基于TDOA多聲源定位的虛假聲源消除方法
2021-04-28 16:22:20劉海濤陳永華林艷明
振動、測試與診斷 2021年2期
關鍵詞:方法
劉海濤,陳永華,林艷明,周 新
(1.華東交通大學機電與車輛工程學院 南昌,330013)(2.清華大學蘇州汽車研究院 蘇州,215131)
引言
近幾十年來,聲源定位一直是研究熱點,引起了眾多學者的關注。聲源定位在噪聲源識別、目標聲源跟蹤、遠程會議系統及智能機器人等諸多領域中得到廣泛應用[1-4]。聲源定位一般采用麥克風陣列來估計聲源位置。聲源定位方法可歸納為3類:①波束形成[5-6],傳統波束形成是將各個麥克風接收到的聲壓信號進行對應的延時求和,在真正的聲源方向的各個延時信號將會同相位疊加形成一個峰值,從而可以識別聲源的方向;②聲全息方法[7-8],它通過求解聲源的逆傳播問題,并重建聲場;③參數測量[9-12],如到達時差、到達時間(time of arrival,簡稱TOA)、達波方向(direction of arrival,簡稱DOA)和接收信號強度(received signal strength,簡稱RSS)等,利用獲得的定位參數構建非線性多元方程組求解,來獲取聲源位置。傳統的波束形成方法和聲全息方法都是在重建的二維聲場平面上識別聲源,為獲得精準的聲源三維位置坐標,需要進行大量的復雜運算[13]。另外,為了獲得高分辨率的聲場重構平面圖,陣列中需要大量的麥克風數量,而TDOA方法用少量的麥克風即可實現聲源定位。
對于單聲源,Chan等[14]提出兩步加權最小二乘算法,可求解出較精確聲源位置。但對于多聲源,陣列中任意一麥克風對,利用互相關算法估計的TDOA與每個聲源的關聯是未知的,從而產生虛假聲源,并降低聲源定位的精度[9]。針對這一問題,相關研究人員已經提出一些解決方法。Mukae等[15]利用檢測到的聲源信號和麥克風位置信息來構造一致性函數,通過快速搜索算法估計函數的最大值,最大值對應的位置為真實聲源位置,但該方法計算效率低,且沒有直接消除虛假聲源問題,導致的位置估計不準確。Stotts等[16]基于結構分析實現多聲源定位,該方法的計算時間隨著監測區域的增大而增加,定位精度受網格大小的影響。Shen等[17]基于凸優化方法來消除虛假聲源,消除虛假聲源的本質是向量中每列的測量值相同或者近似相同對應同一聲源。Venkateswaran等[18]采用并行和分層的方法消除虛假聲源。該方法的定位精度會受到傳播距離的影響,而且假設聲源發射的次數多,會影響計算效率。以上消除虛假聲源定位方法都存在定位精度不高和計算效率低等問題。
