基于邏輯回歸函數(shù)的加權(quán)K-means聚類算法
2021-04-29 04:49:40林麗,薛芳
林 麗,薛 芳
(1.集美大學(xué)計(jì)算機(jī)學(xué)院,福建 廈門 361021;2.集美大學(xué)信息化中心,福建 廈門 361021)
0 引言
聚類分析在數(shù)據(jù)挖掘、文本摘要、圖像識(shí)別領(lǐng)域有廣泛應(yīng)用,它是一種非常重要的機(jī)器學(xué)習(xí)算法。聚類算法能自動(dòng)把數(shù)據(jù)對(duì)象劃分成不同類別,每個(gè)類別中數(shù)據(jù)具有相似特征。通過聚類算法,可以在茫茫數(shù)據(jù)中挖出數(shù)據(jù)的規(guī)律。K-means算法是一種基于劃分的硬聚類算法,其運(yùn)算速度快,尤其適用于高維數(shù)據(jù)、大規(guī)模及文本數(shù)據(jù)的聚類,是目前比較常用的一種聚類算法。
K-means算法的做法是隨機(jī)選擇K個(gè)聚類中心,通過歐式距離計(jì)算各個(gè)樣本和聚類中心的相似度。將樣本分配給距離最近的類。K-means算法存在2個(gè)問題:1)聚類結(jié)果不穩(wěn)定;2)用歐式距離計(jì)算樣本相似度。所有特征參與歐式距離計(jì)算且貢獻(xiàn)度都一樣,這往往帶有大小不等的隨機(jī)波動(dòng)。針對(duì)問題1),文獻(xiàn)[1-3]提出K-means++算法,其采用概率來選擇初始聚類中心,極大改善了傳統(tǒng)K-means算法隨機(jī)選擇聚類中心的不確定性,提高聚類準(zhǔn)確率。但是K-means++算法只考慮優(yōu)化聚類中心,并沒有考慮特征的不同貢獻(xiàn)。關(guān)于問題2)存在如下例子:如有二維樣本(身高,體重),其中身高數(shù)值范圍是150~190,體重?cái)?shù)值范圍是50~60,現(xiàn)有三個(gè)樣本:a(180,50),b(190,50),c(180,60)。按照歐式距離計(jì)算樣本相似度,Dist(a,b)=Dist(a,c),那么身高10 cm真的等價(jià)于體重10 kg么?顯然不是。而根據(jù)不同特征貢獻(xiàn)加權(quán)的歐式距離去計(jì)算,樣本的相似度才更準(zhǔn)確。關(guān)于特征加權(quán),文獻(xiàn)[4-5]提出通過特征的總方差、均值來表示特征權(quán)重,但是方差并不能準(zhǔn)確表示特征的差異情況。文獻(xiàn)[6]提出的特征賦權(quán)主要基于同類內(nèi)特征權(quán)重計(jì)算及學(xué)習(xí)。文獻(xiàn)[7]提出采用Pearso相關(guān)系數(shù)來對(duì)數(shù)據(jù)對(duì)象間的距離進(jìn)行加權(quán),考慮樣本和類中心的特征關(guān)聯(lián)計(jì)算特征權(quán)重。文獻(xiàn)[6]和文獻(xiàn)[7]的特征賦權(quán)考慮是樣本間的關(guān)聯(lián),但是并沒有考慮特征本身的差異對(duì)特征權(quán)重的影響。
