基于卷積神經網絡的道路多目標檢測方法
2021-04-21 14:15:28遲志誠
汽車實用技術 2021年7期
遲志誠
基于卷積神經網絡的道路多目標檢測方法
遲志誠
(長安大學 汽車學院,陜西 西安 710064)
得益于數字圖像處理技術快速的發展和計算機硬件性能的提高,基于機器學習和深度學習的圖像處理技術,成為智能駕駛視覺感知的重要支撐。為了在實際道路環境中持續高效的檢測道路目標,文章利用了YOLO神經網絡作為主要檢測框架。使用卷積神經網絡可以同時捕捉到目標的底層和高層特征。物體的底層特征可以符合人的視覺感知特征和主觀感受,確定物體的所屬種類和外觀形狀,將底層特征與高層語義特征結合進一步增強神經網絡識別的準確度和魯棒性。
卷積神經網絡;目標識別;自動駕駛;YOLO v3
前言
環境感知作為智能駕駛實現第一環節,位于智能駕駛車輛與外界環境信息交互的關鍵位置,是實現車輛自動駕駛的前提[1]。實現高級別的智能駕駛正是要讓車輛模擬人類駕駛員的感知和決策能力,憑借機器更快的運算速度和環境識別能力,彌補人類駕駛員在行駛過程中的缺陷,達到減少交通事故發生,提高交通安全環境的目標。相機、雷達、定位導航系統等為智能駕駛車輛提供了海量的道路環境和車輛本身運行狀況的數據,這些包含諸如圖像,激光點云等形式的數據構造出了整個車輛的運行環境。
在相機等光學設備的觀測下,車輛和行人的外觀、顏色和大小會隨著光線,距離等因素發生變化。當地的天氣條件如雨、霧等也會影響光學儀器的正常工作。在惡劣的天氣條件下,相機只能拍攝到低分辨率圖像,造成檢測器無法正常檢測、跟蹤目標,影響了駕駛系統正常工作。這就要求目標檢測算法具有魯棒性、準確性和實時性的技術特點。為了解決目前存在的影響目標跟蹤精度的問題,我們基于YOLO v3[2]對原有目標檢測框架進行了一系列改進,使算法在保證實時運行的同時,增強其在復雜環境下的識別精度和準確度,提高了算法的魯棒性。
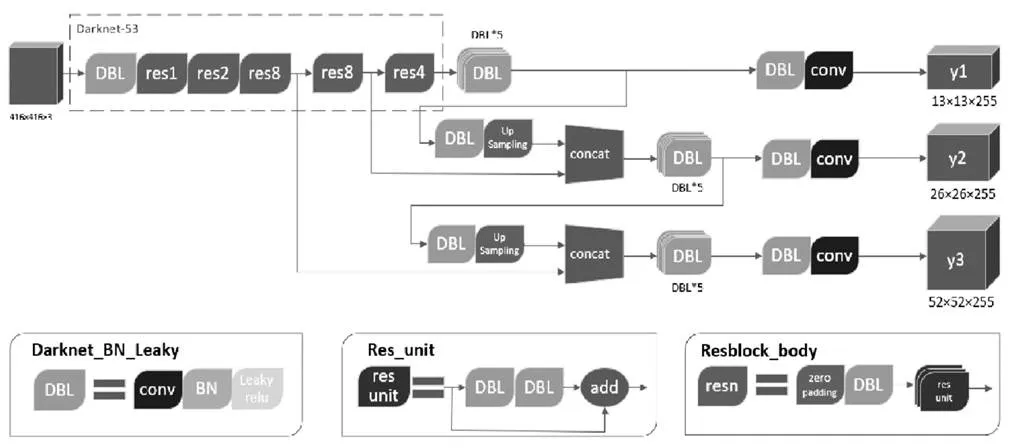
圖1 YOLO v3整體結構圖
1 YOLO v3神經網絡
1.1 網絡結構
目前主流的目標檢測算法大致可以被分為兩類,即兩步式和一步式的檢測算法[3]。與兩步式檢測算法不同的是,YOLO v3作為一種基于卷積神經網絡的目標檢測方法,可以直接針對目標的位置和類別作出預測。合理的網絡結構和檢測算法的改進保證了YOLO v3運行速度的同時也實現了與兩步式算法相同的檢測精度。
YOLO v3首次使用了Darknet-53神經網絡,借助殘差結構可以更有效的提取圖像中豐富的語義特征信息,使神經網絡在訓練時可以學習到更具有辨別力的外觀模型,在一定程度上也可以加速模型的收斂。在主干網絡的后面則采用了多尺度預測,保證了目標檢測框架對大目標和小目標的檢測精度,使得檢測框架可以完全捕捉圖像中的目標特征。
1.2 Darknet-53
YOLO v3使用了Darknet-53神經網絡的前52層作為整個檢測框架的核心網絡。在深度學習任務中,伴隨著卷積層數的加深,網絡會發生“退化”現象,即訓練時的損失函數不會隨著網絡深度的增加而一直下降,而是在達到飽和以后反過來逐漸增加。為了解決網絡退化問題,Darknet-53大量采用了殘差單元連接,以盡可能減少全卷積網絡的梯度退化問題。如圖示的5個殘差塊當中,每個殘差塊的結構相同,即由零值填充層和最基本的卷積歸一化單元作為前半部分,多個殘差單元與其連接共同組成一個完整的殘差塊。
1.3 多尺度預測
如圖所示,YOLO v3結構中有兩次上采樣的過程。在骨干網絡輸出圖像的特征向量以后,我們得到了32倍降采樣的結果,但是降采樣后的特征太小,僅僅關注了圖像中細小特征,對較大尺寸的物體的檢測效果不足。因此使用了兩次步長為2的上采樣,將32倍降采樣的結果的大小分別增加一倍和兩倍,這樣可以充分利用網絡中的深度特征和淺層特征,兩者通過張量拼接結合,隨后通過一系列的卷積池化操作,輸出最終的目標位置和預測類別。
2 運行過程
本文使用Python語言基于Tensorflow深度學習框架構建了目標檢測框架。使用的計算機配置為8核 3.4GHz Intel Core i7-3770和NVIDIA GeForce GTX 1080Ti的GPU,內存容量為16G。預訓練采用PASCAL VOC 2007和2012數據集,設置訓練時的批量大小為64,訓練次數為200次。使用Adam自適應梯度下降法,設置權重衰減和動量的值分別為0.9和0.0001。

