融合神經網絡與矩陣分解的旅游景點推薦模型
2021-04-28 00:49:14鄭吟秋汪弘揚陳建峽
湖北工業大學學報 2021年2期
鄭吟秋, 汪弘揚, 程 玉, 陳建峽
(湖北工業大學計算機學院, 湖北 武漢 430068)
近年來旅游業發展快速,旅游景點的數量與網絡上關于旅游信息愈發繁多,導致用戶決定景點的過程變得復雜與低效。而好的旅游景點推薦服務可以給用戶推薦符合其興趣偏好的景點,從而提高用戶決定景點的效率,同時也提升用戶的出游滿意度。景點所屬類型易于區分,且類型相似的用戶對旅游景點會呈現出非常類似的喜好,因此,實現景點推薦的一個直觀思路就是基于用戶群與景點群的“相似性”,充分利用用戶的偏好與景點的內在關聯實現推薦模型。
在推薦系統方面,已有的代表性工作主要分為傳統模型的研究與深度學習模型的研究。時至今日,傳統推薦模型憑借其訓練速度快、可解釋性強等特點依然得到較為廣泛的使用,但傳統模型所執行的簡單操作并不能充分滿足人們對推薦模型效果的追求。目前,隨著深度學習技術的持續發展及其在多種領域取得的巨大成功,研究者也把深度學習應用到推薦系統中。神經網絡模型具有較強的擬合能力,隨著深度學習技術的發展與算力的提升,現有模型的網絡層數不斷加深,表達能力也越來越強,從而可以挖掘更多數據中隱藏的模式。近年來深度神經網絡在推薦系統領域有兩種應用方式:一是作為傳統推薦算法的輔助,利用神經網絡對用戶和物品的輔助信息進行建模;二是將神經網絡作為推薦模型中的核心板塊,利用神經網絡構建模型,為用戶推薦感興趣的物品。
針對旅游進行推薦模型研究的思路主要有兩種: 排序模型和序列推薦。李廣麗等在2019年提出基于混合分層抽樣統計與貝葉斯個性化排序的推薦模型[1],綜合用戶旅游喜好信息及BPR優化結果,生成混合推薦列表,取得了較好的結果。同年, 張堯舜等人使用基于序列學習的旅游景點推薦[2],分析游客的旅游軌跡信息來為游客作出個性化的旅游景點推薦,解決了傳統推薦中的冷啟動、數據稀疏、忽略旅游軌跡中高級語義和推薦準確度低的問題。
本文圍繞旅游景點推薦問題展開研究,根據問題背景和數據類型,使用了Tr-DNNMF模型來捕獲用戶和景點數據中的有用信息。該模型基于旅游場景,融合了神經網絡和矩陣分解這兩種被廣泛使用的模型,以期望獲得更好的景點推薦效果,并為用戶提供能滿足其興趣偏好的智能推薦服務。
1 相關工作
1.1 協同過濾算法簡介
協同過濾算法是最經典、影響力最大的傳統推薦算法,它根據用戶的歷史行為記錄進行推薦,核心是基于用戶-物品的交互記錄構造用戶-物品評分矩陣,矩陣中已知的元素就是對應的用戶給物品的評分,這個評分矩陣非常稀疏,協同過濾要做的就是基于評分矩陣中已有的元素來預測未知元素的評分,根據預測分數進行降序排序,將前面的物品推薦給用戶,協同過濾算法流程見圖1。
