少樣本學習下的服裝風格分析與評價
2021-04-29 01:09:36胡夢瑩鐘躍崎
毛紡科技 2021年4期
胡夢瑩,鐘躍崎,2
(1.東華大學 紡織學院, 上海 201620; 2.東華大學 紡織面料技術教育部重點實驗室, 上海 201620)
服裝圖像包含豐富的特征信息,以服裝作為研究對象進行分類識別,并設計相關應用層出不窮,不斷吸引著服裝行業與計算機視覺方向研究者的注意并為此創新技術。一方面是由于電子商務行業的興起,大量服裝數據需要被合理分類和檢索,另一方面是由于深度學習技術在計算機視覺方面不斷實現突破。相關的研究包括服裝解析與分類[1],服裝檢索[2],服裝搭配推薦[3],服裝流行度預測[4]等。結合深度學習的服裝風格的分類與評價工作相關記錄甚少。
不同于識別一件服裝的類別(毛衣,短袖,連衣裙)或其屬性(顏色,圖案),服裝風格是表征服裝整體視覺效果的高層次概念,需要分析對比大量的特征來判斷其屬性。以往研究中,評定服裝風格一般采用主觀評價的方法,缺少主觀感受與評判指標間關系的研究,因此,通過提取各類服裝特征并對其進行總結類比對服裝風格的量化具有重要意義[5]。
服裝風格識別的關鍵在于服裝圖像的特征提取,傳統的基于目標圖像的顏色特征、紋理特征、形狀特征、SIFT特征[6]、HOG特征[7]提取方法在這一領域并不適用。卷積神經網絡具有復雜的層級結構,具有局部連接特性和權值共享特性,適用于服裝圖像的特征提取。利用卷積神經網絡對服裝圖像提取對應風格的特征,有助于實現基于服裝風格的分類。
本文以不同品牌的服裝圖像為研究對象,采用卷積神經網絡提取服裝圖像的視覺特征的方法,將其映射到風格特征空間,實現品牌服裝風格的分類識別。由于實驗數據集樣本數量少,采用少樣本學習[8-9]的方法進行實驗。
少樣本學習方法更接近人類的學習模式,是元學習(meta Learning)[10]在監督學習中的應用。元學習旨在讓模型學會如何學習(learning to learn),能夠處理類型相似的任務,而不是只會單一的分類任務。
