復雜環境下基于采樣空間自調整的航跡規劃算法
2021-04-20 14:07:38陳建平
計算機應用 2021年4期
張 康,陳建平
(南京航空航天大學航空學院,南京 210016)
0 引言
航跡規劃是指在任務空間中找到無人機(Unmanned Aerial Vehicle,UAV)從初始狀態到指定目標狀態的可行航跡,其應用背景十分廣泛,如無人駕駛汽車、計算機輔助外科手術、移動機器人等[1-3]。
現有的航跡規劃算法主要分為確定性方法和隨機性方法。確定性方法有人工勢場法[4]、A*算法[5]、智能算法等。人工勢場法需要根據環境信息預先構建勢場,容易陷入局部最優,且在狹窄通道里會出現擺動現象,不適合復雜環境的應用;A*算法在高維空間中會出現組合爆炸的問題;以粒子群[6]為代表的智能算法通常會用來求解滿足性能指標的最優航跡問題,但一般需要大量迭代才能收斂,計算開銷大,運算時間長。
概率路線圖(Probabilistic Road Map,PRM)法[7]和快速擴展隨機樹(Rapidly-exploring Random Tree,RRT)法[8]是當前使用最廣泛的隨機采樣方法,相較于確定性方法的優勢在于使用碰撞檢測技術避免了對障礙物的顯示建模,直接在當前任務空間中生成可行航跡,具有實時處理復雜環境下航跡規劃問題的能力。PRM 算法的性能對障礙物形狀嚴重依賴,難以在不確定環境中發揮作用。相比之下,RRT 算法對環境波動不敏感,且支持非完整約束。這些優點使得RRT 在近年來得到了廣泛的應用和發展。最具代表性的是文獻[9]中提出的具有漸進最優性的快速擴展隨機樹(Rapidly-exploring Random Tree star,RRT*)算法,它針對RRT算法非最優性的缺點,在每次迭代中通過對新擴展節點的近鄰優化來保證算法的漸進最優性。但該算法仍然存在一些不足:1)尋路沒有方向性,規劃過程中會出現很多重復探索;2)沒有利用已有樹的信息,對整個空間采樣導致添加了大量不在航跡附近的無用節點,收斂速度緩慢。
為了增強RRT 算法的魯棒性,文獻[10]中提出了基于動態域的快速擴展隨機樹(Dynamic Domain Rapidly-exploring Random Tree,DDRRT)算法。文獻[11]中則通過引入地圖的代價模型,改善了DDRRT可能造成的對采樣空間過度約減的問題。
為了提高RRT*的收斂速率,文獻[12]中通過對剪枝處理后的可行路徑節點附近集中采樣,從而減少了大量的無用采樣。文獻[13]中借鑒文獻[12]的思路提出了可調邊界的漸進最優快速擴展隨機樹(RRT*-Adjustable Bounds,RRT*-AB)算法,在迭代中一旦找到可行路徑,便在起始點和目標點之間建立一個可調整邊界的連通域作為采樣區域,同樣達到了集中采樣的效果。文獻[14]中提出的帶啟發式采樣的漸進最優快速擴展隨機樹(Informed-RRT*)算法將采樣空間限制在一個超橢球里來達到優化采樣空間的效果。文獻[15]中提出的固定節點數的漸進最優快速擴展隨機樹(RRT*-Fixed Nodes,RRT*-FN)算法通過限制節點的最大數量來減少算法的占用內存。文獻[16]中將Informed-RRT*和RRT*-FN 算法結合,通過啟發式采樣和刪除低權重的葉子節點的方法來加快收斂速度。文獻[17]中通過機器學習的方法得到新的非均勻抽樣分布,該分布只在非障礙區域采樣,極大減少了碰撞檢測次數。
針對RRT*算法在復雜環境下的尋路效率不足、收斂速度緩慢的問題,本文提出了基于采樣空間自調整的漸進最優快速擴展隨機樹(Adjust Sampling space-RRT*,AS-RRT*)算法。該算法在迭代過程中的采樣空間隨著樹的不斷生長而自動調整,算法流程分為搜索和優化兩個階段:搜索階段不采取近鄰優化,在迭代中根據當前樹生長情況選擇合適的采樣策略,目的是更快速地找到初始航跡;優化階段根據算法的近鄰優化次數,周期性地更新高質量節點,并通過學習高質量節點產生新的抽樣分布、刪除低質量節點來保證樹在最優路徑附近高效生長,加快了收斂速度,降低了算法的內存占用。在不同類型的環境下與傳統的RRT*算法進行了對比仿真實驗,結果驗證了本文算法的有效性。
1 相關工作
1.1 RRT*
RRT*算法[9]是RRT 算法中具有漸進最優性質的優化版本,在每次成功擴展節點后通過和近鄰節點互相重選父節點來降低樹的總代價,當采樣量足夠大時,算法會最終收斂到最優航跡。該算法大致流程如算法1 所示。首先,初始狀態xinit被添加到樹的根節點中(第1)行);主循環第2)~12)行表示在N次迭代后終止。只有通過碰撞檢查的邊才能添加到樹中。近鄰優化確保新節點連接到搜索樹中的最佳頂點。碰撞檢測技術不需要約束的顯式表達,具有實時處理復雜環境下航跡優化問題的能力。
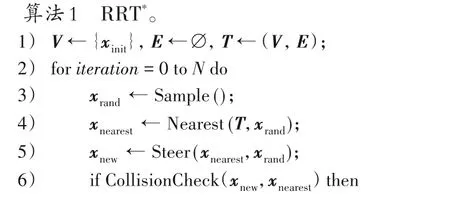