協同過濾的關鍵是計算相似度,主要使用余弦相似度公式、Jaccard公式、皮爾遜相似度等方式計算,根據對象不同可分為基于用戶的協同過濾和基于物品的協同過濾。在協同過濾算法的基礎上延伸出矩陣分解(MF)[3]算法,該算法可在一定程度上解決協同過濾算法存在的稀疏性問題,并且具備較好的擴展性。從直觀上看,矩陣分解是把評分矩陣近似分解成兩個向量的乘積,分別表示用戶向量和物品向量,它們代表了用戶的偏好與物品被關注的因素。在矩陣分解中,用戶向量與物品向量的內積就是該用戶對該物品評分的預測。
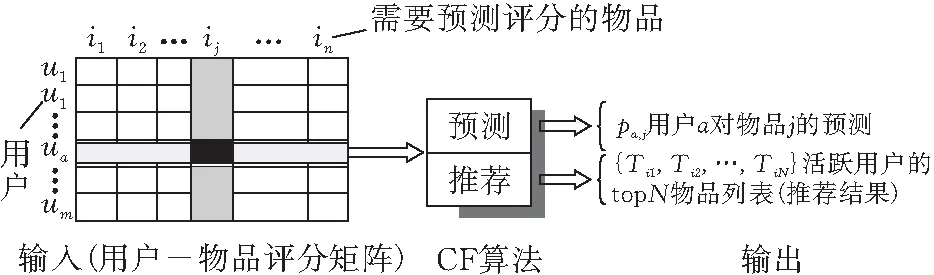
圖 1 協同過濾算法流程圖
盡管協同過濾和矩陣分解算法非常直觀,易于理解,但它們分別利用稀疏的評分矩陣與內積操作進行得分預測,因此模型的泛化能力與表達能力都不夠強,如果面對歷史行為很少的用戶,就沒法產生準確的推薦結果。盡管如此,憑借其特性,在深度學習流行的今天,這類傳統協同過濾推薦模型為深度推薦模型的發展奠定了堅實的基礎。
1.2 基于深度學習的推薦算法
近年來,各大互聯網公司逐漸將深度學習運用到自己的推薦業務中。實際上,深度學習是通過加深神經網絡的層數,使模型有更強的表達能力,能更好地提取特征,挖掘更多數據中隱藏的模式。隨著深度學習技術的演進與算力的提升,深度學習在推薦系統領域的應用出現了兩種趨勢:要么以傳統推薦算法為核心,僅用神經網絡對用戶和物品的文本、圖片信息進行建模;要么把神經網絡作為推薦模型的核心板塊,通過訓練為用戶推薦感興趣的物品。由于深度學習模型的結構靈活,可根據實際場景和數據特點調整結構,因此基于深度學習的推薦系統是發展持續火熱的方向之一。
最簡單的神經網絡推薦模型是AutoRec[4],只有一個隱藏層,是在協同過濾的基礎上加入了自編碼器的思想,有一定的泛化能力。AutoRec模型和Word2Vec模型的結構一致,但優化目標和訓練方法不同。AutoRec利用協同過濾中的用戶-物品共現矩陣,完成物品向量或用戶向量的自編碼。再利用自編碼的結果預估用戶對物品的評分。進一步加深網絡層數后,出現了以微軟Deep Crossing[5]為代表的深度推薦模型。Deep Crossing模型的結構是典型的嵌入加多層神經網絡的模式,該模型首先用embedding層將稀疏特征轉化為低維稠密特征,用stacking layer連接分段的特征向量,再通過多層神經網絡完成特征的組合與轉換,最終用scoring layer進行計算。
1.3 深度推薦模型的改進思路
深度學習推薦模型的主要進化思路有改變特征交叉方式與改變模型組合方式。前一種以PNN[6]模型(Product-based Neural Network)為例,該模型的關鍵是,在embedding層和全連接層之間加入Product layer,其中product操作在不同特征域之間進行特征組合,增加特征交叉和特征組合時對信息表達的針對性。此外,PNN還定義了內積、外積等操作來捕捉不同的交叉信息,增強模型表征不同數據模式的能力 。
