面向圖計算的運行時系統(tǒng)的消息聚合技術(shù)
2021-04-20 14:06:46張魯飛孫茹君
計算機應用 2021年4期
張魯飛,孫茹君,秦 芳
(1.清華大學計算機科學與技術(shù)系,北京 100084;2.數(shù)學工程與先進計算國家重點實驗室,江蘇無錫 214125)
0 引言
在社交網(wǎng)絡關(guān)系挖掘、網(wǎng)頁排序、推薦系統(tǒng)及自然語言處理等大規(guī)模數(shù)據(jù)挖掘和機器學習應用中,大量數(shù)據(jù)以圖的形式進行描述和存儲,數(shù)據(jù)存儲在圖中的頂點以及連接頂點的邊上,需要通過迭代計算的方式分析數(shù)據(jù)間的關(guān)聯(lián)性,典型的算法包括PageRank 算法、Clustering 算法、Collaborative Filtering算法等。為了應對大規(guī)模圖計算應用的問題,使用高性能計算機進行分布式并行處理成為重要的解決方案[1]。但是傳統(tǒng)的數(shù)據(jù)并行計算模型并不適用于圖計算應用,其特殊的通信模式是重要制約因素之一,目前已有多方面的通信優(yōu)化工作[2]。在應用驅(qū)動下,各種面向數(shù)據(jù)中心或者高性能計算機的圖計算平臺應運而生[3]。這些圖計算平臺采用各種手段解決通信量、負載均衡性和通信局部性等方面的問題。
圖計算應用的通信特性包括:
1)訪存/通信密集。通常圖計算算法中頂點上的計算量很小,在單機情況下訪存時間占總時間的98%以上,在分布式處理的情況下網(wǎng)絡通信和訪存占了大部分[4]。
2)隨機訪存/通信。圖計算算法有很強的數(shù)據(jù)依賴性,如圖1 所示,頂點上的計算需要收集鄰居頂點的數(shù)據(jù),圖中的兩種陰影表示兩個頂點的鄰居,一般需要沿著邊訪問鄰居頂點。但是由于圖結(jié)構(gòu)所限,沒有辦法將任意一個頂點的鄰居頂點連續(xù)存儲。在分布式處理的情況下,很難將整個大圖分割成若干完全獨立的子圖并行處理,面臨嚴重的隨機訪存/通信問題。
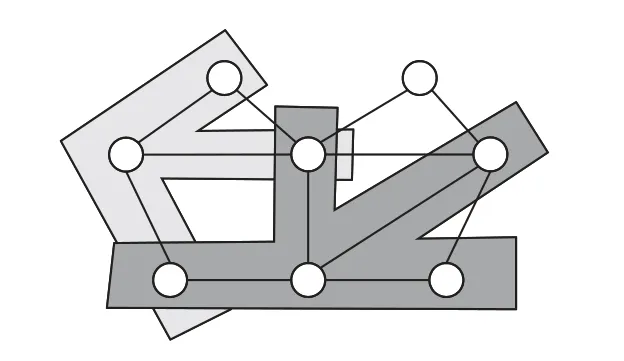
圖1 數(shù)據(jù)依賴示意圖Fig.1 Schematic diagram of data dependency
3)數(shù)據(jù)訪問粒度小。圖計算算法的數(shù)據(jù)訪問粒度一般是一個頂點或者一條邊。在分布式處理的情況下,每一次遠程訪存就需要發(fā)送一個消息,消息內(nèi)容就是頂點或者邊上的數(shù)據(jù)再加上目的地信息,形成了大量細粒度消息。
4)非規(guī)則性。實際生活中的圖一般是出于某種現(xiàn)實的目而建立的,網(wǎng)絡的度分布服從冪律(Power-Law)分布[5],即絕大多數(shù)頂點只有少量的鏈接,但極少數(shù)“樞紐”頂點卻擁有大量的鏈接。在分布式處理的情況下,可能會造成極大的負載不均衡問題。
5)動態(tài)性。很多圖計算算法采用迭代計算的方式,而且每一輪迭代中參與計算的頂點數(shù)量都可能變化。因此,事先針對負載不均衡問題采取的措施可能在實際運行過程中不能取得預期效果。
