基于PSO-NARX網絡的渦軸發動機穩態模型辨識
2021-05-06 07:47:40李本威錢仁軍滕懷亮
兵器裝備工程學報 2021年4期
董 慶,李本威,錢仁軍,滕懷亮,張 赟
(1.海軍裝備部駐蘇州地區軍事代表室, 江蘇 蘇州 215000;2.海軍航空大學 航空基礎學院, 山東 煙臺 264000)
航空發動機是一個復雜的非線性時變系統[1]。在發動機故障診斷[2]、性能分析與仿真及其控制規律設計[3]等多個領域,發動機模型都發揮著無可代替的作用。針對裝配某型渦軸發動機的直升機將在不同大氣環境(高原、高空及高低溫等)下進行飛行試驗的相關工作,為實現對發動機狀態的實時監控和對發動機穩態控制規律的進一步研究,建立精度和實時性均滿足實際要求的發動機穩態模型成為相關工作關鍵的一環。
目前,航空發動機模型建立的方法主要有兩種:一種是分析部件氣動特性、機械關系的解析法,另一種是系統辨識的方法。解析法通過假設、近似處理和大量的迭代運算來獲取發動機的性能數據,過程復雜。而系統辨識的方法無需了解發動機復雜的部件特性,只需足夠的發動機輸入輸出參數即可快速建立精度滿足要求的發動機模型。目前,基于數據驅動的模型辨識方法得到快速的發展,常用的辨識方法有最小二乘法[4]和子空間狀態辨識法[5]等。它們假設發動機是線性時不變系統,導致建立的發動機動態模型精度不能達到很好的效果。近幾年,人工神經網絡[6]。(artificial neural networks,ANN)、支持向量機[7](support vector machine,SVM)和極限學習機[8]。(extreme learning machine,ELM)等機器學習算法快速發展,具有了很好的非線性學習能力,很多人也將它們應用到航空發動機模型的建立。陳超等[9]利用RBF神經網絡對航空發動機起動模型進行辨識與仿真;王海濤等[10]利用稀疏最小支持向量機建立發動機動態過程模型。這些傳統的神經網絡存在初始參數選擇無依據、無反饋單元等各種問題。耿宏等[11]利用NARX網絡建立發動機參數動態辨識模型;Pogorelv等[12]利用動態神經網絡對雙軸燃氣輪機差分形式的非線性動態模型進行辨識,并應用于啟動控制。NARX網絡具有反饋延時單元,具有很好的動態特性,且對非線性動態系統具有良好的非線性逼近能力,效果明顯優于前饋神經網絡,但是網絡初始特性參數由隨機函數產生影響辨識模型精度。
