小數據在精準扶貧中的應用研究
2021-05-10 01:52:50孔艷春蘇為斌陳國平徐子珺楊雪瓊李懿航
昆明冶金高等專科學校學報 2021年1期
關鍵詞:分類
孔艷春,蘇為斌,陳國平,徐子珺,楊雪瓊,李懿航
(1.昆明冶金高等專科學校 a.建筑工程學院;b.測繪學院;c.電氣與機械學院;d.商學院;e.后勤服務中心, 云南 昆明 650033; 2.云南工商學院智能科學與工程學院,云南 昆明 651701)
近年來,大數據助力脫貧成為了研究的熱點,然而,大數據具有“全局思維、混雜相關”的性質,不能很好地適用于具有“隨機個體、因果關聯”的扶貧小數據分析。大數據在扶貧領域的應用存在諸多問題:大數據一般以網絡為基礎,受限于貧困地區客觀條件,比如智能手機的使用率、網絡普及率低就很難實現“全數據”采集覆蓋;大數據并非大家都可以使用,比如涉及個人的隱私、機密等就不宜廣泛使用;大數據無論有多全面,也只能記錄人的片面行為,無法確切描述人的思維;此外在技術實現上,由于大數據重“相關”輕“因果”,導致難以全面分析農戶致貧原因。為了從源頭根除貧困,眾多學者都認識到“扶貧必先智志雙扶”,人的價值觀才是脫貧的最終根源。小數據從個體出發,通過統計個人信息,觀察行為特征,挖掘分析數據,提高扶貧的“精準”度。該方法能夠有效檢測扶貧效果,改進扶貧工作方法。
1 脫貧攻堅小數據的由來
在大數據提出之前,數據本無大小之分。隨著大數據的火熱,越來越多的學者意識到小數據具有不可替代的價值。學術界通常把Estrin[1]于2014 年通過觀察記錄其父親去世前幾個月的行為數據,認定為小數據研究的開端。事實上關于小數據的應用先例早已有之:“星星之火,可以燎原”是毛澤東同志于1927年革命失敗后,透過現象看本質,應用唯物辯證法,科學分析國內政治形勢和敵我力量作出的正確激勵;“關鍵少數”是習近平同志于 2015 年兩會期間提出的最新熱詞,是抓好黨員思想建設和制度保障的“精準良方”。縱觀歷史,小數據總能指導人們在關鍵時刻作出決策,解決棘手問題。
1.1 小數據的國內外研究現狀
小數據的顯著特征在于對單個個體或小團體范圍內人的行為的全數據記錄,它由多個時間標簽系列的小樣本組成。在國外,Augustin[2]認為,一個高質量的小樣本數據要比低質量的大樣本數據更具決策價值;O'Brien[3]認為,小數據能夠優化大數據,實現客觀報告行為與自我報告態度的同步;Robertson[4]指出,通過對個人活動中心和地理社會數據的統計分析,可以驗證小數據高質量樣本的“精準”特性。在國內,陳廉芳[5]指出,小數據是個體用戶的“全”數據,具有大數據無法替代的作用;孫紅蕾[6]認為,小數據將為數字文化治理帶來新的機遇。
1.2 精準扶貧鄉村振興與小數據的關系
習近平總書記講到,扶貧工作不能搞大水漫灌,務必要做到“六個精準”,即:因村派人精準、扶持對象精準、項目安排精準、資金使用精準、措施到位精準、脫貧成效精準。扶貧不是養懶漢,如果不能有效挖掘單個個體或小團體范圍內的小數據,那么這些具體且特定的數據或有可能因大數據的分析方法而泛化,導致真正需要幫扶的人沒有得到有效幫助,那些“等、靠、要”的懶漢則一次次地獲得政策傾斜。針對該類問題,安素霞[7]指出,應當通過開展社會工作,解決貧困戶過度依賴扶貧收益不愿意脫貧的問題;姚展鵬[8]認為,基層組織應當激勵幫扶者改進幫扶方式、提升扶志效果;沈霞[9]提出,教育應當成為精準扶貧的重要保障。顯然,要實現精準扶貧助力鄉村振興,必須長期做好基于小數據的社會學調查統計工作,建立科學的小數據理論分析體系,提高精準識別率。
2 脫貧攻堅小數據理論體系構建
很多學者認為大數據與小數據是矛盾關系,但事實上,它們之間存在著互補與交叉。如圖1所示,學術界通常把數據間的關系定義為“因果”和“相關”。通過“獲取數據樣本→聚類→測定類間距離→獲得相關系數”的方法屬于傳統大數據方法;通過“個體行為的調查研究→實驗論證→得出數據因果關系”的方法屬于小數據方法。顯然在扶貧工作中對數據的界定與劃分是本文研究的首要內容,劃分方法如下:
1)若數據與數據間具有純相關性,則送入大數據系統,不在本項目研究范疇;
2)若數據與數據間既有相關關系,又有因果關系,則采用樸素貝葉斯機器學習算法,構建混淆矩陣,分析準確率;
3)若數據與數據間屬純因果關系,則采用確定性演繹推理方法,對駐村工作中統計的具有數值屬性和非數值屬性的數據進行實驗,驗證理論可行性。
2.1 小數據的確定性推理方法
在脫貧攻堅小數據的分析過程中,依靠確定性推理能夠實現問題的自動求解。“知識表示”是實現確定性推理的前提條件。所謂脫貧攻堅小數據的“知識”是對國家政策規定解讀和長期的駐村扶貧工作中積累的認識和經驗,而“知識表示”是對這一類知識的進一步模型化,構建謂詞邏輯,形成產生式和框架表示規則[11]。“推理”是對這些知識規則,按照某種策略求解的一般過程,如表1所示。

