基于Python的就業信息獲取與分析
2021-05-28 12:38:20龐麗彭立偉余豪夏童趙付英
現代計算機 2021年10期
龐麗,彭立偉,余豪,夏童,趙付英
(1.西南石油大學網絡與信息化中心,成都610500;2.西南石油大學機電工程學院,成都610500;3.西南石油大學電氣信息學院,成都610500;4.西南石油大學地球科學與技術學院,成都610500;5.西南石油大學化學化工學院,成都610500)
0 引言
隨著高校的擴招,社會學歷普遍提高,大學畢業生人數逐年上漲,大學生就業形式也變得更加嚴峻,如何及時可持續性的獲取有效就業信息,并加以分析做出相應決策對于大學生而言顯得尤為重要。通過手動搜索招聘網站、學校/企業/事業單位官網、微信公眾號、各省市人力資源網等發布的招聘信息,可以獲得海量的就業信息,然而這種方式都需要到相應網站翻頁查找,重復的在不同網站之間切換,存在耗費時間長、搜索速度慢、信息獲取不及時、不利于集中分析統計等缺點,導致大學生容易錯過適合的崗位信息。針對目前的這種情況,本文提出了基于Python的就業信息獲取與分析的方法,以期為大學生搜索分析就業信息提供一定的參考價值。
1 網絡爬蟲簡介
網絡爬蟲又稱為網絡蜘蛛,是一種按照一定的規則,自動抓取萬維網信息的程序或腳本[1],基本原理是模擬計算機對服務器發起Requests請求,然后接收服務器端返回的Response內容對其進行解析,以提取所需信息。根據網絡爬蟲爬取的對象和范圍不同可將其分為通用網絡爬蟲和聚焦網絡爬蟲(即主題網絡爬蟲)[2],其中,通用網絡爬蟲爬取目標范圍廣,通常用于搜索引擎;而聚焦網絡爬蟲則是針對某個特定目標和主題進行爬取[3]。Python因其語言的簡潔性、易讀性以及可擴展性[4],在編寫網絡爬蟲時具有其他語言不可比擬的優勢,其強大的第三方庫不僅極大節省了開發人員編寫修改代碼的時間,還支持數據清洗和可視化,為后期的數據整理和分析提供了便捷,因此,本文采取Python語言編寫爬蟲代碼,采用主題爬蟲的策略來實現就業信息的批量獲取。
2 爬蟲程序設計
獲取相應網站的信息首先需要手動翻頁,通過觀察列表頁的URL,找到URL的構成規律;然后通過循環語句,依次將URL取出;最后抓取URL頁面相應的數據并存儲在本地進行數據清洗及分析。本文擬以拉勾網為例,通過編寫爬蟲程序抓取“Python”相關崗位的就業信息,獲取的信息包括公司名稱、公司規模、招聘崗位、公司福利、工作地址、薪資水平、工作經驗、職位類型、學歷要求、發布日期等,并將抓取的就業信息保存在MongoDB數據庫中,以便后期進行數據處理和可視化分析。