改變模型組合的代表是Google的Wide&Deep[7]模型、華為的DeepFM[8]模型。Wide&Deep模型把單輸入層的Wide部分和經過多層感知機的Deep部分連接起來,一起輸入到最終的輸出層。其中,單層的Wide部分讓模型具有記憶性,從而處理大量稀疏的ID類特征,即記住用戶的大量歷史信息,Deep部分則利用DNN強大的表達能力,挖掘特征內在的數據模式,讓模型具有泛化性。最終再利用LR輸出層組合Wide部分和Deep部分。
DeepFM是在Wide&Deep的基礎上,用FM部分替換原來的Wide部分,增強淺層網絡進行特征組合的能力。FM部分由一階和二階特征交叉的計算組成,DeepFM是通過同時組合原來的Wide部分、二階特征交叉部分和Deep部分這三種結構,來進一步增強模型的表達能力。Wide&Deep模型影響力巨大,是因為很多深度學習推薦模型采用了兩個、甚至多個模型組合的形式,利用不同網絡結構的特性挖掘不同的信息并進行組合,這樣就充分利用了不同網絡的優勢,有助于提升模型的推薦效果。
2 TR-NeuMF推薦模型
本文使用的景點推薦模型Tr-DNNMF(Trouism Recommendation Based on Deep Neural Network Matrix Factorization)基于神經協同過濾(Neural Collaborative Filtering, NCF)框架[9],該框架的思路是把模型分成用戶側和物品側兩部分,再使用互操作層把這兩部分聯合起來,產生最終的預測得分。下面根據Tr-DNNMF模型流程圖(圖2)與Tr-DNNMF模型的結構圖(圖3)詳細闡述本文的工作流程、模型的具體結構及訓練細節。
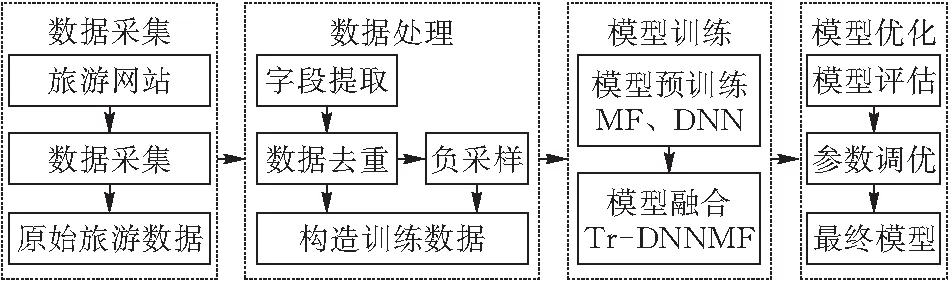
圖 2 Tr-DNNMF模型流程圖
2.1 數據預處理
首先對采集到的原始景點數據進行預處理:提取并保存用于訓練模型的主要字段,然后對數據進行去重、去異常數據等清洗工作。根據相應的訓練集格式構造訓練數據文件,再通過負采樣操作給模型提供從隱式數據中進行學習的負樣本,最后得到了用戶-景點交互數據和負采樣數據。通過數據處理階段,可以改善數據的質量,并對數據的分布和相關信息進行初步探索,有助于后續建模的過程。
2.2 模型結構
Tr-DNNMF模型基于神經協同過濾框架,對用戶-景點的歷史交互數據進行訓練。首先,分別在旅游數據上訓練廣義矩陣分解模型(GMF,Generalized Matrix Factorization)和多層感知機模型(MLP,Multi-Layer Perceptron),然后把這兩個模型最后一層的特征串聯起來,將MF(Matrix Factorization)的線性和DNN(Deep Neural Networks)的非線性相結合,對用戶-景點的潛在結構進行建模,使模型既具備良好的擴展性,又有強大的擬合能力。Tr-DNNMF模型原理見圖3。
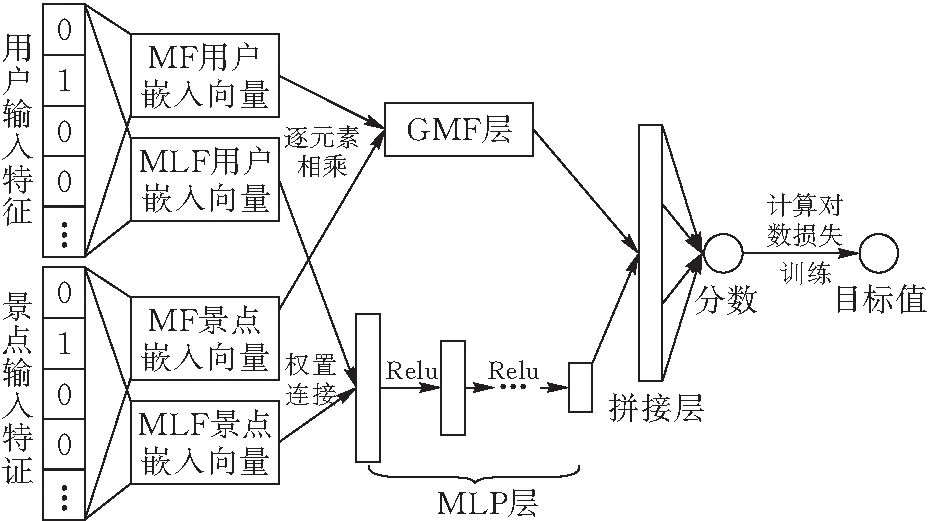
圖 3 Tr-DNNMF模型結構圖