圖1 大數據與小數據的界定與劃分Fig.1 Definition and division of big data and small data

表1 推理方式及分類Tab.1 Reasoning mode and classification
在推理的方向上,已知國家制訂的貧困線標準,該標準為已知的知識庫,也稱為大前提;若有一農戶收入水平在該標準之下,則由該農戶數據構造的謂詞邏輯稱為小前提;顯然得到的結論必然是該農戶屬于貧困戶。這種由一般到個別的推理也稱正向推理,是從已知實事出發的結論構建。
與之向反,若已知部分農戶數據及他們向工作組反映的情況,但又找不到國家或地方相關的政策依據,那么就應當進行數據歸納,然后以某個假設目標作為出發點,尋找支持該假設的證據。這種由個別到一般的推理過程也稱為逆向推理,獲得的結論有利于向農戶提供解釋。
2.2 小數據的樸素貝葉斯分析方法
樸素貝葉斯(Naive Bayes Classifier, NBC)是基于貝葉斯定理特征條件獨立假設的分類方法。具有所需估計參數少,對缺失數據不敏感等特點。結合概率統計,既可避免先驗的主觀偏見,又可避免單獨使用樣本信息的過擬合現象[10]。駐村扶貧工作統計的原始小數據往往是時間離散、格式不統一的excel表格或word文檔。為了向上級呈現更加精練的數據信息,工作人員一般通過鄉鎮一級統一指揮,把整理后的數據錄入國辦數據庫系統,存在錄入失誤和人為主觀更改等問題。對駐村工作人員的原始數據進行上下文文本的樸素貝葉斯分類,能夠在一定程度上規避這些問題。
駐村扶貧統計數據屬于定性的樣本特征向量,把這些數據代入樸素貝葉斯分類器進行訓練,由此估計每種致貧因素類型的識別概率。貝葉斯分類器提供了分類程序的基本概率模型,例如統計辨別分析貝葉斯定理估計概率公式為:
(1)
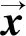
(2)
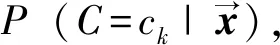
(3)
公式(3)是基于小數據最終分類的樸素貝葉斯概率估計公式,其特點是在獲得一個新的貧困戶特征樣本x時可以估計出該貧困戶能否脫貧的概率。為了盡量降低錯誤的估計數量,應當盡可能地獲得運算結果的最大值,通常取公式(3)分子的最大值來進行分類決策。
3 脫貧攻堅小數據的確定性知識表示
為了奠定小數據推理基礎,需要把扶貧工作中駐村工作隊與村民間的談話和各級會議記錄等形成的自然語言轉換為謂詞邏輯。
3.1 確定性知識表示的謂詞規則
謂詞是對主語的陳述或說明,指出“做什么”“是什么”或“怎么樣”,是條件表達式求值返回真或假的過程。表2以小壩村為例解析了扶貧記錄的謂詞表示。