少樣本學習任務包含3 個數據集: 訓練集、支持集和查詢集。如果支持集包含N類相互獨立的類別,每個類別包含K個樣本,此時的少樣本學習問題則被稱為N類別K樣本(N-way,K-shot) 問題。本文選用3種目前比較流行的網絡架構來對自建的數據集進行測試,分別是Siamese 網絡[11],Prototype 網絡[12]和Meta baseline 網絡[13]。
1 實驗部分
1.1 數據的采集
本文建立了一個品牌服裝風格圖像數據集,該數據集中所有圖像均來自時尚網站VOGUE[14],包含了VOGUE網站時裝秀場的50個服裝品牌,分別是亞歷山大麥昆(Alexander McQueen)、亞歷山大王(Alexander Wang)、鄞昌濤(Andrew Gn)、安娜蘇(Anna Sui)、阿瑪尼高定(Armani Prive)、巴黎世家(Balenciaga)、巴爾曼(Balmain)、藍色情人(Blumarine)、葆蝶家(Bottega Veneta)、博柏利(Burberry)、卡爾文·克雷恩(Calvin Klein)、卡羅琳娜·埃萊拉(Carolina Herrera)、沙杜·拉爾夫·魯奇(Chado Ralph Rucci)、香奈兒(Chanel)、克洛伊(Chloe)、克里斯汀·迪奧(Christian Dior)、德里克·林(Derek Lam)、杜嘉班納(Dolce & Gabbana)、德賴斯·范諾頓(Dries Van Noten)、安普里奧·阿瑪尼 (Emporio Armani)、艾特羅(Etro)、芬迪 (Fendi)、詹巴迪斯塔·瓦利 (Giambattista Valli)、喬治·阿瑪尼(Giorgio Armani)、紀梵希(Givenchy)、古馳(Gucci)、愛馬仕(Hermes)、杰斯· 舞(Jason Wu)、高緹耶 (Jean Paul Gaultier)、吉爾·桑達 (Jil Sander)、浪凡 (Lanvin)、路易威登(Louis Vuitton)、馬克·雅可布之馬克(Marc by Marc Jacobs)、馬克·雅可布(Marc Jacobs)、瑪尼(Marni)、麥士邁娜(Max mara)、邁克高仕(Michael Kors)、米索尼(Missoni)、繆繆(Miu Miu)、蓮娜麗姿(Nina Ricci)、奧斯卡·德拉倫塔(Oscar de la renta)、普拉達(Prada)、拉爾夫·勞倫(Ralph Lauren)、斯特拉·妮娜·麥卡特尼(Stella Nina McCartney)、湯米·希爾費格(Tommy Hilfiger)、湯麗柏琦(Tory Burch)、瓦倫蒂諾(Valentino)、王微微(Vera Wang)、范思哲(Versace)、圣羅蘭(Yves Saint Laurent)。每個品牌的服裝圖像為30張,共計1 500張圖像。隨機抽取36個服裝品牌用作訓練集,剩余14個服裝品牌用作支持集。
1.2 預處理
為了提高服裝圖像分類準確率,對參與訓練的服裝圖像數據進行歸一化、去均值預處理,用于后續的實驗。
1.2.1 歸一化
歸一化也是一種簡化計算的方式,將有量綱的表達式,經過變換,簡化為無量綱的表達式,成為標量,便于不同單位或量級的指標能夠進行比較和加權。歸一化將數據映射到指定的范圍,減少了各維度的數據取值差異,減少了因數據取值范圍差異大造成對分類實驗結果的影響。常見的歸一化方式有特征標準化、圖像像素的簡單縮放等。本文采用min-max歸一化:
式中:xnew為經過歸一化處理后得到的新數據值,xmax為樣本數據的最大值,xmin為樣本數據的最小值。
1.2.2 去均值
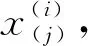
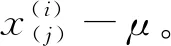
1.2 服裝風格分類模型