Softmax函數(shù)可以凸顯特征差異,Sigmoid函數(shù)平滑極大極小特征差。本文提出一種特征賦權(quán)算法,它結(jié)合歸一化指數(shù)函數(shù)Softmax和激活函數(shù)Sigmoid計(jì)算特征權(quán)重,特征差異低的特征屬性貢獻(xiàn)少則賦予較低權(quán)重,差異大的特征貢獻(xiàn)大則賦予較大權(quán)重,以此嘗試更好地解決K-means算法的兩個(gè)問題。
1 相關(guān)知識(shí)
待聚類樣本集X={xi|xi∈X,i=1,2,…,n},每個(gè)樣本都有m個(gè)特征xi={xi1,xi2,…,xim}。
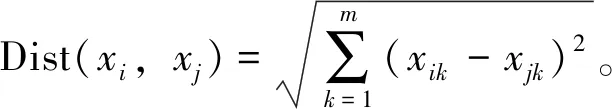
定義2 聚類的準(zhǔn)確率r=(m/n)×100%。其中m為正確聚類的樣本個(gè)數(shù),n為總樣本個(gè)數(shù)。

2 基于邏輯回歸函數(shù)賦權(quán)的LWK-means算法
相對(duì)于傳統(tǒng)K-means算法,本文提出的基于邏輯回歸函數(shù)賦權(quán)的LWK-means算法改進(jìn)了2個(gè)方面內(nèi)容:一是聚類初始中心點(diǎn)優(yōu)化,選擇盡量遠(yuǎn)離樣本作為初始聚類中心;二是設(shè)計(jì)特征權(quán)重計(jì)算方法,改進(jìn)歐式距離計(jì)算公式。
2.1 初始聚類中心優(yōu)化
聚類中心的優(yōu)化策略為:先隨機(jī)選一個(gè)樣本做聚類中心,從第二類開始,計(jì)算每個(gè)數(shù)據(jù)對(duì)象x與已選聚類中心的最小距離minDist(x)。其中:在minDist(x)中選擇最大值所在樣本j作為下一個(gè)聚類中心;每一個(gè)聚類中心的確定都保證是和已有聚類中心的距離是較大的;可以讓選擇的聚類中心更貼近數(shù)據(jù)分布。實(shí)驗(yàn)表明,盡量遠(yuǎn)離聚類中心的做法,可以提高聚類算法的準(zhǔn)確率。
InitCenter(X,k)具體做法:
1)選擇第一個(gè)樣本作為第一個(gè)聚類中心C1,k′為當(dāng)前類數(shù)量,k′=1。
2)根據(jù)定義2計(jì)算樣本集X和已有類中心的距離Dist(X,C)。
3)在Dist(X,C)中選擇離現(xiàn)有類的最小距離作為樣本和目前類Ck的距離值,
min Dist(X)=min(Dist(X,Ck))(k=1,2,…,k′)。
4)min Dist(X)中找出最大值所屬的樣本j,作為下一個(gè)聚類中心Ck′,k′=k′+1,Ck′=arg max(min Dist(X))。
5)重復(fù)步驟2),直到選完k個(gè)聚類中心。
2.2 特征賦權(quán)
特征權(quán)重是改進(jìn)算法中重要的步驟。特征權(quán)重計(jì)算主要是觀察各個(gè)特征的差異情況。如果某個(gè)特征數(shù)據(jù)變化少,這個(gè)特征的差異度就少,該特征在分類中貢獻(xiàn)度也少,賦低權(quán)重;如果某個(gè)特征數(shù)據(jù)變化大,該特征情況顯著,對(duì)分類貢獻(xiàn)大,賦高權(quán)重。特征差異度是在原始數(shù)據(jù)集上,即數(shù)據(jù)集未標(biāo)準(zhǔn)化前計(jì)算。保證特征差異度符合數(shù)據(jù)原始分布。
