基于人工智能和深度數據分析技術的考評系統設計
2021-04-20 09:30:56徐軍委劉長勝
電子設計工程 2021年6期
徐軍委,劉長勝
(國網新疆電力有限公司,新疆烏魯木齊 830000)
在大數據背景下,新的工作考核評價理論與體系的應用研究成為熱點:文獻[1]論述大數據技術對高校科研評估科學性、準確性及優化資源配置的積極作用;文獻[2]使用大數據技術構建表現預測、迭代檢測、質量預警的學習評價體系;文獻[3]提出利用大數據及人工智能方法構建高中生專業興趣評估及學科建立評估系統;文獻[4-5]將大數據技術應用于公務員績效評估中進行理論研究;文獻[6]基于智能設備在對建筑工人施工安全方面,建立了相關考核與激勵機制。即當前的研究主要集中在理論分析,且多用于對項目的評估及對基層公務員的考核,對員工的工作考核體系的創新性研究較少。針對相關研究較少、工作考評因素單一的問題,該文提出了基于人工智能算法及深度數據分析技術的工作考評系統。
1 系統總體架構
圖1 為系統的整體框圖,該系統主要由數據獲取模塊、數據預處理模塊、評價考核模塊及反饋激勵模塊組成。以員工為系統的主體,最終評價考核結果再反饋至員工,使整個系統形成閉環。首先,利用數據挖掘技術對員工工作的相關數據進行處理分析,并提取關鍵性的特征指標;然后,對提取的關鍵指標進行預處理后,根據權重作為人工智能算法的輸入,通過訓練后由人工智能算法進行分析;最終,對員工的工作給出等級性考評;由于算法的透明性可將系統的評估過程輸出,并將其作為對被評估員工的反饋激勵。
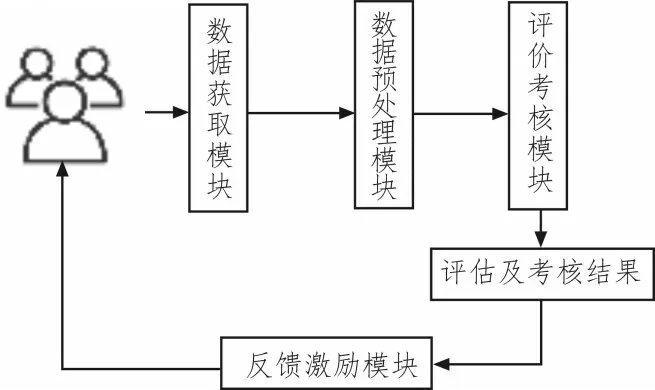
圖1 系統總體框架圖
2 數據的獲取和預處理
2.1 數據的獲取
獲取的員工數據主要包括兩類:基礎數據與日常數據。基礎數據由員工入職時一次性收集,并由人力資源管理部門定期核查更新,通過定期更新,即可完成此類數據的收集;日常數據傳統方法由員工上報或公司定期審查相結合的方式收集,當前隨著物聯網技術的發展,網絡數據庫、移動終端等給此類數據的采集提供便利,常用的獲取方法有:1)使用統一聯網接口進行出勤考核;2)使用二維碼對員工任務進行標注,最后通過二維碼統計任務數據;3)移動終端申報系統、工作狀態識別系統等。
2.2 數據的預處理
數據預處理的過程主要如下:
1)數據清理。即對所獲取的數據中的缺失、異常等數據進行處理;
2)數據集成。即去除獲取數據中無關數據,并合并數據中的相關數據;
3)數據變換。即利用數據變換將數據轉變為方便作為人工智能算法輸入的類型。
該系統使用Python 語言數據的預處理相關工作,相關的處理方法如下。
①數據的裝載