1.2.1 Siamese網絡
在解決N-way、K-shot分類問題方面,孿生神經網絡(Siamese neural networks)是最早得到應用的模型[12]。孿生神經網絡的結構如圖1所示,該類模型包含2個分支(如圖1的分支1和分支2)。每個分支分別對應1個輸入,該類輸入可以是一維的信號、二維的圖像、三維的點云或三角形網格。每個輸入均經過降維或映射后變成1個長度固定的特征向量,如圖1的特征向量1和特征向量2。計算特征向量1和特征向量2的相似程度。
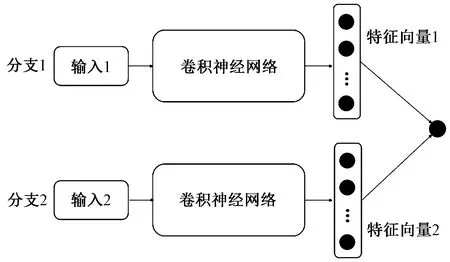
圖1 孿生神經網絡結構示意
1.2.2 Prototype網絡
除了孿生網絡以外,本文還使用了Prototype 網絡,該模型的原理如圖2所示。
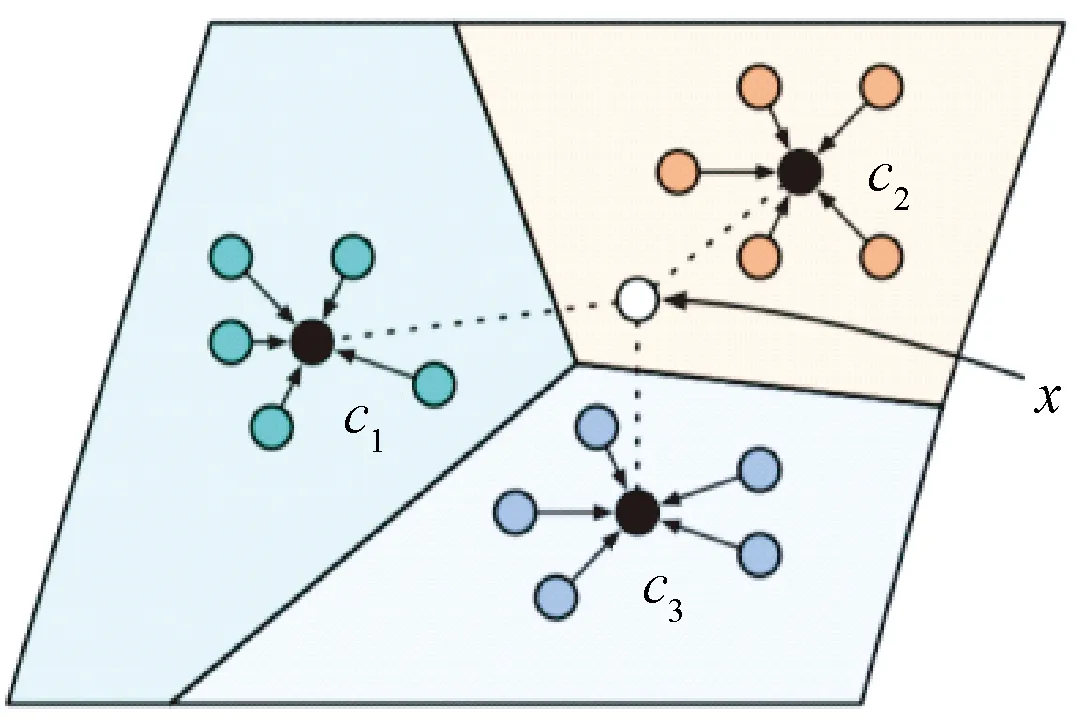
c1—類別1的特征向量;c2—類別2的特征向量;c3—類別3 的特征向量;x—查詢樣本。圖2 Prototype 網絡原理
如圖2所示,若訓練樣本包含3個類別(不同顏色),每個類別包含5個樣本,求每類的特征向量均值ck,其計算方法為:
式中:k=1,2,3,指代類別,每個類別的特征向量均值記為c1、c2、c3。Sk是訓練樣本中屬于第k類樣本的集合,xi是集合Sk中的第i個樣本,yi是xi的標簽,fw(xi)是樣本xi的特征映射(特征向量),其中w為待學習的參數。當k為1時,Sk包含5個樣本,即i的取值為{1,2,3,4,5}。以每個類別的特征向量均值c1、c2、c3分別作為該類的原型,若1個新的樣本x屬于圖2所示的c2類,則x的特征向量與c2之間的距離要小于其與c1或c3的距離。在訓練的過程中以樣本x與各個類別均值的距離來計算樣本x屬于各個類別的概率,同類距離近,異類距離遠。使用交叉熵損失函數實現模型的優化。在測試集(支持集)上也采用求特征向量均值的方法,然后計算查詢樣本與支持集的每個類別中心的距離,以該距離作為度量依據判斷查詢樣本的類別。