表2 確定性知識表示謂詞公式規則
表2第一列中均出現了謂詞關鍵字“是”,然而卻有不同的含義。雖然人類可以輕易理解這種自然語言,但是計算機很難做到正確分析,會錯誤地把 “張老二”認定隸屬于“張三”,錯誤地把時間“2017年”認定為“貧困戶”。顯然,研究人工智能謂詞公式錄入規則可以解決自然語言在計算機中的知識表示能力不足的問題,利于構建確定性扶貧小數據知識體系。
3.2 確定性知識表示的量詞規則
扶貧小數據確定性推理的第二項重要任務是運用“量詞”實現謂詞公式的建立。量詞分為2種,如表3所示。

表3 量詞規則
需要注意的是,表3中的2個例子均有泛化屬性,比如:例1泛化“小壩村的路”為x;例2泛化“魯老三”為x。泛化的充要條件是具備“個別”與“一般”的縮放條件。
3.3 確定性知識表示的連詞規則
“連詞”是對已知事實即前提P與結論Q之間的關系建立,具有“否定”“合取”“析取”“蘊含”“等價”5種連接關系。如表4所示,連接詞與自然語言具有相應的對照關系。

表4 連接詞與自然語言對照Tab.4 Conjunctions and natural language
國家對脫貧的要求,必須做到“兩不愁,三保障”。對于“吃”“穿”“教育”“醫療”“住房”,若只考慮“達到”和“未達到”2個層面。假如任取一戶,存在5項中的任1項未達到,將導致全村無法實現脫貧,可描述謂詞公式為:
?(x)?(y){吃(x)∨穿(x)∨教育(x)∨醫療(x) ∨住房(x)→達到(y)}
3.4 子句集的劃分規則
小數據確定性推理的關鍵是把謂詞公式化為子句集的過程。該過程共分為9個步驟,謂詞公式不可滿足的充要條件是其子句集不可滿足。獲得子句集的目的是為了使用魯賓遜歸結原理(消解原理)的基本思想,建立規則、事實、求證三者之間歸結反演邏輯[10]。任一謂詞公式通過九步法可以化成一個子句集,如圖2所示,依次變換即可得到子句集。
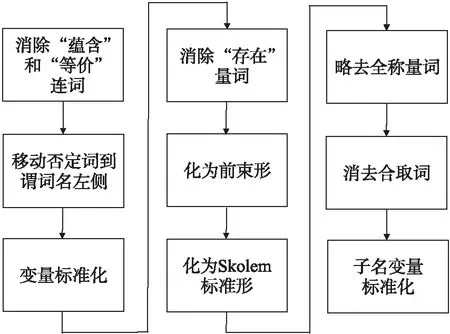
圖2 子句集劃分步驟Fig.2 Clause set transformation
子句集的劃分是對知識的拆解,通過魯賓遜歸結反演方法[11],可以從脫貧攻堅小數據集中抽取知識實現針對特定問題的求證。顯然通過長期觀察并建立確定性扶貧小數據集,該方法能夠正確表達小數據確定性推理過程,提供決策輔助脫貧攻堅和鄉村振興。
4 脫貧攻堅小數據的樸素貝葉斯分類
基于小數據開展樸素貝葉斯算法可以帶來更高的分類精準性。由于地區之間的語言、民族、氣候、產業結構、習俗等存在差異,導致很難找到一個合適的訓練數據集來支撐這種因地區差異而存在的樸素貝葉斯分類算法。本文以小壩村為例,以事實數據作為依據,科學設定統計表格,從而求出樸素貝葉斯公式的先驗概率、似然概率和邊際概率。通過把主動訪談與事件觸發相結合的時間系列記錄數據代入樸素貝葉斯公式,求解后驗,更新先驗,不斷獲得特定貧困戶的趨勢曲線觀察。
在脫貧攻堅工作中,往往以戶為單位判斷是否為貧困戶。在該分類過程中,根據以往的經驗,工作人員通常會將收入、民族、健康狀況、受教育程度等因素作為“經驗”訓練貧困戶判斷的模型要素。這一過程往往需要3個流程:
第一階段:準備階段。對收入、戶籍人數、健康狀況等特征屬性進行劃分。
第二階段:訓練階段。該階段將計算小壩村調查數據在每個類別的訓練樣本中的出現頻率,并劃分特征屬性得到每個類別的條件概率。
第三階段:應用階段。使用分類器對新數據分類,輸入分類器和新數據,輸出新數據的分類結果。
4.1 樸素貝葉斯訓練數據準備
本文用于樸素貝葉斯分類實驗的小數據來自小壩村截至2019年的219戶貧困戶監測數據,如表5所示。該表列出了用于訓練的特征屬性樣本,其中一部分具有數值屬性,比如收入;一部分為非數值屬性,比如文化程度。實驗的目的是對這些具有混合屬性的數據設計基于小數據理論的脫貧攻堅樸素貝葉斯分類器。為了保護貧困戶隱私,表中姓名進行了加*替換。