但佳壁[19]采用了在麥克風陣列中構造校驗麥克風,并利用校驗麥克風與聲源之間的相對位置關系,獲得真實聲源位置。然而該研究中校驗陣列麥克風未能參與聲源定位計算,降低了陣列麥克風的利用效率,多聲源的定位精度還有提升空間。在但佳壁的研究基礎上,筆者提出一種改進多聲源定位的虛假聲源消除方法。通過構建麥克風陣列分組定位校驗模型有效消除虛假聲源,獲取初始真實多聲源位置。再構建全陣列TDOA序列校驗模型,計算初始真實多聲源位置到全陣列麥克風的TDOA序列來近似匹配出全陣列正確TDOA序列。將全陣列的正確TDOA序列帶入空間聲源定位模型來獲取最終真實多聲源位置,充分利用陣列麥克風的數量來提升多聲源定位精度。仿真和實驗結果表明,本方法有效地消除了虛假聲源,同時提升了多聲源定位精度。
1 基于TDOA的空間聲源定位模型
基于TDOA方法建立了空間聲源定位模型。TDOA方法實質上是三角測量方法。假設聲源的坐標為S=(x,y,z),聲源與麥克風的距離差表達式為
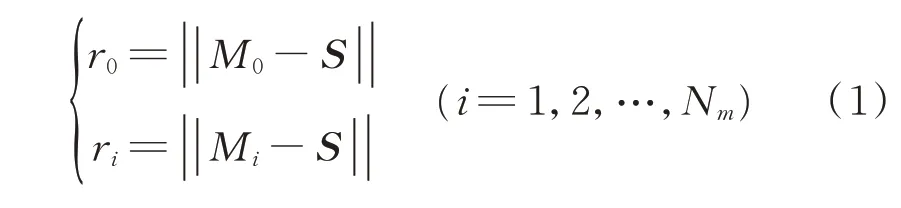
其中:r0為聲源與參考麥克風M0之間的距離;ri為聲源與其他麥克風Mi之間的距離;Nm為除參考麥克風外的其他麥克風的數量。
通過構建聲源到參考麥克風M0和其他麥克風Mi的TDOA,可以得到聲源的空間定位模型。表達式為
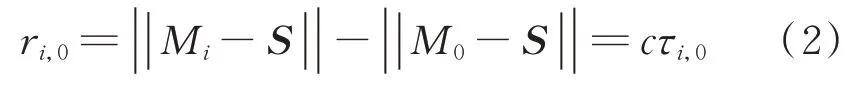
其中:c為聲速;τi,0為聲源到Mi和M0的TDOA。
τi,0可 以 用 互 相 關 算 法[20]來 估 計,設ui(t)和u0(t)分別為麥克風Mi和M0采集到的聲源信號。兩個信號之間的互相關函數為
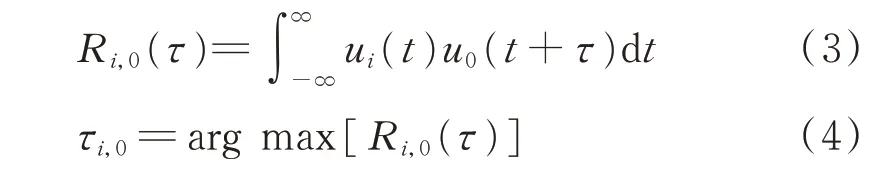
空間聲源定位模型由一組非線性多元方程組成。通常是將其轉化為線性多元方程組來求解,對式(1)中ri進行平方處理,表達式為