粒子群優化算法(particle swarm optimization,PSO)穩定性好且具有較好的全局搜索和尋優能力,利用PSO對NARX網絡的初始參數進行尋優,使得NARX網絡取得更好的效果。文獻[13]驗證了粒子群優化算法的優越性。文獻[14]驗證了NARX網絡對非線性動態系統具有良好的非線性逼近能力。
針對以上分析,本文以直升機飛參數據為驅動,結合提出的三點自適應判斷法從飛參數據中提取發動機穩態數據樣本,采用PSO-NARX方法對渦軸發動機穩態模型進行辨識。利用樣本之外架次的飛參數據對辨識模型的性能進行驗證并與其他不同辨識算法相比較。結果表明本文PSO-NARX方法對渦軸發動機穩態模型辨識的可行性與優越性,為后續在高原、高空及高低溫環境條件下進行飛行試驗的此型渦軸發動機狀態實時監控和控制規律的優化奠定基礎。同時,也為工廠對此型渦軸發動機即將開展的試車試驗提供相關支持。
1 基于PSO的NARX網絡原理
1.1 NARX網絡模型
英文縮寫詞NARX(nonlinear auto regressive with exogenous inputs model)的意思為有外部輸入的非線性自回歸模型,是線性外生輸入的自回歸(ARX)模型改進后在非線性情況下的應用。其通過添加延時單元使過去某些時刻的輸入、輸出成為模型的輸入,再利用多層感知器的非線性映射能力,來實現時間序列的動態預測[11]。NARX模型可由帶有外部輸入的非線性差分方程表示為
y(t+1)=f[y(t),y(t-1),…,y(t-k),
x(t),x(t-1),…,x(t-m)]
(1)
式中:f表示自變量的一個非線性函數 ;y(t-k)表示輸出參數相應時延為k的數值;x(t-m)表示輸入參數相應時延為m的數值;y(t+1)表示得到的下一時刻的輸出數值。NARX網絡模型見圖1。
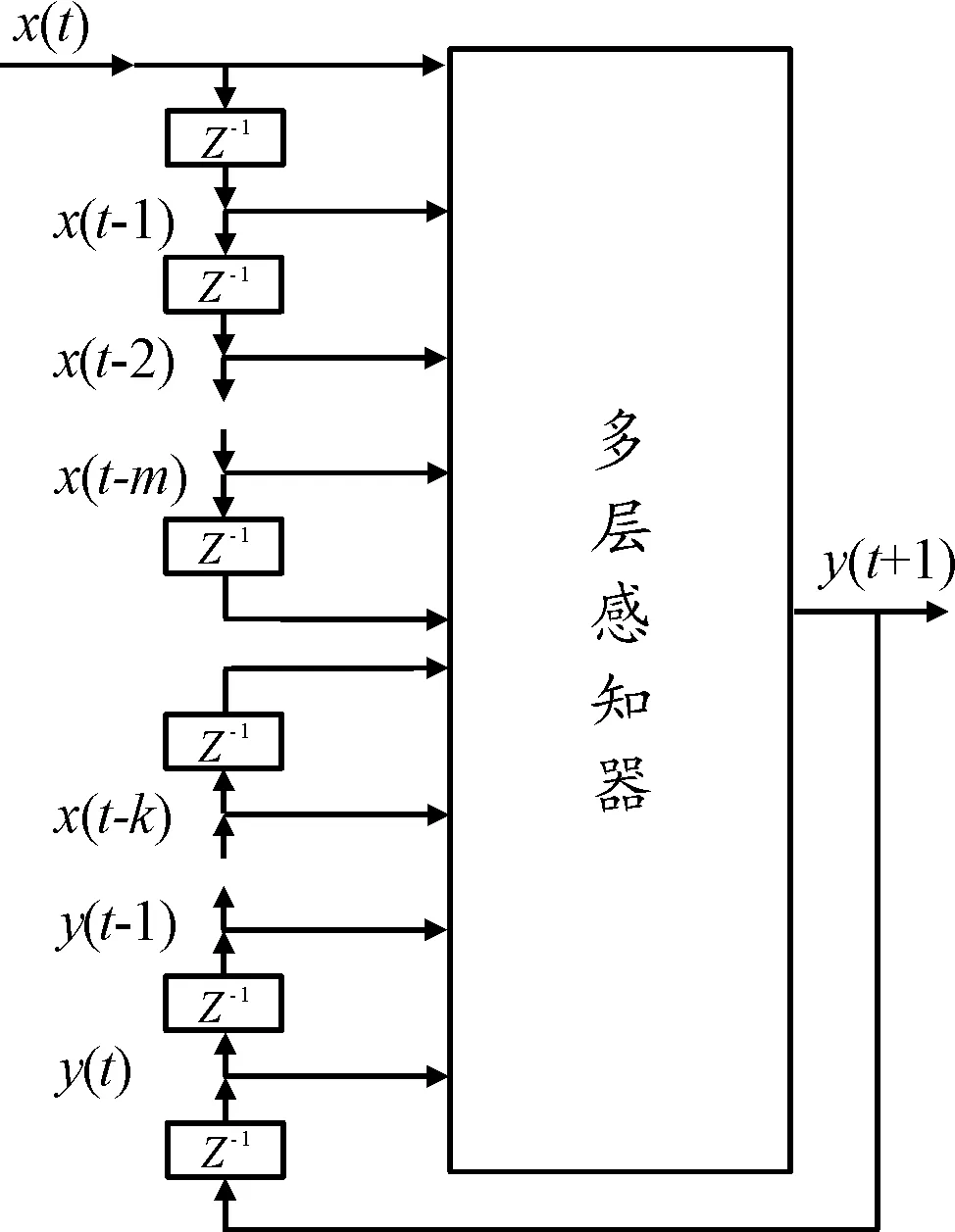
圖1 NARX網絡模型示意圖
某t時刻其第i個隱含層節點的輸出di(t)為
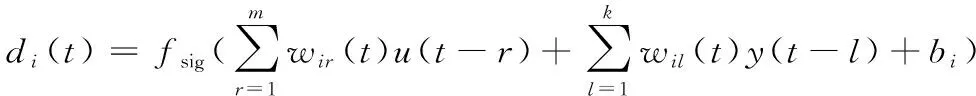
(2)
式中:fsig為隱層節點使用的雙曲線正切sigmoid函數;wir(t)、wil(t)為t時刻第i個隱層節點與輸入u(t-r)、輸出y(t-l)之間的權值;bi為第i個隱層節點的偏置。第j個輸出層節點輸出y(t)為
(3)
式中:wij(t)為t時刻第i個隱層節點到第j個輸出層節點的權值;Tj為第j個輸出層節點偏置;N為隱含層節點個數。
