基于機器學習的雷達電子偵察中的應用探析
2021-06-03 06:40:24徐福富劉欣怡高希光
信息記錄材料 2021年4期
徐福富,劉欣怡,高希光
(中國電子信息產業集團桂林長海發展有限責任公司 廣西 桂林 541001)
1 引言
隨著技術的不斷發展,以人工智能技術基礎的認知技術也迎來了新一輪的發展[1-2],在現代信息戰場的電子戰領域中,電子偵察是軍事情報偵察的重要手段之一,可以說任何在戰場上采取的大多數對抗及進攻模式都需要以電子偵察為基礎,而且電子偵察裝備并不輻射電磁能量,可靈活搭載于各種海陸空平臺中,需要反應迅速、提供情報及時等特點。電子偵察對特定區域或特定輻射源目標的信號進行預先的精確參數測定、收集和記錄,為己方有針對地發展和使用電子對抗技術、制定軍事作戰計劃提供依據。強調的是快速反應能力以及實時的分析和處理能力,將人工智能技術應用于電子偵察能夠提高偵察設備的反應速度與提供更準確的情報[3-4]。
傳統的電子偵察是將偵察所得的信號進行分析,并將所得的結果存儲于數據庫中,如果之后遇到相同或者相似的威脅,仍需要進行比對,之后再采取相應的措施,這大大耗費了時間,很難進行有效的對抗,此外,傳統的電子偵察沒有進行有效整合,其數據庫所包含的信息難以有效描述復雜多變環境下復雜多變的信號。本文通過采用機器學習的方法對所偵察得到的雷達信號進行處理,并將所得的分析結果進行圖形建模,并能夠通過數據量對模型進行完善,從而能夠快速識別出輻射源的威脅情況,并建立與之對應的干擾策略,若后面有相同或者相似的威脅,可以根據先驗模型直接識別出輻射源信息,對其進行快速干擾,而不必重新分析,從而節省時間與資源[5-6]。而對于新型和未知威脅信號,則可以利用其信號特征來完善所建模型,從而優化模型,相對于傳統的“條目狀”比對更具優勢。
此外,電子偵察的作戰對象如雷達、通信等電子信息設備開始逐步走向認知,智能化方向發展,使得相關設備具有自主學習,推理,決斷能力,傳統的電子偵察設備獲得對方的信息難度加大,因此,采用將人工智能技術應用于電子偵察中,對未知信號進行檢測,提取相應特征,優化所使用的智能識別設備模型,提高偵察設備的識別能力。
2 偵察處理流程
電子偵察主要對接收信號進行提取其相應信號特征,從而利用其特征信息對設備進行識別。其識別流程如圖1所示。

圖1 偵察識別流程
電子偵察主要對設備進行識別,從圖1中可以看到,識別設備主要包括信號特征提取、模型建立與優化、模型識別等三個部分,在電子偵察中,對信號所提取的特征可以傳給數據庫進行積累,進行訓練模型,也可以為干擾提供數據支撐。從圖1可以看出,模型判決是偵察識別流程的關鍵,其主要是利用所建立的模型對信號進行快速識別,從而識別出設備,當無法匹配時,將所得到的未知信號特征存入數據庫進行積累,對模型進行優化訓練,從而使模型對在下一次對這種未知信號進行識別,為后續的干擾提供參考。
本文采用機器學習中的決策樹方法進行建立模型,利用信號所提取的特征作為樣本,進行建模,所建立的模型會隨著數據庫數據量的增加和充實,不斷優化,相對于傳統的比對匹配方法,更簡潔,速度更快,隨著模型的不斷完善,其對設備的識別率也在不斷提高,識別出設備的威脅等級,能為后續的干擾提供重要的信息。
3 建立決策模型的方法
決策樹是一種常見的機器學習方法,一般情況一棵決策樹包含一個根結點、若干個內部結點和若干個葉結點;葉結點對應于決策結果,其他每個結點則對應于一個屬性測試;每個結點包含的樣本集合根據屬性測試的結果被劃分到子結點中;根結點包含樣本全集。從根結點到每一個葉結點的路徑對應了一個判定測試序列。決策樹的目的是為了產生一棵泛化能力強,即處理未示例能力強的決策樹,其基本流程遵循簡單而且直觀的“分而治之”策略,是一種進行分類與回歸的方法;本文利用決策樹進行建模訓練,學習時,利用訓練數據,根據損失函數最小化原則建立決策樹模型;訓練時,對新的數據,利用決策樹模型進行分類。
決策樹學習主要包含3個步驟:特征選擇、決策樹的生成、決策樹的修剪。本文采用的是CART算法,CART模型決策樹的生成就是遞歸地構建二叉決策樹的過程,對回歸樹用平方誤差最小化準則,對分類樹用基尼指數最小化準則,進行特征選擇,生成二叉樹。CART生成算法如下:
輸入:訓練數據集D
輸出:決策樹模型
根據訓練數據集,從根節點開始,遞歸的對每個節點進行以下操作,構建二叉決策樹。
(1)設結點的訓練數據集為D,計算現有特征對該數據集的基尼指數。此時,對每一個特征A,對其可能取的每個值a,根據樣本點對A=a時的測試為“是”或“否”將D分割成D1和D2兩部分,計算A=a時的基尼指數。
(2)在所有可能的特征A以及它們所有可能的切分點a中,選擇基尼指數最小的特征及其對應的切分點作為最優特征與最優切分點,依最優特征與最優切分點,從現結點生成兩個子結點,將訓練數據集依特征分配到兩個子結點中去。
(3)對兩個子結點遞歸地調用(1)、(2),直至滿足停止條件。
(4)生成CART決策樹。
算法停止計算的條件是結點中的樣本個數小于預定閾值,或樣本集的基尼指數小于預定閾值,或者沒有更多特征。CART剪枝算法由兩部分組成:首先從生成算法產生的決策樹T0底端開始不斷剪枝,直到T0的根節點,形成一個子樹序列{T0, T1,…,Tn};然后通過交叉驗證法在獨立的驗證數據集上對子樹序列進行測試,從中選擇最優子樹,完成建模。
下面以10個樣本數據為例子進行解釋說明,用基尼指數來計算其節點。