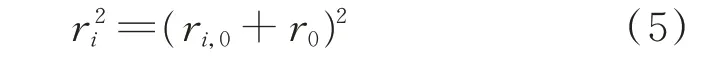
由式(4)進行展開得
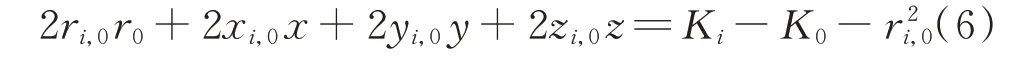
式(6)可寫成矩陣形式,如式(7)所示

當其他麥克風數量Nm=3時,理論上滿足直接求 解空間聲源位置 條 件。當Nm≥4時,Chan等[14]提出了一種精度合理、有效的求解算法,該算法使用兩次加權最小二乘法給出較準確的聲源位置。因此,文中采用Chan的方法求解來獲取聲源位置。
2 多聲源定位的虛假聲源消除方法
2.1 虛假聲源的產生原理
當只有一個聲源時,式(3)只有一個峰值,將獲取的麥克風陣列所有TDOA值可直接來定位目標聲源。當有多個聲源時,式(3)會產生多個峰值,每個峰值代表一個真實聲源信息。然而,在缺乏其他聲源特性信息的情況下,這些峰值的順序是不確定的,不能將這些峰值與聲源一一對應。兩個麥克風檢測3個聲源的混合信號的互相關估計結果如圖1所示。
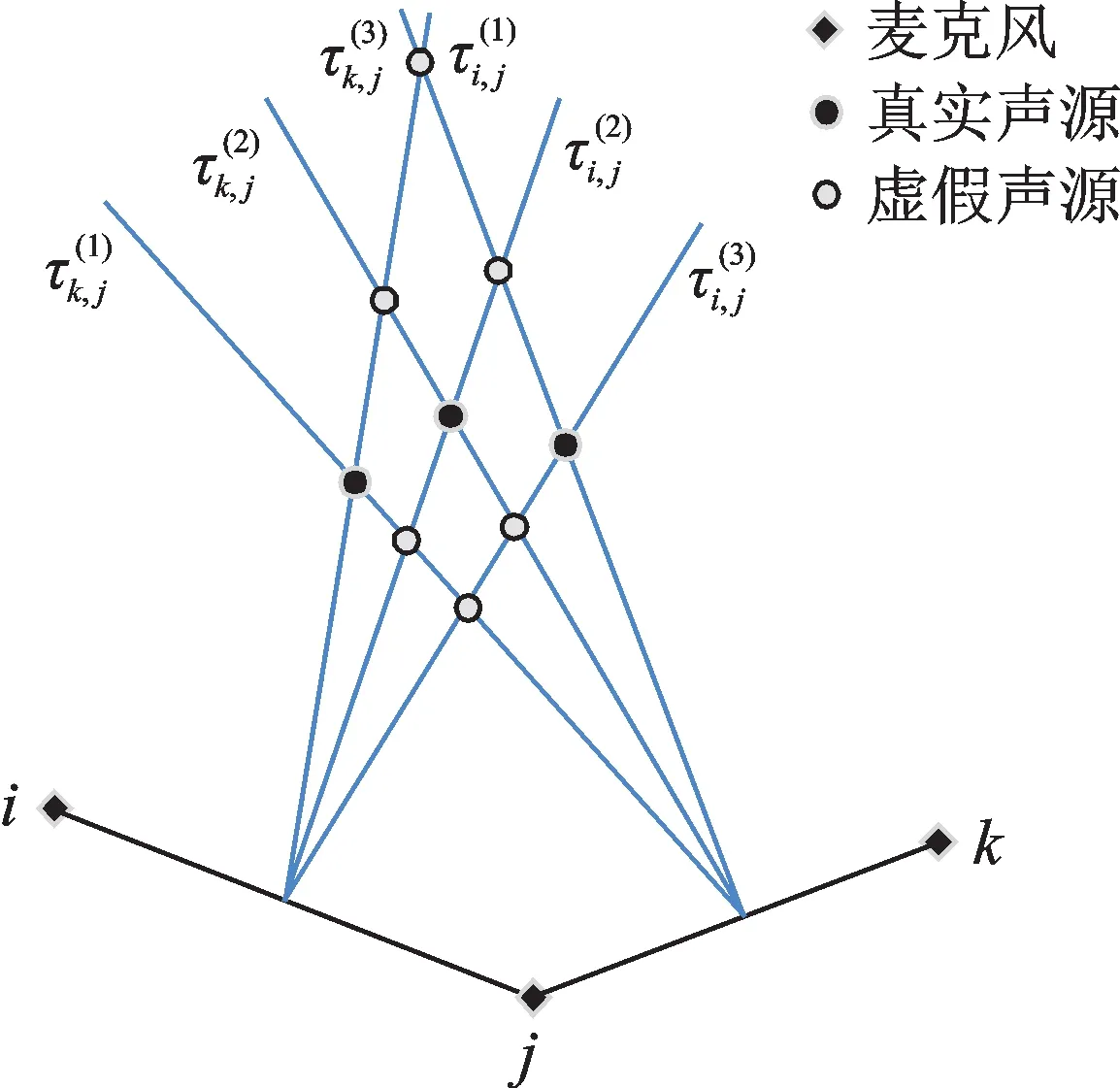
圖2 虛假聲源產生的示意圖Fig.2 The diagrammatic sketch of false source generation
從圖1可以看出,聲源數量與出現峰值的個數相等,解決本研究提出的虛假聲源消除方法過程中所需要的聲源數量先驗知識。從圖2可以看出和的組合一共生成9個聲源,其中只有3個是真實聲源,另外6個虛假聲源需要識別和消除,這也是本研究的重點。
2.2 麥克風陣列分組定位校驗模型
對于多聲源定位,可以利用聲源與麥克風的相對位置關系來分離目標聲源。本研究將陣列麥克風分為兩組。第1組麥克風用于定位多個聲源,為了減少計算量,第1組只需滿足基于Chan算法求解的陣列麥克風最小數量要求。第2組麥克風用于消除虛假聲源,通過陣列麥克風與聲源之間的相對位置關系,構建麥克風陣列分組定位校驗模型,并確定真實聲源的位置。
第1組麥克風可能的定位結果數為Np=NNms,由于計算時間隨著麥克風數量的增加呈指數增長,除了參考麥克風外,還有4個麥克風構成第1組麥克風陣列,這是基于Chan的方法能夠在三維空間中給出具有合理精度定位結果的最小麥克風數量要求。從真實聲源到第1組麥克風陣列的TDOA如式(8)所示