1.2.3 Meta baseline網絡
該網絡包含2個部分,第1部分是Classifier-baseline,是通過預訓練得到1個具有分類功能的分類器。具體實現時,首先以交叉熵為損失函數在訓練集上訓練1個標準的分類網絡fθ,然后將該網絡最后一層的全連接層(FC)去掉,利用該訓練好的卷積模塊作為特征提取器,提取支持集(support set)和查詢集(query set)中樣本的特征向量(representation)。第2部分是meta baseline,元學習框架。元學習框架是以提取的特征向量實現小樣本任務的分類,若支持集中每個類別含有多個樣本(shot大于1),則將多個樣本的特征向量均值(mean)作為該類別的中心,然后計算查詢集(query-set)中查詢樣本的特征向量與支撐集中每個類別特征向量均值的余弦距離(cosine similarity),計算出查詢樣本對每個類別的得分(概率)。模型結構如圖3所示。
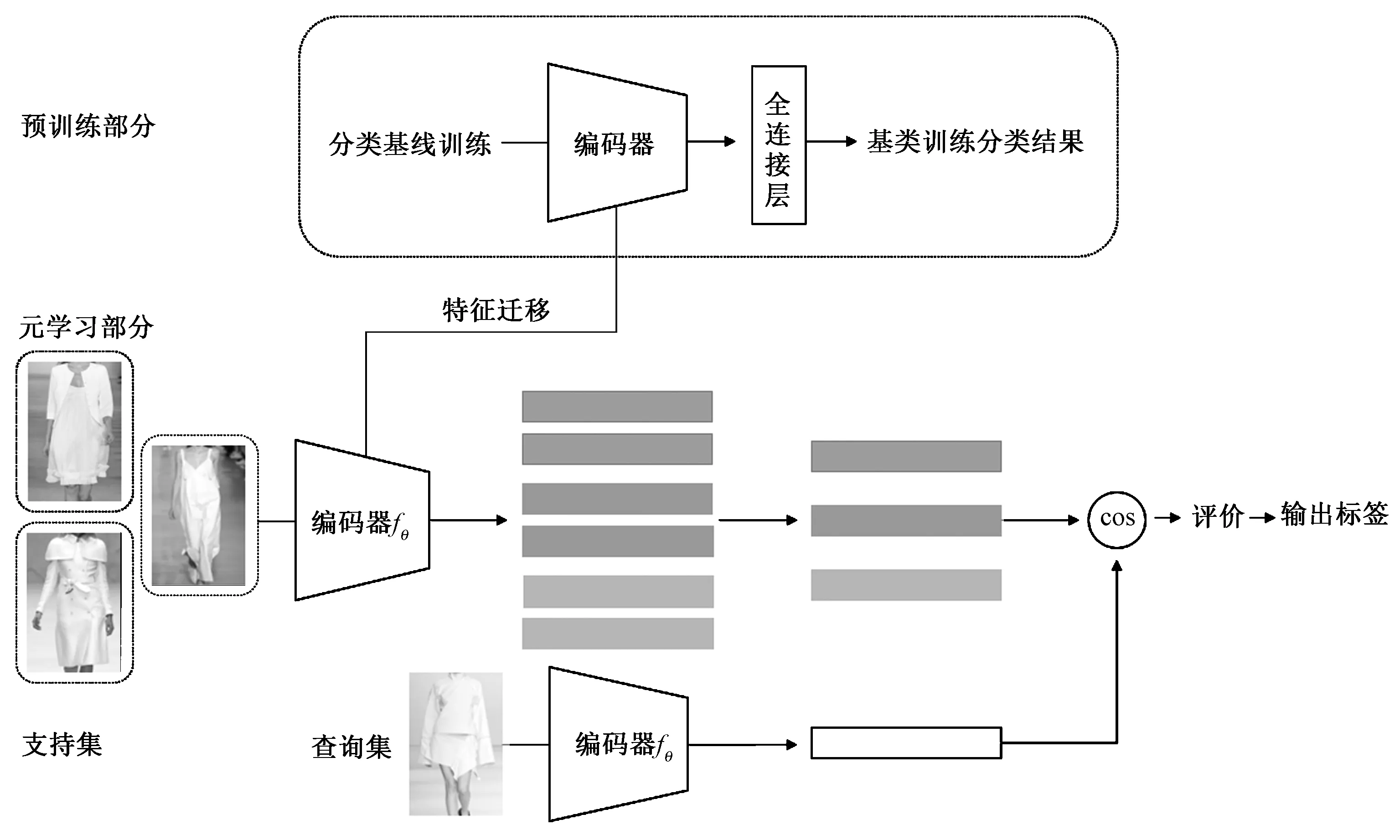
圖3 meta baseline網絡結構圖
2 實驗結果
為了實現較高分類準確率,同時控制訓練的時間成本,設置了80次迭代訓練。以線性衰減作為學習率的衰減方式,由于在網絡訓練中設置適當的學習率、設置適當的權重衰減系數、設置適當的圖像大小可以提高網絡的學習效率,下面依次對上述影響因素進行驗證。
2.1 Siamese網絡實驗結果
Siamese網絡實驗結果如表1所示。
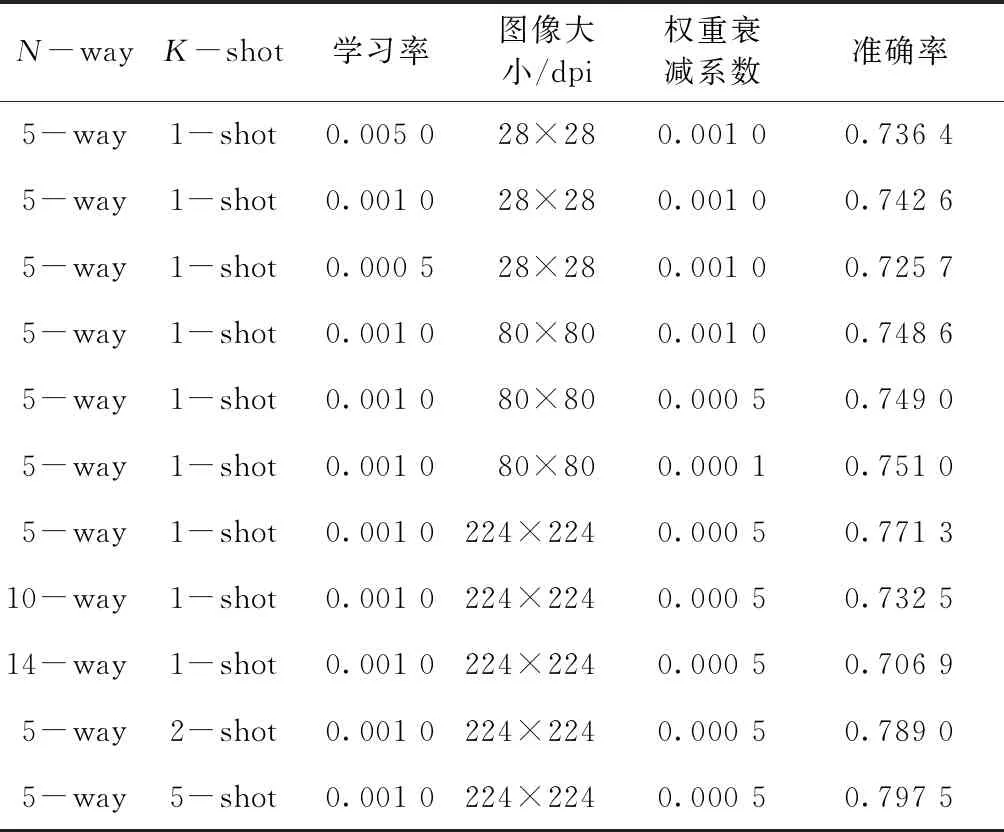
表1 Siamese網絡實驗結果
可以看到,模型的學習率、權重衰減系數的選擇、設置圖像的大小對實驗結果有影響,其中設置圖像的大小對實驗結果影響較大。從實驗結果來看,圖像大小設置為224×224 dpi最合適。本文實驗還嘗試了將圖像大小設置為300×300 dpi,但是對結果影響不大,而且訓練時間成本比224×224 dpi的大。所以,輸入模型的圖像大小最終設置為224×224 dpi。