1.2 粒子群優化算法(Particle Swarm Optimization)
粒子群優化算法屬于進化算法的一種,源于對鳥群捕食的行為研究。該算法從隨機解出發,通過迭代找到最優解,通過適應度來評價解的品質,并通過追隨當前搜索到的最優值來尋找全局最優[16-17]。
每個粒子都有位置xi和速度vi兩個屬性,在每次的迭代中,粒子通過跟蹤個體極值和全局極值來更新自己。假設在一個D維的目標搜索空間中,即每個粒子(解)都是一個D維的向量,粒子群由N個粒子構成,則其中第i個粒子位置可以表示為
xi=(xi1,xi2,…,xiD),i=1,2,…,N
第i個粒子的速度也是一個D維的向量,記為
vi=(vi1,vi2,…,viD),i=1,2,…,N
并設定第i個粒子迄今為止搜索到的最優位置為個體極值,記為pi,而整個粒子群迄今為止搜索到的最優位置為全局極值,記為pg。同樣,pi、pg均為D維向量。在找到這兩個最優值后,粒子通過下面的公式(4)來更新自己的速度和位置。
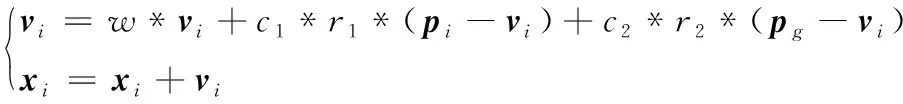
(4)
式中:c1、c2為慣性因子和學習因子,也稱加速常數,反映粒子間信息交換的強度,通常取c1=c2=2,r1、r2為[0,1]范圍內的均勻隨機數,pi為第i個粒子迄今為止搜索到的最優位置,即個體極值,pg為整個粒子群迄今為止搜索到的最優位置,即全局極值。
目前多采用的使線性遞減權值策略,動態w能夠獲得比固定值更好的結果。w的引入使得PSO算法性能有了很大的提高,提高了算法的全局和局部的搜索能力,w的值為
w=(wini-wend)(Gk-g)/Gk-wend
(5)
式中:Gk為最大迭代次數;wini為初始慣性權值;wend為迭代至最大進化代數時的慣性權值,典型權值wini取0.9,wend取0.4[17]。
1.3 基于PSO的NARX網絡特征參數優化流程
NARX網絡結構將隱含層個數設定為1,隱含層神經元個數q值的經驗公式為
(6)
式中:d為輸入層節點數;l為輸出層節點數;a為10~14的常數。
利用PSO優化NARX網絡中輸入層到隱含層的權值vih,隱含層到輸出層的權值whj,隱含層神經元的偏置bh,輸出層神經元的偏置bj,i=1,2,…,d;h=1,2,…,q;j=1,2,…,l。以下是具體的優化流程:
步驟1:初始化。初始化粒子群群體數量N,種群數量和最大迭代步數。每個粒子mi由vih、whj、bh、bj組成:
mi=(v1h,v2h,…,vih,w1j,w2j,…,whj,b1,b2,…,bj,b1,b2,…,bh)
利用rands函數初始化每個粒子mi的xi和vi,xi和vi中的每個元素的取值范圍都在[0,1]之間。
步驟2:計算每個粒子適應度的值。將模型預測輸出與目標輸出的均方誤差作為粒子的適應度函數值,如式(7)所示,均方誤差用來評價模型與實測數據的吻合程度,PSO算法尋優的目標就是使粒子的適應度函數值即均方誤差最小。
(7)
式中:Emse(y,yd)為均方誤差;y(t)為模型的預測值;yd(t)為輸出實測值。
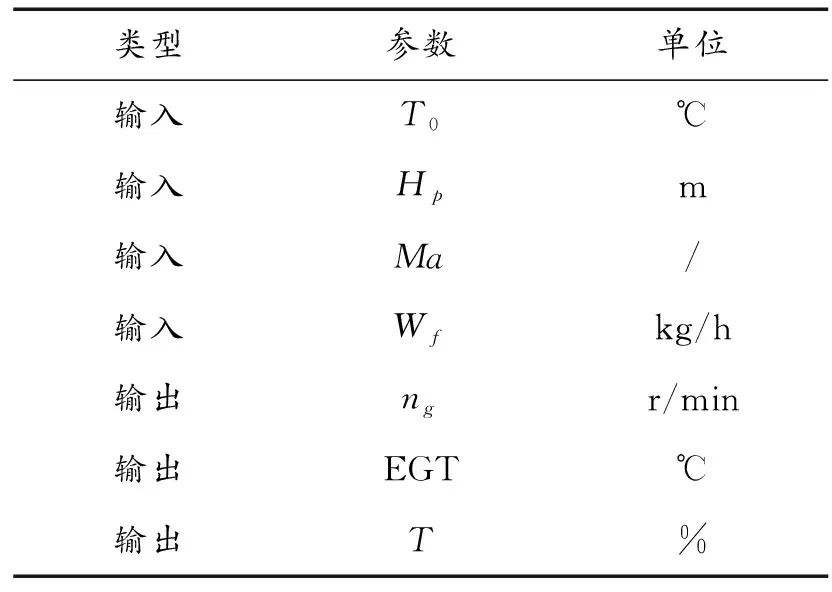
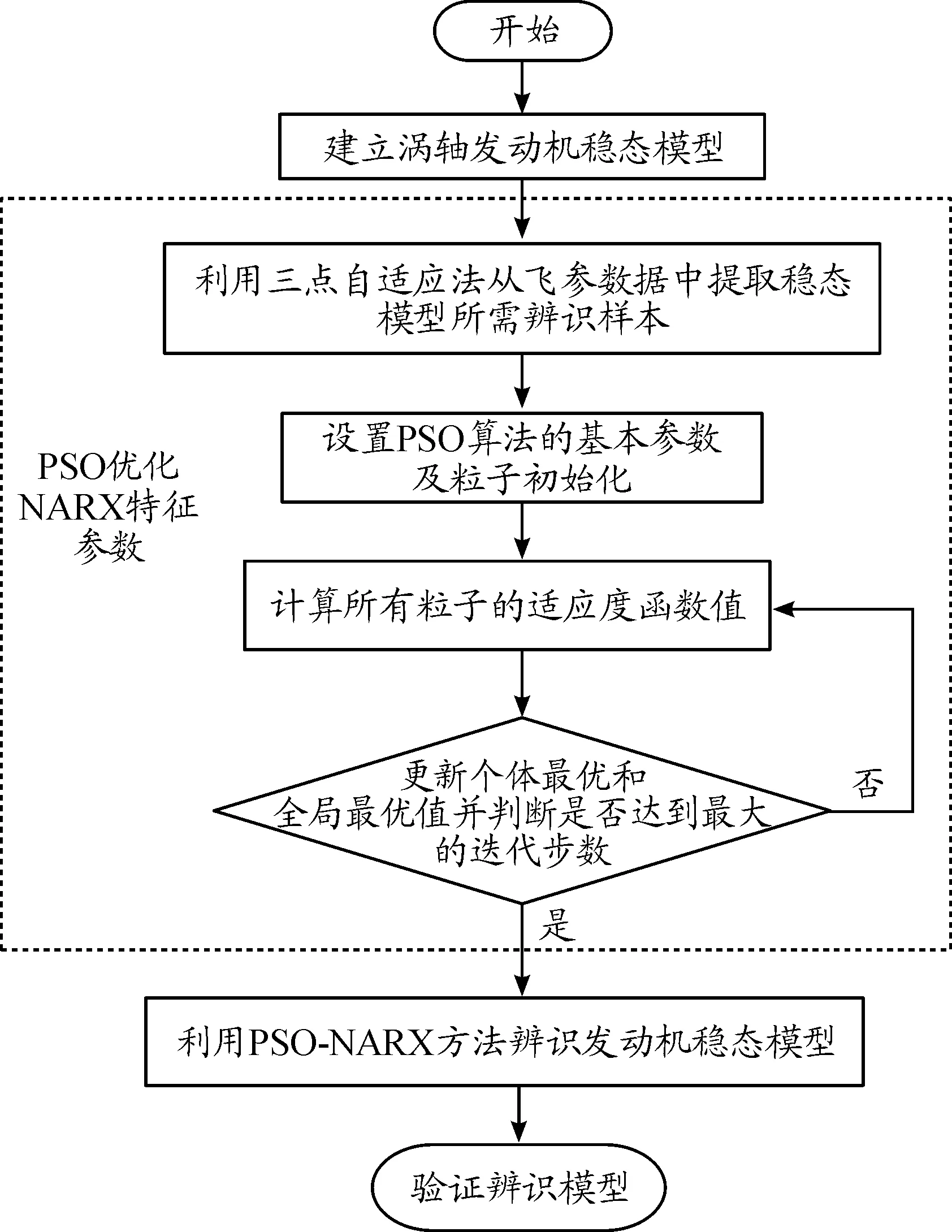
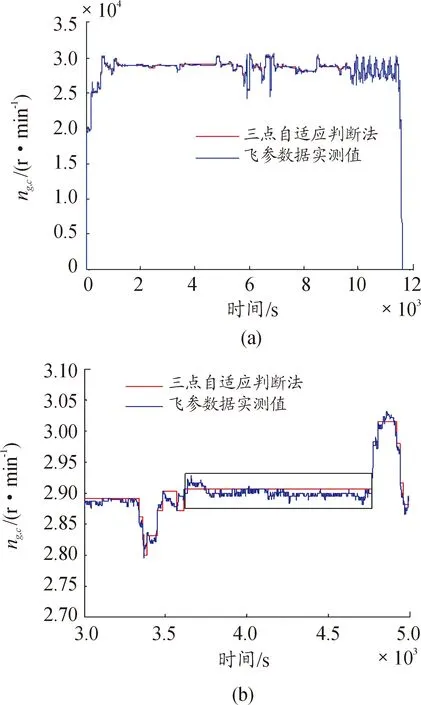
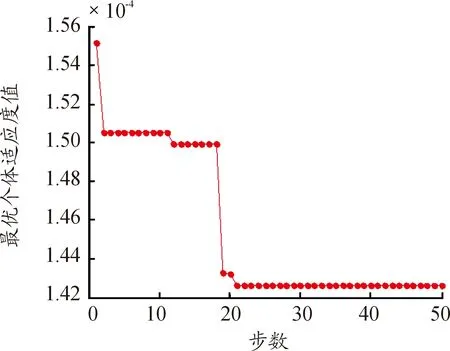
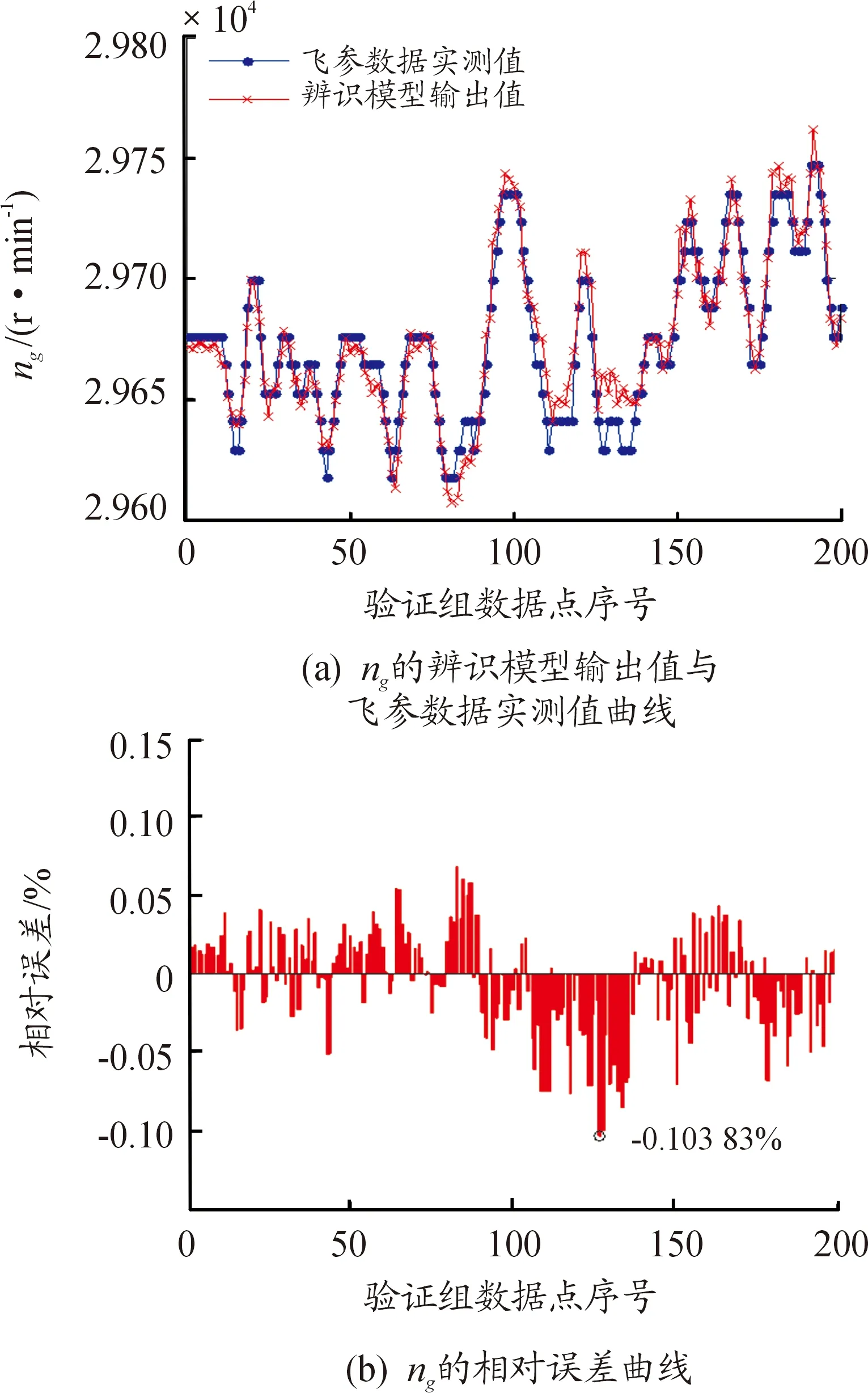
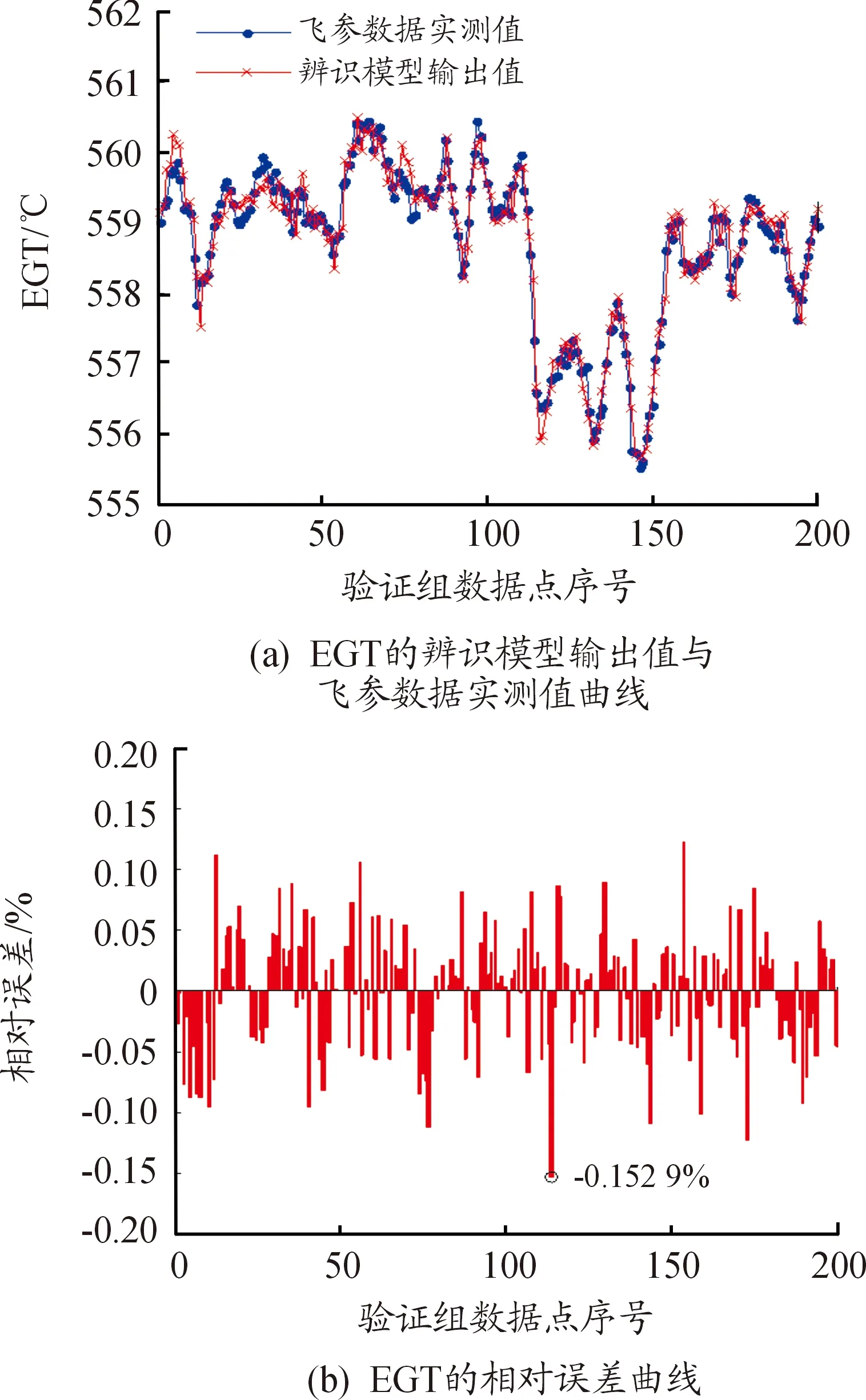
步驟3:計算每個粒子,用它的適應度值ffitness(mi)和個體極值pi比較,如果ffitness(mi) 步驟4:重復步驟1~3直到最大迭代步數,利用PSO算法得到NARX網絡的特征參數。 航空發動機是一個高度非線性的時變系統。大氣靜溫T0、絕對氣壓高度Hp、飛行馬赫數Ma、燃油流量Wf都會影響發動機工作過程。渦軸發動機主要工作狀態參數為燃氣發生器轉速ng、發動機排氣溫度EGT和發動機扭矩T。 發動機當前時刻的工作狀態與過去時刻的工作狀態密切相關。渦軸發動機穩態模型的輸入參數設置為T0、Hp、Ma、Wf的當前時刻值與過去時刻的值以及ng、EGT和T過去時刻的值,輸出參數設置為ng、EGT和T的當前時刻值。渦軸發動機穩態模型輸入輸出參數如表1所示。 綜上,渦軸發動機穩態模型為: (8) 式中:fss為需要辨識的發動機模型;k、m為輸入輸出延時階次。文獻[18]提出:通常,發動機模型輸入輸出參數延時階次設置為2為最佳方案。因此,將k和m設置為2。 表1 發動機穩態模型輸入輸出參數 根據表(1)知輸入層節點數d為4,輸出層節點數l為3,根據式(6)得到本文NARX網絡隱含層神經元個數q選為15。 