基于圖神經網絡和異構信息的興趣點分類
2021-04-25 05:22:56任成森楊易揚郝志峰
現代計算機 2021年6期
任成森,楊易揚,郝志峰,2
(1.廣東工業大學計算機學院,廣州510006;2.佛山科學技術學院,佛山528225)
0 引言
近年來,隨著移動智能終端的普及,用戶的注意力從固定設備轉移到掌上移動設備,并隨著3G、4G 網絡的普及,眾多移動應用開始推出可以記錄用戶位置的地理位置、興趣點推薦的應用,例如美團、餓了么、支付寶口碑。為了給用戶推薦更合適的興趣點,進而帶動該地點的消費,眾多企業和研究團隊都花費了大量的精力研究基于地理位置的各種應用。其中,興趣點分類是眾多下游應用的基礎。大公司能夠利用雄厚的財力來推廣并獲取海量的用戶評論信息,能夠簡單地在大數據的基礎上將興趣點分類轉化為文本分類,再加上足夠的興趣點標注預算,使得普通的文本分類模型也能進行精準分類。但這些數據和模型都是閉源的,新公司、新研究團隊無法在有限的條件下快速實現能夠適合生產的興趣點分類模型。在這個背景下,如何在已有數據和有限標注成本的情況下,提高興趣點的分類成為了研究重點。為了達到這個目的,我們需要解決以下問題:如何充分利用興趣點的已有信息?
圖卷積神經網絡(Graph Convolutional Networks,GCNs)[1]作為一個半監督學習框架,在不規則場景獲得了大量的關注。在眾多的領域獲得了大量的應用[2],如自然語言處理[3]、計算機視覺[4]、網絡分析[5]等等。對于深度神經網絡來說,復雜的結構往往能夠帶來準確率上的提升。而復雜結構的GCN 卻會引入新的問題:領域指數增加[6]。也就是說,假設要計算第L 層的一個節點的損失值,則需要獲得第L-1 層的k 個節點(k 為鄰接節點的數量,且每個節點的k 值都不固定),如此類推到更多的網絡層上,這就意味著隨著GCNs 的迭代網絡層的增加,計算量也會成倍地增加,但模型預測效果反而降低。特別是在興趣點這一類包含大量節點的任務中,深層的GCNs 網絡并不適用,但GCNs 能夠利用興趣點之間的關聯信息,是一種很強大的特征融合/傳播工具。
除了網絡層的深度,有不少研究在圖結構上對GCNs 進行了進一步擴展。文本圖卷積網絡(Text Graph Convolutional Networks,TextGCN)[7]就是從節點類型來擴展GCNs 的模型,它把文本和單詞分別視為不同類型的節點,從而有兩種類型的邊:文本-單詞,單詞-單詞。前者的權重是通過詞頻-逆文本頻率指數(Term Frequency-Inverse Document Frequency,TF-IDF)來計算,后者則是通過點互信息(Pointwise Mutual Infor?mation,PMI)給出。不同類型的兩種節點和邊整合到一個圖上,從而融合了異構信息,這就考慮了,進而使用GCNs 來處理。這種擴展了信息融合的維度,同時考慮了單詞節點之間的共現信息和文本-單詞之間類主題信息。本文模型借鑒了TextGCN 的文本-單詞結構,構建出興趣點-單詞(來自評論文本)的異構網絡。但原始的TextGCN 并直接應用在興趣點上并不合適,而且會導致性能上的損失。