2.1 分析網頁結構
使用谷歌瀏覽器進入拉勾網,輸入Python關鍵字搜索就業信息,通過查看源代碼發現網頁元素不在源代碼中,判斷使用了AJAX(異步加載)技術,這種網頁要使用逆向工程來抓取數據[5]。利用谷歌瀏覽器開發者工具,選中XHR(可擴展超文本傳輸請求),通過觀察Preview標簽,可發現我們要獲取的信息都存放在Response返回的JSON文件中,進一步手動翻取拉勾網頁面,請求的URL并未發生變化,進一步分析發現是利用POST方法提交表單數據依據pn字段來實現頁數的變化,通過這些分析編寫程序代碼構造出列表頁。同時為避免網站把訪問當作爬蟲程序加以阻止,要使用cookie信息進行模擬登錄,以獲取信息。
2.2 獲取就業信息數據
就業信息獲取的實現主要包括三個部分:一是編寫getWebResult函數,用于獲取Response返回的JSON文件,從而得到崗位全部信息。首先需要創建一個Session對象,使用Session維持同一個對話,從而獲取該對話的cookie,利用cookie實現模擬登錄,然后獲取JSON文件職位相關信息。
二是編寫warefare_combine、address_combine函數對崗位信息中的福利數據和地址數據進行預處理,在爬取信息的時候,有的公司的福利、所在城市或城市所屬區域沒有寫,讀取時會返回結果None,由于None不能與字符串相加會導致爬取報錯,所以需要定義合并福利和地址的函數,當返回結果為None時,將其設置為空字符'',然后再實現相加。
三是編寫getJob_Infos函數,用于將獲取的崗位信息存儲在MongoDB數據庫中,需要導入PyMongo庫文件,連接數據庫并建立數據庫和數據集合。由于要將爬取的信息插入到數據庫中進行存儲,在循環調用函數之前還需要設置一個用來標示csv是否創建表頭的參數,表頭包括:公司、規模、招聘崗位、福利、工作地址、工資、工作經驗、職位類型、學歷要求以及發布時間,表頭創建完成之后再將爬取的信息逐條插入到數據庫中。循環體主要實現兩部分功能,一是循環讀取崗位信息并將福利和工作地址進行合并,避免出現爬取程序失敗,二是循環將信息逐條插入到數據庫中,表頭所對應的字段名可利用Preview標簽查看JSON文件,以便準確讀取相應內容。通過以上功能的編寫即可爬取python崗位相關就業信息。當控制臺提示“爬取信息結束!”,可在MongoDB數據庫中導出數據,導出的格式為CSV,由于編碼不同,用Excel打開文件會出現亂碼,先選用記事本打開,選擇編碼方式為ANSI再保存,打開文件后則顯示正常,如圖1展示了爬取的就業信息。