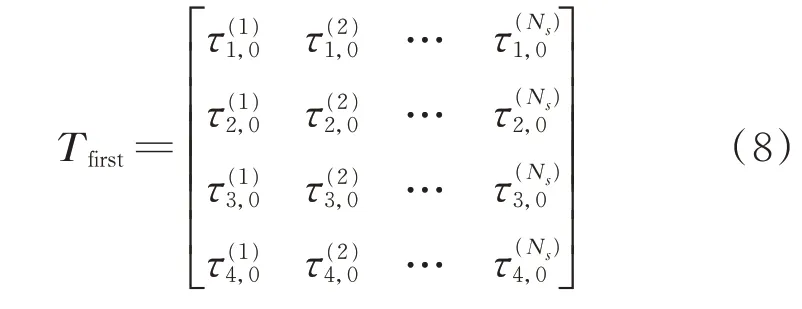
從真實聲源到第2組麥克風陣列的TDOA如式(9)所示

一個可能的聲源可以從Tfirst矩陣的每一列中選擇一組TDOA序列,再基于Chan算法求解得到。基于排列組合的知識,可以從矩陣Tfirst中得到N4s可能的聲源。所有可能的聲源都由Sp表示,即
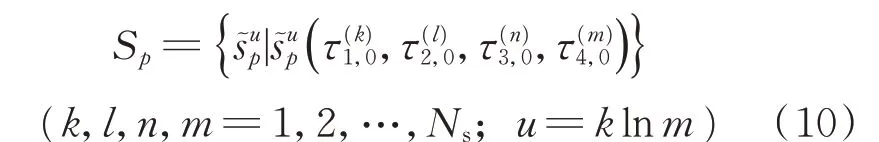
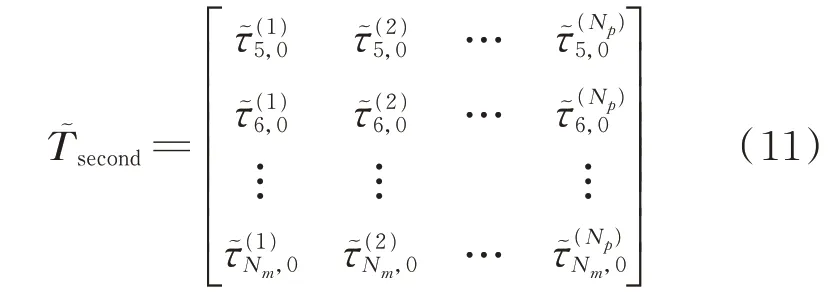
需要一個校驗矩陣來識別Np個聲源中的真實聲源。校驗矩陣的元素從矩陣Tsecond中選擇。選擇矩陣的準則定義為校驗矩陣表達式為

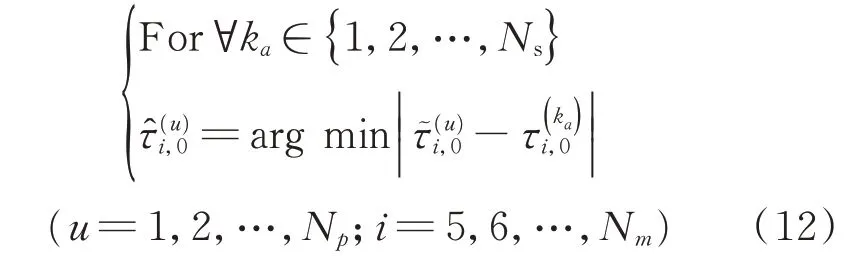
其中:UNs(u)為前Ns個u的值,代表真實聲源;ARankNs[?]表示按升序排列,并獲取前Ns個結果的函數為矩陣的列向量為矩陣的列向量為2-范數。獲得的初始真實聲源表示為
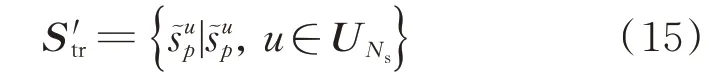
2.3 全陣列TDOA序列校驗模型
以上僅有5個麥克風用于定位來獲取初始的真實聲源,增加定位的麥克風數量會提升定位精度。文中利用初始真實聲源位置信息,構建了全陣列TDOA序列校驗模型,可以利用所有陣列麥克風來提升多聲源的定位精度。
由式(8)和式(9)可以得到,真實聲源到所有陣列麥克風的TDOA,如式(16)所示
幅流風機出風口處設置有送風格柵,幅流風機向下吹風,經過格柵進行風向的分列,用來增強吹風作用效果。扇葉長1.1 m,直徑為8 cm,蝸殼上部開設有進風口,下部平面處為出風口。蝸殼以扇葉圓柱中心線為軸做來回圓弧擺動,使得出風口的位置不斷變化,進而形成“掃風”的過程。
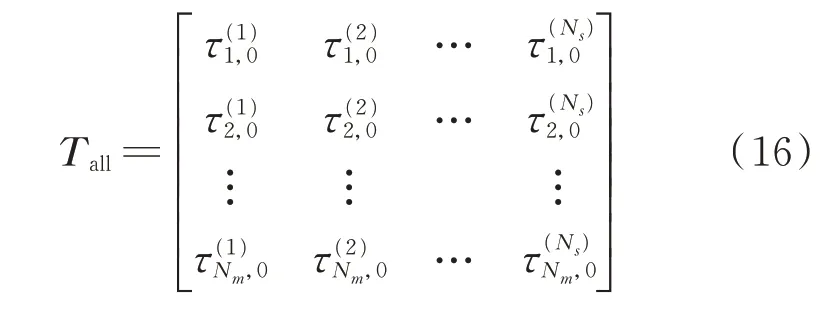
矩陣Tall中每一行元素的順序是不確定的,這就需要識別真實聲源對應的正確TDOA序列,而利用初始真實聲源位置可以識別出全陣列正確TDOA序列。初始真實聲源到所有陣列麥克風的TDOA,如式(17)所示
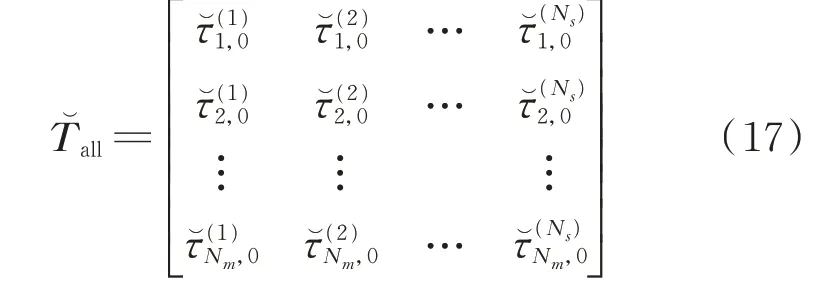