Tr-DNNMF模型中的MF結構可作為NCF框架下的一個特例,用戶和景點的One-hot編碼在經過嵌入層之后會分別生成用戶和景點的隱向量,之后在GMF層中逐元素計算用戶隱向量與景點隱向量的內積,在輸出層使用sigmoid激活函數和對數損失函數。MLP結構使用了多層神經網絡,在學習用戶和景點潛在特征之間的交互時,在拼接的向量上添加隱藏層,使得模型具備較強的靈活性和一定的非線性,以解釋用戶和景點潛在特征之間的交互,增強了用協同過濾建模的能力。Tr-DNNMF模型的內容可定義為公式(1)~(3):
(1)
式(1)為GMF部分通過計算用戶u的隱向量和景點i的隱向量的內積,以得到推薦得分
(2)
式(2)為MLP部分通過多層神經網絡從用戶-景點數據中學習交互函數,最終得到預測分數。
(3)
式(3)為Tr-DNNMF模型最終通過拼接層得到GMF和MLP的融合模型預測結果。
為讓融合模型獲得更多的靈活性,Tr-DNNMF模型中GMF和MLP先各自學習單獨的嵌入,而不是使用共享的嵌入,如此可以避免共享GMF和MLP的嵌入向量對模型融合性能的限制,然后通過連接它們的最后一個隱藏層將這兩個模型結合起來。
2.3 模型訓練
Tr-DNNMF模型從零開始訓練GMF和MLP,采用了Adam算法,通過對頻繁的參數進行較小的更新和對不頻繁的參數進行較大的更新,動態地改變每個參數的學習率。與原始SGD相比,這兩個模型使用Adam的收斂速度更快。在給Tr-DNNMF模型輸入預先訓練好的參數后,使用原始的SGD,因為Adam需要保存動量信息,以便正確地更新參數,而Tr-DNNMF模型只使用預先訓練好的模型進行參數初始化,不保存動量信息,故不適合使用基于動量的方法來進一步優化Tr-DNNMF模型。模型的輸出層使用ReLU作為激活函數,使模型輸出的預測分數表示用戶和景點相關的概率,然后通過對數損失函數計算真實值與預測值的損失,進行參數更新。
Tr-DNNMF模型采用point-wise方法學習模型參數,使用的損失函數為平方損失的回歸函數。由于Tr-DNNMF模型的目標函數是非凸的,基于梯度的優化方法只能找到局部最優解,因此初始化對模型的收斂和性能起著重要作用,采用隨機初始化。由于Tr-DNNMF模型是GMF和MLP的結合,本文使用GMF和MLP的預訓練模型來初始化Tr-DNNMF模型。首先對GMF和MLP進行訓練直到收斂。然后把它們的模型參數作為Tr-DNNMF模型相應部分參數的初始化。在輸出層連接兩個模型的權值,此過程中需通過對超參數的調整來決定兩個預訓練模型之間的權衡。
3 實驗與分析
3.1 實驗數據
本文使用的用戶評分數據來自攜程網,進行了數據預處理。用戶評分數據包含4999條用戶-景點交互記錄,每行的格式為(用戶ID,景點ID,用戶評分,時間戳),見表1,數據稀疏度為0.0189%,由于模型是從隱式數據中學到交互數據中用戶與景點的關聯性,故模型不會利用真實的評分,而是通過把交互樣本被標記為0(負樣本)或1(正樣本)來構建訓練數據,進行后續訓練過程。
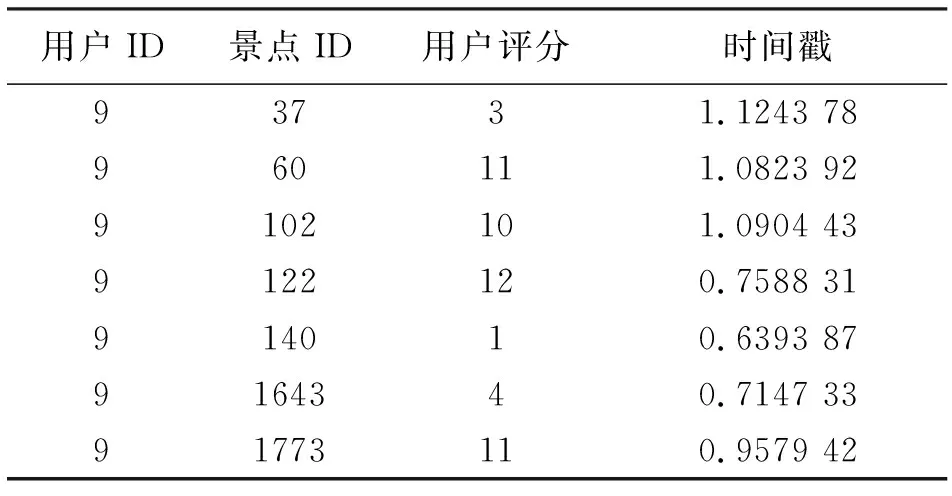
表1 景點交互數據示例
3.2 實驗設置