表5 樸素貝葉斯分類器訓練樣本表
表5訓練樣本列出了2014—2019年每戶的人均年收入數據,最后一列“脫貧評估”是人工統計后給出的綜合決策。表格的第一和第二列對最后一列的脫貧評估不會造成影響,其余列均是綜合評估的特征指標。“人數”列表示該戶共有多少人口,人數較多的戶口,其人均收入水平也會較低。設計該表的初衷在于發現脫貧與家庭人口數、民族、文化程度、健康及技能之間的關系。表中“#N/A”表示缺失,可計算一個平均值進行替換,否則會影響識別正確率。對于該表,首先需要進行數據預處理,然后使用開源數據分析工具實現樸素貝葉斯算法的性能分析。
WEKA是一款開源的機器學習及數據挖掘軟件[13],它把需要訓練和推理的數據分成屬性和實例2個部分。一般情況下,對應了表格的列對應屬性,行則對應實例,通過把表格轉換為ARFF文件從而可以依靠該工具實現樸素貝葉斯分析。由于WEKA不支持中文,首先需要把表5轉換為漢語拼音表格,然后去除序號、戶名2列對最終決策毫無影響的屬性。通常這種數據預處理過程會占用大量的工作時間,本文通過Python調用excel庫,把預處理的代碼發布于CSDN[14],可通過調用該代碼重現。
4.2 基于WEKA工具交叉驗證數據集
為了防止訓練過程中的過擬合問題,通常將數據分為訓練和測試集。由于測試集不參與訓練,用于模型評估,這樣就會在小數據集上浪費了這部分數據,無法使模型達到最優。采用K-Fold 交叉驗證能夠很好地解決這個問題,進而利用全部數據構建模型。交叉驗證又稱循環驗證。它將原始數據分成K組,然后對每個子集數據做一次驗證,剩下的K-1組子集數據用作訓練,即可得到K個模型。最后對這K個模型驗證評估結果。交叉驗證能夠盡可能接近模型在測試集上的表現優化模型。
針對表5的219個實例,應用WEKA選擇樸素貝葉斯分類器,設定10折交叉驗證可以得到如下數據:

=== Stratified cross-validation ====== Summary ===Correctly Classified Instances17278.5388%Incorrectly Classified Instances4721.4612%Kappa statistic0.133Mean absolute error0.1332Root mean squared error0.2875Relative absolute error100.6491%Root relative squared error113.8194%Total Number of Instances219
表5源自國辦系統的數據導出,從分類正確率來看,實例樣本還有很大的提升空間。Kappa指標與分類器正確率成正相關關系,值域為[-1,1]且越接近1越好,訓練數據集值為0.133,說明統計數據對最終脫貧評估分類具有良性的支撐作用;平均絕對誤差MAE為0.133 2,均方根誤差RMSE為0.287 5,也獲得了較好的數值范圍;然而,相對絕對誤差、根相對平方誤差的值則過于欠佳。這也恰恰說明了脫貧攻堅和鄉村振興需要科學的小數據分析方法促進數據精準率的提升。
基于WEKA樸素貝葉斯分類器的10折交叉驗證分析該數據集,還可得到如下的混淆矩陣:
可以看出主對角線上的樣本總計172例,錯誤的肯定得到的誤報數為24例,錯誤的否定得到的誤報數為23例。此外,基于WEKA的數據集分析還可得到準確率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲線、PR曲線等評價指標參數,能夠對模型效果進行科學評價,為后續算法改進提供思路。
4.3 運用訓練集推理貧困戶實現自動分類
運用WEKA雖然可以方便地獲取數據集分析的效果,但在特征參數選取與分類上往往存在矛盾。雖然通過數據預處理,可以一定程度上減少一些無用特征,比如序號、姓名等,但是一些特征與最終分類的權重往往不能均分,比如2014—2019年的收入。顯然2019年的收入權重更大,但也不是說2014—2018年的收入沒有多少用。若收入屬于平穩增長,則說明其返貧的概率要小得多。此外,“民族”特征屬性對最終分類顯然沒有因果關系,但卻又有一定的相關性,所以應當弱化其對最終分類的權重。基于此本文運用Python語言,以樸素貝葉斯分類公式(3)作為指導設計分類程序。
為了驗證算法的有效性,我校5名駐村工作人員隨機調查各抽取1戶數據形成測試集,如表6所示。