由于初始真實聲源的坐標與最終真實聲源的坐標很接近,因此可以利用矩陣T?all對矩陣Tall的每一行進行重新排序。重新排序準則如式(18)所示
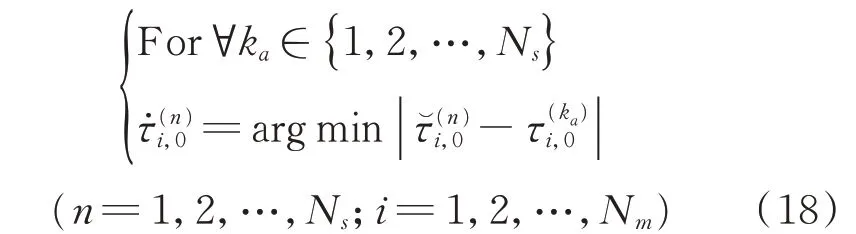
最后,獲得的最終真實聲源定位的重排TDOA矩陣為

選擇矩陣T˙all的每一列,再基于Chan算法求解可以獲得最終的真實多聲源定位結果。
3 仿真分析
3.1 定位場景和聲源信號構造
實際場景中的絕大多數音頻噪聲都是有色噪聲。為了更好地模擬實際聲源定位場景,文中采用有色噪聲來構建各種目標聲源信號。陣列幾何關系與聲源頻率特性有關[4]。對于單頻聲源定位,為了避免相位纏繞,陣列設置需要滿足以下條件:dmax<c2fsingle,其中dmax為參考麥克風與其他麥克風之間的最大距離,c為聲速,fsingle為單頻聲源的頻率。對于寬帶和脈沖聲源,可以忽略相位纏繞現象,陣列幾何關系將不受限制。文中選用麥克風陣列中的最大間距約為0.5 m,僅對單頻聲源具有頻率上限,可實現絕大部分聲源頻率特性的聲源定位。為了模擬實際聲源的復雜多樣性,不同聲源設置為不同頻帶且部分頻帶重疊。圖3為由高斯白噪聲構成的4個聲源的聲譜圖,分別由2,3,4個聲源構成3種多聲源定位場景。利用這3種多聲源定位場景,來驗證筆者提出的方法有效性。表1為3種場景中的聲源坐標位置和頻帶信息。文中一共采用8個麥克風,以建立的參考坐標系的坐標原點為參考麥克風,另選4個麥克風構建定位麥克風陣列實現多聲源定位,其余3個麥克風為校驗麥克風。麥克風陣列的坐標位置如表2所示。
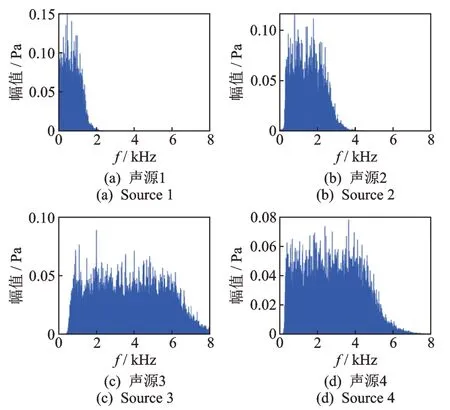
圖3 4個聲源的聲譜圖Fig.3 The spectrogram of four sound sources

表1 3種定位場景的聲源坐標和頻帶信息Tab.1 Coordinate position and frequency band in?formation of the three localization scenarios
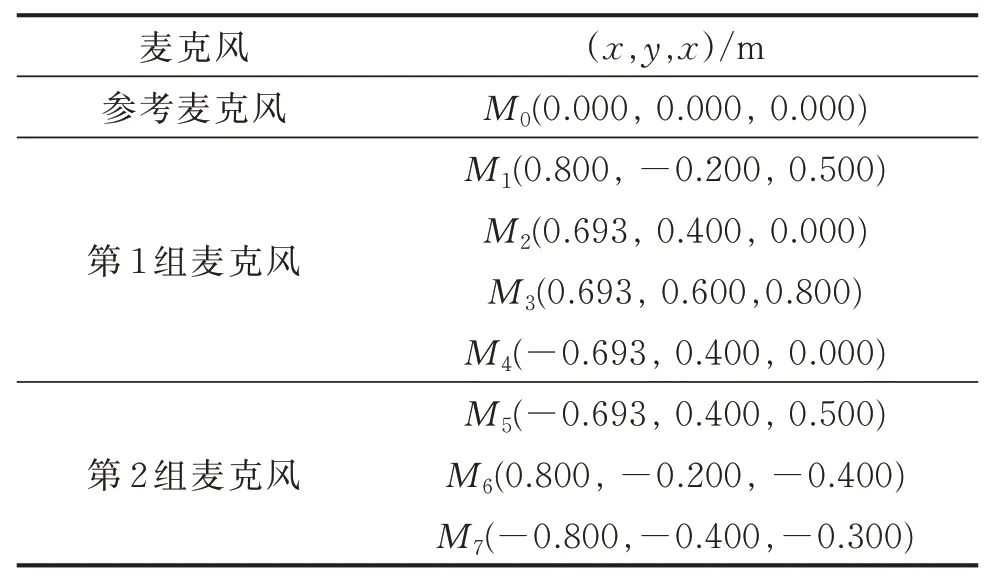
表2 麥克風陣列的坐標Tab.2 The coordinates of the array microphones