定義4 特征差異度p={p1,p2,…,pm},表示每一列特征變化情況。是個(gè)一維向量。
特征差異度一般都用方差表示特征整體誤差情況。由于各個(gè)特征取值范圍不同,某些特征即使差異較大,若取值較小,也會(huì)導(dǎo)致方差較小。本文提出一個(gè)新的計(jì)算差異度公式衡量特征差異情況。令
pi=(max(xi)-min(xi))/avg(xi),
(1)
其中:xi表示某一列的數(shù)據(jù);max(xi)表示該列的最大值;min(xi)表示該列最小值;avg(xi)表示該列平均值。極大極小差表示該列數(shù)據(jù)最大差異度,其與平均值比例可以從整體了解該列數(shù)據(jù)差異情況。p值越大,特征差異度越大,該特征數(shù)據(jù)變化大。
定義5 特征差異度的最大比值maxr=max(pi/pj)。pi,pj分別表示第i列與第j列的特征差異度。主要通過這個(gè)參數(shù)了解是否存在極大極小特征差異度。
定義6 特征權(quán)值w={w1,w2,…,wm},表示m個(gè)特征在歐式距離計(jì)算的不同貢獻(xiàn)度。使用邏輯回歸函數(shù)Softmax計(jì)算,公式為:
(2)
其中pi為每個(gè)特征差異度。pi越小,其貢獻(xiàn)度越小;反之,則貢獻(xiàn)度越大。
使用Softmax函數(shù)可以凸顯最大值,抑制低于最大值的其他分量。但是Softmax函數(shù)會(huì)出現(xiàn)特征權(quán)重極大極小情況,當(dāng)maxr值超過10,wi會(huì)完全偏向某一個(gè)特征。如某個(gè)數(shù)據(jù)集有3個(gè)特征權(quán)重分別為[0.070,0.012,0.910],第三個(gè)特征值比前2個(gè)大很多,特征權(quán)重計(jì)算會(huì)出現(xiàn)極大極小情況。由于特征值的取值范圍不同,導(dǎo)致權(quán)重值完全失衡。Sigmoid函數(shù)有很強(qiáng)的魯棒性,各個(gè)特征權(quán)重值可以映射到(0,1)區(qū)間,平衡特征權(quán)重間的差異,故公式(2)也可以用Sigmoid函數(shù)設(shè)計(jì):
(3)
每個(gè)特征賦權(quán)后,歐式距離及類誤差平方和SSE也改為加權(quán)歐式距離及加權(quán)的SSE(S)。
(4)
2.3 LWK-means算法
基于邏輯回歸函數(shù)賦權(quán)的LWK-means算法流程為:
ⅰ)輸入 樣本數(shù)據(jù)集X,聚類個(gè)數(shù)K
輸出K個(gè)聚類數(shù)
ⅱ)步驟
1)根據(jù)函數(shù)InitCenter(X,k),選擇k個(gè)初始聚類中心Ci。
2)根據(jù)公式(1)計(jì)算數(shù)據(jù)集的特征差異度Pi。
3)根據(jù)定義5計(jì)算最大特征比值maxr。若maxr>10,說明存在極大極小特征權(quán)重問題,則選擇公式(3)計(jì)算特征權(quán)重wi;若maxr<10,則選擇公式(2)計(jì)算特征權(quán)重wi。
4)根據(jù)公式(4),計(jì)算樣本和中心點(diǎn)的相似度Dist(x,C),取最小相似度作為樣本歸屬類別。將樣本分配至類別Li。