基于PSO-NARX網絡的渦軸發動機穩態模型辨識的具體流程如圖2所示。 步驟1:根據發動機穩態工作原理,建立渦軸發動機的穩態模型如式(8),包括輸入、輸出參數和函數關系。 步驟2:利用三點自適應法從大量飛參數據中提取發動機穩態時的數據,建立辨識所需的樣本,并對樣本進行預處理。 步驟3:設置PSO算法的種群粒子數和最大迭代次數等基本參數,利用PSO對NARX網絡的特征參數進行尋優。 步驟4:以提取處理的辨識樣本為驅動,利用優選特征參數后的NARX網絡對所建立的渦軸發動機穩態模型進行辨識。 步驟5:利用驗證樣本對辨識得到的穩態模型進行驗證。 綜上,步驟1~5構成了基于PSO-NARX網絡的渦軸發動機穩態模型的辨識方法。 圖2 渦軸發動機穩態模型辨識流程框圖 以直升機飛參數據為驅動,建立基于PSO-NARX網絡的渦軸發動機穩態辨識模型,對辨識模型的性能進行驗證并與NARX、PSO-BP、PSO-SVM建立的辨識模型進行對比。 針對從飛參數據中對發動機穩態狀態進行識別的問題。本文在此提出一種穩態狀態的識別算法——三點自適應判斷法。設換算轉速-時間序列為向量ng,c(t),穩態轉速限制值采用動態變化值δn為 δn=0.01ng,c(t) (9) 采用三點自適應判斷法判斷第i個點是否為穩態點,將三點數值相減得到: (10) 若Δ<δn,則第i個轉速點為穩態工作點,并令ng,c(i+1)=ng,c(i),將時間平移繼續進行判斷。對符合轉速波動的穩態點進行記錄后通過穩態的時間限制值δtime,確定發動機的穩定工作狀態。根據渦軸發動機大量分析數據、工作經驗及其工作特點,通常選取轉速限制值為1%,穩態時間限制值為10 s。 使用DBSCAN聚類方法對某一架次飛參數據(飛參數據的采樣頻率為1s)中1發位置發動機轉速去噪處理后[20],利用三點自適應判斷法得到此架次穩定狀態處理曲線如圖3所示,從中可以得出發動機的穩定狀態。圖3(a)是利用三點自適應判斷法得出的穩定狀態判斷曲線,圖3(b)是圖(a)中3 000~5 000 s段的局部放大。例如,圖3(b)圖方框內的ng,c=28 997 r/min(即水平線所對應的換算轉速)時的穩定狀態即為發動機的穩態點,由此得到此架次此渦軸發動機在裝機過程中轉速從0~32 400 r/min(最大連續狀態)之間所有穩態點。 