3.2 多聲源定位結果分析
3個聲源和陣列麥克風構成的定位場景如圖4所示。在某一合理噪聲水平下,分別對3種定位場景,將參考麥克風與另一定位麥克風構成的一組麥克風對,利用互相關算法估計的TDOA如圖5所示,其中圖(a)~(c)表示不同的定位場景。基于互相關算法估計所有TDOA,再利用文中提出的消除虛假聲源方法實現多聲源定位,第1組麥克風獲取的初始真實多聲源定位的結果如圖6所示,其中圖(a)~(c)表示不同的定位場景。將第1組麥克風經蒙特卡羅循環處理,目的是消除隨機噪聲對單次定位結果的影響,再利用所有陣列麥克風獲得的最終真實多聲源定位結果,與第1組麥克風的獲得初始真實多聲源定位結果進行比較,對比結果如表3所示。通過計算定位結果的平均誤差來衡量定位的精度。平均定位誤差定義為
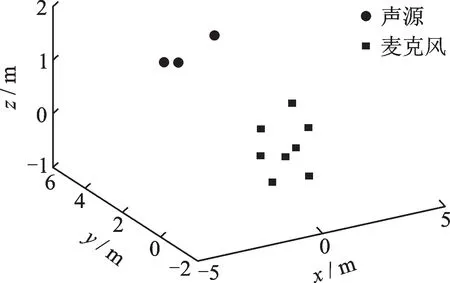
圖4 陣列麥克風和定位場景2Fig.4 Microphone array and localization scenario 2
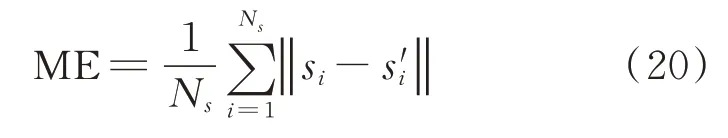
其中:ME為定位結果的平均定位誤差;si為原始聲源的坐標;s'i為定位結果的坐標。
經蒙特卡羅過程可以表示為
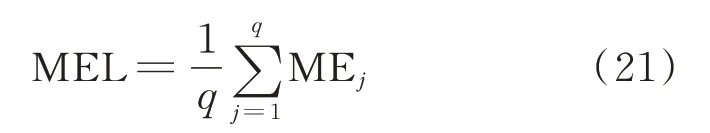
其中:MEL為經蒙特卡羅處理后的多聲源定位誤差,MEL值越小多聲源定位精度越高;q為仿真實驗過程中蒙特卡羅次數,仿真過程令q=1 000。
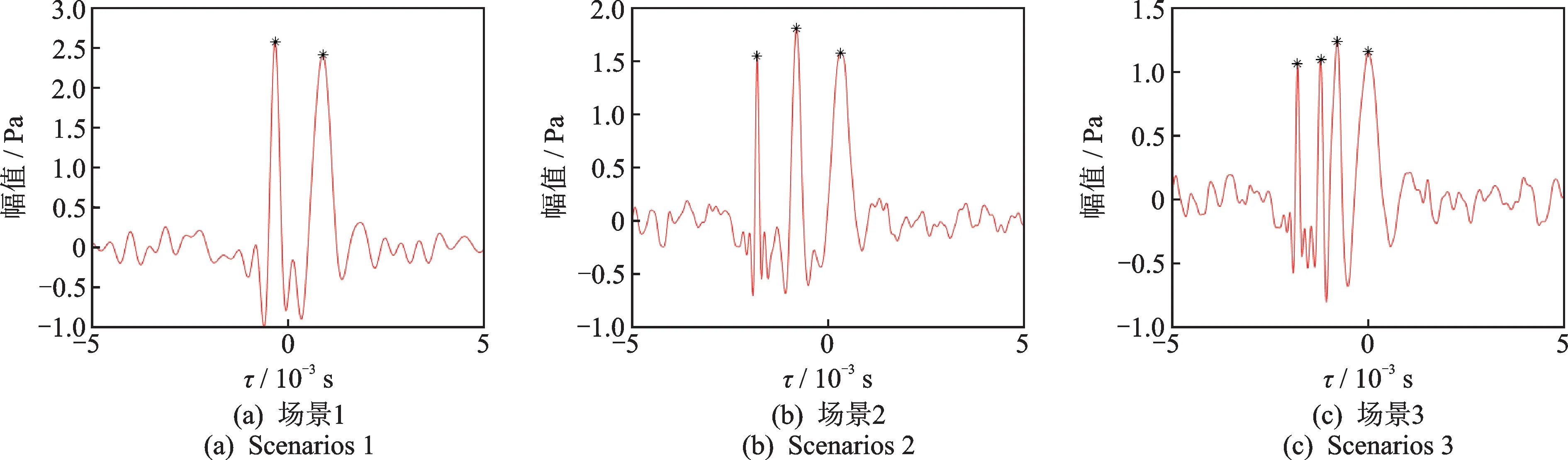
圖5 3種定位場景的互相關結果Fig.5 The cross-correlation results for the three localization scenarios
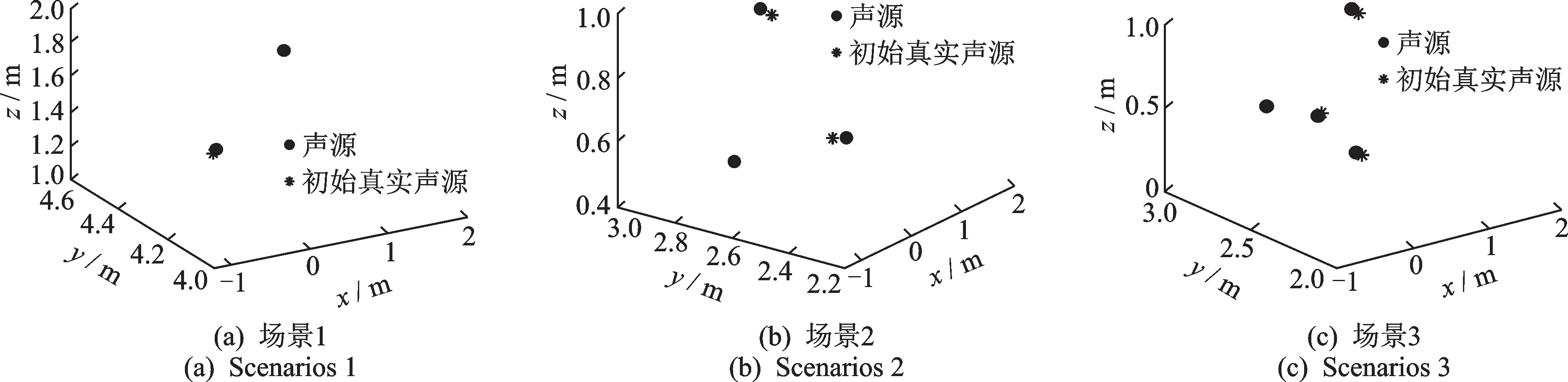
圖6 初始真實多源定位結果Fig.6 The results of initial real multi-sources localization
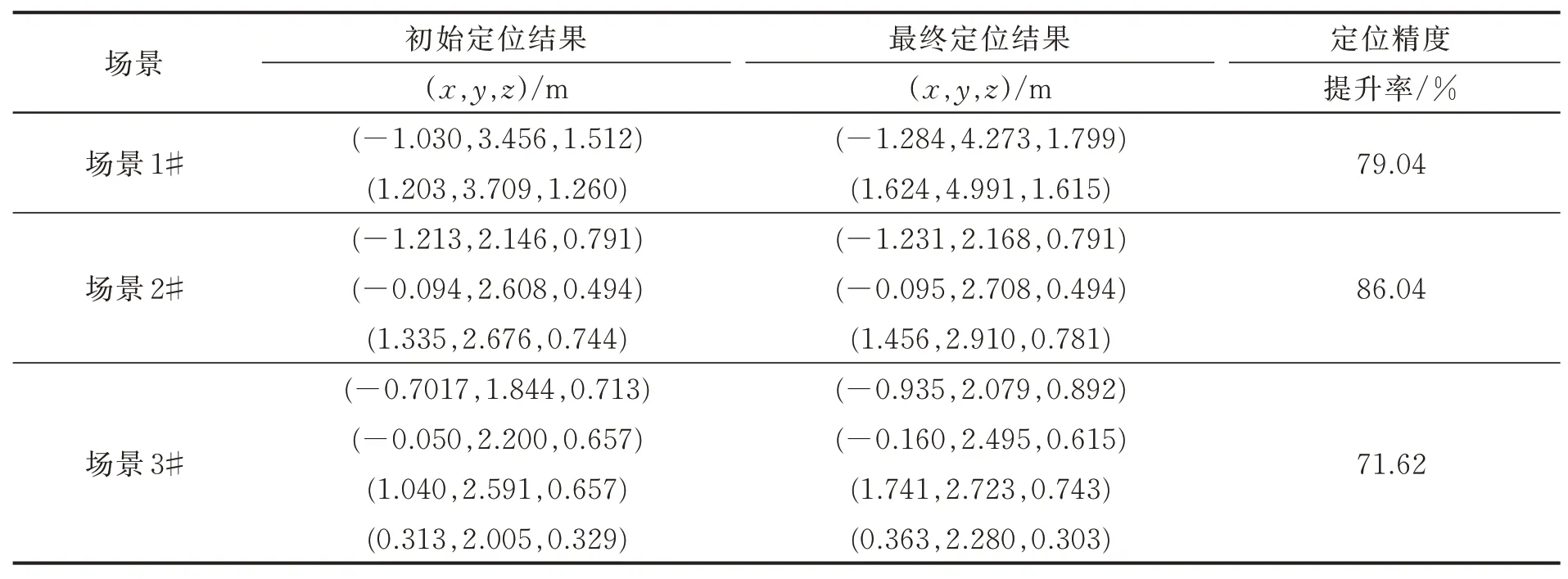