2.2 Prototype網絡實驗結果
Prototype網絡的實驗結果如表2所示。
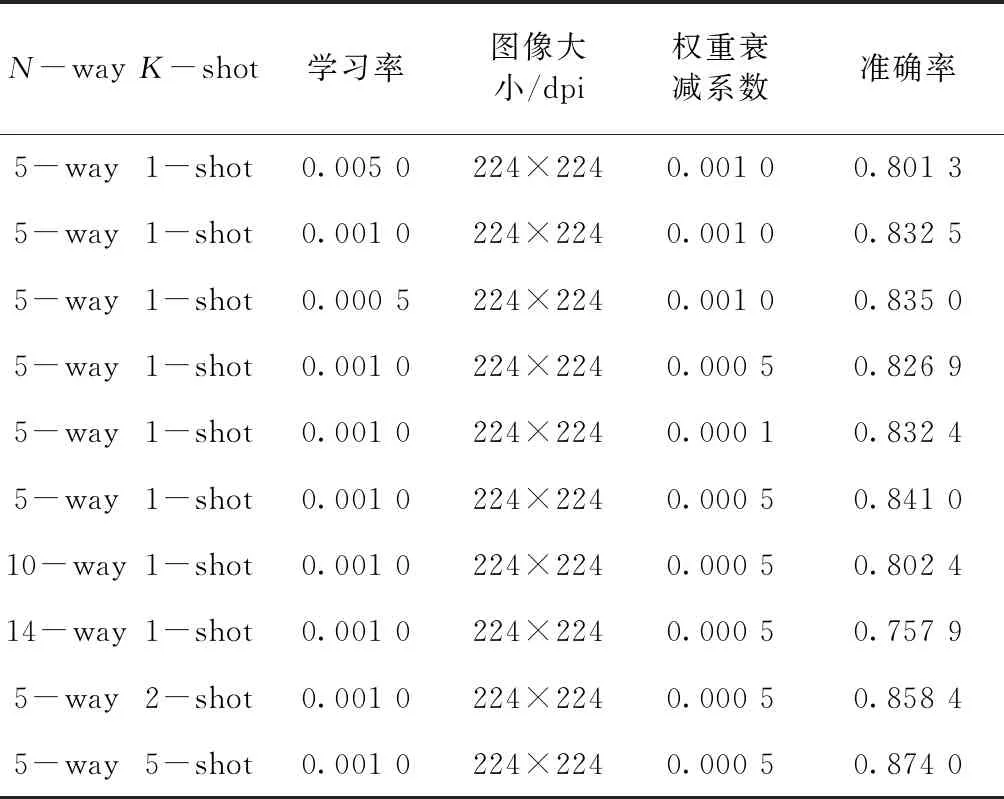
表2 Prototype網絡實驗結果
實驗結果表明,Prototype網絡模型對于品牌服裝數據集的分類準確率相比于Siamese網絡有了一定的提高。在5-way,1-shot任務中,在最優參數下,品牌服裝數據集分類準確率高達0.841 0。
2.3 Meta baseline網絡實驗結果
Meta baseline網絡的實驗結果如表3所示。
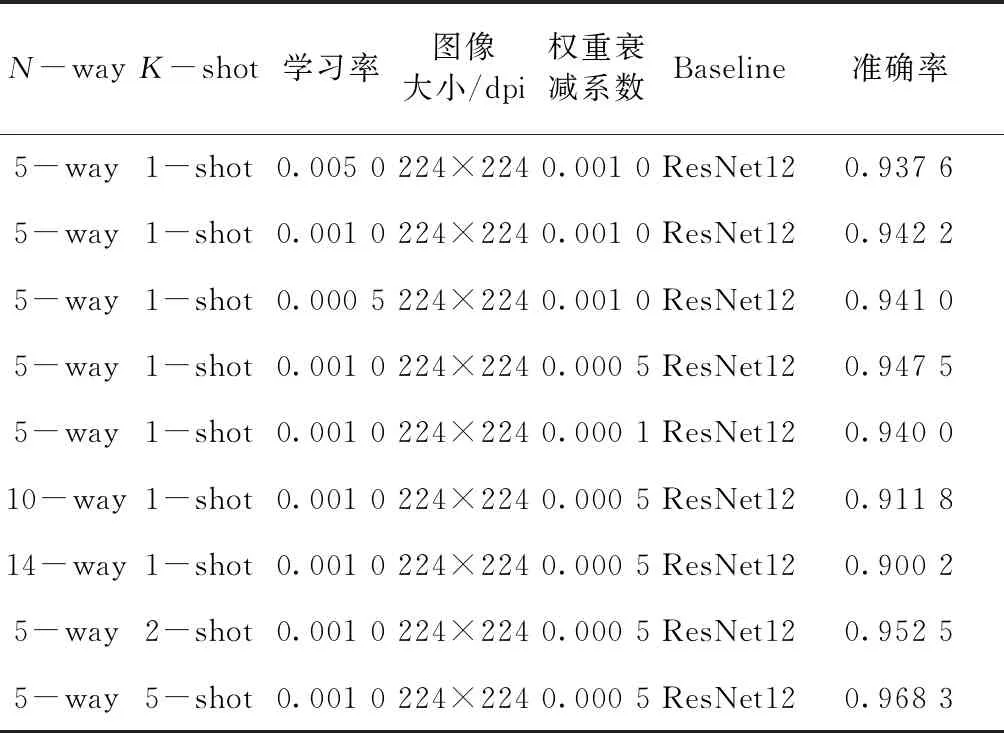
表3 Meta baseline 網絡實驗結果
實驗結果表明,Meta baseline網絡對于自建的品牌服裝數據集的分類任務的效果比前2種方法的效果都好,分類效果有了很大的提升。在5-way,1-shot任務中,在最優參數下,品牌服裝數據集分類準確率高達0.947 5。由于實驗環境的限制,本實驗選擇了ResNet-12作為基線網絡,batchsize均為1。雖然理論上這意味著隨機梯度下降,但是從實驗效果來看,優化的過程中,震蕩現象并非過于激烈,可為工程實踐中,當硬件條件有限時的網絡訓練實踐提供一定的參考。
3 結束語
本文利用深度神經網絡將服裝的風格特征提取為特征向量,從數學的角度來描述服裝風格特征并判斷服裝風格特征的相異性。對比分析了適合本文數據集網絡模型的分類結果,并驗證了可能影響分類結果的參數。本研究對于穩定服裝品牌風格,提升傳統服裝產業,迎合在線服裝市場,滿足消費者的消費需求,對服裝在線交易的風格推薦、風格評估具有一定的參考價值。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