5)根據(jù)Li劃分的樣本,計(jì)算同類樣本在每一個(gè)特征的平均值,更新聚類中心Ci。
6)加入特征權(quán)重計(jì)算誤差平方和SSE(公式(4)),重復(fù)步驟2)→3)→4)→5),直至SSE不變或達(dá)到指定的迭代次數(shù)。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集
為了驗(yàn)證LWK-means算法的有效性及合理性。選用UCI數(shù)據(jù)庫(kù)中的6個(gè)數(shù)據(jù)集作為仿真數(shù)據(jù)測(cè)試。表1為數(shù)據(jù)集說明。針對(duì)每個(gè)數(shù)據(jù)集,運(yùn)行各算法100次。以算法的迭代次數(shù)、誤差平方和、準(zhǔn)確率作為有效性數(shù)據(jù)分析依據(jù)。并分別與K-means、SWK-means、LWK-means的聚類結(jié)果進(jìn)行對(duì)比。其中:K-means算法的聚類中心是隨機(jī)選擇,歐式距離不帶權(quán)重;SWK-means和LWK-means初始聚類中心的選擇策略一樣;SWK-means算法的歐式距離權(quán)重值為各列的方差;LWK-means算法的歐式距離權(quán)重值是基于特征差異度及邏輯回歸函數(shù)計(jì)算的結(jié)果。數(shù)據(jù)預(yù)處理方面,采用Z-Score標(biāo)準(zhǔn)處理原始數(shù)據(jù),保證不同維度數(shù)據(jù)的標(biāo)準(zhǔn)化。

表1 UCI數(shù)據(jù)集及說明
3.2 數(shù)據(jù)集特征權(quán)重
特征權(quán)重是衡量各個(gè)特征貢獻(xiàn)的指標(biāo)。如Iris數(shù)據(jù)集,類別劃分主要依據(jù)第3、4特征的數(shù)據(jù),由于第3、4特征的數(shù)據(jù)差異度比第1、2特征大,故第3、4特征貢獻(xiàn)大。使用Softmax函數(shù)凸顯第3、4特征,根據(jù)公式(1)、(2)計(jì)算各特征權(quán)重后,對(duì)第3、4特征在歐式距離測(cè)量中賦予較高權(quán)重[0.29,0.45](見表2)。

表2 數(shù)據(jù)集的特征權(quán)重
從表3的實(shí)驗(yàn)結(jié)果可看到,Iris數(shù)據(jù)經(jīng)過特征賦權(quán)后,聚類正確率高達(dá)95%。Haberman和Glass數(shù)據(jù)集中特征差異度出現(xiàn)極大極小情況,使用Sigmoid回歸函數(shù)平滑特征權(quán)重,即改善特征權(quán)重間的不平衡問題,也能按照特征的不同貢獻(xiàn)對(duì)特征賦權(quán)(見表2)。Balance數(shù)據(jù)集每個(gè)特征都為離散型數(shù)據(jù),列取值區(qū)間為[1,5],各個(gè)特征變化情況一致,故各個(gè)特征權(quán)重一樣(見表2)。
3.3 實(shí)驗(yàn)結(jié)果及分析