Sample:隨機地在狀態空間均勻采樣,生成一個狀態點。
Nearest:通過一個度量函數Distance 來衡量節點與采樣點的距離,函數Nearest 返回搜索樹T中與采樣點距離最近的節點。

Steer:給定兩點xnearest和xrand,Steer 函數返回擴展的新節點xnew,在滿足最大生長步長r的情況下,使新節點xnew盡可能地靠近xrand。

CollisionCheck:檢查連接到新節點的航跡是否通過碰撞檢測,滿足則返回ture,否則返回false。
Near:從搜索樹T中篩選出與新節點的距離小于γ的節點,組成一個節點集并返回。

其中:γ=k(logn/n)1/d表示近鄰優化半徑;k是與規劃空間尺寸有關的常數;n為節點數量;d為規劃空間的維數。
Chooseparent:遍歷節點集Vnear為xnew重新分配父節點指針,返回使xnew代價最低的父節點。

Rewire:如果重連接后代價更低,則Vnear中的節點重新分配父節點指針到xnew。
RRT*算法雖然保證了RRT 算法的漸進最優性,但由于沒有在探索和優化做一個合理的權衡,一成不變地對整個空間進行均勻采樣,導致了很多優化操作不能集中在最優航跡附近,也就是說空間中那些沒有降低最終航跡代價的采樣是無用的,浪費了大量計算資源。
1.2 改進RRT*-FN
Informed-RRT*算法[14]是為了減少無用采樣、提高收斂速度的一個RRT*改進版本。該算法通過當前可行航跡的最小代價來生成一個超橢球采樣空間,減少了在無用區域的采樣。RRT*-FN 算法[15]通過預設值最大節點數量來減少算法所占用的內存。改進RRT*-FN[16]結合了前兩者的優點,在搜索到初始航跡后通過啟發式采樣把采樣空間限制在橢圓子集和航跡點的鄰近區域,在達到預設最大節點數量后刪去不在啟發采樣區域的葉子節點,進一步加快了收斂速度。改進RRT*-FN算法的大致流程如算法2。


改進RRT*-FN 在RRT*基礎上增添了啟發式采樣和節點刪除的步驟,雖然有效提升了收斂速度,減少了計算占用內存,但是仍有一些不足之處:1)在找到初始航跡前使用RRT*算法均勻搜索整個空間,造成了許多對無用區域的近鄰優化操作;2)橢圓子集采樣更適合最終航跡長度和起始點到目標點的直線距離相差不大的情況,否則,橢圓區域可能會大到覆蓋整個采樣空間。
2 問題定義
令規劃任務的狀態空間通過集合X?Rn來表示,n∈N為狀態空間維數。Xobs?X用來表示空間中的障礙區域,Xfree=Xobs/X表示空間中的自由區域;xstart∈Xfree為起始點,xgoal∈Xfree為目標點;對于自由空間中任意兩狀態點x1∈Xfree,x2∈Xfree,定義一個連續函數π:[0,s]來表示連接兩點的一段可行航跡(π(0)=x1,π(s)=x2),s表示航跡代價;令空間中所有的可行航跡πf∈Xfree(πf(0)=xinit,πf(s)=xgoal)由一個集合Σf表示。算法將通過構造搜索樹T來找尋航跡,主要考慮了以下兩個問題。
問題1 在限定搜索時間里找到一條可行航跡πf∈Σf(πf(0)=xinit,πf(s)=xgoal)。
問題2 在有限時間里不斷優化可行航跡πf∈Σf,使航跡代價s最小。
3 AS-RRT*
為了減少尋路時間、降低航跡代價,本文提出的AS-RRT*算法將流程分為搜索和優化兩個階段,分別采用不同的采樣策略和擴展策略,目的是同時保證快速性和優化性。算法大致流程如算法3所示。