本文使用MLP、GMF和Tr-DNNMF這三種模型實現了對用戶-景點交互數據的建模,前兩種模型使用小批量Adam優化方法,針對Tr-DNNMF使用了隨機梯度下降算法。Tr-DNNMF模型的參數及數值見表2,其中模型的預測因子(factor number)為模型最后一層隱藏層的神經元個數。表2是三種模型在HR@10和NDCG@10指標上的對比,實驗結果表明模型融合后的性能更好。
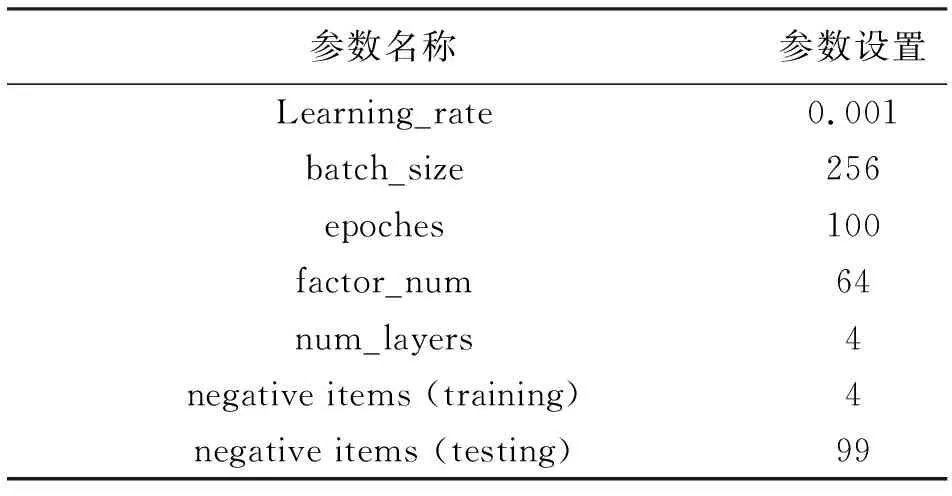
表2 實驗參數設置
3.3 評價指標
本文使用了命中率(HR)、歸一化折損累計增益(NDCG)作為評估模型性能的評價指標,并將這兩個指標的排名都設置為10。在實驗中,每個測試用戶計算了這兩個指標的平均值。HR是目前TOP-N推薦研究中十分流行的評價指標,能夠很直觀地衡量測試景點是否出現在前10名的景點列表中。HR的計算見公式(4):
(4)
其中#users是用戶數,#hits是測試集中的item出現在Top-N推薦列表中的用戶數。
NDCG通過給排名靠前的熱門景點分配更高的分數來說明熱門景點的位置,它在折損累計增益(DCG)的基礎上進行歸一化處理,取值在0-1之間。DCG假設相關度高的結果排在前面,高分的相關性更高,DCG與NDCG的計算分別見公式(5)和公式(6)。
(5)
(6)
其中,reli表示排在第i位的商品用戶是否喜歡(值為1是喜歡,為0是不喜歡),p是推薦列表長度,iDCG是理想情況下的值。
3.4 實驗結果
本文在建模用戶-景點交互數據時,對factor_num和num_layers等參數進行了參數調優過程。實驗了factor_num為[8,16,32,64]的情況和num_layers為[3,4,5]的情況,當factor_num取值為64,num_layers取值為4時模型性能較好。如果factor_num取值過大會導致模型過擬合。模型在該參數配置下的實驗結果見表3。

表3 基于交互數據推薦的實驗結果
實驗結果表明Tr-DNNMF模型比MLP模型的NDCG@10提高了7%,HR@10提高了0.5%,比GMF模型的NDCG@10提高了37%,HR@10提高了38%。
4 結論
根據景點推薦問題實現了Tr-DNNMF模型,詳細介紹了模型結構與訓練流程。本文用該模型在用戶對景點的交互數據上進行了大量實驗,并與單模型進行推薦性能的對比測試。實驗結果表明,Tr-DNNMF模型具有良好的景點推薦效果,與單模型相比,性能有較大的提升。為進一步提升景點推薦的效果,可從以下三個方面考慮:1)利用時間(如不同季節、節日效應),地理環境等多種上下文信息進行訓練,實現不同類別景點的推薦權重的智能調節,推薦更滿足用戶需求的景點;2)除了用戶評分數據,模型還可以利用包括景點圖片和景點描述文本的輔助信息,構建更適合旅游場景的模型;3)利用圖嵌入和基于鄰域的推薦算法,進一步提升模型在高稀疏度數據上的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