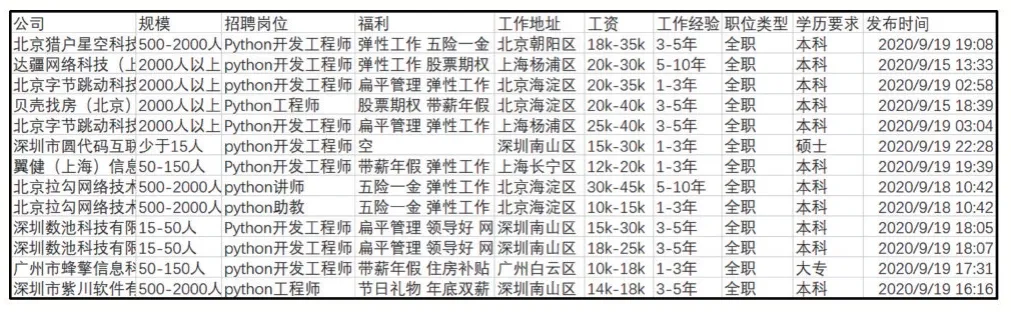
圖1 爬取的就業信息
2.3 就業信息數據處理
根據圖1所展示的爬取結果可以看出獲取的數據存在一些問題,不利于對數據進行分析,主要體現在:①工作地址具體到各個區,不利于宏觀了解Python崗位在各個城市的需求,需要將工作地址升級到市級;②工資格式顯示形式為區間,需要將最低工資和最高工資分開,便于了解Python崗位的薪資水平。選擇Excel作為數據處理工具,利用其提供的LEFT函數、FIND函數以及MID函數可以快速有效地對數據進行整理分析。
經過處理后的就業信息數據如圖2所示。
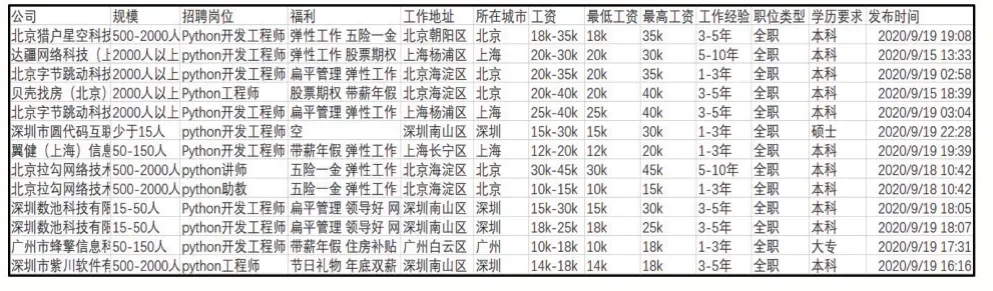
圖2 處理后的就業信息
3 就業信息可視化分析
根據前面整理好的數據,利用Excel的圖表功能對Python崗位招聘信息進行可視化分析,并結合Python的jieba分詞、WordCloud對崗位類型進行詞頻統計并詞云化。
從學歷要求來看(如圖3所示),從事Python相關的職業對學歷要求并不高,84%的崗位僅要求本科學歷即可,對碩士研究生的需求僅占2%,更加注重的是工作經驗(如圖4所示),要求有3-5年工作經驗的占42%,有1-3年工作經驗的占30%,應屆畢業生由于沒有相關工作經驗,符合需求的崗位僅占9%,建議大學生在校期間多參與實戰項目或者實習,了解當前技術的發展方向,熟悉項目的流程,積累更多的實戰經驗,以便在擇業時有更多選擇的空間。
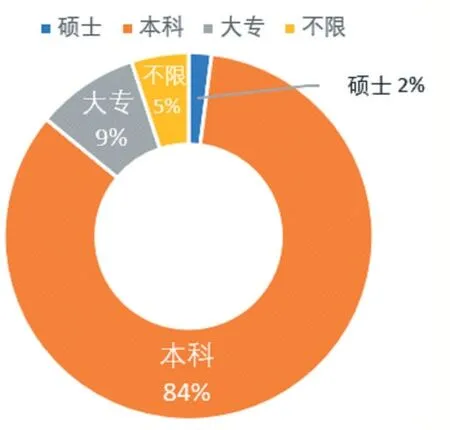
圖3 Python崗位學歷要求占比圖

圖4 Python崗位 工作經驗占比圖
從招聘所在城市來看(如圖5所示),對Python崗位需求較大的是北京、上海、深圳、廣州這四個一線城市,其次是杭州、成都、武漢等新一線城市,二三線城市對Python崗位需求相對較少,大學生在求職Python相關崗位工作時盡量優先選擇一線或者新一線城市,以獲取更多的工作機會和更好的發展前景。
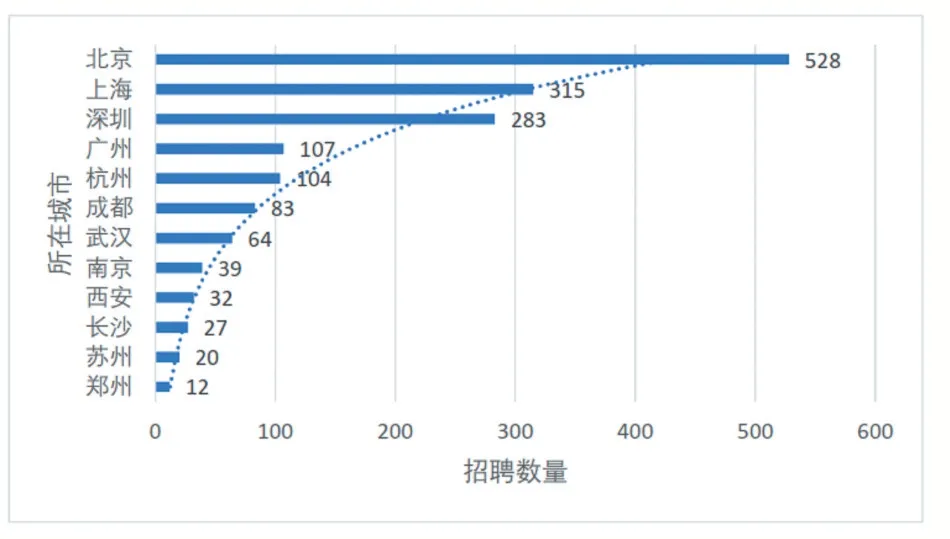
圖5 Python崗位城市需求分布圖