算法在初始化參數后進入搜索階段(第2)~5)行),基于樹的生長情況的自適應選擇向光區采樣和背光區采樣(第3)行),引入一個基于碰撞增量的代價模型來降低障礙物附近節點被擴展的概率(第4)行),此階段不考慮近鄰節點的優化,目的是快速找到一條可行航跡(第6)行)。在找到初始航跡Πinit后,篩選高質量節點放入集合Velite中(第7)行),使用一種多變量概率模型來描述抽樣分布,參數α表示概率模型的均值和協方差矩陣(第8)行)。接著進入迭代優化階段(第9)~17)行),基于近鄰優化次數NOT(Optimized Times)來更新精英集和抽樣分布(第12)~16)行),通過Matlab 的mvnrnd 函數生成采樣點(第10)行),同RRT*一樣對新擴展節點采取近鄰優化,當節點數量超過限定值時,則刪去樹中低質量葉子節點(第11)行)。
3.1 搜索階段
向光采樣和背光采樣依據當前節點總的擴展失敗率οEFR(Expansion Failure Rate)來選擇,它是擴展失敗次數和搜索次數的比值,反映了當前樹的生長情況。如果擴展失敗率低,說明障礙物的影響較小,算法會趨向于在目標點附近的向光區域采樣;反之,則說明障礙物影響較大,算法會在遠離樹中心的背光區域外采樣,加強探索力度引導樹逃離障礙區域。搜索階段的采樣和擴展策略如算法4和算法5所示。

3.1.1 向光區域均勻采樣
向光區域是一個以目標點為中心的超球錐,對n維空間下的超球錐子集的均勻采樣可以通過約束一個超球的極坐標來方便地實現。

圖1 是在一個中心有障礙的簡單二維環境下樹的生長情況,方塊為起始點,圓圈為目標點,黑色表示障礙物。一開始,向光區域為起始點和目標點間的連線,保證在自由空間里以最高效率向目標點生長;在與障礙物發生碰撞后,向光區域擴張為一個扇形,由于擴展失敗率很低,向光區域可以繼續引導樹向目標點生長。
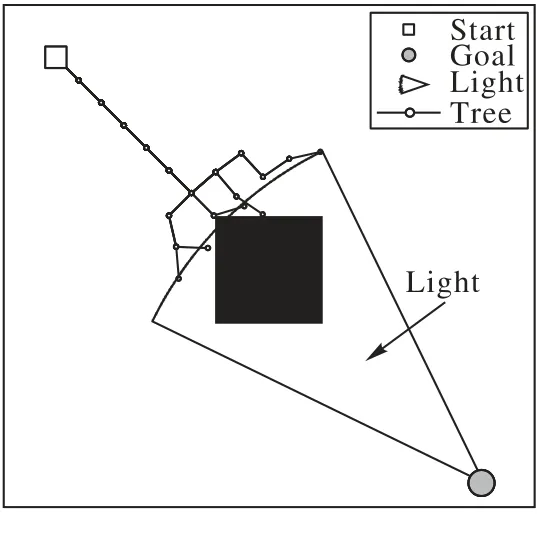
圖1 向光區域采樣Fig.1 Sampling in light area
3.1.2 背光區域
背光區域的形狀是一個超球,超球的中心是當前樹的中心xcenter,也就是所有節點坐標的均值,半徑r為xcenter到擴展失敗次數最多的節點x″的距離,在背光區域外的采樣點xrand滿足以下約束:

為了減少不必要的碰撞檢測,引入一個基于碰撞增量的代價模型C,在計算最近的節點時,那些擴展失敗的節點將被考慮額外的代價。

其中:n為單個節點的擴展失敗次數;k的取值范圍為0到1,目的是保證不會高估節點的額外代價。
圖2表示的是一個規劃難度較高的Bug trap 難題[10],起始點在凹障礙物內,且與目標點無法直接相連。算法在向光區域多次嘗試無果后轉而在背光區域外采樣,因此障礙物包圍區域里的節點內疏外密,而且由于考慮了額外代價,在障礙物附近的節點出現了多分枝現象,相較于傳統RRT 算法用了更少的擴展次數和碰撞檢測次數。