運(yùn)行K-means、SWK-means、LWK-means算法各100次,再取平均值。各算法在迭代次數(shù)、類誤差平方和SSE、類劃分準(zhǔn)確率的比較結(jié)果見表3和圖1~圖3。

表3 迭代次數(shù)、類誤差平方和SSE、類劃分準(zhǔn)確率指標(biāo)對(duì)比結(jié)果
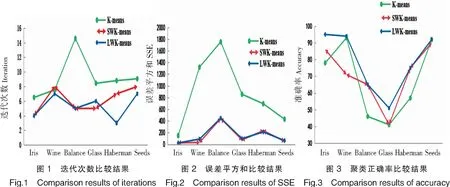
從表3及圖1可以看到,在迭代次數(shù)方面,LWK-means算法迭代次數(shù)均少于傳統(tǒng)K-means、SWK-means算法。聚類中心優(yōu)化后,LWK-means算法的迭代次數(shù)在數(shù)據(jù)集Haberman中表現(xiàn)出更快的收斂,運(yùn)行速度更優(yōu)。類誤差平方和SSE是聚類效果的一個(gè)重要衡量標(biāo)準(zhǔn)。SSE越小,說明類內(nèi)的誤差越小,類越緊湊,聚類效果也越好。表3及圖2顯示加權(quán)后的LWK-means和SWK-means算法的SSE更小,加快了算法的收斂。Iris數(shù)據(jù)集中,歐式距離經(jīng)過特征加權(quán)后,LWK-mans及SWK-means算法的準(zhǔn)確率明顯高于K-means;其他數(shù)據(jù)集中,LWK-means算法平均準(zhǔn)確率也高于K-means、SWK-means算法。
準(zhǔn)確率是一個(gè)很直觀的評(píng)價(jià)指標(biāo),但是準(zhǔn)確率高并沒有反映出模型真正的能力,并不能代表某個(gè)算法就好。因此,引入另外兩個(gè)指標(biāo):精確率(Precision)P和召回率(Recall)R,P=類別正確歸類的樣本數(shù)量/聚類后新類別的樣本數(shù)量,R=類別正確歸類的樣本數(shù)量/該類別原始的樣本數(shù)量。精準(zhǔn)確率用于檢驗(yàn)聚類結(jié)果的有效性,召回率用于檢查聚類結(jié)果的完整性。表4展示2個(gè)數(shù)據(jù)集中每個(gè)類別的精確率和召回率。圖4和圖5是6個(gè)數(shù)據(jù)集的精確率和召回率取均值后的柱狀圖。
由表4、圖4、圖5可以看出,LWK-means在6個(gè)數(shù)據(jù)集中的精確率、召回率都優(yōu)于其他2個(gè)算法;Balance、Haberman、Glass數(shù)據(jù)集中,LWK-means算法特征加權(quán)后的精確率和召回率都明顯比未加權(quán)的K-means算法高。表5是對(duì)6個(gè)數(shù)據(jù)集的精確率、召回率、準(zhǔn)確率取均值的比較結(jié)果:LWK-means算法的精確率較未加入權(quán)重的K-means算法提高7.6%,較方差加權(quán)的SWK-means算法提高1.7%;其召回率較K-means算法提高4.2%,較SWK-means算法提高1.7%;其準(zhǔn)確率較K-means算法提高12.4%,較SWK-mean算法提高3.3%。這3個(gè)指標(biāo)再次證明LWK-means算法的有效性及穩(wěn)定性。
