者選擇滿足需求的圖書、論文、專利文獻。推薦算法作為圖書館個性化服務系統設計的核心模塊,推薦質量直接影響到服務效率和質量[12]。傳統的圖書數據推薦難以滿足不同客戶需求的個性化、精準化推薦,因而導致用戶節約轉化率低。在大數據環節下,利用大數據挖掘算法,來提升推薦算法的精準性、新穎性等性能,成為迫切解決的問題[13]。目前,主流的推薦算法包括內容推薦算法、協調過濾推薦算法以及混合推薦算法[14-16]。
關聯規則作為數據挖掘領域的重要技術,用來發現用戶使用文獻間的關系。基于關聯規則推薦算法首先根據用戶使用文獻構成關聯規則,并通過瀏覽、查閱行為進行推薦,但用戶使用文獻數據較大時,則需要通過信道數據挖掘獲得用戶使用文獻的關聯規則。基于內容的推薦算法根據不同文獻間存在的相似度進行推薦,通過數據挖掘對用戶文獻內容進行評分,建立檔案模型,根據評分篩選推薦給用戶。
協同過濾算法中,根據不同的對象分為基于用戶、物品和模型的協同過濾。基于用戶協調算法相當于一類聚類算法,即根據用戶對文獻的評價日志進行用戶間相似度計算,根據相同評分層次的鄰居用戶來推薦相應的文獻;基于物品的協同則通過物品間相似度進行,即對文獻進行聚類,推送給特定用戶;基于模型的協同通過對用戶歷史借閱信息來構建模型,采用概率模型、人工神經網絡等數據挖掘技術進行圖書評價預測,通過數據挖掘算法獲得的歷史數據向用戶推薦圖書文獻。
混合推薦算法則是綜合了多種推薦技術獲得的推薦結果,最終形成一個推薦列表。混合推薦算法有效避免了單一推薦算法的弱點,模型級聯融合和加權融合作為兩種方式,將人工神經網絡、大數據回歸算法和概率模型、回歸算法等線性和非線性技術融合起來,提高推薦結果精確度。
本文針對圖書館文獻數據格式多、類型復雜的特點,為避免文獻查找缺陷、文獻瀏覽迷航、文獻分析效率低的特點,基于大數據環境下,提出一種新的混合推薦算法,針對文獻間相似度較大的情況,采用“字符串匹配”和“相似性度量”的文獻關聯,利用參數優化提升推薦性能,避免“文獻缺失”,通過構建文獻列表來概述“瀏覽迷航”的問題,同時,基于Spark框架構建內存算法結構,提升大數據系統性能,提升文獻推薦算法的分析效率。
2 圖書館文獻推薦的混合算法
2.1 文獻推薦的混合推薦算法
