一種基于模擬退火的動態(tài)發(fā)射型CGRA編譯方法
2021-05-28 12:37:42楊偉東
現(xiàn)代計算機 2021年10期
楊偉東
(上海交通大學(xué)電子信息與電氣工程學(xué)院,上海200240)
0 引言
可重構(gòu)架構(gòu)因為其相較于ASIC的靈活性和相較于CPU的高能效比,在Dennard縮放定律逐漸失效的現(xiàn)在[1],獲得了學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注[2-6]。相比于FPGA(Field Programmable Gate Array),粗粒度可重構(gòu)架 構(gòu)(Coarse-Grained Reconfigurable Architectures,CGRA)因為其粗粒度的重構(gòu)粒度,降低了重構(gòu)代價,帶來更高的能效比。
傳統(tǒng)的CGRA屬于靜態(tài)放置靜態(tài)發(fā)射(Static Issue,Static Placement,SISP)型CGRA[7-8],該類型的CGRA一般由指令進行驅(qū)動,需要編譯器顯式指明每條指令的執(zhí)行時間和對應(yīng)的處理單元,給編譯器開發(fā)帶來了較多約束,例如:計算資源的約束、存儲資源的約束、互連約束,等等。這些約束可能導(dǎo)致編譯器用調(diào)度效率來交換調(diào)度正確性,將優(yōu)化壓力集中到編譯器上,給編譯器開發(fā)帶來了嚴峻的挑戰(zhàn)。而且,如果CGRA內(nèi)部存在同步機制,每個處理單元(Processing Element,PE)需要等待執(zhí)行時間最久的PE的任務(wù)完成,使得其他處理單元處于閑置狀態(tài),從而導(dǎo)致CGRA性能降低。
針對以上問題,Zhao在文獻[9]提出一種靜態(tài)放置動態(tài)發(fā)射(Static-Placement,Dynamic-Issue,SPDI)型CGRA,通過硬件機制減少編譯器在時間域上的約束,對編譯器的開發(fā)更加友好,同時通過算子的動態(tài)執(zhí)行來減小同步機制帶來的性能損失。
本文面向以上SPDI型CGRA開展編譯技術(shù)研究,充分發(fā)揮其硬件性能。
1 SPDI型CGRA架構(gòu)
SPDI型CGRA主要加速程序中計算密集型循環(huán)。該類型CGRA不需要配置信息顯式指明算子的執(zhí)行時間,其內(nèi)部的Token Buffer機制可以根據(jù)算子的輸入操作數(shù)是否就緒以及CGRA內(nèi)部的資源情況動態(tài)地決定算子的發(fā)射時間,該類型的CGRA架構(gòu)如圖1所示。
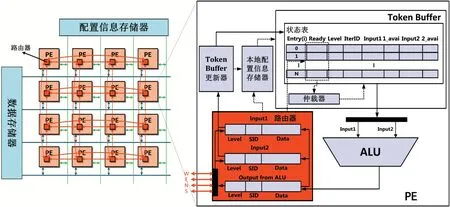
圖1 SPDI型CGRA架構(gòu)[9]
2 問題定義
CGRA的編譯是將需要加速的代碼編譯成CGRA配置信息的過程,該過程不僅要保證結(jié)果的正確性,還要進行調(diào)度空間探索,尋求性能最優(yōu)的調(diào)度(又稱映射)方案。完整的編譯流程如圖2所示。
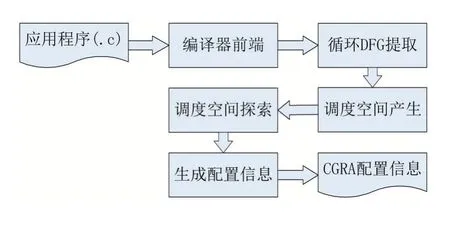
圖2 完整的編譯流程
