基于Adaboost的改進Elman神經網絡港口吞吐量預測方法
2021-05-20 01:22:36李廣儒朱慶輝
重慶交通大學學報(自然科學版) 2021年5期
李廣儒,張 新,朱慶輝
(大連海事大學 航海學院,大連 遼寧 116026)
0 引 言
港口吞吐量體現港口的作業規模和經營成果,是衡量港口建設發展的重要指標。通過對港口吞吐量的預測,實現對港口未來短期及長期作業量的感知,可指導港口企業提前部署港口作業設施,有效銜接碼頭裝卸和堆場作業,減少貨物在港周轉時間。隨著港口智能化水平的不斷升級,港口作業更加高效,對港口吞吐量預測的準確度提出了更高的要求。
目前,針對港口貨物吞吐量的預測模型有很多,如灰色預測模型[1]、時間序列模型[2]、回歸預測模型[3]、Logistic生長預測模型等。同時,由于神經網絡具有很強的非線性擬合能力,有學者亦將神經網絡算法應用于港口吞吐量的預測。例如,劉枚蓮等[4]使用BP神經網絡對廣西北部灣港口吞吐量進行預測;劉長儉等[5]通過基于時間序列的BP神經網絡,對天津港集裝箱吞吐量進行了預測;李季濤等[6]通過RBF神經網絡算法對大連港的吞吐量進行預測。以上各類方法雖采取了不同的預測模型,但均是將預測問題轉化為靜態建模問題求解,具有一定的局限性。
針對港口貨物吞吐量基于時間序列動態變化的數據特點,楊珩等[7]采用Elman神經網絡對港口貨物吞吐量進行預測,取得了一定的預測效果。但由于Elman神經網絡通常使用梯度下降法作為學習規則,導致進行模型訓練和預測時,容易出現收斂過程不穩定、收斂速度慢、陷入局部最優值[8]等缺陷,導致預測誤差增大。Adaboost算法將多個弱預測器組合形成強預測器,通過對弱預測器設置不同的權重,能夠將預測誤差大的樣本分離出來,從而更加重視對誤差較大的數據的訓練,達到更高的精度。筆者將Elman神經網絡作為弱預測器,進行港口吞吐量的預測,同時選擇Adaboost算法將多個弱預測器組成Elman-Adaboost強預測器模型。然后采用該方法對寧波-舟山港的港口吞吐量進行預測,并將預測結果與相同數據及構建方式下的BP、BP-Adaboost以及Elman神經網絡的預測結果進行比較。
1 Elman-Adaboost算法
1.1 Elman神經網絡理論
Elman神經網絡是J.L.ElMAN[9]在1990年提出的。Elman模型在前饋式網絡的隱含層中加入了一個承接層作為一步延時的算子,以達到記憶目的,這使系統能更好適應時變特性,從而具有反映動態過程系統特性的能力。Elman神經網絡由輸入層、隱含層、承接層和輸出層共4層組成,如圖1。相比于BP神經網絡的網絡結構,Elman的承接層用于記憶隱含層單元前一時間的輸出值,能夠表達輸入和輸出間的時間延遲[10]。

圖1 Elman神經網絡的結構
1.2 Adaboost算法
Adaboost算法是“Adaptive Boosting”(自適應增強)的縮寫,由Yoav Freund和Robert Schapire在1995年提出,屬于一種迭代算法。算法通過合并多個“弱”分類器的輸出,將訓練數據樣本進行有效分類。Adaboost算法首先給出弱學習算法和數據樣本,在開始訓練時,對每組數據樣本賦予相同的權重,通過弱學習算法運算T次后,將運算結果分類并調整權重分布。對于預測誤差大的樣本,賦予其更大的權重,在下一次迭代運算時,系統將更加關注這些樣本。在新的樣本分布下,對弱分類器再次進行訓練。經過T次反復迭代后,能夠得到T個弱分類器,把這T個弱分類器加權疊加,得到最終的強分類函數[11-13]。
2 Elman-Adaboost強預測器模型
Elman-Adaboost強預測器模型首先將Elman神經網絡作為弱預測器,用Elman神經網絡對數據樣本進行訓練、預測,并使用Adaboost算法優化多個基于Elman的弱預測器,從而組成強預測器。由此構造的Elman-Adaboost強預測器港口吞吐量預測模型如圖2。
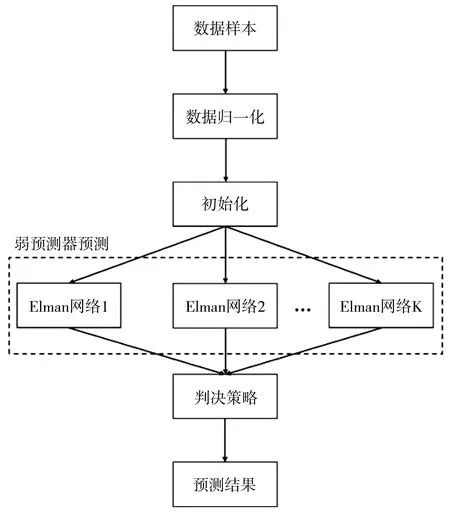
圖2 基于Elman-Adaboost的強預測器港口吞吐量預測模型
Elman-Adaboost強預測器的算法步驟如下:
1)選擇數據、處理數據
選擇原始的訓練數據,對數據進行歸一化處理。初始化測試數據的分布權值Dt(i)=1/m,根據數據樣本的輸入輸出維數,確定神經網絡的結構,初始化Elman神經網絡的權值和閾值。
2)弱預測器預測
訓練第t個弱預測器時,用訓練數據訓練Elman神經網絡并且預測訓練數據輸出,能得到預測序列g(t)的預測誤差之和et,計算如式(1):
et=∑iDi(i),i=1,2…,m。且(g(t)≠y)
(1)
式中:g(t)是預測分類結果;y是期望分類的結果。
3)計算預測序列的權重
根據預測序列g(t)的預測誤差et計算預測序列的權重at,如式(2):
(2)
4)調整測試數據權重
根據預測序列的權重at,設置下一輪訓練樣本的權重,如式(3):
(3)
式中:Bt是歸一化因子,目的在于使分布權值在權重比例不變的情況下和為1,即:
(4)
5)構建強預測函數
訓練T輪后可以得到T個弱預測函數f(gt,at),組合得到強預測函數h(x),如式(5):
(5)
3 寧波-舟山港貨物吞吐量預測
3.1 預測模型建立
寧波-舟山港是中國第一大港口,是國內重要的鐵礦石中轉、液體化工儲運基地和原油轉運基地、及華東地區重要的煤炭、糧食儲運基地。2017年,港口年貨物吞吐量完成10.1×108t,是突破10×108t的超級大港。筆者以中國港口網數據為數據來源,收集整理2011年1月—2017年8月共計80 m的寧波-舟山港港口月吞吐量數據,數據按照時間順序排列。在進行Elman神經網絡的訓練時,筆者使用連續6 m的吞吐量數據,遞歸預測下一個月的數據方式構建樣本數據,即神經網絡的輸入節點數為6,輸出節點數為1。以2015年的寧波—舟山港貨物月吞吐量為例,原始數據如表1,構建形成的數據樣本如表2。經過上述方法處理,可將原始的80 m的數據轉換為74組數據樣本。將前69組數據作為Elman-Adaboost強預測器預測模型的訓練數據,后6組(2017年4月~8月)的數據作為Elman-Adaboost強預測器預測模型的測試數據。為更好適應該模型,所有數據在輸入Elman神經網絡前,均進行數據歸一化處理。