圖2 目標檢測結果
選擇MOT 16[4]多目標跟蹤數據集中具有代表性的場景圖片進行測試,可直觀地觀察YOLO v3目標檢測網絡在實際道路環境下的檢測效果。從圖像上可以看出,大部分目標的置信度分數在60%以上,同時也沒有出現類別誤判的現象,行人和車輛的位置信息和類別信息可以準確的標定和輸出。在部分目標出現遮擋或者缺失的情況下依然可以在正常完成道路目標檢測的工作。
3 結論
全卷積神經網絡的YOLO v3算法可以很好地完成道路上多目標的檢測任務,在保證檢測精度的同時也可以做到實時性。目標檢測算法可以提高自動駕駛車輛對周邊環境的感知程度,一定程度上增加車輛安全性能,也為諸如道路多目標跟蹤等視覺感知任務作出了鋪墊。
[1]《中國公路學報》編輯部.中國汽車工程學術研究綜述·2017[J].中國公路學報,2017,30(06):1-197.
[2] Redmon J, Farhadi A.YOLOv3:An Incremental Improvement[J].ar Xiv e-prints, 2018.
[3] 盧宏濤,張秦川.深度卷積神經網絡在計算機視覺中的應用研究綜述[J].數據采集與處理,2016,31(01):1-17.
[4] Milan A,Leal-Taixe L,Reid I, et al. MOT16:A Benchmark for Multi- Object Tracking[J].2016.
Multiple Object Detection Method Based on Convolutional Neural Networks on Road
Chi Zhicheng
( Chang'an University, School of Automobile, Shaanxi Xi’an 710064 )
Because of the rapid development of digital image processing technology, image processing technology based on machine learning has become an important support for the visual perception of intelligent vehicle.In order to continuously and efficiently detect targets in the actual road environment, we use the YOLO v3 neural networks as the main detection framework. This network can simultaneously capture the bottom and high-level features of the target. The low-level features of an object can conform to human visual perception features and subjective feelings, determine the type and appearance of the object. We combined the low-level features with high-level semantic features to further enhance the accuracy and robustness of neural network recognition.
Convolutional neural networks;Object recognition;Autonomous driving;YOLO v3
10.16638/j.cnki.1671-7988.2021.07.008
U471.1
A
1671-7988(2021)07-23-02
U471.1
A
1671-7988(2021)07-23-02
遲志誠(1996-),男,長安大學研究生,車輛工程專業,研究方向為汽車NVH。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