調(diào)度空間探索主要研究循環(huán)映射技術(shù),探索如何更充分地利用硬件的計算資源。SISP型CGRA循環(huán)映射方法主要借鑒軟件流水[10]的思想,通過模調(diào)度算法[11]充分利用硬件資源。基于模調(diào)度的編譯技術(shù)[12-16]主要研究如何在更小的迭代間隔(Initiation Interval,II)下完成數(shù)據(jù)流圖(Data Flow Graph,DFG)的映射,一旦映射完成,II就是對其性能的表達(不考慮訪存沖突)。
SPDI型CGRA由于其更為寬松的約束機制,更有利于編譯器進行DFG的映射,更容易產(chǎn)生調(diào)度方案。但是由于其缺乏對性能的有效監(jiān)督,導(dǎo)致不同調(diào)度方案會有著不同的性能,圖3展示了一些應(yīng)用在不同的調(diào)度方案下性能的差距。
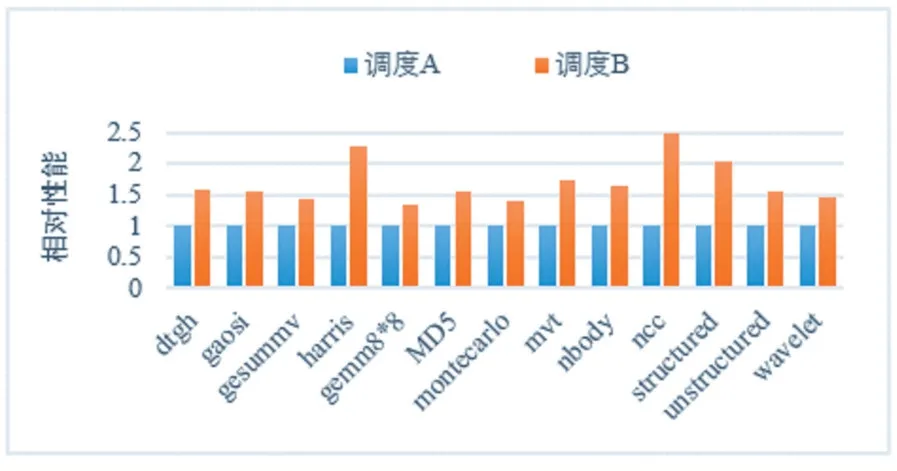
圖3 不同調(diào)度方案的性能對比
基于以上分析,和SISP的編譯技術(shù)解決的問題不同,SPDI型CGRA的編譯技術(shù)的重點和難點在于如何去進行調(diào)度空間的探索,如何從大量的調(diào)度方案中選擇正確且最優(yōu)的一種調(diào)度方案。
本文設(shè)計的面向SPDI型CGRA的編譯器前端主要用來提取源代碼中的循環(huán)部分,這部分代碼會被標(biāo)記,以供編譯器識別用于CGRA加速。這部分代碼在轉(zhuǎn)化成IR后會被編譯器提取出DFG,以DFG的形式作為源代碼和CGRA的媒介。DFG中的每個節(jié)點對應(yīng)CGRA中每個PE所執(zhí)行的一個運算,DFG中的邊(表示節(jié)點間的依賴性)對應(yīng)CGRA中的互連部分,由此引出了面向CGRA的有效映射的定義,如定義1所示:
定義1(有效映射):給定一個DFG D=(VD,ED),以及一個PE陣列G=(VG,EG),其中VD表示DFG中的節(jié)點集合,ED表示DFG中的邊的集合,VG表示PE集合,EG表示PE間支持的互連方式的集合,f(u)表示節(jié)點u映射的目標(biāo)PE,f(l)表示DFG的邊l映射的互連方式。因此,一個有效映射D->G需滿足以下要求:

滿足定義1的映射,即為面向SPDI型CGRA的有效映射,可以將該映射轉(zhuǎn)換成CGRA的配置信息,從而使用CGRA來對應(yīng)用進行加速。SPDI型CGRA由于缺少了時間軸上的約束,帶來了比傳統(tǒng)SISP型CGRA更為寬松的互連映射條件。
調(diào)度的高效性問題體現(xiàn)在不同的調(diào)度方案會產(chǎn)生不同的性能,需要選擇其中最優(yōu)的方案。這是一個典型的組合優(yōu)化問題,即從有限個可行解的集合中找出最優(yōu)解的過程,其數(shù)學(xué)表示如式(3)所示。

式中D表示所有滿足定義1的調(diào)度映射的集合即可行解的結(jié)合,f(x)表示當(dāng)前調(diào)度映射方案x下硬件的執(zhí)行時間。面向SPDI型CGRA的編譯器后端的主要工作就是解決上述這個組合優(yōu)化問題。
3 問題求解
基于第2節(jié)中定義的問題,基于SPDI型CGRA的編譯主要關(guān)注以下兩個問題:
(1)確定可行解的集合,即調(diào)度空間的產(chǎn)生;