所以本文所提出的模型基于GCNs,并通過構建興趣點-興趣點、興趣點-評論單詞之間的連接,得到一個高魯棒性的圖網路結構,即保證了特征的高效融合/傳播,也保證了與基準模型相近的準確率,甚至在Macro-F1 評價標準上超出了基準模型。本文的主要貢獻如下:
(1)將興趣點分類任務轉化為節點分類任務,利用興趣點和評論文本之間的單詞關系,構建興趣點-單詞異構網絡,并通過實驗證明TextGCN 在興趣點分類任務上的性能差異,使得原本只適用于文檔分類的模型改造成適合興趣點分類的模型。
(2)利用興趣點的名稱,構建興趣點之間的相似性,使得模型在保證其準確率不下降的情況下,大幅降低其訓練速度。
(3)在現實世界的真實數據上的兩個城市進行測試,并在不同的參數下測試了其魯棒性,證明了本文算法的有效性。
1 算法
本節將給出具體的算法實現步驟,分別為異構圖網絡的構建和模型的構建。
1.1 異構圖網絡的構建
給定n 個興趣點,每個興趣點有諾干篇評論。通過匯總評論進行清理和切割,獲得m 個單詞。把這n興趣點和m 個單詞視為異構圖網絡中兩種節點,其中該圖網絡的總節點數為|V|=n+m,其節點特征為單位矩陣。也就是說單個節點時,其特征只考慮自身,所以其對應的特征向量設置為獨熱編碼。本文的任務就是要將這n 個興趣點分成c 類。
其中興趣點和單詞之間的邊的權重由使用TFIDF 算法來計算,這部分和TextGCN 類似。我們在實驗中發現,TextGCN 中的單詞-單詞之間的邊,在新聞、疾病文摘這一類中等長度的文本語料上會幫助Text?GCN 提高效果,但是其在短文本和超長文本上,則效果式微。表2 中的對比實驗也展示了其在興趣點分類上的效果,在不考慮單詞-單詞之間的邊的情況下,準確率、Macro-F1 下降幅度有限,但大幅降低了訓練時間。所以本文不考慮傳統的單詞-單詞結構連接。
雖然在單詞-單詞之間的邊帶來的提升效果有限,但去除了卻會導致模型略微的降低。本文考慮了興趣點信息的多樣性,利用興趣點名稱作為信息來源之一來考慮。雖然興趣點名稱廣義上也屬于文本數據,但其來源不同、結構各異,所以并不能上面處理評論數據的方法來處理興趣點名稱。
本文先統計興趣點名稱中的單詞詞頻,把少于2次出現的單詞去除,同時也把單詞長度少于2 個字符的單詞也刪除。這主要是因為只出現過一次的單詞,對興趣點之間的相似性并沒有積極作用,反而會加大單詞列表提高計算成本。構建了興趣點名稱單詞列表后,將把每個興趣點構建其名稱的獨熱編碼。有了名稱獨熱編碼,通過計算兩兩興趣點的名稱獨熱編碼的余弦相似性,構建興趣點和興趣點之間邊,其核心思想在于興趣點名稱中有相似單詞的,會認為具有一定的業務相似性,也就是其類別有可能是相似的。其構建公式如下:
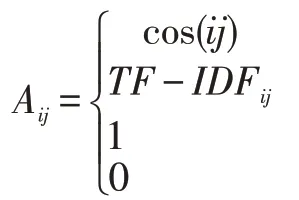
其中,cos(ij)表示興趣點i 和興趣點j 的名稱獨熱編碼的余弦相似度。TF-IDFij表示興趣點i 和單詞j的TF-IDF 值。則是為了和GCNs 保持一致,對角線元素設置為1,即i=j 的情況,表示節點的自環。其他情況則設為0。用鄰接矩陣構建了興趣點-興趣點、興趣點-單詞之間的關系后,需要進一步正則化,正則后的鄰接矩陣表達為:

其中,Dii=∑j Ai j。
1.2 模型的構建
本文模型的構建和TextGCN 一樣,也是使用了標準的GCNs 模型。一旦興趣點異構圖構建好,就可以輸入到一個簡單的兩層GCNs 模型。第二層節點的模型輸出緯度等于興趣點的類別數c。
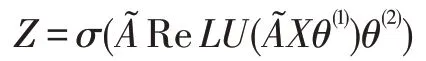
其中ReLU(?)=max(0,?)是激活函數,σ是softmax算子,θ(1)和θ(2)分別是第一層網絡和第二層網絡的權重矩陣。模型的損失函數定義已標注興趣點上的交叉熵損失,其具體定義如下:
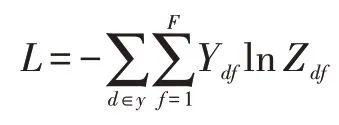
其中y 是已經有標簽的興趣點,F 是模型輸出特征的維度。
2 數據與實驗
本文在Yelp 2019 數據集①https://www.yelp.com/dataset上進行了對比實驗,評估了本文的模型和基準模型TextGCN 之間的性能差異。使用分類任務中常用的評價標準準確率和Macro-F1 來評價模型的表現,其中也給出了訓練時間(用秒來計算),來評價各模型的訓練效率。
2.1 Yelp數據集
本文采用的Yelp 數據集,來自美國Yelp 公司提供的開源真實興趣點數據,包含了美國2019 年截止的興趣點數據。因為實驗環境所限,本文抽取了其中兩個具有代表性的城市:夏洛特(用Char 來替代)和鳳凰城(用Ph 來替代)。其中Char 包含5842 個興趣點,平均每個興趣點的評論長度為1754 個單詞;而Ph 包含11125 個興趣點,平均每個興趣點的評論長度為2146個單詞。實驗的城市包含了大城市和小城市,已確保實驗上的有效性。

表1 Yelp 2019 數據集下兩個城市的數據情況
2.2 數據預處理
對于評論數據的處理,將按照TextCNN[8]的文本處理方法,以保證其公平性。先去除在NLTK 定義的停留詞,詞頻低于5 次的單詞。對于興趣點名稱數據,因為興趣點名稱的單詞數過于簡短,一般為2 到5 個單詞,所以本文先對興趣點名稱進行按單詞切割,統計其單詞頻率,把只出現過一次的單詞和單詞長度少于3個字符的單詞去除。從而留下的單詞作為詞表,為每個興趣點構建其獨熱編碼(one hot)。
2.3 實驗設置
本文使用PyTorch 框架來實現。所有的都在相同的硬件配置下進行:64 位Ubuntu 18.04.2 系統,Intel Core i7-6850K CPU(6 核3.60GHz),32GB 內存,和NVIDIA GeForce RTX 1080Ti 顯卡(11GB 顯存)。中間隱含層的維度均設置為200 維,所有模型的學習率均設置為0.02,Dropout Rate 為0.5,最大迭代次數為200次,使用Adam 優化器進行優化,如果模型在驗證集上的損失值不再下降(10 次迭代內),則提前停止訓練。本文的數據集劃分,遵循7:3 比例,即70%的興趣點作為訓練集、30%的興趣點作為測試集。其中,為了調整超參數,從訓練集中隨機抽出了10%的興趣點作為驗證集。
2.4 實驗分析