當用戶根據自身需求登錄圖書館信息系統,查閱感興趣的文獻鏈接時,系統通過用戶瀏覽文獻的特征度來查找相似的文獻。基于此,本文提出的混合推薦算法即根據瀏覽的文件相似度特征來進行匹配度排名后,推薦給客戶。因此,基于用戶興趣和文獻數據來構建混合關聯模型,具體以用戶感興趣的文獻特征建立用戶偏好模型,同時根據文獻特征和用戶匹配度來建立海量文獻的數據建模。根據用戶興趣模型從數據庫中選定相似匹配度高的文獻進行排序,并推薦給用戶。基于用戶興趣的文獻數據模型的混合推薦算法,如圖1所示。
從圖1中可以看出,利用Sparik RDD來支撐“字符串匹配”,利用Spark MLlib支撐“相似性度量”。采用混合推薦算法主要是根據用戶需求推薦不同類型的的文獻,如“圖書到圖書”或“圖書到文獻”間不同類型的推薦。為提高推薦性能,其中建立了“字符串匹配”和“相似性度量”關聯方法。“字符串匹配”主要將“作者”“關鍵詞”等文獻數據庫中規劃化的元數據進行比較,確定不同文獻間的字符串是否關聯。“相似性度量”主要將文獻“摘要”“篇名”等內容較長切標書靈活的文檔類型進行相似度計算,并整合成混合權重進行排名推薦。
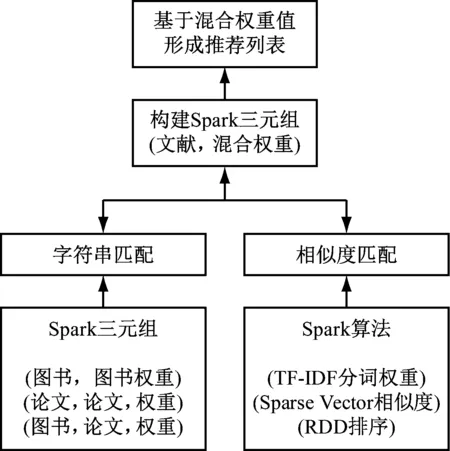
圖1 圖書文獻混合推薦算法
2.2 混合關聯算法的流程
根據上節中算法的結構框架,建立“混合關聯”推薦算法。具體流程如圖2所示。
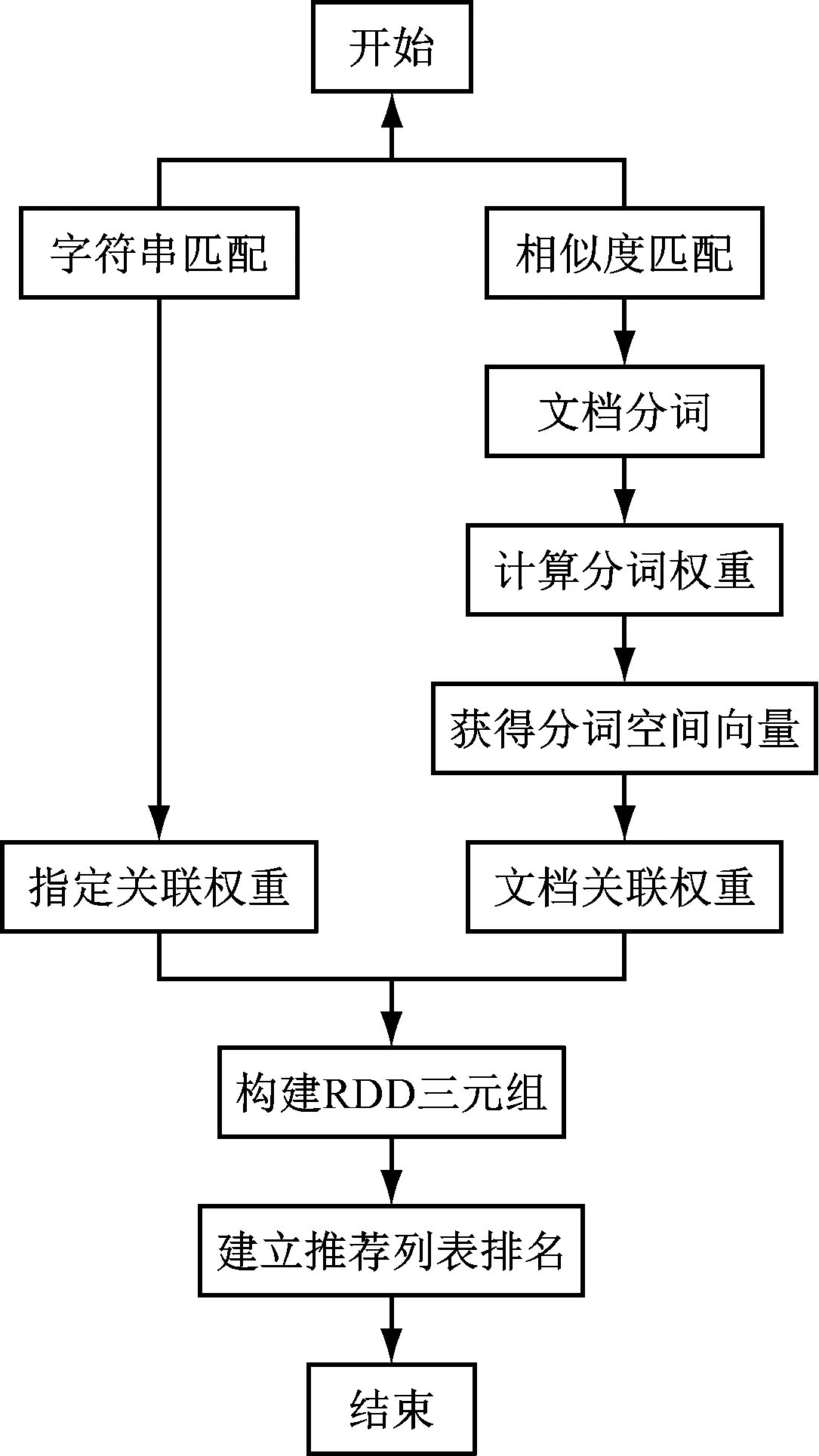
圖2 推薦列表實現流程
圖中包括了“字符串匹配”“相似性度量”“混合關聯權重計算”“推薦列表”排名四個具體步驟。
字符串匹配中,抽取圖書數據庫中的“作者”“關鍵詞”信息與論文數據庫進行關聯。如圖書數據庫和論文數據值相同,則建立兩個文獻的關聯Spark RDD三元組(id1,id2,Wchar),其中id1和id2分別為兩個文獻id;Wchar為字符關聯度權重,反映關聯的重要程度。
相似性度量中,通過抽取圖書數據庫中的“書名”“內容介紹”與論文數據庫中的“篇名”和“摘要”進行關聯。由于文檔內容較長,因此,采用文檔相似度關聯時,首先利用分詞軟件對文本進行預處理,去除停用詞,保留分詞,通過TF-IDF()算法獲得分詞的TF/IDF值作為權重值。這里的TF為某一文檔個中該分詞出現的頻數,如式(1)。
