基于深度神經網絡的配資網站識別研究
2021-06-03 02:23:02王叢雙
四川大學學報(自然科學版) 2021年3期
何 穎, 楊 頻, 王叢雙, 湯 娟
(四川大學網絡空間安全學院, 成都 610207)
1 引 言
近年來,隨著科技的迅速發展,互聯網已經成為人們生活中不可或缺的一部分. 中國互聯網絡信息中心在2020年的數據統計顯示,我國網民規模突破9億,網站數量達497萬個[1]. 然而,在互聯網為人們的生活帶來巨大便利的同時,網絡的負面影響也逐漸顯現. 網絡違法信息開始出現在互聯網的各個角落,其中通過提供非法配資來賺取盈利的網站對網民群體造成了嚴重的影響,威脅到了網絡用戶的財產安全.
配資是指根據資金需求方與配資公司簽訂的協議,在資金需求方原有資金的基礎上,配資公司以原始資金作為配資基數按照一定比例另行提供新的資金供資金需求方使用. 配資公司要求資金需求方必須使用其公司的賬戶進行操作,若選擇使用自己的賬戶,則需要抵押物,如車、房等. 配資公司會隨時監督賬戶的虧損情況,當虧損達到原有資金的一定金額并且持續虧損時,配資公司會強行平倉. 大量民間配資公司利用互聯網信息技術搭建互聯網配資平臺,而這些配資網站并不具備經營證券業務資質,其在本質上就不被法律允許,這種不受監管的配資帶來的爆倉風險和資金安全風險不容忽視. 而大量配資網站往往裹上投資咨詢、網絡信息和商貿服務的外衣,有著極強的迷惑性. 因此,為了能夠對配資網站進行監管,迫切需要能夠準確檢測出配資網站的方法.關于以網絡釣魚、網絡色情為代表的以提供非法內容為主的網站識別工作已經取得了一定的進展,但是對于配資網站識別的相關研究較少. 針對惡意網站識別問題,研究者提出了很多解決方案和識別技術,主要有基于黑名單的識別方法,基于網站URL異常特征的識別方法和基于網站頁面內容的識別方法.
基于黑名單的識別方法是用蜜罐技術、人工檢查等手段預先構建一份包含網站URL或關鍵詞信息的列表,通過黑名單技術可準確識別已被確認的釣魚網站或其他類型網站. 以PhishTank[2]為例,人們可自愿提交和共享釣魚網站網址,依據其提供的列表可以主動過濾釣魚網址. 這種方法誤報率低,但是無法準確識別新出現的釣魚網站,維護和更新完整的黑名單列表是十分困難的.
基于網站URL異常特征的識別方法是用分析URL特征來構建網站識別模型. Abdelhamid[3]根據URL特征,提出一種基于多標簽規則的分類算法來識別釣魚網站,能夠從單個數據集生成具有多個類標簽的規則. Moghimi等[4]提出基于規則的使用兩種新的特征集的釣魚識別方法,使用字符串近似匹配算法來確定特征集中的頁面內容和URL之間的關系. 方勇等[5]使用LSTM算法來挖掘釣魚網址字符序列的潛在特征,提出基于LSTM與隨機森林的混合框架模型提高了釣魚網站的識別效率和檢測準確率,能夠快速識別海量釣魚網站攻擊. 但是網站URL特征有限且容易模仿,這在很大程度上限制特定網站識別的實際效果.
基于網站頁面內容的識別方法是用挖掘標題、圖片、關鍵字等網頁內容中的特征進行識別. Mao等[6]指出網頁之間的相似性是檢測釣魚網站的一個重要指標,提出一種基于網頁之間視覺外觀相似度來量化網頁可疑度評級的算法,使用層疊樣式表作為基礎來量化每個頁面元素的視覺相似性,并用真實的釣魚網站樣本證明了它的有效性. Zhang等[7]從文本內容和視覺內容的角度檢測釣魚網站,利用貝葉斯理論推導出的概率模型,有效地估計文本分類器和圖像分類器的匹配閾值,可直接合并不同分類器產生的多個結果. Jain等[8]綜合分析了基于視覺相似性的釣魚檢測技術,其利用文本內容、文本格式、HTML標簽、層疊樣式表和圖像等特征集來做出判斷,能夠有效應對釣魚攻擊. 這些工作的關鍵在于特征的選取,不同特征的識別效果存在一定的差異. 另外,沙泓州等[9]在研究中指出,移動互聯網的繁榮和社交網站的興起使得網頁的傳播途徑逐漸多元化,可以通過掃描“二維碼”和社交網站的形式傳播. 新的應用場景的出現,豐富了特征選擇的范圍,也對特定網站識別時選擇的特征提出了更高的要求. 同時,網站規模的迅速擴大帶來了海量新特征,為了保證識別效率,需要選擇有助于識別特定網站的重要特征變量.