表1 樣本數據例子
從表1中可以看出,樣本數據10個例子,型號有2種,“A”有6種,“B”為4種,對于信號類型和調制方式等特征參數,對其進行賦值量化,根據根節點信息熵的計算公式,計算信息熵為:

接下來,計算特征集合中每個特征的信息增益(即基尼指數),首先計算每個特征的基尼值,從表中可以看出,信號類型只有雷達,其基尼值為:
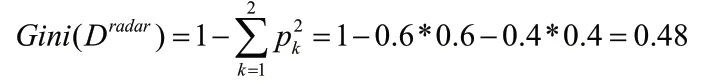
信號類型的基尼指數為:

調制方式的基尼值為:


信號類型的基尼指數為:
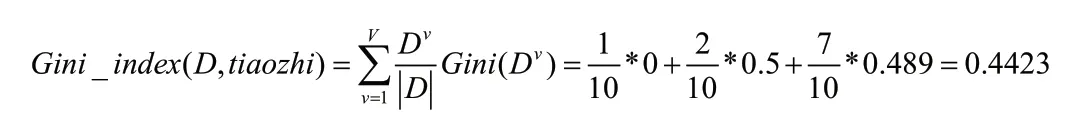
同理,下面對頻率,帶寬,脈寬,脈沖重復周期等特征參數求基尼指數,找出最小的基尼指數,即為根節點,并在最小基尼指數的特征上找出切分點,將訓練數據分成兩組,重復上面的情況,求解下一節點,依次即可建立決策樹的模型。
對于類似頻率等連續值的特征需要進行離散化處理,以頻率為例,在表中10個樣本中,頻率的值為10個,分 別 是(8255,9004,9752,10504,11254,12005,8151,8903,9655,10402)直接對頻率進行排序,排序后 的 結 果 為(8151,8255,8903,9004,9655,9752,10402,10504,11254,12005),然后取前后兩個頻率點的中間值做為分支點,分支點為(8203,8579,8953.5,9329.5,9703.5,10077,10453,10879,11629.5)同 理計算其基尼指數即可。
4 仿真與建模
下面利用數據進行仿真實驗,選用4種設備的參數,型號為“A”、“B”、“C”、“D”四種型號的設備的訓練樣本,利用不同數據量進行建模,并對測試數據進行判決。
四種設備時,分別選取總樣本數據120,600,3000,15000例,平均每種型號設備的訓練樣本分別為30,150,750,3750例,并且設備之間的特征參數具有重疊的區間。對模型進行建模,所建模型變化見圖2。
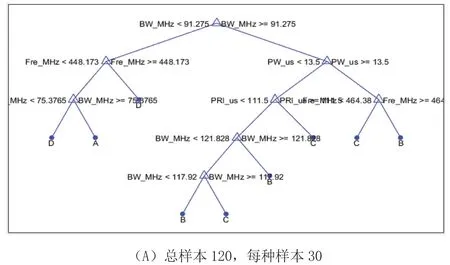

圖2 四種型號建模情況
從圖2可以看出,訓練數據的增加,都會增加模型的復雜度,也使模型的構建不斷完善,下面運用所建模型的四個模型,對測試數據進行測試,測試數據分別選擇每種型號80,400,2000,10000個樣本,做蒙特卡洛仿真測試100次,其測試結果見圖3。

圖3 模型測試識別情況
從圖3中可看出,模型(D)的識別率是最好的,相對于其他模型,其識別率也比較穩定,從而可以看出,模型越完善,其識別率更好,圖2可以看到,訓練數據的增加,使模型更加優化。結合圖2和圖3,可以看到,隨著數據庫的完善,其對數據模型進行優化,從而使識別率更好,對后面的情報分析與智能干擾提供重要支撐作用。
5 結論
通過利用機器學習中的決策樹對雷達輻射設備進行識別的仿真驗證與分析,可以看到,相對于傳統的匹配比對判斷,決策樹具有快速,不斷優化,具象化的優勢;判決模型也會隨著數據的完善而不斷優化,使得識別準確性提高,從樹形圖來看,對于某一種設備識別規則,有直觀的認識。隨著新型智能體制雷達的發展,傳統電子偵察難度在不斷提高,電子偵察技術需要往一體化,可優化,可重構方向發展,因此,將機器學習技術應用于電子偵察中能起到重要支撐作用。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:26:08
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
工業設計(2016年12期)2016-04-16 02:52:00
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