本文聚焦圖計算應用的“大量隨機細粒度消息”特征,分析消息的固定開銷對可擴展性造成的影響,并分析傳統(tǒng)的直接消息聚合方法中聚合開銷的影響,研究面向圖計算的消息聚合方法及相關(guān)運行時系統(tǒng)。本文暫不考慮圖計算應用通信的非規(guī)則性和動態(tài)性,因此也只和不做負載均衡優(yōu)化的圖計算平臺作橫向比較。
具體地,本文工作總結(jié)如下:
1)提出結(jié)構(gòu)動態(tài)的消息聚合和路由技術(shù)(Structuredynamic Message Aggregation and Routing Technique,SMART),使用參數(shù)化的虛擬拓撲將消息聚合方法應用在從源到目的地的多個中間點上,這樣一方面可以減少聚合緩沖區(qū)的數(shù)量;另一方面可以有效增強通信的局部性,提升傳遞大量隨機細粒度消息時的性能。不同虛擬拓撲結(jié)構(gòu)和配置可以使得消息聚合適應特定圖計算應用。
2)提出運行時系統(tǒng)中虛擬拓撲的消息聚合模塊VAggregator。V-Aggregator 模塊將消息聚合功能和消息路由功能分離,并加入了若干策略控制點,方便探索最優(yōu)的通信優(yōu)化策略。利用自動調(diào)優(yōu)工具可以方便地用于從多個候選策略中針對性地選擇最佳策略,有效降低應用開發(fā)人員的調(diào)優(yōu)難度。
3)提出基于消息聚合庫的圖計算平臺AGGraph。使用VAggregator 可以使得應用開發(fā)人員不需要再針對隨機細粒度消息做應用層的通信優(yōu)化,使用AGGraph 的編程接口可以方便快捷地開發(fā)一系列圖計算算法。實驗結(jié)果表明,基于AGGraph 的典型應用性能比目前常用的圖計算平臺提升100%以上。
1 相關(guān)工作
1.1 基于消息傳遞模型的圖計算平臺
很多分布式內(nèi)存系統(tǒng)上的圖計算平臺使用基于消息傳遞的通信模型,例如Pregel[6]、GPS(Graph Processing System)[7]、PBGL(Parallel Boost Graph Library)2.0[8]和Giraph[9]。在基于消息傳遞的圖計算平臺中,頂點的狀態(tài)保存在本地,通過消息傳遞方式更新其他機器上的頂點的狀態(tài)。其中,PBGL 2.0 基于Active Pebbles 編程系統(tǒng)[10]開發(fā)。Active Pebbles 使用主動消息機制,其執(zhí)行模型包含了消息聚合機制,能夠?qū)⒓毩6缺磉_映射到高效實現(xiàn),適合圖計算應用,但是消息聚合方法固定,靈活性不足。
1.2 具備消息聚合功能的運行時系統(tǒng)