近年來深度學習在計算機視覺[10]、圖像處理[11]、自然語言處理[12]和大數據分析[13-14]等許多領域的應用中取得了不錯的表現. 深度神經網絡(Deep Neural Networks, DNN)作為一種深度學習架構在分類問題方面[15-16]非常成功. 在上述研究成果的基礎上,本文從5個不同的維度選取能夠有效識別配資網站的重要特征,包括域名特征、搜索引擎收錄特征、HTML標簽特征、圖片特征和文本特征,較全面地體現了配資網站和其他類別網站的本質區別,提出一種基于深度神經網絡的配資網站識別模型.
2 基于深度神經網絡的配資網站識別模型
2.1 模型框架
本文提出的配資網站識別模型如圖1. 該模型主要包含三個部分:數據采集模塊、特征處理模塊和識別模型模塊. 首先,我們通過動態爬蟲技術和文本處理手段采集原始數據,進行格式化處理后,經特征提取器提取多維度特征數據;然后,經過特征向量化,將字符串等文本特征轉化為特征向量;最后,我們將實驗數據隨機抽樣分成兩組,使用深度神經網絡算法,利用訓練集建立配資網站識別模型,再利用測試集對該模型的識別性能進行驗證.
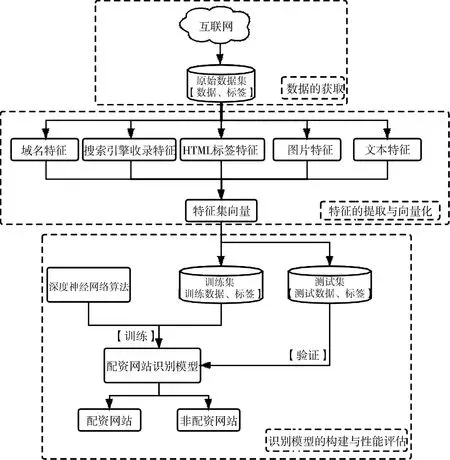
圖1 識別模型構建及評估流程Fig.1 Process of recognition model construction and evaluation
2.2 特征選取
為了提高配資網站識別的準確性和可靠性,選取的特征需要能夠充分體現配資網站的特征,并能夠有效區分配資網站和其他類型網站. 本文參考傳統惡意網站識別特征,在對大量配資類網站樣本分析的基礎上,從多個維度選取了共60個特征,這些特征可歸納為域名特征、搜索引擎收錄特征、HTML標簽特征、圖片特征和文本特征等5大類,具體內容如圖2所示.
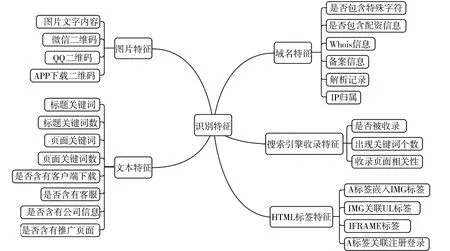
圖2 識別特征Fig.2 Identification features
(1) 域名特征.基于域名的特征可以分類為詞匯特性和域名屬性特性.
詞匯特性是域名本身的文本屬性. 域名由于其便于記憶的特點,成為使用者使用網站的代名詞,運營者為了促進網站傳播,加深使用者記憶,會使用與網站內容相關的短詞匯,如PZ、Peizi等字符. 域名中的短文本詞匯是反映網站類型的一個重要體現.