圖2 背光區域采樣Fig.2 Sampling in dark area
3.2 優化階段
3.2.1 節點篩選
基于降低航跡代價的原則篩選節點,定義節點x質量高低的指標函數為J,它與當前可行航跡Πcurrent有關,Πcurrent表示起始點到目標點的節點序列。

其中:J1代表了節點到當前航跡的最小距離,J2代表了節點到連接起始點和目標點間直線的距離;k1和k2表示權重系數。指標函數J越低則節點的質量越高。算法6為篩選節點流程。

3.2.2 機器學習模型
合適的機器學習模型可以更好地描述數據。高斯混合模型由多個單高斯分布組成,當分模型個數K選取合適時,可以用來逼近任意的抽樣分布。
高斯混合模型被定義為:

現已有很多成熟的算法求解高斯混合模型的參數,本文采用最大期望化算法求解高斯混合模型參數,利用Matlab 的mvnrnd函數生成采樣點。
3.2.3 分模型個數K
合適的K值選取是求解高斯混合模型的關鍵步驟,它需要合理地反映出當前航跡被障礙物分成了幾個部分,也就是說K應該和航跡的有效節點數量是等同的。有效節點被定義為航跡節點序列Π經過裁剪后的新節點序列Πprune。

算法7 為裁剪函數的流程,它從起始點開始逐漸向目標點移動,遍歷所有子節點直到找到最少代價的無碰撞航跡,裁剪過程結束后,航跡中不會再有可以直接連接的額外節點,圖3 為一段航跡的裁剪示意圖,實線為裁剪后的航跡,虛線為失效的航跡。

圖3 航跡裁剪示意圖Fig.3 Schematic diagram of pruning path
3.2.4 最大節點數量
優化階段的擴展策略考慮近鄰節點的優化,當節點數量達到最大值時,便刪去樹中最低質量的葉子節點,質量高低由3.2.1節定義的函數J判斷,擴展流程見算法8,最大節點數量由式(18)定義:

其中:Nmax表示最大節點數量(Maximum Number of Nodes);εi為地圖尺寸;d為地圖維度;λ為生長步長為初始航跡的節點數量。


3.2.5 更新周期
與其他通過找到新的可行航跡來調整采樣策略的算法不同,本文根據近鄰優化次數來周期性地更新抽樣分布,具有穩定的更新頻率。在算法更新了m次后的更新周期P被定義為:

其中:m為更新次數;P0為初始更新周期。
圖4 中展示了抽樣分布的變化過程,由于節點會不斷被篩選更新,抽樣分布也逐漸被學習更新到最優路徑的附近區域。

圖4 更新m次的抽樣分布變化Fig.4 Sampling distribution change after m-times updating
4 算法性能分析
4.1 概率完備性
在找尋初始航跡的搜索階段:理想情況下,向光區域采樣策略可以引導樹快速達到目標點;極壞情況下,那些擴展失敗節點的額外代價將達到最大值,背光區域作用失效,同RRT一樣對空間均勻采樣。因此本文算法與RRT 一樣具有概率完備性。
4.2 計算復雜度
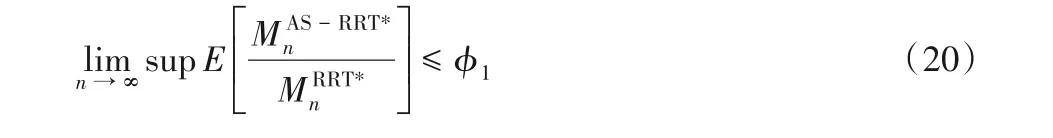
5 仿真實驗與結果分析
在Map1~4 等不同類型環境下仿真來驗證本文算法的有效性,將其與RRT*算法、改進RRT*-FN 算法進行比較,從而來表現本文算法的優越性。考慮到算法本身具有的隨機性和不同環境下的規劃難度不同,對相同環境下的不同算法各進行30 次實驗,不同環境下的仿真時間、起始點和目標點的位置見表1。算法的運行環境:64 位Windows10 操作系統;處理器Intel Core i5-8250U CPU;主頻1.60 GHz;內存8 GB;計算軟件Matlab 2017b。
圖5 是不同環境下運行結果的比較。如圖5(a)所示,Map1 是一個障礙物密度較大的環境場景,可以看出RRT*算法一成不變地對整個空間均勻采樣,產生了大量那些遠離航跡的采樣,而這些節點對最終航跡并沒有起到降低代價的作用;改進RRT*-FN 算法在一定程度上改善了RRT*算法對空間的盲目探索,在找到初始航跡后,便可以使用啟發式采樣向樹中添加有意義的節點,達到集中采樣的效果來優化航跡;相比之下,本文所提出的學習高質量節點的策略、自適應調整抽樣分布的方法具有更好地識別航跡特征的能力,優化效果更為出色。Map2 是一個帶有U 形障礙的特殊環境場景,從起始點到目標點需要穿過兩個狹窄通道,規劃難度較大,如圖5(b)所示,由于最終航跡長度和起始點到目標點的直線距離相差很大,橢圓子集采樣效果退化嚴重,大多節點都集中在了障礙物內,包裹航跡的附近節點分布不均勻,導致改進RRT*-FN算法的優化性能大大減弱。Map3 是一個由20 個隨機半徑、隨機位置威脅球組成的三維環境場景,如圖5(c)所示,在三維環境下本文算法依然可以靈活地調整采樣空間,相較于另外兩種算法也具有更好的優化效果。Map4 是一個帶有兩個狹窄通道的三維環境場景,如圖5(d)所示,可以看出隨著環境空間維度的提升,規劃難度加大,算法的性能對比也變得越來越明顯。

