基于LSTM 的CPU 資源使用情況預測算法的研究
2021-05-12 02:59:44樊文杰
電子設計工程 2021年8期
樊文杰,陳 嵐,張 賀
(1.中國科學院大學,北京 100049;2.中國科學院微電子研究所,北京 100029;3.三維及納米集成電路設計自動化技術北京市重點實驗室,北京 100029)
資源預測對于資源監控、資源分配等方面都具有重要意義[1]。為了高效、合理地利用資源,需要對資源進行準確預測,這樣能夠更好地提高資源利用率,為資源調度做準備。以前的研究表明,CPU 資源使用情況有一定的時間關聯性,也就是說基于歷史數據的CPU 資源預測可行。基于時間序列的預測法在此類場景中應用較多,常見的模型有自回歸滑動平均模型(ARMA)[2]。該模型在時間序列[3]預測方面有一定不足。由于該模型捕捉數據的線性關系,在時間序列變化不穩定、時間跨度較長時,自回歸滑動平均模型因其主要依賴歷史平均值,預測值總是停留在歷史范圍內,導致預測效果不佳。因此,自回歸滑動平均模型往往用于短期預測,無法進行中長期預測[4]。基于以上問題,考慮到CPU 資源使用情況受多種因素影響,且具有非平穩、不規則的特性[5],該文嘗試使用機器學習算法長短期記憶網絡來進行CPU預測。長短期記憶網絡是一種特殊的RNN[6],能夠學習長期依賴性,可以通過非線性計算更好地提取出CPU 資源使用特征,克服CPU 資源不規則的特性。
該文主要工作包括使用長短期記憶網絡(LSTM)算法對CPU 資源使用情況進行預測,并對算法進行了優化,使用非飽和激活函數ReLU 函數[7]代替飽和激活函數Tanh 函數[8],可以加快模型的收斂速度。最后,通過實驗結果表明,相比自回歸滑動平均模型(ARMA)、循環神經網絡(RNN)算法和傳統LSTM 算法,優化的LSTM 算法在CPU 使用率預測上表現出較好的效果,預測的準確率有所提高。
1 長短期記憶網絡(LSTM)模型構建及訓練
1.1 CPU資源使用情況數據收集及處理
1)數據采集
使用shell 腳本,從服務器中自動收集CPU 資源使用情況的數據,數據內容為CPU 資源使用率,每隔5 s 收集一次,共收集3 萬條數據。
2)數據預處理
考慮到CPU 數據不穩定,且容易存在噪聲點,采用滑動平均法[9]對數據做平滑處理。此外為了方便模型訓練及準確性評價,對數據進行壓縮和平移,完成歸一化處理[10]。
1.2 LSTM模型構建
LSTM 模型對RNN 模型[11]進行了改進,用cell 門開關替換了RNN 的單個循環結構,這樣能夠更加精確地處理時間序列的長期依賴關系[12]。CPU 使用情況隨時間的變動屬于時間序列類型,可將各個時刻CPU 的狀態作為LSTM 模型的輸入,進行CPU 使用情況預測分析。
LSTM 模型的具體構建過程如下所示:
步驟1:遺忘門的輸入由預處理之后的數據xt與前一時刻隱藏層輸出ht-1決定,輸出為ft。表達式如下:
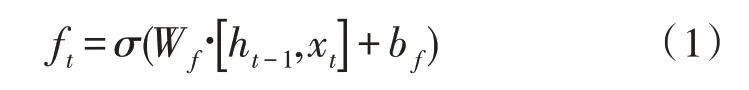
Wf為遺忘門權重;bf為遺忘門偏置;σ 為Sigmoid 激活函數。
遺忘門訓練的結果是Wf的權重,此外,上一時刻的輸出和當前時刻的輸入分別為一個向量,通過連接操作將兩者連接成為長向量。遺忘門控制模型從cell 狀態丟棄信息,因為激活函數輸出一個小于1的值,這就意味著對每個維度值進行衰減。
步驟2:預處理之后的數據xt與前一時刻隱藏層輸出ht-1經過單元的輸入門,然后更新參數,參數更新由Sigmoid 函數來控制,之后再結合ReLU 層產生一個新的候選狀態向量,輸入門的表達式定義為it,Ct是由和it共同創建的新的狀態向量,相關表達式如下:

Wi為輸入門的權重;Wc為輸入單元狀態權重矩陣;bi為輸入門偏置項,bc為輸入單元狀態偏置項,ReLU 為激活函數。
步驟3:隱藏層單元輸出值ht由輸出門ot和單元狀態值Ct計算后得出,表達式如下:

ot為輸出門;Wo為權重矩陣;bo為偏置項。
步驟4:根據ht計算出模型的輸出值,進而構造模型的均方誤差,最后通過Adam 算法[13]最小化目標函數,并不斷更新模型參數,使得網絡達到最優。
步驟5:通過以上步驟訓練完成后,將要預測的時間段作為模型的輸入,則模型的輸出值即為后一時間段CPU 的預測值。
1.3 激活函數的選擇
在深度學習中,常見的飽和激活函數[14]包括Sigmoid 函數和雙曲正切函數Tanh 函數。其函數和導數曲線如圖1 和圖2 所示。
從圖中可看出,Sigmoid、Tanh 兩個激活函數的導數值在正負飽和區接近于0值,即梯度趨近于0,當梯度消失[15]時,模型學習速度變慢,進而減緩收斂速度[16]。
基于以上兩種激活函數存在的問題,該文在激活函數方面采用非飽和激活函數ReLU 函數。ReLU函數的表達式為:

圖1 Sigmoid函數和導數曲線

圖2 Tanh函數和導數曲線

其函數圖像如圖3 所示。

圖3 ReLU函數曲線
由圖像和表達式可知,ReLU 激活函數在正區間的梯度為常數,不會產生梯度消失現象,從而可以加快模型的學習速度和收斂速度,縮短訓練周期。
2 長短期記憶網絡(LSTM)預測流程
LSTM 算法預測包含6 個步驟,主要流程如圖4所示。

圖4 預測流程圖
1)數據采集:收集服務器上的CPU 資源數據。
2)數據預處理:使用滑動平均法對數據做平滑處理,并且對數據做歸一化處理。
3)模型構建:選擇合適的隱藏神經元數和層數,選擇激活函數、配置訓練集與預測集占比等,完成LSTM 模型構建[17]。
4)訓練模型:選用大量數據進行模型訓練。
5)優化參數:根據各訓練模型的預測表現,優化模型各參數[18]。
6)預測模型:通過最優參數生成預測模型,后續用于對資源進行預測。
3 實驗結果分析
為了分析LSTM 模型在各激活函數下對CPU 預測的準確率和性能,將采集的3 萬條CPU 使用率數據分為30 組,每組各1 000 條數據,每條數據采集間隔5 s。選用Sigmoid、Tanh、ReLU 3 個激活函數進行實驗。同時,使用自回歸滑動平均模型(ARMA)、循環神經網絡(RNN)算法做參照對比。
首先,評估各激活函數預測準確性。在評價各組模型表現時,采用平均相對誤差(MRE)進行對比。第n組數據平均相對誤差(MRE)的公式為:
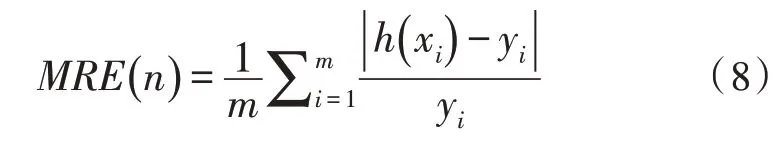
其中,h(xi)為預測值,yi為真實值,m為測試集數據長度。
在評估整體函數表現時,使用30 組預測結果平均相對誤差的均值進行對比分析。

訓練集與測試集比例分別為7∶3、8∶2、9∶1 時,ARMA、RNN 和LSTM 各激活函數預測的平均相對誤差的均值()如表1 所示。
表1 各模型不同訓練集占比平均相對誤差的均值()

表1 各模型不同訓練集占比平均相對誤差的均值()
從表中可見,ReLU 激活函數平均相對誤差較其他算法表現好。其中Tanh 與ReLU 3 種訓練集與預測集比例的平均分別為3.47%、2.99%,可知ReLU 激活函數的平均相對誤差相比傳統LSTM 算法中Tanh 激活函數下降13.75%。
考慮CPU 預測場景的實際意義,對不同函數相對誤差的最大值進行分析。不同訓練集和測試集比例下各激活函數預測的相對誤差的最大值如表2 所示,可以看到30 組數據中,ReLU 函數不僅在準確率的穩定性上表現優異,在極端預測場景,表現也是最佳。