圖3 飛參數據穩態處理曲線 使用同樣的數據處理方法對5臺直升機2016—2018年的27個架次飛參數據中1發位置發動機轉速進行處理,得到同型號渦軸發動機轉速從0到最大連續轉速之間3 564個穩態點,每個穩態點的數據記為一組樣本數據,3 564組辨識樣本共129 076個數據點作為渦軸發動機穩態模型辨識樣本。此27個架次飛參數據來源于不同工況下的直升機飛行數據,包括低溫、高溫等多種飛行工況,發動機的工作點幾乎涵蓋了整個飛行包線。 根據構建的渦軸發動機穩態模型如式(7)所示,確定樣本參數為:T0、Hp、Ma、Wf、ng、EGT和T。對選取的樣本數據進行濾波和歸一化的處理。將處理后的數據作為模型的辨識樣本,在模型的訓練與驗證結束后對數據進行還原。采用辨識模型輸出值與飛參數據實測值最大相對誤差以及最大相對誤差均值來評價建立的辨識模型性能。相對誤差Eref為 (11) 式中:y(t)為辨識模型的輸出值;yd(t)為飛參數據實測值。 綜合考慮計算時間和收斂性以及資源占用的最優值等因素,將PSO算法的最大迭代步數設置為50,種群粒子數量設置為30[21-23]。利用PSO算法對NARX網絡特征參數尋優,尋優過程的適應度函數值曲線如圖4所示。結合從飛參數據提取的辨識樣本,利用PSO算法優化過特征參數的NARX網絡對建立的渦軸發動機模型進行回歸辨識。 圖4 尋優過程的最優個體適應度函數值曲線 利用樣本外的4個架次不同編號發動機穩態數據對得到的辨識模型非樣本點推廣能力進行驗證,分別取轉速ng,c=25 417、28 703、28 997、30 301 r/min時的4個穩態點數據為4組驗證樣本,分別記為M1、M2、M3和M4。通過將驗證樣本輸入辨識模型得到的輸出值與飛參數據實測值對比來驗證辨識模型的性能。例如,以M3組為驗證樣本時,取M3組中200個連續的數據點,得到辨識模型輸出參數ng、EGT和T與飛參數據實測值曲線和相對誤差分布曲線如圖5、圖6、圖7所示。 圖5 M3為驗證樣本ng辨識結果曲線 圖6 M3為驗證樣本EGT辨識結果曲線 4組數據分別作為驗證樣本時得到ng、EGT和T的最大相對誤差及最大相對誤差均值如圖8所示。從圖8可以得到,不同驗證樣本時,輸出參數ng、EGT和T的最大相對誤差分別為0.11%、0.26%和0.95%,最大相對誤差均值分別為0.105%、0.193%和0.865%。從圖5、圖6、圖7、圖8可以得到,辨識模型輸出結果很好地逼近了飛參數據實測值。說明本文提出的基于PSO-NARX網絡的發動機穩態模型精度滿足實際應用時的精度要求。 