域名屬性信息包括域名的Whois信息、備案信息、解析記錄、IP歸屬等,這些信息可以反映目標域名的背景情況,Whois信息有域名的注冊時間、注冊人等,備案信息有備案網址名稱、備案主體信息等,解析記錄有目標域名變更情況,IP地址的歸屬等. 單獨來看這些信息并不能作為有效區分配資網站和非配資網站的特征,但將這些特征與其他特征融入在一起后,能有效地反映域名的背景狀況. 除此之外還有域名解析記錄在一定時間范圍的變化頻率,實驗中選取一年(域名的一般購買周期),獲取該一年內域名解析IP的變更次數,以及這些IP地址是否屬于CDN類型IP或IDC類型IP等.
(2) 搜索引擎收錄特征.搜索引擎是一種收錄互聯網各種類型網站網頁內容,給用戶提供海量內容準確檢索服務的工具. 借助搜索引擎,可以使用關鍵詞檢索出大量與關鍵詞相關的內容. 為了利于網站的傳播,增加被搜索引擎收錄的內容,存在一種搜索引擎優化技術(Search Engine Optimization, SEO),來提高某一個網站被網絡收錄的速度和關鍵詞數量. 配資網站需要通過推廣來增加用戶量,一般會使用這種技術手段增加收錄關鍵詞量. 因此,指定域名網站的搜索引擎收錄情況,是否被搜索引擎收錄配資等關鍵詞,是配資網站的重要特性之一.
(3) HTML標簽特征.每一個網站都是由HTML、Javascript和CSS共同組建而成,用戶瀏覽網頁,是瀏覽器對這些代碼渲染后的效果. 通過對配資網站的大量分析,本文發現配資類網站在網頁結構上具有眾多特有特征:(a) A標簽嵌入IMG標簽. 配資網站常使用在A標簽中嵌入IMG標簽來使用戶點擊圖片以達到跳轉的目的. 配資網站會在網站首頁添加大量虛假的友情鏈接,包括銀行等,使用這種技術手段來欺騙用戶,并且A標簽的鏈接多為站外鏈接;(b) 導航欄IMG標簽. 眾多配資網站會在導航欄左側使用圖片標簽的形式展示配資站點的名稱,右側則以ul/li標簽結合A標簽的形式給出導航菜單選項,A標簽內容為站內鏈接;(c) Iframe標簽. 配資網站為了簡化部署復雜度,達到快速建站,快速遷移的目的,會使用iframe標簽嵌入主站內容,從而實現只需要修改主站內容,其他網站就會同步更改;(d) 基于A標簽的注冊、登錄跳轉. 配資網站為用戶提供了復雜的交易功能,需要涉及用戶注冊、開戶等,因此基于A標簽的注冊跳轉也被應用于模型中.
(4) 圖片特征.非法配資網頁的傳播方式隨著新的應用場景的出現逐漸多元化. 二維碼作為一種全新的信息傳遞、識別和存儲技術,能夠快速傳播網頁. 配資網站在設計網頁頁面時,往往將二維碼放置在醒目的位置,吸引用戶去掃描,以達到推廣網頁的目的. 同時,隨著即使通訊工具的廣泛使用,配資公司還會利用微信或QQ二維碼、APP下載二維碼來宣傳配資資訊,錯誤地引導投資者. 因此,檢查網頁中是否包含二維碼圖片是識別配資網站的有效方法. 配資網站中的虛假宣傳圖片、配資內容宣傳圖片也是本模型關注的重點,通過提取配資網站中的圖片數據,并使用文字識別工具識別圖片中的文字信息,基于文本關鍵詞來判斷文本內容是否與配資相關.
(5) 文本特征.為了實現擴大宣傳、增強網站影響力的目的,配資網站會發布大量與配資相關的內容,其文本特征與正常網站存在較大差異,這是無法偽裝的,這些差異恰恰可以作為判斷該網站是否是配資網站的重要依據.
在多數情況下,和網站頁面中其它位置的文本信息相比,網站標題的文本信息能夠更好地概括網站的主題內容. 配資網站往往會通過在標題中使用“配資”、“操盤”、“股票”、“平臺”等關鍵詞來吸引和欺騙用戶. 除標題外,頁面中的文本信息經常含有“配資”、“杠桿”、“策略”、“實盤”、“開戶”、“操盤”、“新手”和“交易”等關鍵詞. 因此,是否出現以上關鍵詞,統計關鍵詞出現的個數,以及在眾多關鍵詞中出現的幾個組合關鍵詞的個數等特征將用來判斷網站是否為配資網站.