data=pandas.read_csv("./data.csv");
或data=pandds.ExcelFile("./data.xlsx");
其中,函數參數為對應讀取文件的路徑。而data 變量為生成的Data Frame 的數據結構。通過此方法,可讀取.csv 或.xlsx 類型數據。下面即可使用科學數據庫對數據進行處理。
②缺失值的處理
關鍵操作如下:
index_null=pandas.isnull(column);
column_null_true=column[index_null];
其中,column為待處理的數據列。pandas庫中使用isnull()方法可以獲取列數據中缺失數據的索引,通過獲取到的缺失數據索引再對缺失值進行處理。
對于員工指標數據中的缺失值,要根據指標不同的重要程度采取對應的措施,如:再次補錄或使用所有數據中的某個統計量代替(最小量、最大量、中位量、眾量等)。
③無關值的刪除與相關值的合并
無關值刪除關鍵的操作為:
data.drop('column',axis=1)
執行該操作可刪除名為data 中列的名字為column 的數據,其中axis=1 代表對列進行刪除操作;
對于相關數據可使用data["column"]引用對應列的數據,之后可使用對應的運算向相關的數據行處理或合并。如:
data["column1"]=data["column1"]+data["column2"]
data.drop('column2',axis=1)
上述操作實現了對列1 與列2 相關數據的合并。
在員工相關數據的處理中,對姓名、序號、工號等與績效評估無關的數據可在進行考評前刪除;對諸如入職年份、工齡、出勤次數、缺勤次數等可先根據其相關關系,對數據進行合并。
④連續數據的離散化
連續數據離散方法如下:

其中,data 為DataFrame 格式的數據,fun 為自定義的操作函數,可通過自定義系列操作函數完成復雜的數據處理。
實現連續數據離散化的自定義函數格式如下:

其中,column 為待處理的數據列的列名稱,column data 為根據列名獲取的列數據,value 為指定的連續數據的分割值,class1、class2 分別為指定的離散化后數據的類名稱。
3 評估算法及反饋激勵
該文將對員工工作的考評問題等價于對相關工作數據的分類操作。近年來有多種人工智能算法被應用于分類問題,文獻[7-8]使用SVM 算法實現對遙感圖像及恒星光譜的分類。文獻[9-10]使用神經網絡相關算法實現了文本及目標圖像的分類;文獻[11-12]使用K 近鄰算法實現對多標簽數據及高速鐵路故障的分類;文獻[13-16]使用決策樹或決策森林實現了對數據的分類。其中,決策樹算法具有實現簡單、運算量小、決策過程透明且可復現等優點,綜合考慮相關因素,本體系采用決策樹算法。