利用Python的jieba分詞,再通過WordCloud將招聘崗位高頻詞進行詞云化(如圖6所示),根據詞云圖生成原理,詞語顯示規格越突出、距離中心位置越近,詞語出現頻率越高[6],從詞云圖可以看出用人單位對Python開發工程師、中高級工程師、后端開發工程師以及研發工程師的需求量較大。進一步通過餅狀圖分析,可得出各招聘崗位所占比例,其中Python開發工程師占44%,中高級工程師占15%,后端開發和研發工程師分別占13%和9%,說明開發和研發類的崗位需求量較大,建議在校學生多學習了解開發工程師所需的技能和要求,以獲得更多的工作機會。爬蟲工程師、實習生、Python講師所占比例較小,爬蟲工程師的需求遠小于開發工程師原因可能在于純爬蟲的崗位需求越來越少,建議大學生在學習爬蟲時要更多的與數據挖掘、數據分析相結合,提高綜合競爭力。

圖6 Python崗位數量占比及詞云圖
為進一步了解Python各崗位薪資水平,對最低工資均值以及最高工資均值進行分析。從圖7薪資水平折線圖可以看出,Python相關崗位除了實習生的工資水平較低以外,總體來看其他崗位薪資水平較高。中高級工程師薪資水平最高,其次是運維/測試工程師、后端開發及研發工程師,爬蟲工程師和講師的薪資水平相對較低,推薦求職者在找工作時可先考慮招聘范圍較廣的Python開發工程師,在工作中不斷積累經驗提高能力,向薪資水平較高的中高級工程師過渡。
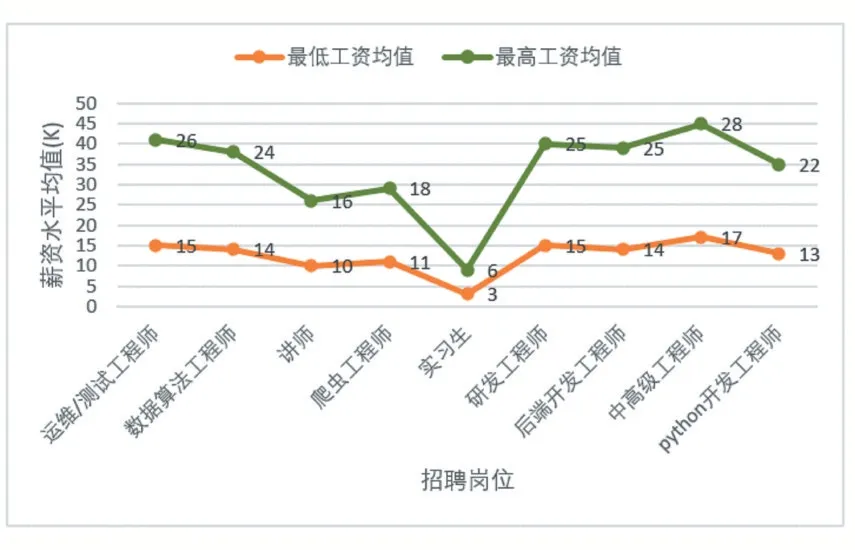
圖7 Python崗位薪資水平折線圖
4 結語
本文通過分析招聘網站網頁結構,利用Python語言及其強大的第三方庫編寫流程代碼,獲取相應的就業信息,并對收集到的數據進行清洗整理及分析,結合可視化圖表及詞云圖了解Python相關崗位的學歷要求、城市需求量、崗位分布情況以及薪資水平等,有效的降低了求職者手動翻頁瀏覽招聘信息的時間成本,分析結論能夠為求職者提供參考意見,同時也為在校學生提出了學習方向及側重點的相關建議。本文的不足之處在于只獲取了單個網站的就業信息,下一步的重點將放在如何進行多數據源的就業信息獲取,以獲得更加全面的就業信息。此外,本文主要針對個人求職者,因此,只是在獲取就業信息之后進行了簡單的統計分析;而對于高校管理者,如何在獲取海量的就業信息之后為學生實現個性化的就業信息推薦,則需要借助一些大數據分析技術。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