表2 各模型不同訓練集占比下相對誤差的最大值
除訓練集占比影響外,分析各模型在整體數據集長度不同時,平均相對誤差的均值()情況,統計數據如表3 所示。
表3 各模型不同數據集長度平均相對誤差的均值()

表3 各模型不同數據集長度平均相對誤差的均值()
從表中可知,各算法預測效果差距隨數據集長度變化不大,即ReLU 在各時間長度下均為最優,其次為Tanh,最差為ARMA。各算法隨著數據集時長增加,預測誤差有一定上升,這在一定程度上體現出測試數據中,CPU 使用情況與較長時間前使用情況關聯性較弱。在實際應用時,需根據具體預測場景選取時間長度。
其次,評估各激活函數訓練速度。此處選用各激活函數平均相對誤差均值最小的訓練預測占比9∶1進行評估,使用各激活函數分別訓練10 輪、30 輪、50 輪、70 輪,數據集為1 000 個點(5 s 采集一個數據,1 000 個點共計83 min)。記錄完成訓練所需時間,如表4 所示。

表4 各激活函數訓練時長對比表
從上表可以看出各激活函數在同樣訓練輪數下,速度沒有顯著差異。分析激活函數收斂速度,隨著訓練輪數的增加,各激活函數歸一化均方誤差變化見圖5,選取歸一化后均方誤差小于0.005 且訓練輪次變動比例小于5%作為收斂點,ReLU 激活函數、Tanh 激活函數、Sigmoid 激活函數分別在24 輪、30 輪、50輪收斂。計算可得,ReLU收斂速度比Tanh、Sigmoid分別提高20%、52%。隨著訓練輪數增加,ReLU 激活函數收斂速度最快。
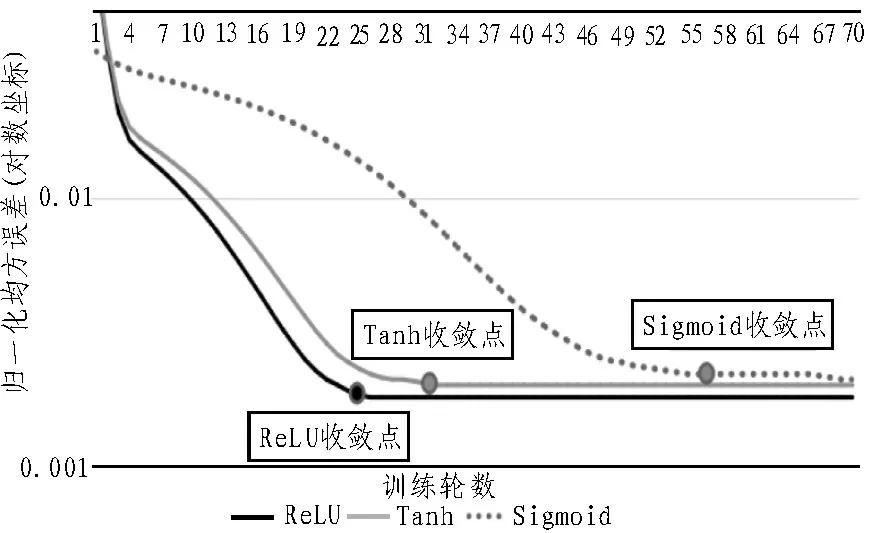
圖5 3個函數歸一化均方誤差對比圖
接下來,評估各激活函數預測CPU 不同變動場景的效果。選取預測誤差最小和預測誤差最大的兩組數據進行預測效果對比。首先,對兩組數據進行平穩性檢驗。
序列的平穩性檢驗常用的一種方法是圖檢驗法,通過繪制序列時序圖和序列自相關圖,針對圖形展現的特征判定平穩性。其中,自相關圖反映了自相關系數隨延遲期數k的變化趨勢。自相關系數(Autocorrelation Coefficient)的定義如下:

平穩序列具有短期相關性。通過自相關圖的變化趨勢可以看出,當延遲期數k增加時,自相關系數快速震蕩衰減或單調衰減接近0 的是平穩序列,緩慢衰減的則是非平穩序列。對兩組數據進行自相關圖繪制,分別得到圖6 與圖7,可以看出,第一組數據的自相關系數下降至0 的速度較第二組數據更快,即第一組數據的平穩性高于第二組數據。

圖6 第一組數據自相關圖

圖7 第二組數據自相關圖
對兩組數據在不同激活函數下的預測效果進行對比。
第一組對比:其自相關圖見圖6,其預測效果如圖8 所示。該場景下,CPU 使用率變化不大,各激活函數預測效果差距不大。可見在此場景下,ReLU 激活函數預測優勢并不顯著。
第二組對比:其自相關圖見圖7,其預測效果如圖9 所示。該場景下,CPU 使用率出現大幅上升,ReLU 預測效果顯著優于其他激活函數。實際運維監控中,CPU 使用率上升到90%等閾值是關鍵監控指標,但此場景其他激活函數預測效果較差,無法起到提前預警作用。

圖8 第一組數據CPU預測效果對比
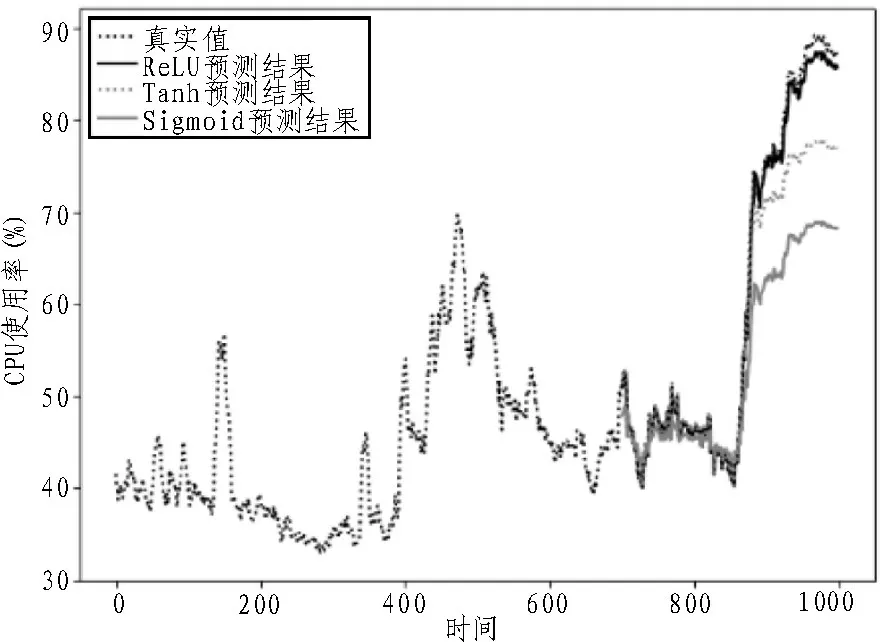
圖9 第二組數據CPU預測效果對比
總的來說,在CPU 運行相對平穩時,ReLU 激活函數優勢不明顯,但在CPU 突變場景下,其預測效果明顯優于Tanh、Sigmoid。在實際監控場景,使用ReLU 進行CPU 使用率預測有很大的實踐意義。同時,在訓練集占比方面,如表1 所示,ReLU 函數在訓練集與預測集比例為9∶1 時表現最佳,且從圖5 可見,ReLU 激活函數在30 輪基本完成收斂,可作為模型訓練參考比例與輪數。在該文訓練CPU 使用率的30 組數據中,ReLU 激活函數未出現不收斂數據集。
4 結束語
提出了一種基于長短期記憶網絡(LSTM)的CPU資源使用情況預測算法,該算法優化了傳統LSTM 算法,選用非飽和激活函數ReLU 函數替換飽和激活函數Tanh 函數,提高模型收斂速度。經實驗對比,優化的LSTM算法比自回歸滑動平均模型(ARMA)、循環神經網絡(RNN)算法和傳統LSTM 算法預測準確率更高,為實際CPU預測場景提供了一個較好的解決方案。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
