基于多損失值融合神經網絡的語音增強研究
2021-04-22 03:22:08朱世宇李根孫令翠謝箭柏森孟宓
數字技術與應用 2021年2期
關鍵詞:模型
朱世宇 李根 孫令翠 謝箭 柏森 孟宓
(1.重慶工程學院,重慶 400056;2.重慶電訊職業學院,重慶 402274)
0 引言
多個研究中指出,增強后語音均方差損失值得分較小的語音(與相對應干凈語音相比)不能保證其具有高語音質量和高可懂度[1-2],均方差損失函數,其缺乏與人類聽覺感知系統或人類聽覺間的關聯。對語音增強神經網絡損失函數的改進,能提高語音增強神經網絡性能,從而解決其受損失函數制約性能的問題。
本研究中提出的多損失值損失函數,由經過訓練的語音生成對抗神經網絡中的判別網絡,融合均方差損失函數構成。在判別網絡損失函數基礎上,使用均方差損失函數,保證了增強語音與干凈語音間的相關性。
此外本研究中提出的基于多損失值融合神經網絡,使用音頻波紋數據作為輸入,在較多語音增強神經網絡模型中,使用語音頻域信息作為輸入[3-4],語音音頻數據與語音頻域數據轉換過程,并非完全可逆,轉換過程中語音音頻部分細節信息(例如相位信息)丟失[5]。直接使用音頻波紋數據作為輸入,保留了音頻數據的細節信息。為保證語音音頻細節信息在卷積網絡層間的流動,在卷積網絡特定層間添加跳連結構,使相位、校正等語音音頻細節信息,不經過卷積網絡進行特征抽取壓縮,直接在各卷積網絡層間流動。也進一步避免了語音音頻細節信息丟失的問題。
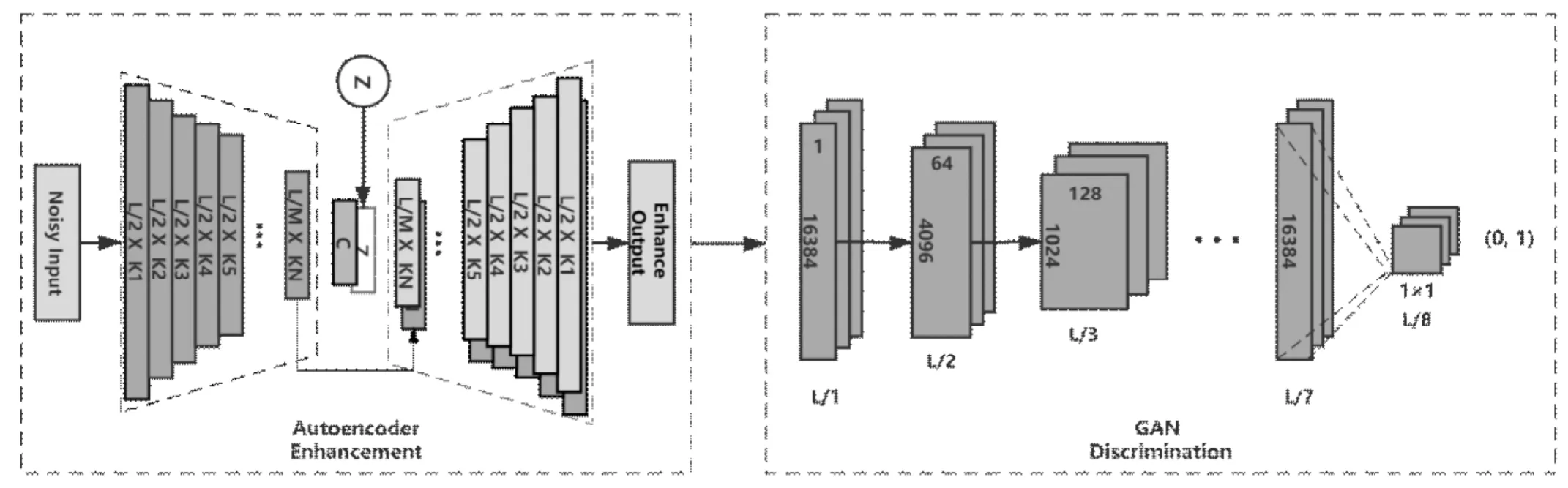
圖1 多損失函數結構Fig.1 Multi-loss function structure
1 多損失函數
使用對抗網絡判別器作為損失函數,判別器網絡被鏈接在基于自編碼器的語音增強網絡后。其網絡結構如圖1所示。
如圖中所示,語音增強結果將繼續被輸入判別器網絡結構。判別器網絡結構并不參加網絡模型訓練,判別器網絡權重由對抗神經網絡訓練獲得,判別器將對語音增強結果進行計算給出二分類結果值。
假設帶噪語音輸入為?,帶噪語音經過自編碼器的語音增強網絡獲得增強后的語音,增強結果繼續經過對抗網絡判別器計算獲得結果為0與1的真假二分類結果。最終的損失值計算為:
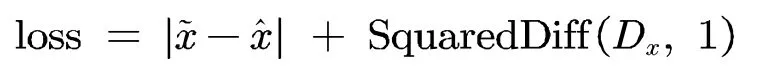
其中的SquaredDiff為差平方函數,式中將求得Dx與1的差平方結果。為平衡兩部分計算結果差值的數量級,將引入超參 ,所以最終的損失式為:

其中均方差損失值與判別網絡損失值,數值相差為兩個數量級。將各損失值統一到同以數量級,可避免其梯度變化傾向于單個損失函數[5]。因此引入經驗參數λ,根據數量級差異在實驗中設置λ=100。
2 實驗方案
為完成多信噪比下,語音增強神經網絡,語音增強性能的評估。以及多種噪聲環境下其語音增強性能評估,本研究實驗分兩部分完成。
第一部分實驗,此部分采用不同信噪比下的語音進行實驗,具體的,選擇了四個信噪比(SNR),即0dB、5dB、10dB、15dB的測試語音音頻,進行語音增強實驗。為獲得良好性能的判別網絡,首先對語音生成對抗神經網絡進行訓練。其中共投入473段人聲語音數據,其原始語音長度為38秒,經過分割為時長為1秒的訓練數據,總共約為20000段訓練音頻。語音生成網絡使用20000段左右語音進行了訓練,即一個訓練周期(Epoch)。而后為訓練基于多損失值融合神經網絡的語音增強模型,進行150個訓練周期的網絡訓練。
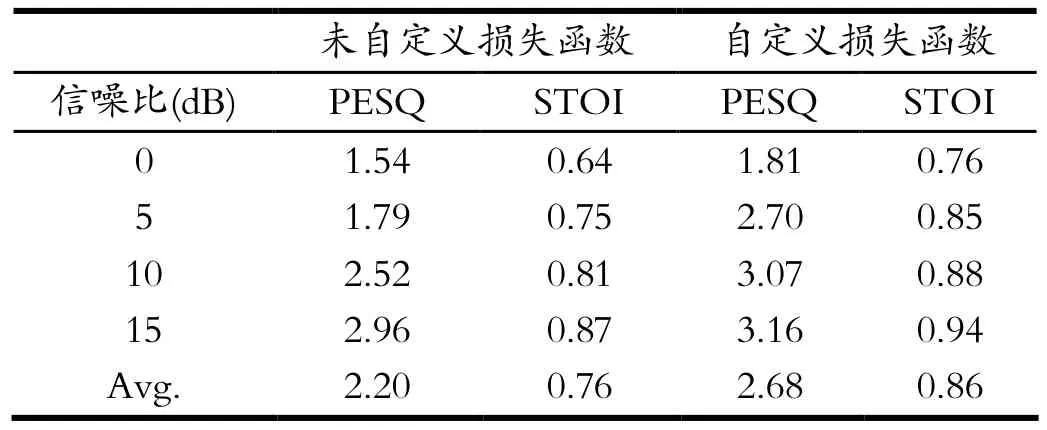
表1 PESQ與STOI對比結果Tab.1 Comparison results of PESQ and STOI
第二部分實驗,為了證明具有多損失函數的自編碼語音增強網絡的在多種噪聲下的普適性。設計了一組對照實驗。與實驗第一部分相同使用了一個訓練周期的語音生成對抗網絡模型中的判別網絡。將未自定義損失函數的語音增強網絡,與加入自定義損失函數后的語音增強網絡,經過同樣的40個訓練周期,以及150個訓練周期的訓練,兩模型使用同樣的參數配置,且均為首次訓練。隨后隨機選擇16組不同噪聲語音音頻進行測試。兩模型也均采用相同數據,進行訓練與測試。通過PESQ與STOI評分進行評價,每組對照實驗進行4次。未自定義損失網絡模型采用均方誤差作為損失函數。

圖2 (b)噪聲語音Fig.2(b) Noise speech

圖2 (c)增強語音Fig.2(c) Enhanced speech
3 實驗結果
通過在不同信噪比下對不具有自定義損失函數的基于自編碼器的語音增強模型,與具有自定義損失函數的基于自編碼器的語音增強模型,進行對比其結果如表1所示。從結果中可以看出具有自定義損失函數的模型下,PESQ評分均值相較于未自定義損失函數的模型,高出約0.4個點,STOI評分高出0.1個點。且在不同信噪比下具有自定義損失函數的模型分數均高于不具有自定義損失函數模型。因而具有自定義損失函數的基于自編碼器的網絡模型,相較于MSE損失函數即傳統損失函數的自編碼器網絡模型,在性能效果上具有提升。
語譜圖時聲音頻率隨時間變化的直觀表示,如圖2所示,圖2為信噪比為10dB的增強語音信號語譜圖,圖2(a)為純凈語音的語譜圖,圖2(b)為帶噪聲語譜圖,圖2(c)為增強后語音的語譜圖。通過語譜圖可觀察到,被噪聲掩蓋的語音信息,在增強后有明顯恢復。如圖中的A-a區域至C-a區域,原本被噪聲遮蓋的B-a區,在經過語音增強后C-a區對其進行了恢復。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