圖8 M1 M2 M3 M4為驗證樣本時輸出參數ng、EGT、T誤差的直方圖 為了更好的說明本文提出的基于PSO-NARX的渦軸發動機穩態模型辨識的優越性,用相同的訓練樣本和驗證樣本,利用PSO-BP、PSO-SVM和NARX網絡辨識建立的渦軸發動機穩態模型。 BP神經網絡使用MATLAB R2014a中的工具箱,設置為輸出層、單隱含層和輸出層,隱含層神經元個數依據經驗公式設置為15,各層連接權值及神經元偏置通過PSO尋優得到,選用Levenberg-Marquardt算法。SVM對渦軸發動機穩態模型進行回歸辨識時,利用PSO對SVM特征參數平衡因子C、不敏感度ε和徑向基核函數參數σ進行尋優。兩種算法中PSO的最大迭代步數均設置為50,種群粒子數量均設置為30。NARX網絡使用MATLAB R2014a中的工具箱,隱含層神經元個數依據經驗公式(6)設置為15,輸入輸出延時階次均設為2,權值及神經元偏置由rands函數隨機給定,采用train函數對NARX網絡進行訓練。 圖9 4種方法誤差曲線 圖9列出了采用4種不同方法辨識模型得到的4組驗證樣本輸出參數ng、T4和T的最大相對誤差均值。表2為4種不同方法建立渦軸發動機穩態辨識模型精度,由表可見輸出參數ng、EGT和T的最大相對誤差與最大相對誤差均值。 表2 4種不同方法辨識模型精度 從圖9和表2可知,PSO-NARX的不同驗證樣本最大相對誤差及最大相對誤差均值均小于PSO-BP、NARX和PSO-SVM。主要是因為PSO-NARX具有延時單元,將過去時刻的值反饋對當前時刻的輸出產生影響,PSO對NARX網絡的特征參數進行優化使得辨識模型的精度更高。BP神經網絡是前饋神經網絡無反饋單元,NARX網絡具有反饋單元,但初始權值、偏置也是由隨機函數產生,網絡特征參數沒有進行尋優。PSO-SVM精度也較好,但SVM對大規模訓練樣本會耗費大量的計算機內存和運算時間。由于PSO-NARX方法需要在最大迭代步數內對全部粒子進行適應度更新與尋優,PSO-NARX方法的訓練時間也較長,但平均訓練時間明顯短于PSO-SVM方法。 1) 辨識模型輸出參數ng、EGT和T的辨識結果很好的逼近了飛參數據實測值,證明了基于PSO-NARX網絡的渦軸發動機穩態模型辨識方法的可行性。 2) 采用4組驗證樣本對辨識模型的性能進行驗證,得到輸出參數ng、EGT和T的最大相對誤差分別為0.11%、0.26%和0.95%,最大相對誤差均值分別為0.105%、0.193%和0.865%。