(2)從可行解的集合中尋找最優(yōu)解,即調(diào)度空間的探索。由于可行解集合的規(guī)模隨著DFG和PE規(guī)模的擴大而迅速增長,無法通過窮舉來找出最優(yōu)解。
3.1 調(diào)度空間產(chǎn)生
調(diào)度空間的產(chǎn)生要求正確且盡可能全面地覆蓋所有可能的調(diào)度方案,從而更好地進行調(diào)度空間的探索。另外,由于調(diào)度空間產(chǎn)生和探索屬于編譯器的一部分,從利于程序員編程的角度考慮,需要自動化地產(chǎn)生調(diào)度空間,盡量少地需要人為干預(yù)。
進行調(diào)度空間探索要求迅速產(chǎn)生調(diào)度方案,基于以上考慮,采用文獻[16]中的前向貪婪和反向回溯的方法來作為本文中產(chǎn)生調(diào)度方案的算法。將調(diào)度方案的產(chǎn)生分為兩個子問題:算子的排序以及算子的放置。
對于前者,可以采用廣度優(yōu)先搜索(Breadth First Search,BFS)和深度優(yōu)先搜索(Depth First Search,DFS)來對DFG進行遍歷,從而得到一個一維的算子序列。在算子放置的過程中,可以采用貪婪算法,按照算子序列的順序進行放置,在放置過程中要考慮互連約束,如果出現(xiàn)違背定義1約束的情況,則進行回溯,直到滿足定義的1要求為止。同時,在算子放置的過程中,加入一個啟發(fā)式策略:每個處理單元所執(zhí)行的算子數(shù)目盡量均衡,這樣一般會比不均衡的情況的性能更高。通過這樣的方式,可以迅速得到定義1約束的調(diào)度映射。但是貪婪算法容易陷入局部最優(yōu)解,無法得到全局最優(yōu)解,所以只通過此方式來得到可行解,尋找最優(yōu)解的過程依賴于后續(xù)其他的算法。
上述算法可以正確地產(chǎn)生一個可行解,但是確定可行解的集合的問題和調(diào)度空間的探索問題有一定的耦合性,將于3.2小節(jié)中進行介紹。
3.2 調(diào)度空間探索
調(diào)度問題轉(zhuǎn)化為了一個組合優(yōu)化問題,可以使用模擬退火算法進行調(diào)度空間探索,該算法主要需要考慮兩個問題:代價函數(shù)的制定和鄰域的選擇。
針對代價函數(shù)的制定有兩種方案,一種是直接在仿真器上運行,另一種是對仿真器進行建模,用表達式來對仿真器的運行結(jié)果進行近似,前者結(jié)果準(zhǔn)確但是需要耗費大量時間,后者花費時間少,但動態(tài)發(fā)射的執(zhí)行模式以及編譯時難以預(yù)知的訪存沖突,導(dǎo)致建模的方案較難實現(xiàn),所以本文采用直接在仿真器上運行的方案。
另一個問題是鄰域的選擇,該問題也可以認為是3.1小節(jié)中調(diào)度空間的產(chǎn)生問題。之前的研究主要采用交換算子分配的PE的方式[17]。SPDI型架構(gòu)因為不涉及時間軸的約束,不用因為DFG上兩個節(jié)點相鄰時間不為1而添加路由操作,路由開銷較小。而交換PE的方式會帶來額外的路由算子開銷,一定程度上抵消了SPDI型架構(gòu)的優(yōu)勢,而且直接交換PE會產(chǎn)生大量的不滿足定義1的非法解,不適合本文中的調(diào)度空間探索。所以本文提出通過在算子排序階段對算子順序進行交換的方式來進行鄰域的選擇,然后通過貪婪算法進行放置,以此方式來保證每次鄰域交換幾乎都能產(chǎn)生有效解。兩個步驟共同作為模擬退火算法中的一次迭代(算法1中的NeighborTran函數(shù)和ScheduleGen函數(shù)),以此來進行調(diào)度空間的探索。