表3 定位結果對比Tab.3 The comparison of the localization results
從圖5可以看出,在不同定位場景下,聲源數量等于峰值的數量。從圖6中可以看出,3個定位場景中的多個聲源有效地分離和定位,且定位誤差合理,但是僅用5個麥克風來獲得初始真實聲源,沒有充分利用麥克風數來定位,聲源定位精度還有待提升。從表3可以看出,3種定位場景下,所有陣列麥克風參與定位計算的最終定位結果精度均大幅提升,驗證了筆者方法的有效性。
4 實驗分析
為了驗證筆者提出的基于TDOA多聲源定位的虛假聲源消除方法,在空曠的運動場上搭建實驗測試系統對筆者提出方法進行驗證。構造具有重疊頻帶的不同聲源信號,所有聲源的頻帶范圍為300~1 650 Hz,將構造聲源信號的音頻文件導入至揚聲器播放。整個實驗過程中忽略風速,設置聲速c=343 m/s。實驗麥克風及聲源位置如表4所示,在聲源s1~s4中分別選擇前2個、前3個和前4個,構成定位場景1、場景2和場景3。實驗過程的采樣頻率fs=10 kHz。實驗場景由聲源、信號采集裝置和麥克風陣列三部分組成,如圖7(a)~(c)所示。圖8是對前5個麥克風通道經傅里葉變換獲得的頻譜圖,其中圖8(a)~(e)表示每個通道的圖譜圖。將每個麥克風檢測的信號利用互相關算法估計出TDOA,并基于Chan算法求解出所有可能聲源位置,再利用校驗麥克風與聲源的空間位置關系來消除虛假聲源,得到初始的真實聲源位置,定位結果如圖9所示,其中圖9(a)~(c)表示不同的定位場景。圖10是在3種定位場景下,本方法獲得的最終真實聲源與初始真實聲源的平均定位誤差對比。
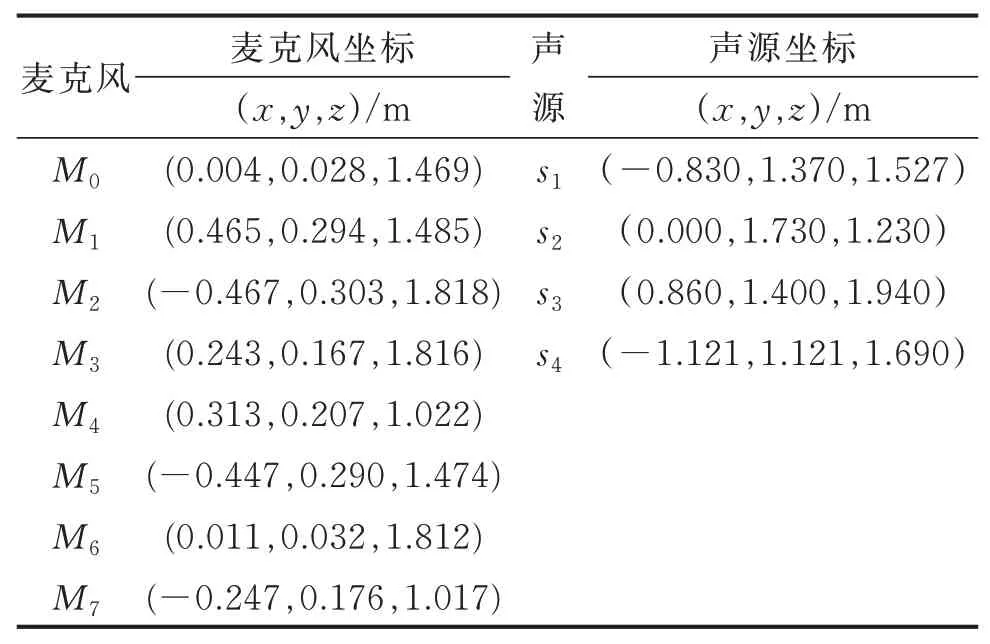
表4 陣列麥克風和聲源空間位置坐標Tab.4 The coordinates of the array microphones and sound sources
圖7 實驗場景Fig.7 The experiment scene
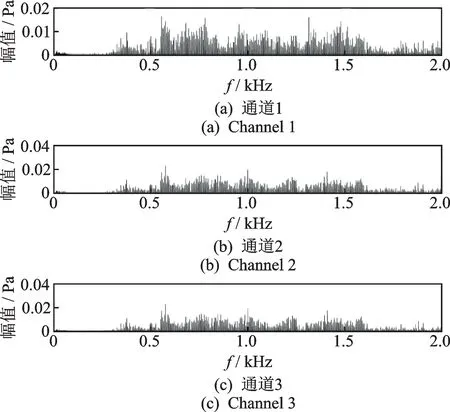
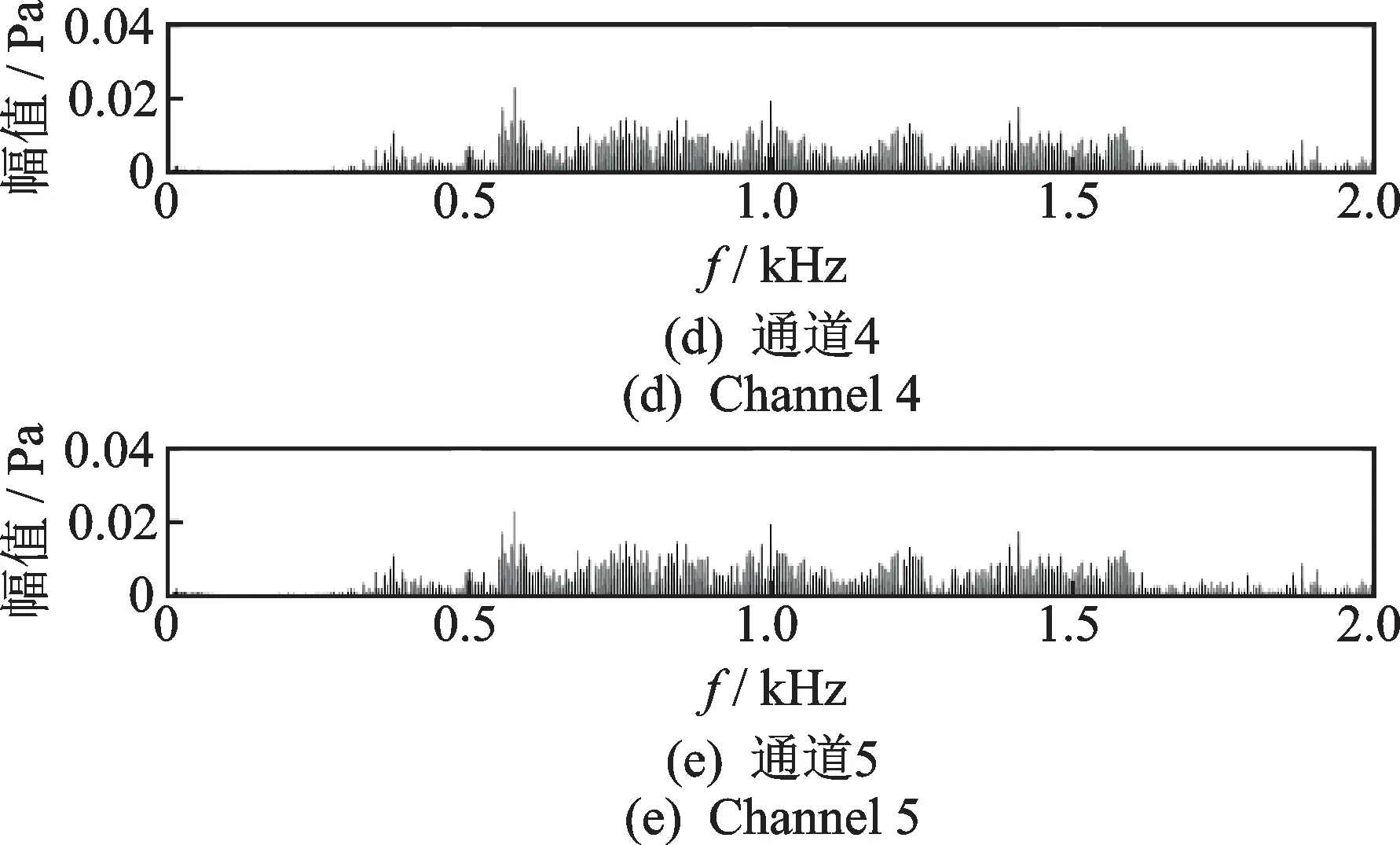