同時,頁面內容中是否包含“客戶端下載”、“客服”、“公司信息”、“推廣頁面”和“關于我們”,這些文本內容也是能有效區分配資網站和非配資網站的文本特征.
2.3 檢測模型算法
人工神經網絡雖然已經被研究了70多年[17-18],但隨著一些研究人員的開創性工作,它們開始被廣泛應用在解決數據挖掘問題上. 在擁有足夠的計算資源和訓練數據的情況下,多層人工神經結構可以學習復雜的非線性函數映射. 對于分類任務,更高層次的表示放大了輸入的各個方面,這些方面對于識別和抑制無關的變化非常重要.
神經網絡分類器可以簡化為三層結構:輸入層、多個隱藏層和輸出層. 本文選擇的多層神經網絡結構如圖3所示. 輸入層的每個神經元代表一個特征,首先隨機初始化權值,權值向量可以被認為是一個向量到另一個向量上的投影,或者是兩個向量之間相似度的度量. 然后利用梯度下降調整參數使誤差最小化. 學習過程包括連續多次向前和向后傳遞. 在前向傳播中,通過多個非線性隱藏層將輸入轉發到輸出,并最終將計算出的輸出與對應輸入的實際輸出進行比較. 在反向傳播中,相對于參數的誤差導數被反向傳播以調整權值,以使輸出中的誤差最小化. 這一過程將持續多次,直到在模型預測中獲得了預期的改進. 如果Xi為輸入,fi為第i層的非線性激活函數,第i層的輸出可以表示為
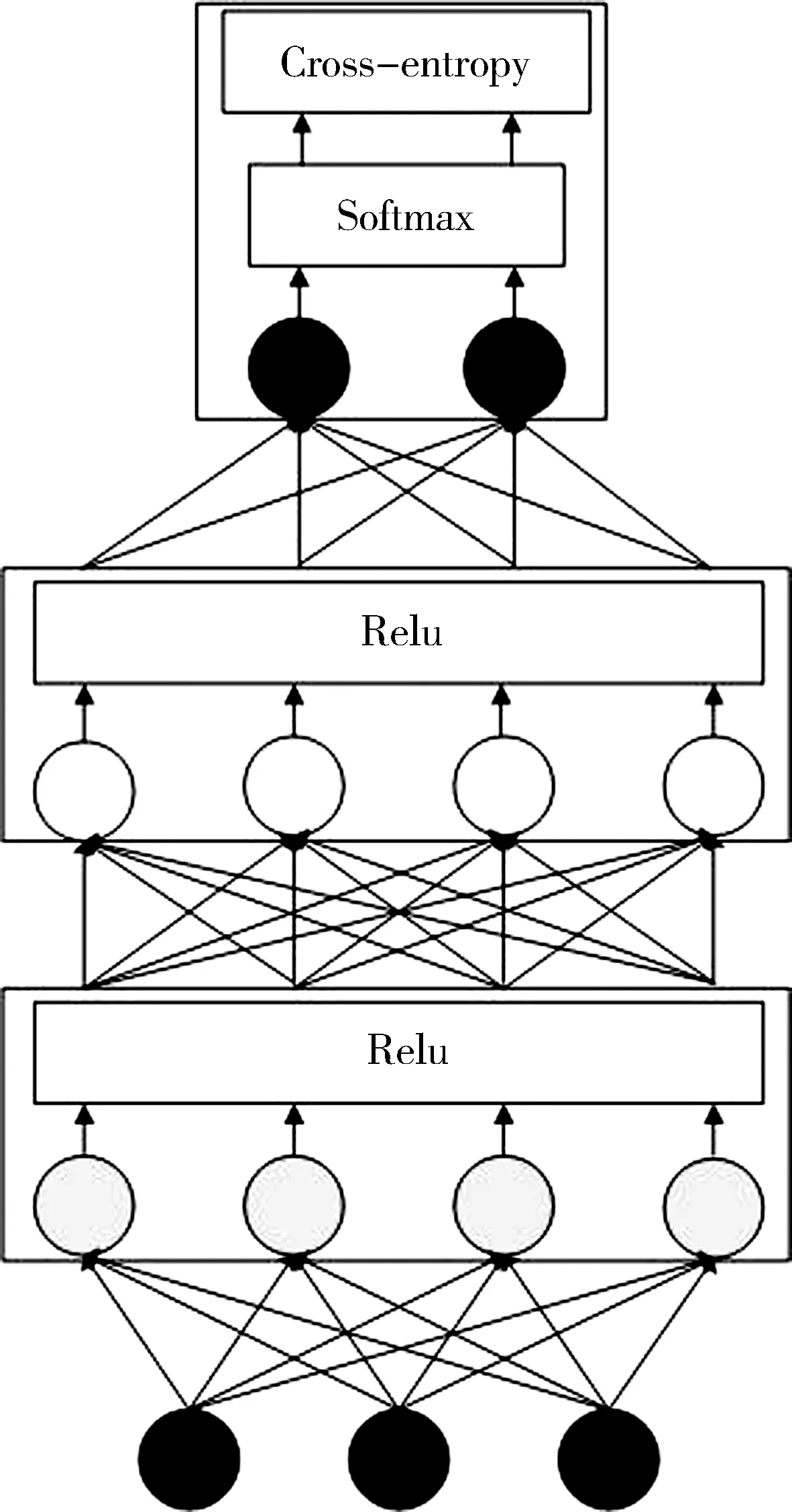
圖3 多層神經網絡結構圖
Xi+1=fi(WiXi+bi)
(1)
其中,Xi+1為下一層的輸入;Wi和bi是連接層與層之間的參數. 在反向傳播中,這些參數可以更新為
Wnew=W-η?E/?W
(2)
bnew=b-η?E/?b
(3)
其中,Wnew和bnew分別是W和b更新后的參數;E為損失函數;η為學習率.