TF=T/M
(1)
其中,T為文檔中詞語總數;M為該分詞出現次數。
IDF為反文檔頻率,用于鑒定某一分詞在文檔中的區分能力,如式(2)。
IDF=log(D/(Dw+1))
(2)
式中,D為數據庫中文檔總數;Dw為出現該分詞的數量,通常Dw越小,IDF越大,則表明該分詞越重要。
將計算獲得的分詞TD-IDF值生成新的文檔向量模型,其中w=TF*IDF作為該分詞的權重,計算文檔D1和D2的余弦相似度Sim(D1,D2)作為“相似性度量”權重WSim,建立基于(id1,id2,WSim),如式(3)。
(3)
式中,s為模型分詞列表長度;wi1、wi2為文檔對應分詞權重。
再進行“混合關聯”權重計算,得到“字符串匹配”權重和“相似性度量”權重,并將結果作為文獻id1和id2的最終關聯權重Whybrid,建立格式為(id1,id2,Whybrid)的RDD三元組,如式(4)。
(4)
式中,a為調和參數,確定兩個關聯比重[17];m,n為兩類關聯關聯此次;k為關聯種類求和變量。
根據獲得的Whybrid大小排名,獲得推薦列表,利用Spark中的RDD函數包中的rdd.sortBy()進行函數排表,將文獻相關度高的文獻排名靠前。
3 實證研究分析
3.1 運行平臺
為驗證本文提出的混合文獻推薦算法的可行性,本文以某大學圖書館館藏書名數據庫為對象進行實例分析。其中實證數據來源包括該校圖書館藏書數據庫共1 243 557條數據,同時,通過爬蟲軟件從互聯網中收集共472 536條文獻數據,其中期刊論文373 327條,碩博論文125 646條構成研究論文庫。
系統運行在3個節點的Spark集群上。考慮到數據計算量較大,將系統分為Spark離線計算部分以及Web界面部分。離線計算用于在Hadoop+Spark平臺計算文獻間關聯權重,建立RDD三元組;Web界面能直接調取數據庫結果,并實時推薦和顯示。
3.2 推薦性能評價
目前針對文獻推薦性能的指標評價有多種類型[18]。本文在相關研究的基礎上,采用準確率來評價算法的推薦性能[19]。即在推薦列表中用戶真正感興趣的類型所占的比重,建立起準確率計算公式,如式(5)。