圖8 前5個麥克風通道經過傅里葉變換后的頻譜圖Fig.8 Spectrum of the first five microphone channels after Fourier transform
由圖8可以看出,檢測的聲信號主頻帶在300~1 650 Hz之間,測試環境存在背景噪聲。從圖9可以看出,本方法成功消除了虛假聲源,實現了多聲源定位,且定位誤差合理。從圖10可以看出,在不同的定位場景下,本方法獲得最終真實聲源位置相比初始真實聲源位置的平均定位誤差均有所減小,本方法提升了多聲源定位精度,實驗與仿真結論一致。然而,實驗過程中存在麥克風位置測量誤差的影響,而且聲源和陣列的相對位置與仿真有所不同,因而本方法在實驗驗證中的定位精度提升率比仿真稍有下降。
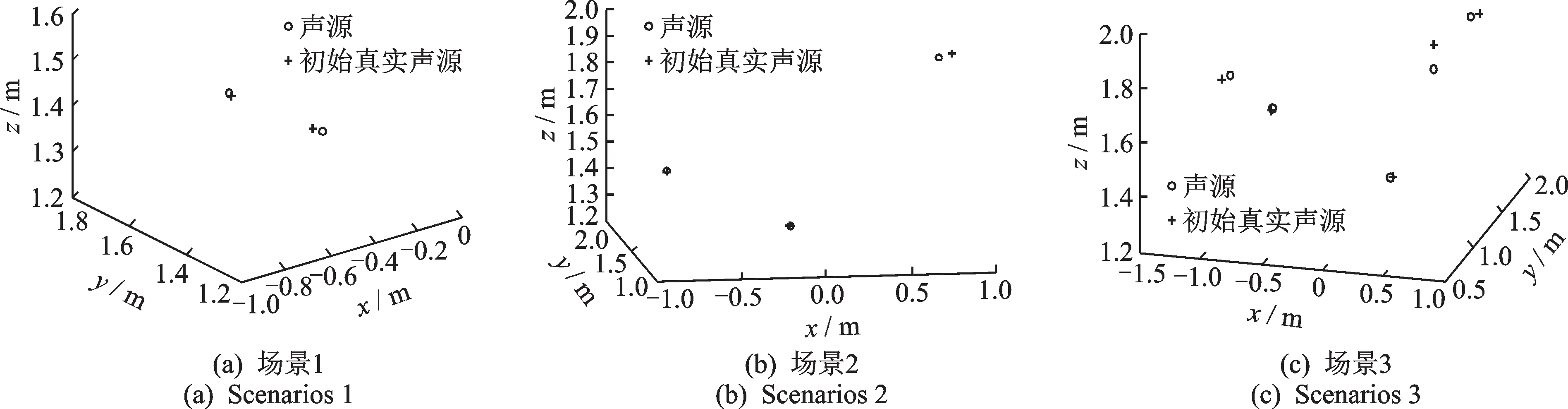
圖9 本方法獲取的初始真實聲源的實驗定位結果Fig.9 The experimental results of the initial real sound source obtained by the proposed method
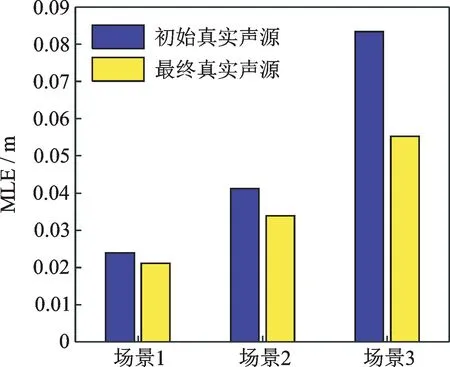
圖10 不同場景下最終真實聲源位置與初始真實聲源位置的平均定位誤差對比Fig.10 Comparison of the average positioning errors between the final real source position and the initial real source position under different scenarios
5 結論
1)利用麥克風陣列分組定位校驗模型有效地消除了虛假聲源,實現多聲源分離和定位。
2)利用全陣列TDOA序列校驗模型獲得的最終真實多聲源平均定位誤差比分組定位校驗模型獲得的初始真實多聲源平均定位誤差更小。本方法充分利用了陣列麥克風,并有效提升了多聲源定位精度。
3)文中多聲源定位方法的實驗驗證僅在空曠的測試環境下進行,該場景混響和其他干擾噪聲影響較少;同時僅實現近場多聲源定位。今后可研究存在麥克風位置誤差以及遠場和復雜噪聲環境下的多聲源定位方法。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