本文模型中隱藏層使用的是ReLU激活函數,輸出層使用的是Softmax激活函數,選擇的損失函數是categorical_crossentroy(分類交叉熵),交叉熵損失只考慮樣本的標記類別,而不考慮標記類別之外的其他類別,其損失函數可以表示為式(4)所示.
(4)
其中,L表示樣本的交叉熵損失;yi為樣本被正確分類的輸出;yj為樣本y從類別1到類別n的輸出. 每次對損失進行計算后,會根據損失對模型中的參數進行更新,對模型中參數進行更新的過程就是學習的過程.
3 實驗結果與分析
3.1 實驗數據及環境
為了對模型進行充分驗證,本文分別采集了1 200個配資網站(正樣本)并進行了手工驗證,3 000個其他類型網站(負樣本). 為了使負樣本能充分覆蓋除配資網站外的網站類型,先通過CommonCrawl可信網站平臺選取了5×104個目標網站,使用2.2中第五點文本特征中包含的多個文本關鍵詞組合,剔除目標網站中不存在這些關鍵詞的網站,并結合人工篩查,最終選擇了3 000個目標網站作為訓練數據集. 實驗采用了十折交叉驗證方法對模型進行評估. 本模型實驗環境為單臺PC機,Intel酷睿i7處理器,16 G內存. 神經網絡采用Python語言的scikit-learn[19]和keras框架進行實現.
3.2 實驗指標
實驗評估指標可以通過以下4種類型表示:(1) 真陽性(TP),數據標簽為配資網站,并且模型識別結果也為配資網站的數據類型;(2) 假陽性(FP),數據標簽為非配資網站,并且模型識別結果為配資網站的數據類型,即誤報;(3) 真陰性(TN),數據標簽為非配資網站,并且模型識別結果為非配資網站的數據類型;(4) 假陰性(FN),數據標簽為配資網站,并且模型識別結果為非配資網站的數據類型,即漏報.
使用準確率(Accuracy)、召回率(Recall)、精確率(Precision)和調和平均數(F1)作為模型性能的基本評估指標,這些指標的計算方式分別為式(5~8).