本章在Yelp 2019 數據集上的兩個城市進行了對比實驗,評估了本算法的有效性,并結合實驗結果分析了本文分類算法的優勢。
TextGCN 則是原論文的模型,而TextGCN-WW 則是保留文檔-單詞圖,去掉單詞-單詞共現圖下的模型。從表2 可以看出,在準確率上,三種模型的準確率都差不多,證明了單詞-單詞的共現信息在超長文本上的作用較小,而且大幅度增加了其訓練時間,增加了大約6~7 倍的訓練時間。隨著單詞列表增加,這個訓練時間還會進一步提高。而本文的模型在保證其準確率上,依然獲得了更高的訓練效率,可以看到本文模型的有效性。
在Macro-F1 方面,這是一個在準確率的基礎上衡量預測標簽多樣性的指標,我們可以看到,在小城市上,即興趣點和評論數都少的情況下,本文模型的效果反而有所提升。這就說明了使用興趣點所構建的興趣點-興趣點網絡具備一定的信息傳遞能力,彌補了部分特征單詞缺失的興趣點的缺陷。
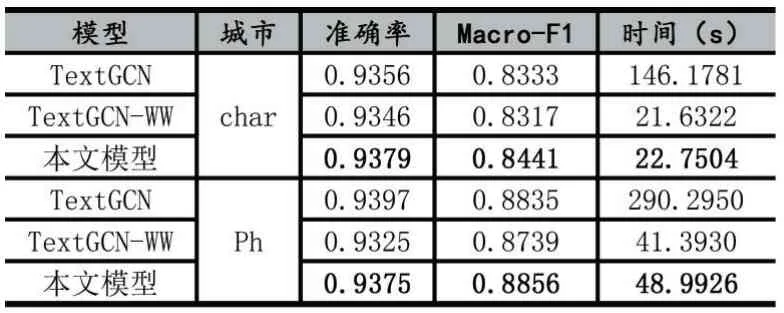
表2 本文模型與基準模型TextGCN、TextGCN-WW 的對比實驗
本文即一步探討其超參數的相關性,以評價本文模型的魯棒性。因為興趣點評論文本具有較大的不確定性,而且Yelp 數據集所面向的用戶有著各種語言習慣、語言分割、語言種類。探索詞的種類有利于衡量模型的魯棒性,使得模型應用更廣泛。
本文分別調整低頻詞和高頻詞來調節單詞的種類,從而從詞頻的角度來控制單詞的種類,如表3 所示。可以看到,低頻詞對于分類的多樣性非常重要,大量的詞雖然只在不到一百篇文章里出現過,但其對分類的多樣性非常重要,可以看到刪除詞頻低于50 到100 的單詞,基線模型會出現了2%的準確率下降,Macro-F1 更是下降了0.06 個點。本文模型則體現出了其魯棒性,雖然也有相同趨勢的下降,但整體效果還是超過了基線模型,這證明了利用興趣點名稱構建興趣點網絡的有效性。

表3 低頻詞保留情況及模型的相應表現
與低頻詞不一樣的是,高頻詞在數據中的占比非常少,即使減少到1%,也只是減少了大約1 千個單詞。在這里,可以看到兩個趨勢:
(1)雖然單詞數量減少有限,但其能降低其訓練時間;
(2)當高頻詞限制在2%以內時,基準模型的性能則開始下滑。
單詞越高頻,在圖網絡中,意味著該單詞節點連接的興趣點節點就越多;在信息融合角度上,意味著該單詞節點融合的信息就越多,但從特征傳播的角度,信息融合得越多,其特征顯著性就越低,傳播的效率就越低,而且連接的節點越多,其傳播的影響力就越小,因為其邊權重會正則化使得每一條邊的權重占比更低;在卷積的角度,會增加其卷積的范圍,模型在正向/反向傳播時,則需要更多的計算資源。這三個角度解釋了為什么減少的節點的數量有限,訓練速度的提高卻如此明顯;而且效果卻不怎么下降。
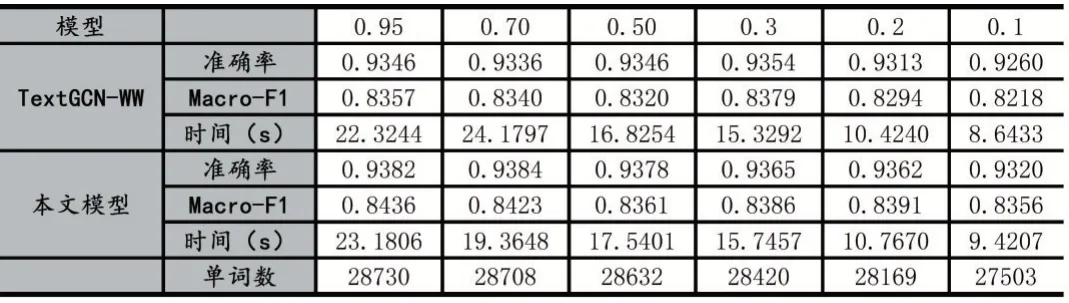
表4 高頻詞限制下本文模型的表現
3 相關工作