Grappa[11]和Active Pebbles 編程系統(tǒng)分別在網(wǎng)絡傳輸層和運行時系統(tǒng)支持請求的聚合,基于它們實現(xiàn)的圖計算應用性能良好。此外,STAPL(Standard Template Adaptive Parallel C++Library)編程框架[12]也支持直接的消息聚合,該圖計算平臺用于位于美國勞倫斯伯克利國家實驗室(Lawrence Berkeley National Laboratory)的采用Cray XE6 架構(gòu)的“Hopper”高性能計算機。以上系統(tǒng)采用的是直接消息聚合方法,緩沖區(qū)內(nèi)存開銷存在限制,聚合隨機請求的時間開銷也較大,因此可擴展性不足。
1.3 面向消息聚合的虛擬拓撲結(jié)構(gòu)
在應用層、運行時系統(tǒng)層、網(wǎng)絡層利用虛擬拓撲結(jié)構(gòu)進行消息聚合,可以增加大量細粒度消息的聚合機會并且減少緩沖區(qū)的內(nèi)存開銷,使得應用層的細粒度通信的表達不必要翻譯成網(wǎng)絡層上的細粒度消息。虛擬拓撲結(jié)構(gòu)上的路由的基本思想是在所有節(jié)點上都提供尋址方案,并且任何消息可以僅根據(jù)當前節(jié)點的地址以及目的地節(jié)點的地址進行路由,路由的跳數(shù)與源和目的地的坐標差有關(guān)。Kumar 在Charm++運行時系統(tǒng)的通信抽象層上通過使用2D 正方形和3D 正方形虛擬拓撲上的消息聚合方法來優(yōu)化all-to-all 通信,并分析了消息數(shù)量減少的情況[13]。但是這種方法只是針對單次通信進行優(yōu)化,沒有采用流式發(fā)送策略,也沒有使用可配置的虛擬拓撲。神威·太湖之光上的圖計算平臺ShenTu[14]提出了基于分組的消息聚合技術(shù),來解決超大規(guī)模網(wǎng)絡下無規(guī)則消息的傳輸問題:一方面解決了連接數(shù)過多的問題,另一方面在系統(tǒng)規(guī)模很大的情況下提升了應用性能。但是這種方法只是針對神威·太湖之光的有裁剪的多層胖樹網(wǎng)絡結(jié)構(gòu),沒有使用可配置的虛擬拓撲。Charm++運行時系統(tǒng)上的消息聚合庫TRAM(Topological Routing and Aggregation Module)[15]使用了可以配置的虛擬拓撲,但是并沒有針對圖計算應用作深入分析。
2 結(jié)構(gòu)動態(tài)的消息聚合和路由技術(shù)
結(jié)構(gòu)動態(tài)的消息聚合和路由技術(shù)(SMART)和傳統(tǒng)的直接消息聚合方法相比強調(diào)了“結(jié)構(gòu)動態(tài)性”,體現(xiàn)在兩個方面:一是消息聚合的動態(tài)性,使用虛擬拓撲后消息可以在某一中間點上動態(tài)地聚合;二是虛擬拓撲的動態(tài)性,可以靈活地改變虛擬拓撲的配置以適應不同的軟硬件條件。
SMART使用發(fā)送端發(fā)起的消息聚合策略,如圖2所示,即發(fā)送端決定如何聚合消息以及何時發(fā)送聚合后的大消息。
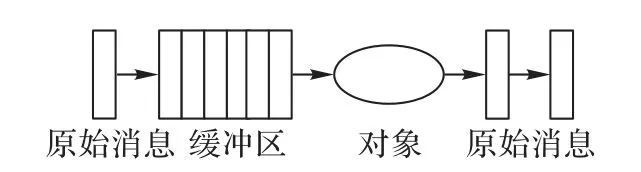
圖2 發(fā)送端發(fā)起的消息聚合策略示意圖Fig.2 Schematic diagram of message aggregation strategy initiated by sender