Pre=N/L
(5)
式中,L為文獻推薦列表長度;N為感興趣文獻數量。
根據研究,為保證算法的準確率,確定該“混合關聯”調和參數a取值范圍在0.5-0.7。本文中根據算法特點,確定a=0.6[20]。
3.3 結果和討論
全數據集調價下,不同長度推薦列表的準確率。如圖3所示。
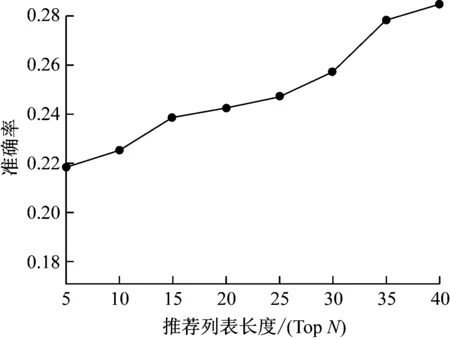
圖3 不同推薦列表長度下的算法準確率
通常準確率指標表征了符合用戶興趣的文獻占比。從圖3中可以看出,隨著TOPN長度的增加,與用戶偏好具有高相似度論文進入列表的概率逐漸上升,由于采用本文算法是融合論文不同特征構建的空間向量模型,因此能夠有效提取文檔特征,從而當文獻列長度更大,則相應的關聯相似度更大,則表現出更高的準確率。
TopN=10條件下,不同論文庫規模下的算法準確率測試結果,如圖4所示。
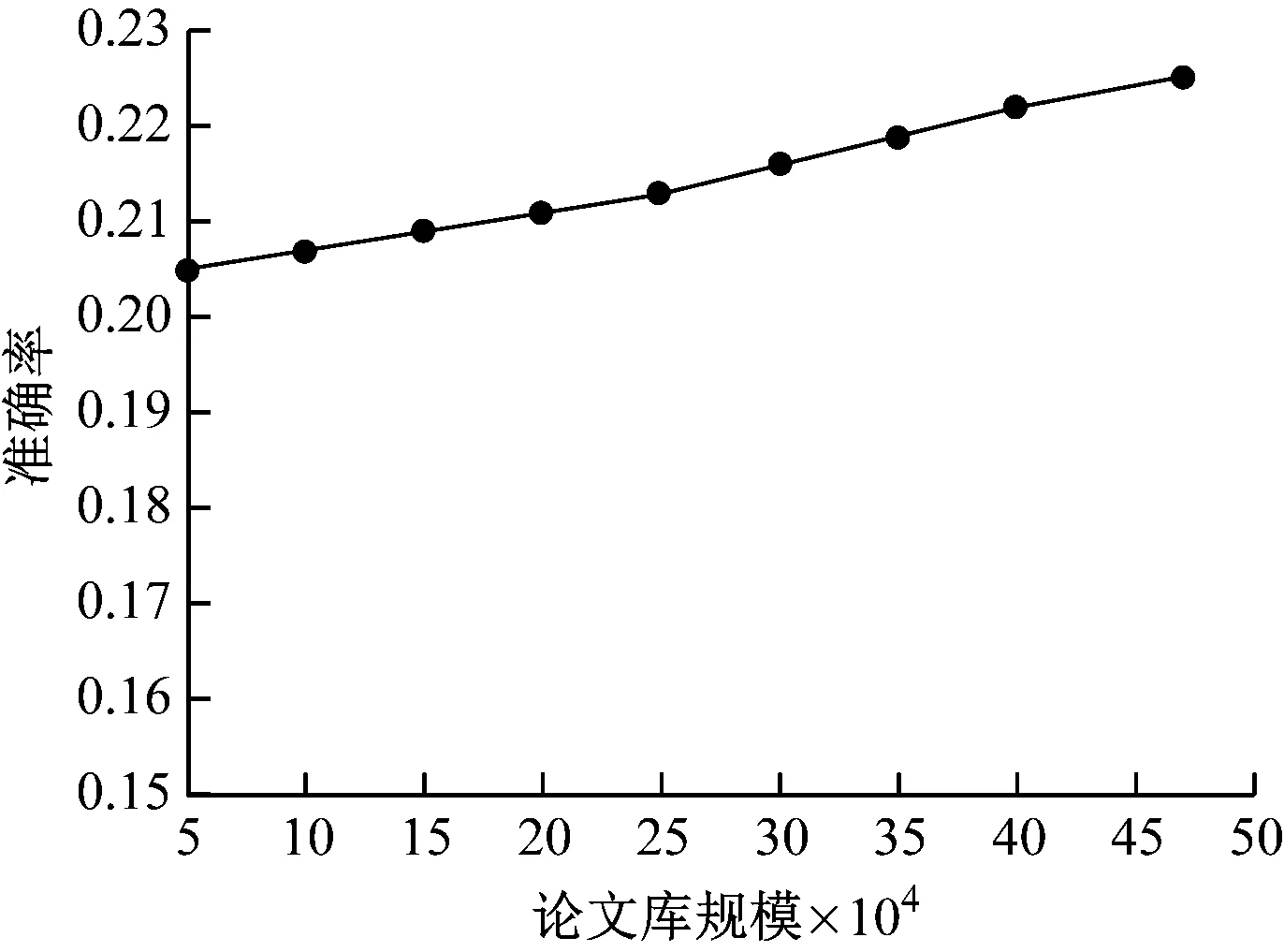
圖4 不同論文庫規模下的算法準確率
可以看出,隨著論文庫規模不斷增加,數據更為豐富,算法的準確率穩步提升。采用RDD關聯三元組算法是基于“先計算后檢索”方案進行,能夠根據所需文獻形成的兩兩相似度數值進行檢索排序,因而論文庫越大,則相似度數值越精確,準確率越高。
4 總結
本文在大數據背景下,提出了一種“混合關聯”的圖書館文獻推薦內存算法。通過將短文本“字符串匹配”和長文檔“相似性度量”進行匹配,引入調和參數實現不同分詞相似度的融合,提高文獻的相互關聯性。并通過構建文獻、權重間的Spark RDD三元組實現文獻的交叉推薦,根據不同的混合權重排名獲得不同長度推薦列表。在引入準確率進行算法的評價中表明,該算法在較大圖書資料系統中依然具備了非常高的準確率,并能夠滿足用戶對感興趣資料文獻的查找需求。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
財經(2017年2期)2017-03-10 14:35:35
讀者(2017年5期)2017-02-15 18:04:18
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