表明了基于PSO-NARX網絡的渦軸發動機穩態模型的精度達滿足實際應用的精度要求。 3) 在相同的訓練樣本和驗證樣本情況下,本文采用的基于PSO-NARX網絡的渦軸發動機穩態模型精度優于PSO-BP、NARX和PSO-SVM方法辨識的渦軸發動機穩態模型,有效的解決了渦軸發動機穩態模型建模復雜且精度不高的問題。 4) 若已知某些大氣環境條件和該條件下燃燒室供油特性,即可通過辨識模型獲取此大氣環境下的發動機穩態性能,表明了基于PSO-NARX網絡的渦軸發動機穩態辨識模型可用于其他任意大氣環境下發動機穩態性能的遞推估算。 5) 此辨識模型可用于后續在高原、高空及高低溫環境條件下進行飛行試驗的發動機狀態的實時監控,為渦軸發動機控制規律的優化奠定基礎,也為工廠對此型渦軸發動機試車試驗提供相關支持。2 渦軸發動機穩態模型辨識方法
2.1 建立渦軸發動機穩態模型
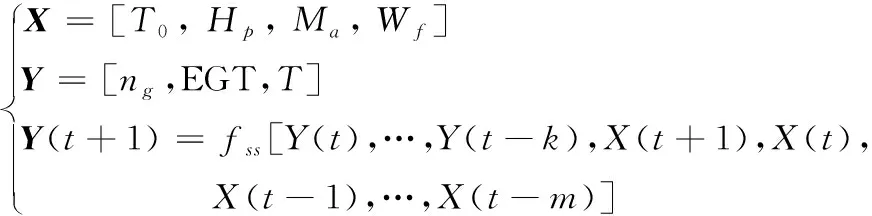
2.2 基于PSO-NARX網絡的穩態模型辨識方法
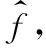
3 辨識過程與結果分析
3.1 從飛參數據中提取辨識樣本與數據預處理
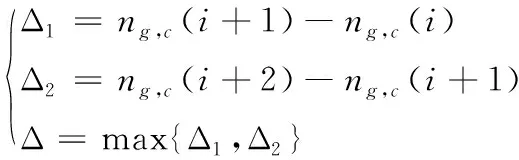
3.2 模型辨識結果
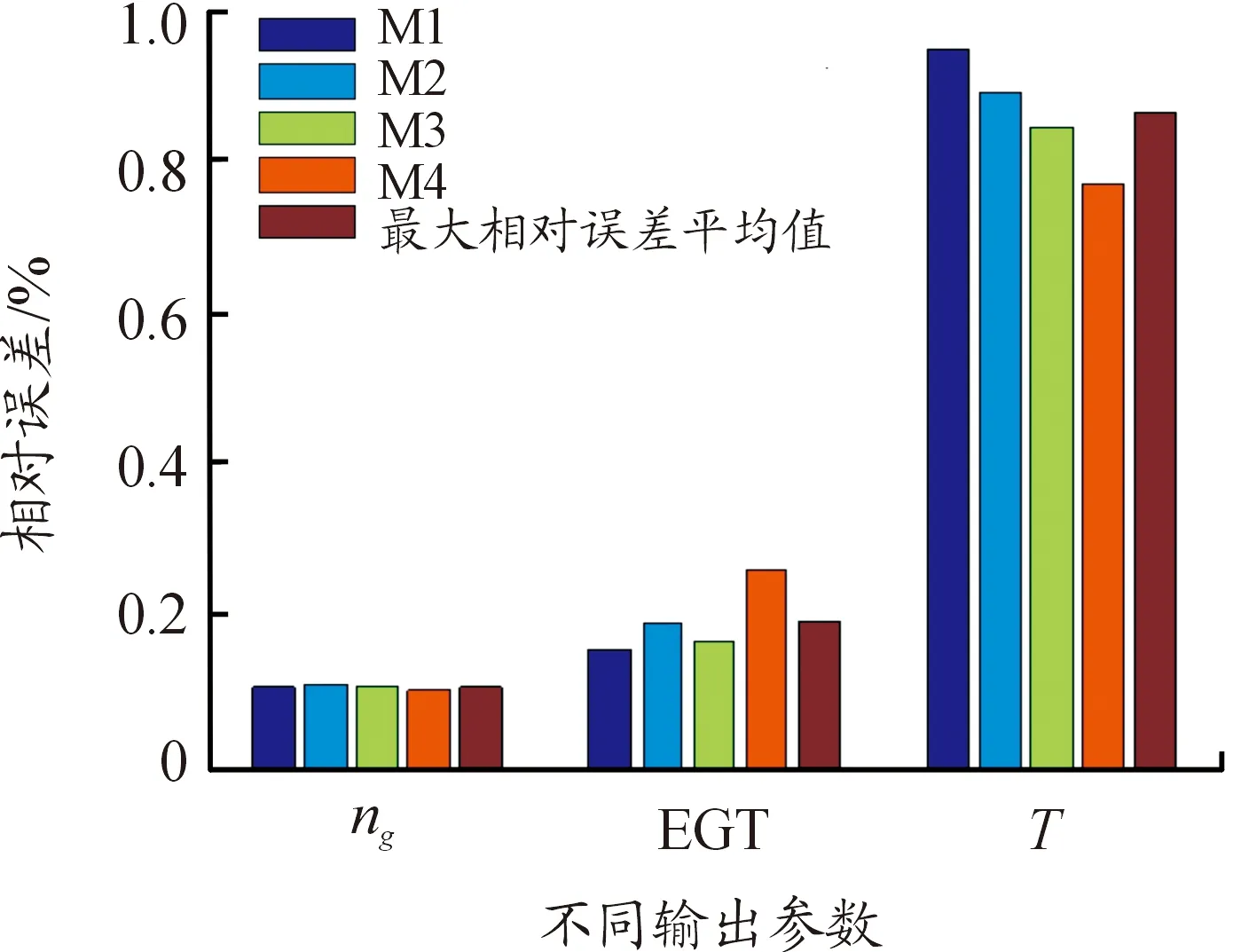
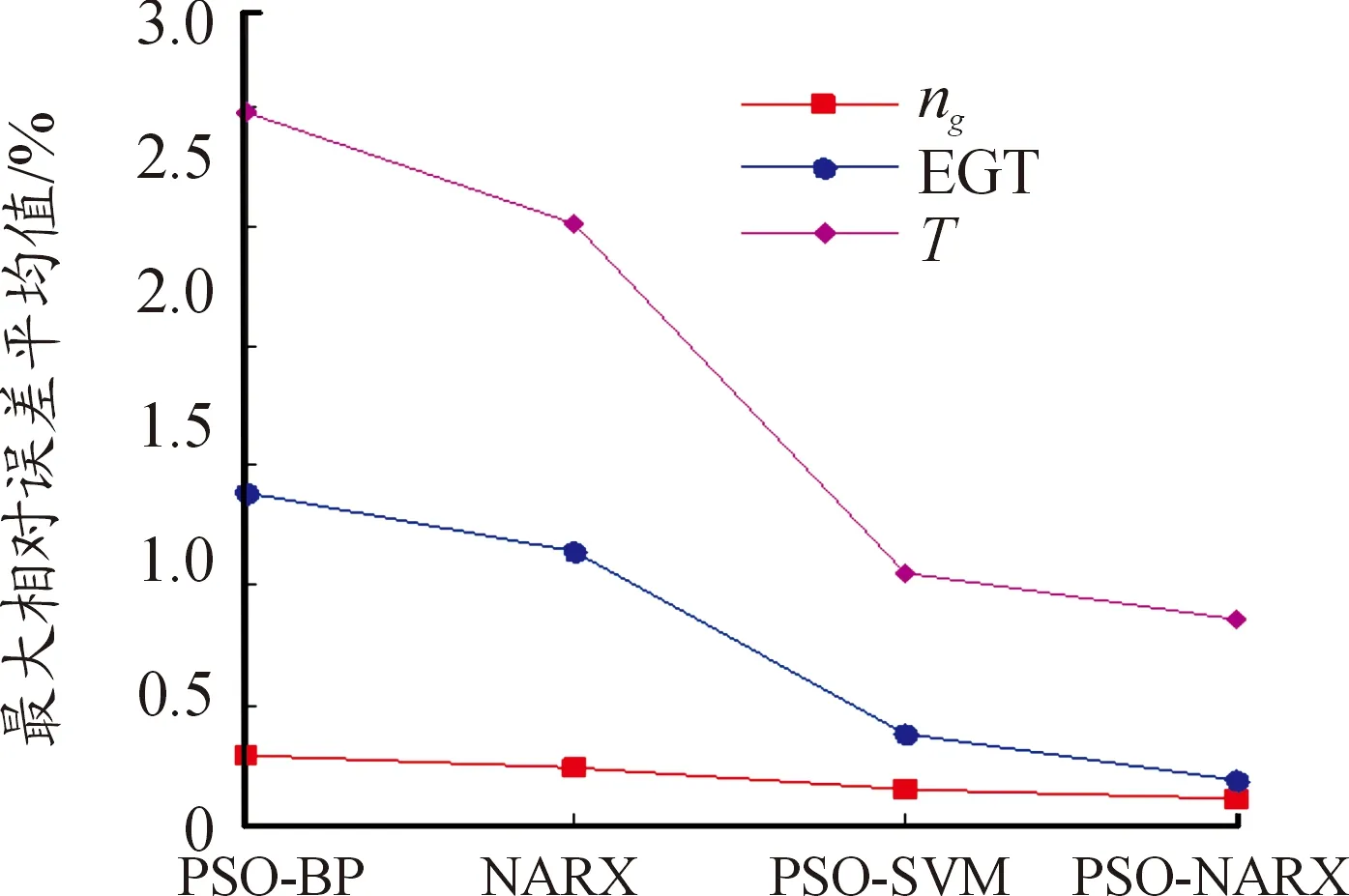
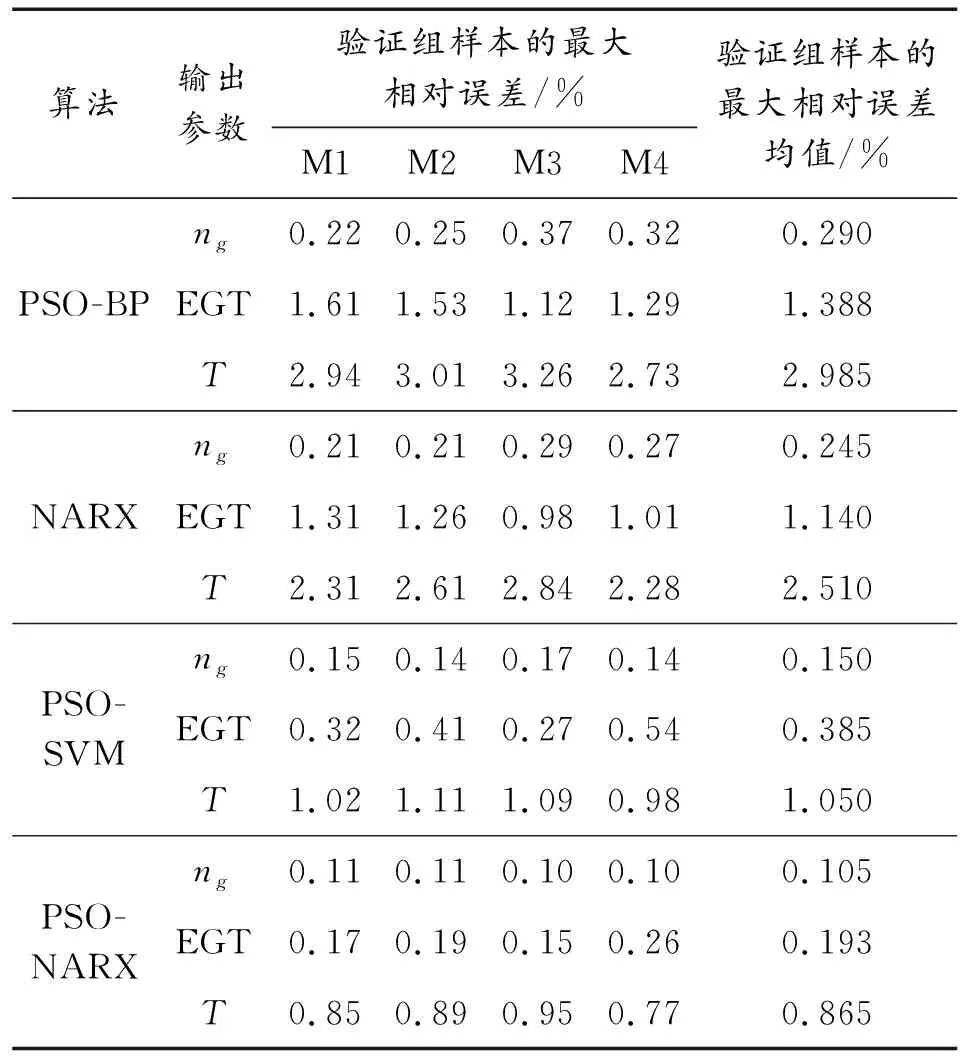
3.3 不同方法辨識效果對比
4 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車維修與保養(2021年8期)2021-02-16 00:28:30
汽車維修與保養(2021年8期)2021-02-16 00:28:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車與新動力(2015年1期)2015-02-27 12:11:01
汽車與新動力(2014年2期)2014-02-27 12:10:15
汽車與新動力(2013年5期)2013-03-11 16:08:17