發(fā)送端發(fā)送聚合后的大消息的時機為到達最大緩沖區(qū)大小,緩沖區(qū)大小即消息聚合后發(fā)送的大消息的粒度。固定緩沖區(qū)大小,將緩沖區(qū)設置為與應用無關(guān)的大小,以能有效利用帶寬為宜。另外,約定每個緩沖區(qū)大小是固定的,可以增強虛擬拓撲的對稱性。
在圖計算應用中,消息的時空隨機性很強,消息隨時可能發(fā)往任意地方。可能有消息來源于不同的處理器,但前往同一目的地;也有可能來源于同一個處理器,但前往不同目的地。但是傳統(tǒng)的直接消息聚合方法只能對通信路徑完全一樣的消息進行聚合,聚合機會有限。很多編程系統(tǒng)的消息框架支持機制和策略分離,可以利用網(wǎng)絡虛擬化技術(shù),可以將任意物理拓撲結(jié)構(gòu)轉(zhuǎn)化為虛擬網(wǎng)格拓撲結(jié)構(gòu)。SMART 方法首先構(gòu)建一個廣義超立方體虛擬拓撲結(jié)構(gòu),如圖3 所示,然后將消息的通信過程劃分為若干步驟,形成若干中間目的地,在每一個中間目的地均可以重新聚合數(shù)據(jù)項。在虛擬拓撲中,即使消息的源和目的地都不相同,也可能通過一部分相同的子路徑到達目的地。
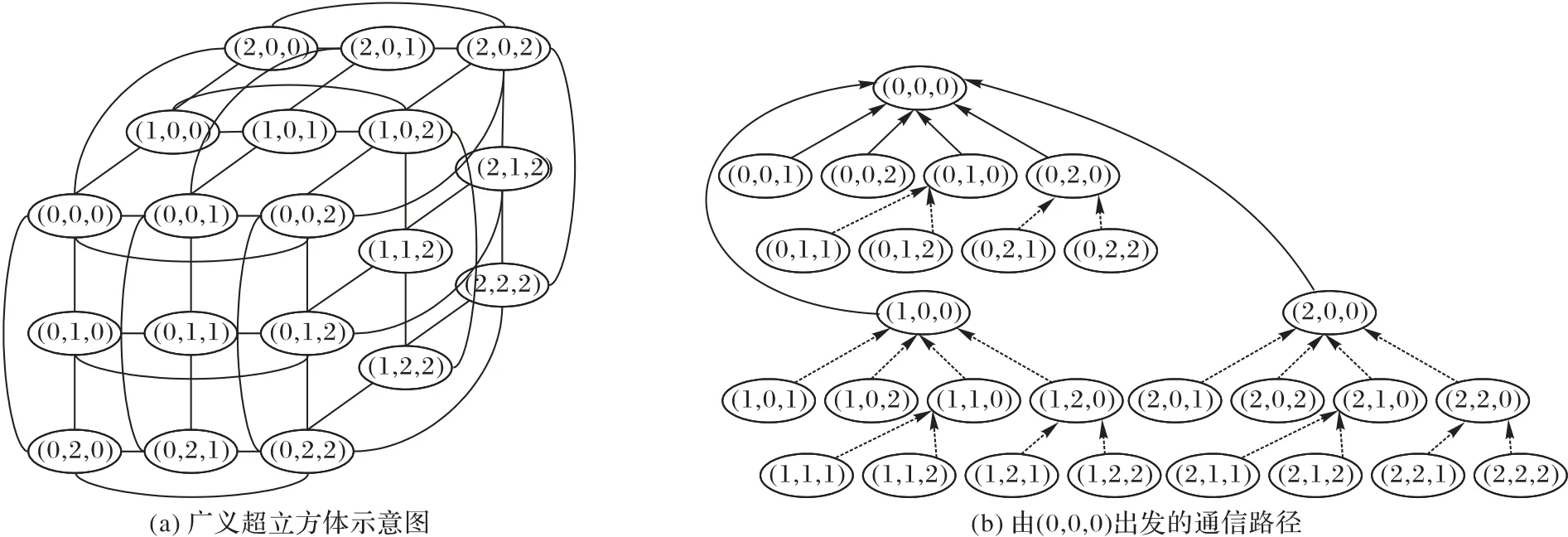
圖3 通信路徑列舉示意圖Fig.3 Schematic diagram of communication path enumeration
路由采用最高維度優(yōu)先轉(zhuǎn)發(fā)算法,即每次沿著虛擬網(wǎng)格拓撲的一個單一維度進行消息路由。這種路由算法可以保持最小路由的性質(zhì),且具有負載均衡性。
傳統(tǒng)的直接消息聚合方法在系統(tǒng)規(guī)模較大的情況下內(nèi)存開銷過大,更為重要的是,在緩沖區(qū)上重組消息通常會導致聚合開銷過大,可能會影響性能。如圖4所示,SMART使用中間頂點轉(zhuǎn)發(fā)消息可以增加聚合機會從而使得緩沖區(qū)填充速度加快,同時降低緩沖區(qū)內(nèi)存開銷。
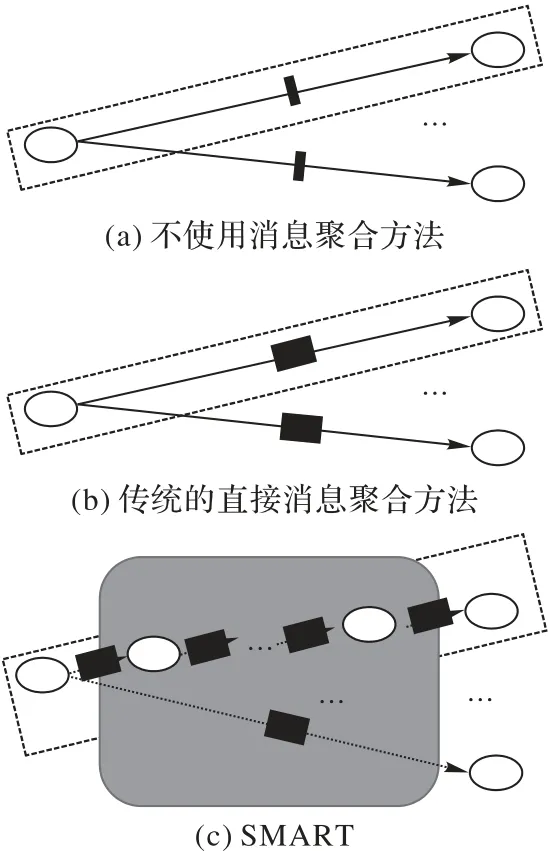
圖4 某一對頂點之間通信示意圖Fig.4 Schematic diagram of communication between a pair of vertices
SMART對于圖計算應用具有適應性,具體分析如下:
1)系統(tǒng)規(guī)模非常大時,SMART 在減少消息聚合方法使用的緩沖區(qū)的內(nèi)存開銷方面意義重大。
2)對于圖計算應用“大量細粒度消息流式發(fā)送”的通信特征,消息聚合方法可以減少發(fā)送消息次數(shù)從而減少固定開銷。
3)對于圖計算應用的“時空隨機通信”的通信特征,消息聚合方法帶來的聚合開銷對性能影響較大,SMART 相較于傳統(tǒng)的直接消息聚合方法因為聚合開銷減少而獲得一定的加速效果。
4)系統(tǒng)規(guī)模越大,SMART 使用虛擬拓撲增加消息聚合的機會從而減少,聚合開銷的優(yōu)勢越大。