(5)
(6)
(7)
(8)
3.3 實驗步驟
為了驗證模型的效果,使用Python對第二章中配資網站識別模型進行了實現,并設計多個對比實驗,進行了如下的實驗步驟.
步驟1將原始數據集劃分兩組,數據組1用于模型的訓練,數據組2用于模型的實驗評估.
步驟2使用Keras實現神經網絡模型訓練和模型評估代碼,通過畫圖的方式展現不同的訓練輪數,記錄模型效果變化.
步驟3實現傳統機器學習模型訓練和模型評估代碼,通過圖像、表格等方式,記錄不同的參數下模型的效果,以獲取該模型的最佳效果.
步驟4使用準確率、精確率、召回率、ROC曲線等評估指標,觀察不同模型的評估結果.
本文模型的一些參數選擇包括,優化函數為Adam[20],訓練模型評估指標使用準確率,epochs為15,batch_size為32. 使用to_categorical來實現輸出正負樣本概率,訓練過程中對上述參數值,以及決策樹的深度、最大最小葉參數、支持向量機中的核函數、懲罰系數、K-鄰近的鄰居個數等參數進行調整,包括修改參數的大小,選用不同的參數值,最終根據模型的分類效果選擇最佳的參數.
3.4 實驗結果
對比決策樹(Decision Tree,DT)、支持向量機(Support Vector Machine,SVM)、K-鄰近(k-Nearest Neighbor,KNN)和深度神經網絡的實驗結果,本文設計的深度神經網絡模型在準確率、召回率、精確率等方面都優于以上傳統機器學習算法. 