同時,在執(zhí)行模擬退火算法的過程中,記錄曾經(jīng)出現(xiàn)過的最優(yōu)解。最終的算法如下所示。
算法1:基于模擬退火的調(diào)度空間探索
輸入:經(jīng)過編譯器前端得到的中間表示IR
輸出:尋優(yōu)后的調(diào)度方案及其性能


4 實驗結(jié)果與分析
4.1 實驗方法
本文基于LLVM8.0.0實現(xiàn)了面向SPDI型CGRA的編譯器,可以將C語言編寫的應(yīng)用程序轉(zhuǎn)化成SPDI型CGRA的配置信息,并通過C++編寫的SPDI型CGRA架構(gòu)仿真器評估本文提出的編譯算法的效果。
表1展示了實驗所采取的CGRA的硬件參數(shù),其中Torus的互連方式如圖1中紅色線條所示。
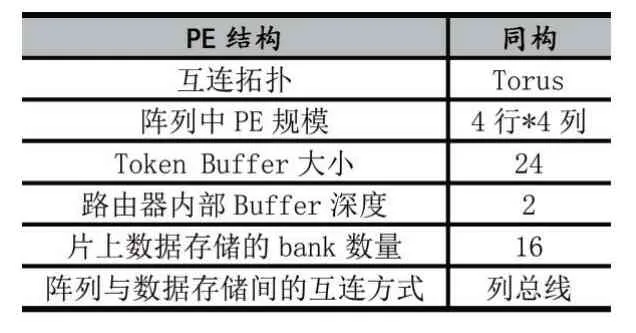
表1 CGRA硬件參數(shù)配置
benchmark選用來自EEMBC、MediaBench、Mach-Suit和Polybench等的循環(huán)核心。
本文將當(dāng)前執(zhí)行時間與理論最優(yōu)執(zhí)行時間的比值作為評估編譯算法性能的標(biāo)準(zhǔn),并將文獻[9]中的編譯算法作為baseline,驗證本文編譯算法的有效性。理論最優(yōu)執(zhí)行時間的計算如公式(4)所示。
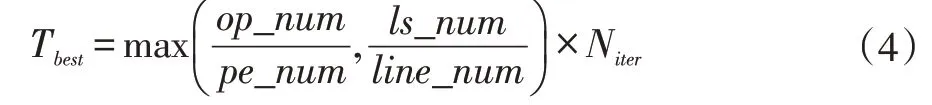
式中,Tbest表示理論最優(yōu)執(zhí)行時間,op_num表示應(yīng)用中算子數(shù)量,pe_num表示陣列中PE的數(shù)目,ls_num表示應(yīng)用中訪存(load和store)算子的數(shù)量,line_num表示陣列中列的數(shù)量,Niter表示循環(huán)的總迭代次數(shù)。
4.2 實驗結(jié)果
圖4展示了本文的編譯算法下不同應(yīng)用的性能和文獻[9]中編譯算法下相應(yīng)性能的對比。其中縱坐標(biāo)為當(dāng)前執(zhí)行時間與理論最優(yōu)執(zhí)行時間的比值,即縱坐標(biāo)為1時,性能為理論最大值。
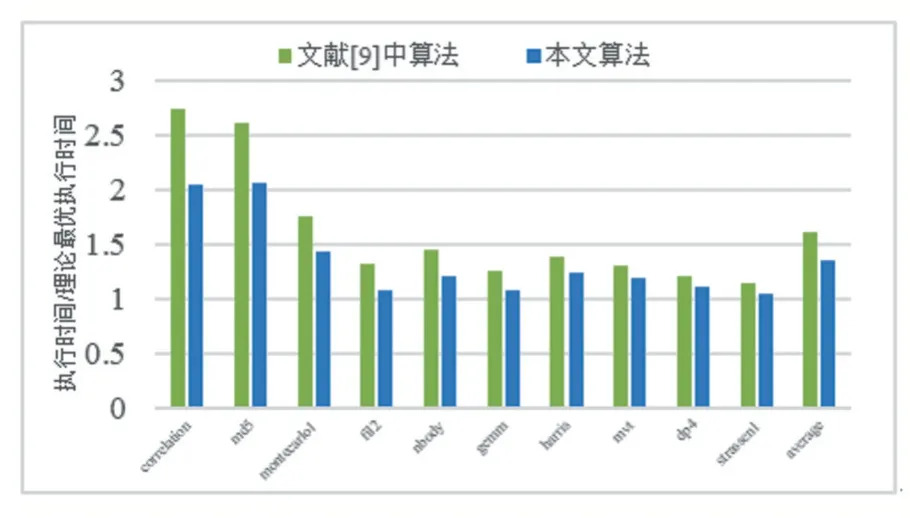
圖4 不同編譯算法下性能比較
統(tǒng)計圖4結(jié)果發(fā)現(xiàn),本文的編譯算法相比文獻[9]的算法,可獲得最高33.40%,平均19.80%的性能提升,體現(xiàn)了本文提出的編譯算法的有效性。
本算法導(dǎo)致性能提高的原因主要在于:
(1)更廣泛的調(diào)度空間。之前的調(diào)度空間的產(chǎn)生有其局限性,有些應(yīng)用即使完全窮舉,依然無法搜索到本文算法得到的最優(yōu)解。
(2)更為有效的尋優(yōu)算法。
5 結(jié)語
本文針對SPDI型CGRA架構(gòu)的編譯問題進行分析,將問題抽象為一個組合優(yōu)化問題,并通過使用模擬退火算法解決這個組合優(yōu)化問題。實驗結(jié)果顯示,本文提出的算法比之前的算法獲得了平均19.80%的性能提升。