圖卷積神經網絡作為卷積神經網絡在不規則圖形上的擴展,近年來獲得了大量的關注和應用。TextGCN把文本和單詞視為節點來構建異構圖,使用標準的GCNs 來進行文本分類。但TextGCN 并不能充分利用文本信息,例如忽略了文本之間的語序信息。同時,TextGCN 為了提升效果,引入了單詞-單詞共現圖,但這也導致TextGCN 所需的計算資源快速上漲。同時結合原論文的實驗和我們的實驗,TextGCN 并不適合短文本分類和超長文本分類。這是因為短文本分類的單詞數量較少,且比較注重語序結構;而超長文本,例如本文的評論文本,眾多的詞匯信息,使得超長文本僅憑單詞信息就能獲得足夠的分類特征,從而無需額外的單詞共現信息來彌補單詞信息不足的缺陷,這也是本文模型在去除單詞共現矩陣后依然有不錯的效果的原因。除了語料的處理,TensorGCN[9]則是增加網絡的多樣性來彌補TextGCN 的不足,包括使用LSTM[10]來保留語序信息、使用CoreNLP 來抽取單詞的關系樹。但這種做法的問題在于增加了計算復雜度;計算量是Text?GCN 的幾倍,而準確率則是略有提高。圖網絡的復雜結構同時也決定了這樣的神經網絡難以訓練和調試。
興趣點分類的工作則是比較少,因為這一類工作往往轉化成文本分類來實現。通過評論文本的分類來實現對興趣點的分類。但這也的做法也是存在缺陷的,一是沒有考慮興趣點信息的多樣性,例如同樣是文本信息,興趣點名稱和興趣點評論則有著不同的來源渠道和語言特征。而Yelp 數據集大多數是用來進行評論情感分類和興趣點推薦。POIC-ELM 模型則是對POI 進行另一種分類[11]:每日簽到POI,每周簽到POI,每月簽入POI 和年度簽入POI。使得模型能夠預測推薦的興趣點是否與用戶形成某種生活上的關系,這是從用戶和推薦的角度來進行興趣點分類。
4 結語
綜合以上實驗,本文提出的模型的確能增強圖卷積神經網絡在興趣點分類上的魯棒性,充分利用了興趣點上的異構信息。因為Yelp 數據集是來自現實世界真實數據,其評論均來自于真實用戶,所以該數據集上的噪音更大,所以在該數據集上解決興趣點相關的任務更具有挑戰性。但是本文的模型算法在這個數據集上,而且是在減少大量邊信息的情況下,依然有效而且提高了訓練效率。興趣點分類是一項基礎研究任務,精準地為興趣點進行分類,有利于下游任務,例如興趣點推薦、社區劃分,等等。而興趣點分類不同于文本分類,其評論數量是動態增加的、不確定性的,而文本分類的樣本是固定的,沒有時間維度。這就造成了興趣點分類更容易受新加入的評論影響而使得模型準確性無法保證。
針對以上問題,本文利用圖卷積神經網絡,針對興趣點的數據特點,把興趣點名稱作為新的信息補充,通過打通興趣點之間的信息流通和減少了非關鍵節點之間的信息流通,大大提高了模型的穩定性和運行效率。充分利用了興趣點中存在的異構數據。本文設計的實驗也進一步證明了本算法的有效性,并在同等條件下獲得準確率和訓練效率上的提高。雖然本文針對的是興趣點分類任務,但可以本文的算法適用其他有著異構數據的任務。
目前利用評論和興趣點名稱獲得不錯的效果,但興趣點的還包含著地理信息、用戶信息和時間信息,但這部分信息更難處理且包含更多的噪音。所以這是一個有待解決的挑戰。本文接下來的工作將進一步深入挖掘興趣點的其他信息。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