5)隨著虛擬拓撲的維度數(shù)量的增加,消息聚合方法獲得的收益和付出的代價都在增加。當維度大到一定程度時,由于重復發(fā)送數(shù)據(jù)造成的可變開銷增加會使得SMART 不能取得預期效果。
6)SMART 并不能解決圖計算應用的“非規(guī)則通信”的問題,但是SMART本身不會引入負載不平衡問題。
3 面向圖計算的消息聚合運行時實現(xiàn)
在通信軟件棧的不同層次都可以使用消息聚合方法,越接近應用層,越有利于減少發(fā)送和聚合后的數(shù)據(jù)項相關(guān)的消息頭,越有利于減少通信軟件棧底層的通信開銷。但是通信軟件棧中的層次越高,和應用本身的相關(guān)性越強。因此,在運行時系統(tǒng)層使用消息聚合方法有兩點優(yōu)勢:一是效果好,可以減少在網(wǎng)絡和運行時系統(tǒng)層的頭部數(shù)據(jù),降低細粒度通信的可變開銷和固定開銷;二是通用性好,將消息聚合行為抽象為一些簡單接口提供給應用程序,可以方便為應用開發(fā)人員所使用。如圖5 所示,通過縱向增加軟件層次,橫向拓展軟件功能,形成網(wǎng)絡虛擬化的通信軟件棧V-Aggregator。
V-Aggregator 為應用開發(fā)人員提供了簡單、優(yōu)化的細粒度通信接口,并支持應用開發(fā)人員根據(jù)各種軟硬件條件靈活配置參數(shù)以得到最優(yōu)性能,這些參數(shù)包括拓撲結(jié)構(gòu)、緩沖區(qū)大小。由于圖計算應用一般有迭代的過程,V-Aggregator 可在應用程序確定一組配置集合后,在每一輪迭代中自動地嘗試各種配置,直到收斂到最佳的解決方案。
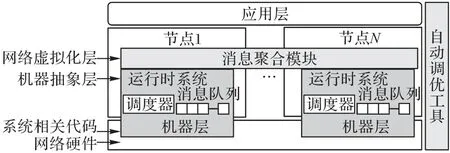
圖5 網(wǎng)絡虛擬化的通信軟件棧V-Aggregator示意圖Fig.5 Schematic diagram of communication software stack for network virtualization named V-Aggregator
基于V-Aggregator 實現(xiàn)的圖計算平臺AGGraph 是以頂點為中心的:將一個頂點作為一個基本對象,用戶只需要按照模板實現(xiàn)不同的頂點類就可以實現(xiàn)不同的圖計算算法。
在AGGraph 中,主對象Mainchare 負責創(chuàng)建頂點對象集合,并協(xié)調(diào)它們之間的計算和通信;而頂點對象Vertex 主要負責處理頂點之間的消息。
AGGraph的一般處理流程是:
1)主對象使用適當?shù)腉raphIO 對象讀取圖數(shù)據(jù),并將頂點和邊數(shù)據(jù)發(fā)送到每個頂點對象。
2)使用運行時系統(tǒng)的靜默檢測功能來確定所有數(shù)據(jù)都已發(fā)送到對應的頂點對象,然后發(fā)起start()回調(diào),此回調(diào)函數(shù)在不同計算模型下,以不同的方式調(diào)用頂點對象的run()方法。