K-means算法采用歐式距離計(jì)算樣本相似度,適用于球形數(shù)據(jù)分布,對(duì)非球形數(shù)據(jù)及離群點(diǎn)不敏感。從實(shí)驗(yàn)中看到,關(guān)于Glass和Balance等非球形數(shù)據(jù)集,3種算法準(zhǔn)確率較低。需要引入監(jiān)督算法訓(xùn)練權(quán)重值。但從表3及圖3可看到LWK-means算法平均準(zhǔn)確率還是高于傳統(tǒng)的K-means及SWK-means算法。
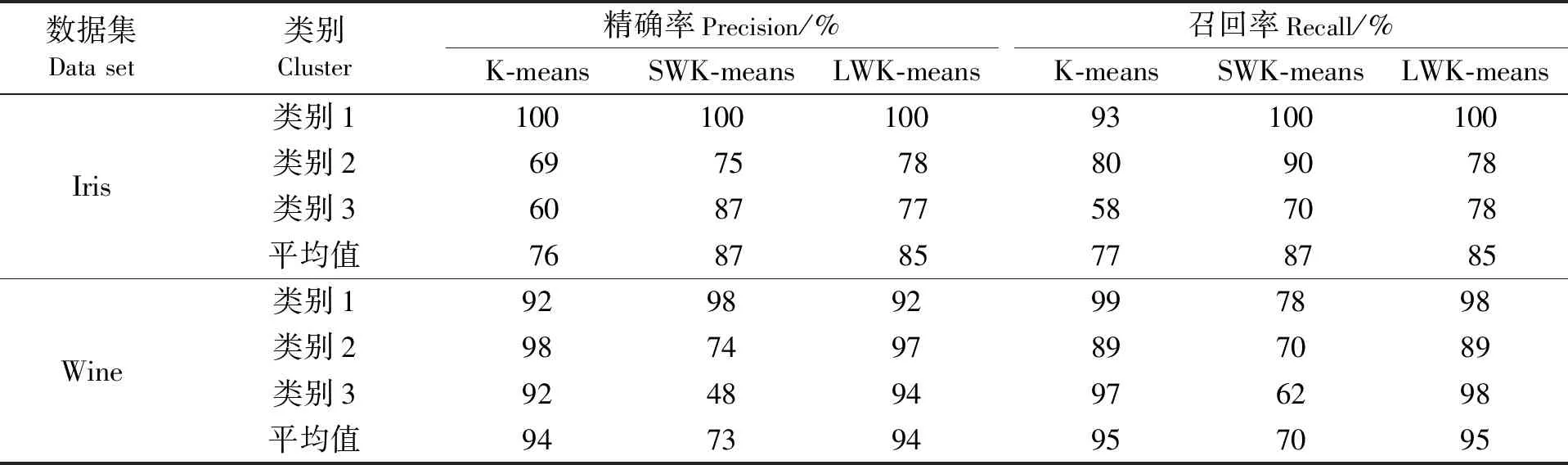
表4 各算法精確率和召回率的比較結(jié)果
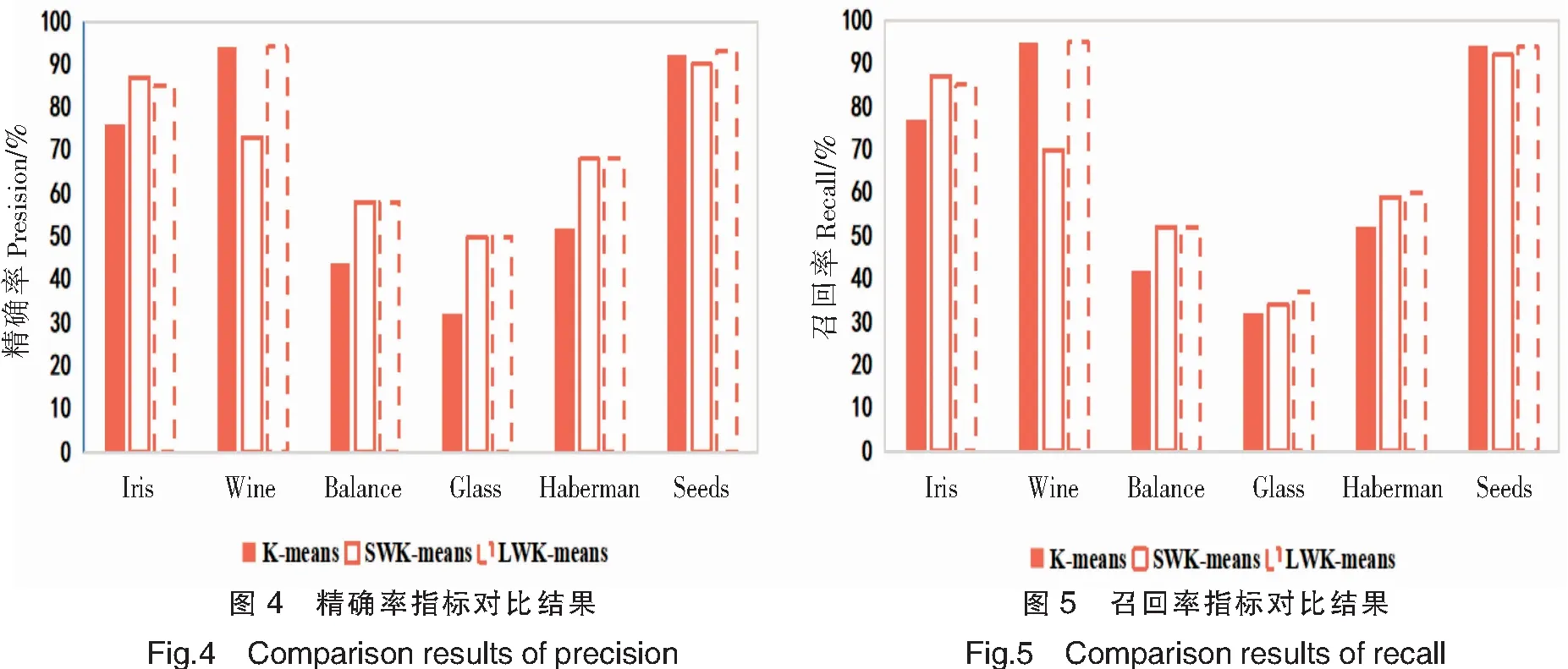

表5 各算法精確率、召回率、準(zhǔn)確率指標(biāo)對(duì)比結(jié)果
4 結(jié)論
傳統(tǒng)的K-means算法存在隨機(jī)選擇聚類中心、特征權(quán)重均等情況,導(dǎo)致聚類結(jié)果不穩(wěn)定、樣本相似度計(jì)算不準(zhǔn)確的問題。本文針對(duì)K-means算法的不足,提出基于邏輯回歸函數(shù)賦權(quán)的LWK-means算法。首先,優(yōu)化聚類中心。選擇距離較大的K個(gè)樣本作為聚類中心,解決了傳統(tǒng)K-means聚類中心不穩(wěn)定問題,初始中心點(diǎn)盡量貼近類別本身。然后,根據(jù)每個(gè)特征差異度,使用Softmax和Sigmoid回歸函數(shù)計(jì)算特征權(quán)重,為特征分配不同貢獻(xiàn)度。經(jīng)過加權(quán)的歐式距離計(jì)算方法可以提高樣本相似度的計(jì)算準(zhǔn)確率。實(shí)驗(yàn)選擇了UCI數(shù)據(jù)庫(kù)中的6個(gè)數(shù)據(jù)集,通過與K-means、SWK-means算法比較,LWK-mean算法在迭代次數(shù)、誤差平方和、準(zhǔn)確率、精確率、召回率方面都表現(xiàn)更優(yōu)性能。但是,在實(shí)驗(yàn)中也發(fā)現(xiàn),歐式距離的計(jì)算方法并不適用所有數(shù)據(jù)集,后續(xù)研究工作中,可以引入監(jiān)督學(xué)習(xí)方法改進(jìn)樣本相似度計(jì)算方法,提高聚類準(zhǔn)確率。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
音樂探索(2022年2期)2022-05-30 21:01:37
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2019年8期)2019-08-27 02:23:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中國(guó)特種設(shè)備安全(2018年11期)2019-01-08 02:08:32
小學(xué)科學(xué)(學(xué)生版)(2018年7期)2018-08-13 09:33:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
鄭州大學(xué)學(xué)報(bào)(醫(yī)學(xué)版)(2015年2期)2015-02-27 14:50:46