3.1 決策樹算法的實現
決策樹算法利用信息熵原理對數據進行分類,信息熵值可表征數據的混亂程度,信息熵定義為:
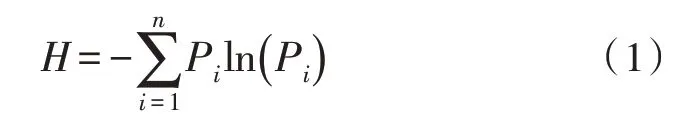
式(1)中,H為數據集的信息熵,Pi為對應數據i在整個數據集中發生的概率,n為數據集中數據的類數。
決策樹算法的實現過程如下:
1)計算整個數據集的信息熵:
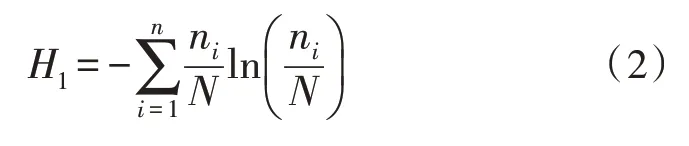
式(2)為整個數據集熵的計算方法。其中,ni是每類數據在數據集中的個數,N為數據集中數據總個數;
2)計算信息熵的增益,信息熵增益的計算方法如式(3)所示。
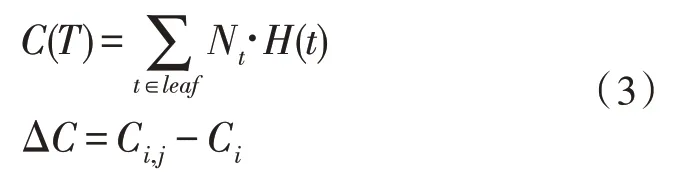
式(3)中,Nt為對應枝的概率,Ci為數據集信息熵,Ci,j為添加分割屬性j后的信息熵。然后,選擇熵增益最大的屬性作為根節點,完成分割后再重新執行上述決策樹算法的步驟1)和2)。
由此即可建立出決策樹的分類模型。同時,可視化該模型即為反饋激勵模塊的輸出。
3.2 反饋激勵機制
由于決策樹的透明性及可復現性[17-19],在生成決策樹后,整個決策過程可進行輸出,通過決策過程可表現出各個指標在評估過程中的重要程度。因此,將評估過程生成的數據反饋給被評估者,可以使被評估者清楚地了解自己在工作中的不足,以及各評估指標的重要程度,從而激勵被考評者的工作潛能與積極性。
4 系統的實現
選取某企業員工工作考核表數據進行系統實現,數據集中共40 名員工。經數據預處理后[20-21],提取與工作關聯較大的指標有:Jobage、Task、Language、Teamwork 和Professional,而考評結果從優到劣分為由A 到D 共5 個類別,其中B 類2 個。
選取數據集中24 名員工為訓練集,剩余16 名員工為測試集對該考評系統進行測試。24 個訓練集中5 類考核結果個數分別為:3,5,9,5,2。由式(1)得初始集合的信息熵為:
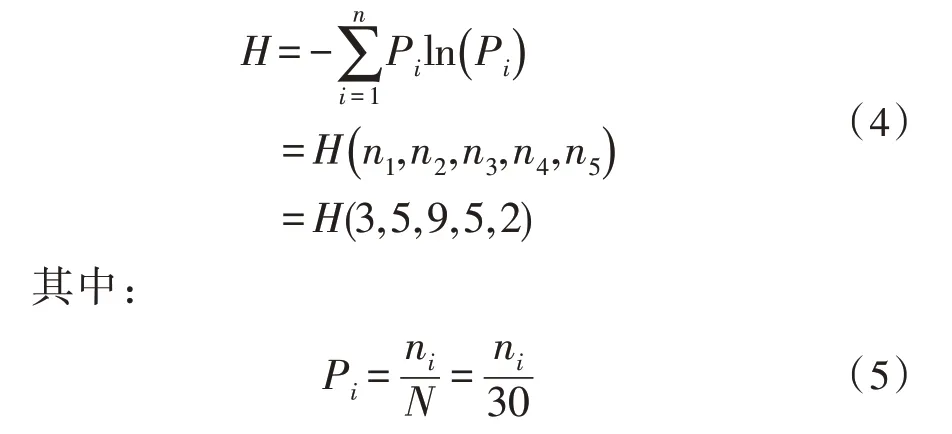
將式(5)代入式(4)中得:H=1.975 4;
對應Task 為excellent 時,共有8 個樣本,各類考核結果的個數分別為:3、3、2,則此時信息熵為:
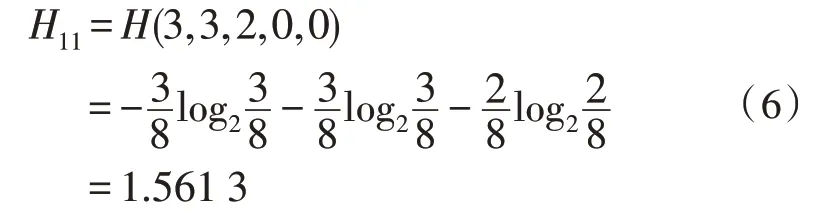
同理可得,當Task 為good、poor 時:
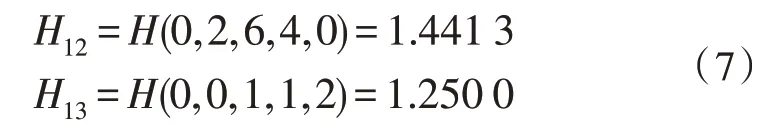
則由式(2)對應Task 的信息熵為:
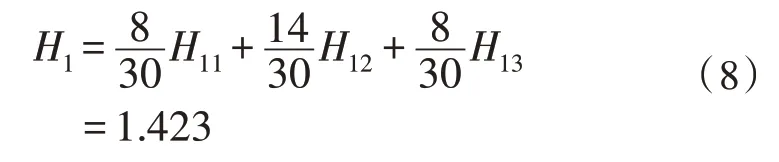
則選Task 為根節點的信息熵增益為:
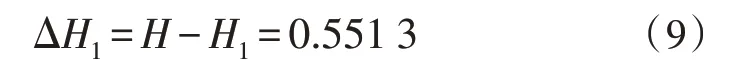
同 理,計 算 對 選Jobage、Language、Teamwork、Professional 為根節點計算信息增益率,如表1 所示。
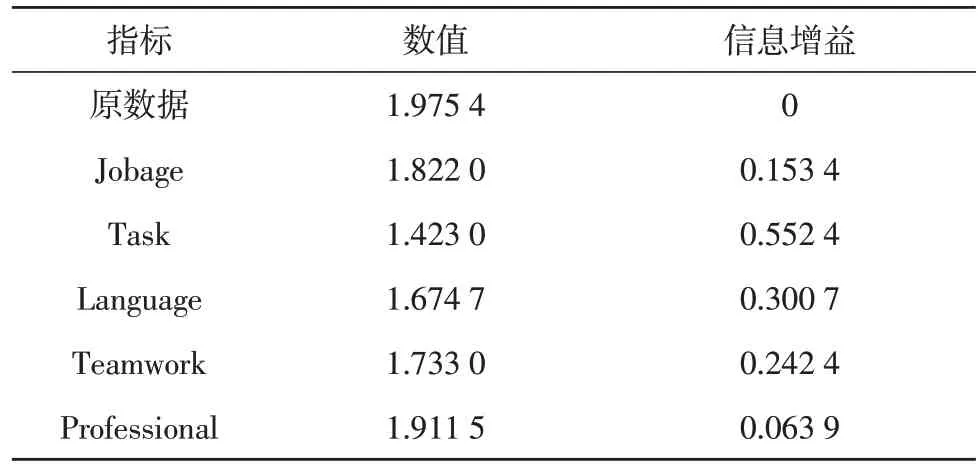
表1 確定根節點熵增益表
根據表1 可知,Task 屬性的信息增益最高,因此選擇其為根部節點。同理,根據信息增益的數值,依次確定決策樹的決策過程如圖2 所示。
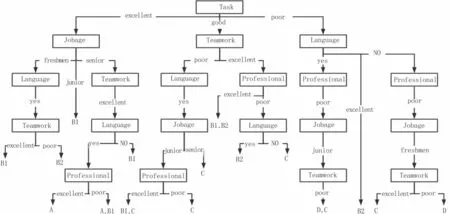
圖2 決策過程
使用該決策樹對6 個測試樣本進行考評,考評結果如表2 所示。
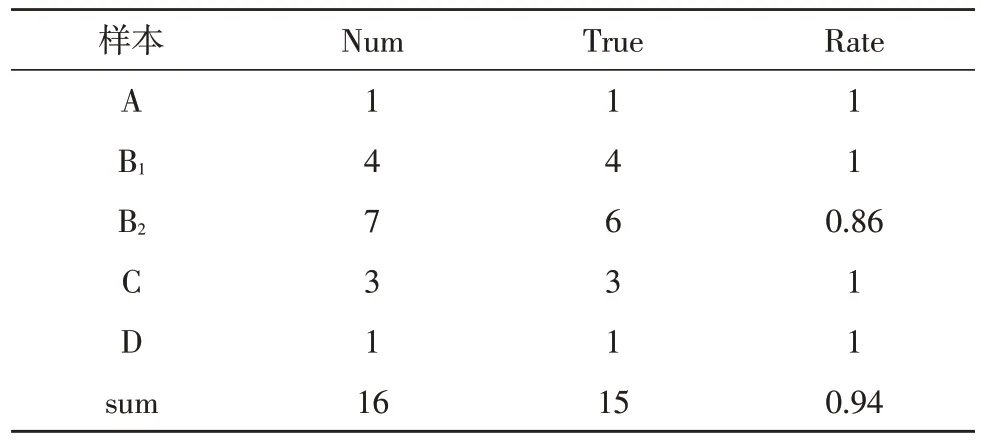
表2 考評結果
由數據結果可知,考評的正確率可達94%,驗證了該體系的正確性和有效性。同時,系統把決策過程也反饋給被考評的員工,從該過程中,員工可以獲得以下信息:明晰自己績效的變化,Task 指標的重要性,了解Jobage、Teamwork 和Professional 等指標的信息,從而起到對員工的激勵作用。
5 結束語
該文利用人工智能相關算法及深度數據分析技術構建員工的工作考評體系。該體系中利用數據挖掘技術,對獲取的員工數據進行清理、集成與變換,即使用決策樹算法利用處理好的數據實現員工工作的考核評價。同時,利用評價過程對員工進行反饋激勵,使員工評價考核體系幾乎無主觀因素的影響,且更加智能化。該體系也存在一些不足,例如:為使評價考核的過程更加清晰明了、保持良好的運算速度,該文未使用多棵決策樹組成隨機森林算法,導致了考評結果的準確率有所降低,而且在出現多類的葉子節點時,仍需人工進行再次分類。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
童話世界(2020年10期)2020-06-15 11:53:22
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
小康(2017年16期)2017-06-07 09:00:59
中國衛生(2016年2期)2016-11-12 13:22:24
南風窗(2016年19期)2016-09-21 16:51:29