表6 樸素貝葉斯分類器測試樣本表Tab.6 Reasoning sample table of Naive Bayes Classifier
由于表6中序號、戶名兩列特征對最終推理結果分類不會產生任何貢獻,導致程序的運行分類結果為:
測試 1 是 監測戶
測試 2 是 監測戶
測試 3 是 監測戶
測試 4 是 監測戶
測試 5 是 監測戶
正確率: 0.4
顯然可以看出這是一個錯誤的分類。這是由于第一列和第二列特征的條件概率計算值為0造成的分類錯誤。為了消除這種分類錯誤,可以改進公式(3)如下:
(4)
公式(4)中aj的作用在于屏蔽、開啟、強化或弱化特征系列對分類結果造成的影響。若aj=0,則該特征對應概率為1,即表示屏蔽了該列特征對推理結果的影響;若aj=1,則該特征對應概率不變,既沒有被強化,也沒有被弱化,以本征的方式開啟了樸素貝葉斯的推理運算;若0
為了消除序號、戶名2列特征對最終推理的影響,代入aj數列,即a=[0,0,1,1,1,1,1,1,1,1,1,1,1],然后再運行程序。所得結果與表6的人工統計結果存在1項偏差。主要是“測試2”的人工統計結果為“監測戶”,而推理識別的結果為“脫貧戶”,使得正確率為0.8。代入aj數列,屏蔽序號、戶名可以得到程序運行的最終分類結果為:
測試1是未脫貧戶
測試 2是脫貧戶
測試 3是脫貧戶
測試 4是監測戶
測試 5是未脫貧戶
正確率: 0.8
事實上監測戶本來就被歸納為脫貧戶,由于兩者存在細微的數據差別,很難獲得正確的分類。駐村工作人員往往通過到戶走訪,根據自身的感覺最終劃分分類。由于測試集數據過少,識別正確率的實際值,可以通過增加測試數量獲得。最科學的方法就是從訓練集中隨機抽取1/3的數據進行10次交叉驗證[16]。也就是每次隨機抽取訓練集中的71條數據作為測試數據代入推理。同時位于最后一列,即2019年收入的權重相對較高,為了強化其作用,設定系數為0.8,即把aj數列設定為a=[0,0,1,1,1,1,1,1,1,1,1,1,0.8],得到了交叉驗證準確率統計表(表7)。

表7 交叉驗證準確率Tab.7 Cross validation accuracy
其算術平均準確率為0.893,這是一個相對較好的統計數據,表明該方法在脫貧攻堅小數據分析中性能優越。
當然這種方法適用于在特定區域、特定時間段的數據分析。因為地區收入水平、民風、民情、自然資源等存在差異,且認定標準會隨時間變化,駐村工作人員統計標準不一,所以訓練集并不能總是一成不變,應當使用最新數據更新訓練集確保正確識別率。
5 結 語
在國家的貧困治理工作中,實現精準幫扶始終是核心與關鍵。隨著大數據的火熱,小數據也以其獨特的魅力讓更多的學者注意到它。小數據側重個體、決定、精準、因果的特性為精準幫扶工作開創了新路徑。它針對個體,能夠從根源上提高扶貧的“精準”度,在當前扶貧攻堅的關鍵時期,具有幫助扶貧工作者作出決策、預防“大水漫灌”的風險、測試幫扶成效、降低返貧風險的科學價值。
本課題組常年駐村扶貧,深刻體會到通過采集、整理獲取小數據精準樣本的重要性。本文致力于構建脫貧攻堅小數據理論體系,應用機器學習、數據理論中的推理方法和相關性分析方法,對扶貧工作中的數據進行分析驗證,提出基于樸素貝葉斯的小數據分析方法。通過反復實踐,證明該方法計算簡便,能夠得出扶貧成效的準確率,具有推廣使用的價值。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