在準確率方面,深度神經網絡達到95.9%,并且精確率高達98.7%,傳統機器學習算法中決策樹是表現最差的,支持向量機優于其通過構建超平面能滿足高維度數據的二分類,其各種指標表現僅次于深度神經網絡,F1值為0.942. 4種算法的詳細評估數據見表1. 工作特征曲線見圖4.
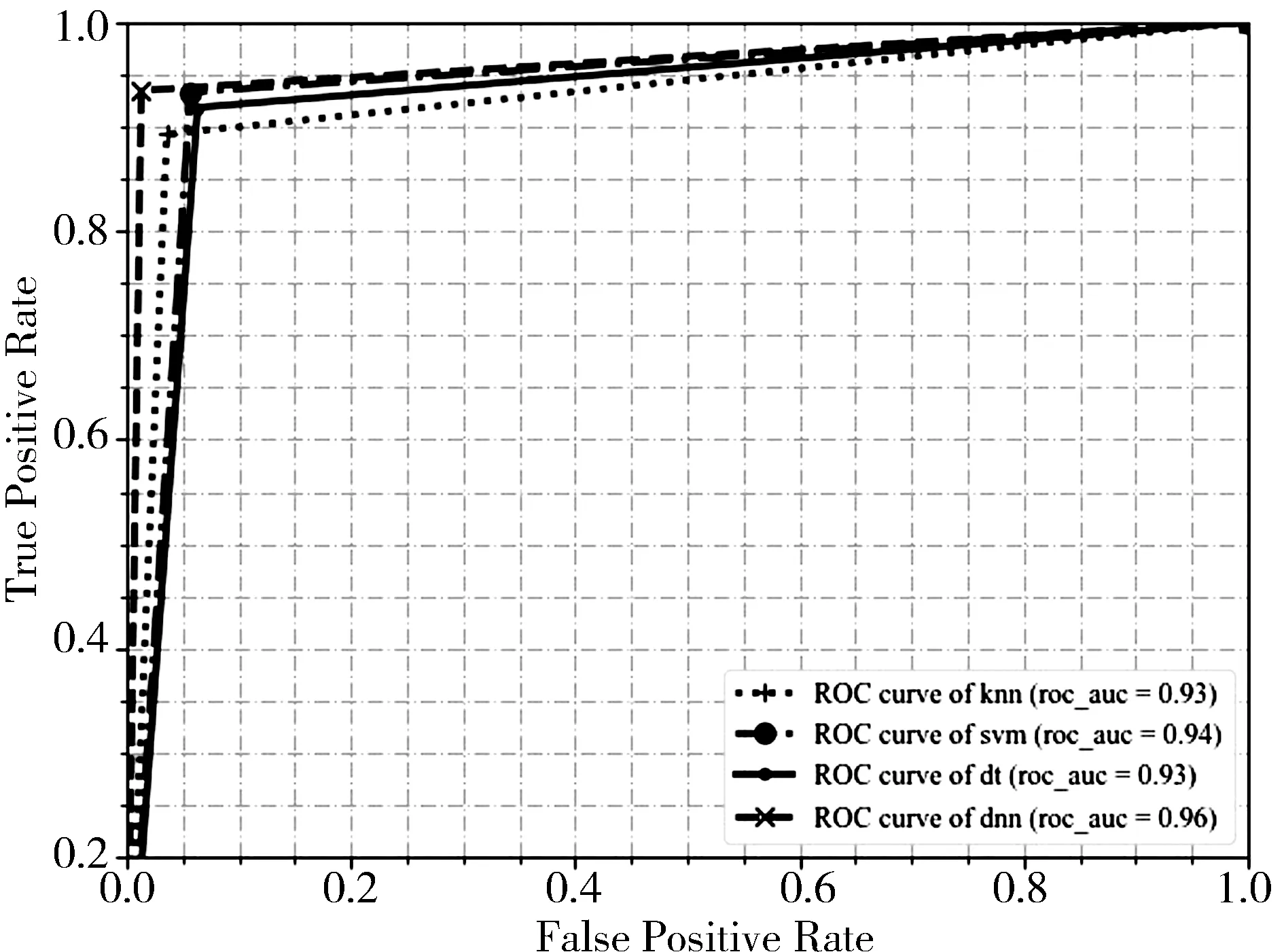
圖4 4種算法的ROC曲線Fig.4 ROC of four algorithms
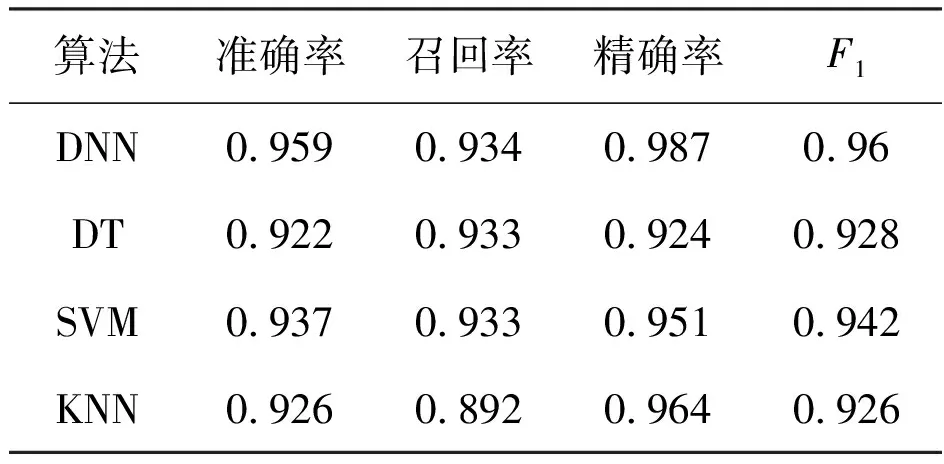
表1 實驗環境配置4種算法性能對比
4 結 論
傳統的網站識別模型在配資網站的識別上效果不佳,不能滿足對配資網站的準確識別. 為此,本文設計了一種基于深度神經網絡的配資網站識別模型. 本方法從多個維度選取區別配資網站和其他類別網站的關鍵特征,采用深度神經網絡構造分類器用于配資網站識別. 為了驗證該方法的有效性,與傳統的一些機器學習算法進行了比較,本文方法識別準確率接近96%,精確率達到了98.7%,均優于其他模型. 實驗結果表明,本文提出的配資網站識別模型能有效識別配資網站.
雖然本文模型擁有不錯的檢測效果,但是仍存在不足. 基于網站頁面內容的特征在本次實驗中占有很大比例,但配資網站可以通過在網頁中添加干擾內容來影響模型的識別效果. 因此本文下一步的研究是如何針對這種對抗,繼續提高識別準確率以及方法的穩定性.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