表1 2015年寧波-舟山港的貨物月吞吐量

表2 樣本數據示例
使用MATLAB進行Elman-Adaboost強預測器預測模型仿真,根據港口吞吐量數據特點,確定模型隱層節點的個數和弱預測器的個數。經過多次試驗,最終采用的Elman神經網絡結構為6-7-1,即Elman神經網絡的輸入層節點數為6個,輸出層節點數為1個,隱含層節點數為7個;訓練生成的Elman弱預測器的數目設置為10個,即Adaboost算法中弱預測器數目K=10。
3.2 評價指標的選取
筆者選取絕對百分比誤差最大值tMAX、平均絕對誤差tMAE、平均絕對百分比誤差tMAPE以及均方根誤差tRMSE,作為檢驗模型預測結果的標準[14-15]:
(6)
(7)
(8)
(9)
式中:dfi是Elman-Adaboost強預測器的預測值;dmi是港口吞吐量的真實值。
上述4項評價指標值越小,則預測的精度越高。
3.3 預測結果的比較及分析
為驗證Elman-Adaboost強預測器預測模型的有效性,將預測結果與相同構建方式下的單一BP神經網絡預測模型、單一Elman神經網絡預測模型以及BP-Adaboost強預測器預測模型的預測結果進行比較分析。
首先用整理好的訓練數據(69組)分別對以上4種預測模型進行訓練,然后用訓練好的預測模型對寧波—舟山港2017年4~8月的港口貨物吞吐量進行預測,將各模型預測結果與真實值進行誤差分析。4種預測模型得到的預測結果如圖3,各預測模型對測試數據的預測結果的誤差評價指標如表3、表4。

圖3 4種預測模型的預測值與真實值

表3 4種預測模型的港口吞吐量預測值與預測誤差

表4 四種預測模型的誤差評價指標值
由表3和表4的各預測模型的預測結果及評價指標分析比較可知,使用Elman-Adaboost強預測器預測模型、BP-Adaboost強預測器預測模型、Elman神經網絡預測模型、BP神經網絡預測模型進行港口貨物吞吐量的預測,均可以實現不同程度的預測效果。相比較而言,Elman-Adaboost模型的預測值的平均絕對誤差、平均絕對百分比誤差以及均方根誤差最小,預測值與真實值的數據擬合程度更高,預測結果的相對誤差最大值1.91%,最小值0.06%,可以將預測誤差控制在2%以下,預測模型具有更好的精度。
4 結 語
1)使用Adaboost算法優化Elman神經網絡構建Elman-Adaboost強預測器預測模型,并應用于港口貨物吞吐量的預測,預測值的擬合效果好,預測精度高。
2)通過Elman-Adaboost強預測器模型與BP、Elman、BP-Adaboost模型的預測結果的百分比誤差最大值、平均絕對誤差、平均百分比絕對誤差以及均方根誤差的對比,發現Elman-Adaboost強預測器模型的預測結果的相對誤差最大值1.91%,最小值0.06%,可以將預測誤差控制在2%以下,預測模型具有更好的精度。
3)港口實際生產作業及發展規劃中,使用該模型預測時,應結合各港口吞吐量數據的實際情況對模型進行訓練,以達到更好的預測效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
金橋(2022年10期)2022-10-11 03:29:46
金橋(2022年10期)2022-10-11 03:29:22
機電設備(2022年2期)2022-06-15 03:20:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代工人(2019年20期)2019-12-13 08:26:11
水上消防(2018年4期)2018-09-18 01:49:38
海洋世界(2016年12期)2017-01-03 11:33:00
光學精密工程(2016年6期)2016-11-07 09:07:19