圖5 Map1~4上的算法性能對比Fig.5 Performance comparison of three algorithms on Map1-4
表2 列出了30 次仿真實驗的各算法性能指標的平均值。從表2 可以發現,從找尋初始航跡的消耗時間上看,近鄰優化步驟使得RRT*算法比RRT算法要慢很多,本文方法根據樹的生長情況去自適應調整采樣策略,因此比RRT 算法用了更少的時間。從最終生成的航跡代價來看,在相同的仿真時間下,本文方法依據當前近鄰優化次數周期性地學習樹中高質量節點,新的抽樣分布更能反映當前最優航跡的幾何特征,相較于其他兩種算法具有更高的優化效率,最終生成了更低代價的航跡。

表1 仿真參數設置Tab.1 Simulation parameter setting
圖6 是不同環境下算法的收斂結果對比。由圖6 可以看出,本文方法在搜索初始解時目的性強,優化階段集中采樣效果好,因此相較于另外兩種算法具有更好的收斂性,而且在規劃空間維度變高后差距更為明顯。
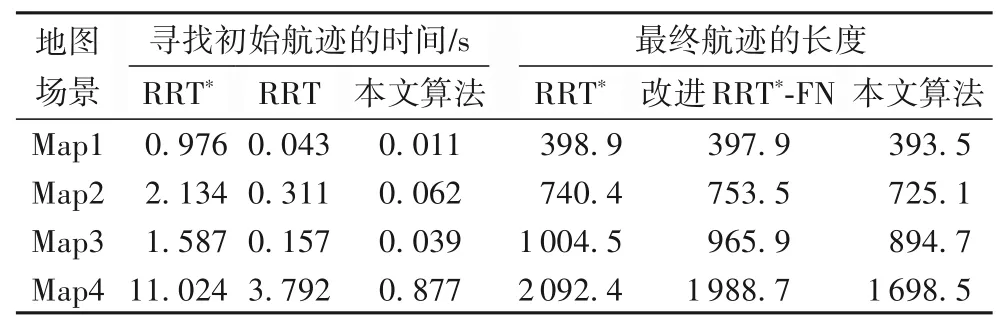
表2 不同算法性能指標平均值Tab.2 Average performance indices of different algorithms

圖6 時間與路徑長度的關系對比Fig.6 Comparison of relationship between time and path length
6 結語
本文提出的AS-RRT*算法主要是在RRT*算法基礎上對采樣空間的建模進行改進,分為搜索和優化兩階段考慮、在向光和背光區域的有偏采樣、學習高質量節點等策略都是為了降低隨機采樣帶來的負面影響。最后的實驗結果中也表明了本文方法的有效性。
本文只考慮了在靜態環境下以無人機質點模型為載體的離線路徑規劃,未來方向可考慮任務目標的運動學約束、在動態環境下在線的路徑規劃。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中老年保健(2021年12期)2021-08-24 03:30:40
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