3)每個超步結(jié)束時調(diào)用check(),決定整個計算是否結(jié)束。
4 實驗分析
4.1 實驗環(huán)境
實驗使用CPU通用計算系統(tǒng),詳細配置如表1所示。

表1 系統(tǒng)軟硬件配置Tab.1 System hardware and software configuration
測試程序為基于AGGraph 實現(xiàn)的PageRank 算法、寬度優(yōu)先搜索(Breadth-first Search,BFS)算法、連通分支(Contected Component,CC)算法[16]。
測試數(shù)據(jù)為生成的不同運行規(guī)模(scale)的R-MAT(Recursive MATrix)圖[17],總的頂點數(shù)量為2scale。具體方法為,利用Graph500 測試規(guī)范中的克羅內(nèi)科(Kronecker)生成器[18]產(chǎn)生服從冪律分布的邊因子(edgefactor)為16 的無向圖,每個頂點使用8個字節(jié)存儲。
4.2 實驗結(jié)果
分別測試同步計算模式下的PageRank 算法、異步計算模式下的BFS算法、異步計算模式下的CC算法使用原有通信框架(naive)和V-Aggregator 的性能,并和PBGL(Parallel Boost Graph Library)[19]中的算法作比較。選用PBGL 作為對比平臺主要是由于它只是做了簡單通信優(yōu)化,沒有采用過多的負載均衡優(yōu)化,和本文研究出發(fā)點類似。采用強可擴展性測試,物理資源規(guī)模分別為1、2、4、8、16、32個節(jié)點,一個節(jié)點上運行8個程序?qū)嵗_\行規(guī)模分別為20、22。
1)PageRank算法。
指定迭代次數(shù)為3。通過使用自動調(diào)優(yōu)工具確定:節(jié)點數(shù)量在1 至4 時,最優(yōu)策略為1 維虛擬拓撲結(jié)構(gòu),緩沖區(qū)大小為2 KB;節(jié)點數(shù)量在8 至16 時,最優(yōu)策略為2 維虛擬拓撲結(jié)構(gòu),緩沖區(qū)大小為2 KB;節(jié)點數(shù)量為32 時,最優(yōu)策略為3 維虛擬拓撲結(jié)構(gòu),維度大小分別為4、8 和8,緩沖區(qū)大小為4 KB。強可擴展性測試結(jié)果如圖6所示。

圖6 不同運行規(guī)模時PageRank算法的測試結(jié)果Fig.6 Test results of PageRank algorithm under different running scales
2)BFS算法。
通過使用自動調(diào)優(yōu)工具確定:節(jié)點數(shù)量在1 至2 時,最優(yōu)策略為1 維虛擬拓撲結(jié)構(gòu),緩沖區(qū)大小為4 KB;節(jié)點數(shù)量在4至32 時,最優(yōu)策略為2 維虛擬拓撲結(jié)構(gòu),緩沖區(qū)大小為8 KB。強可擴展性測試結(jié)果如圖7所示。
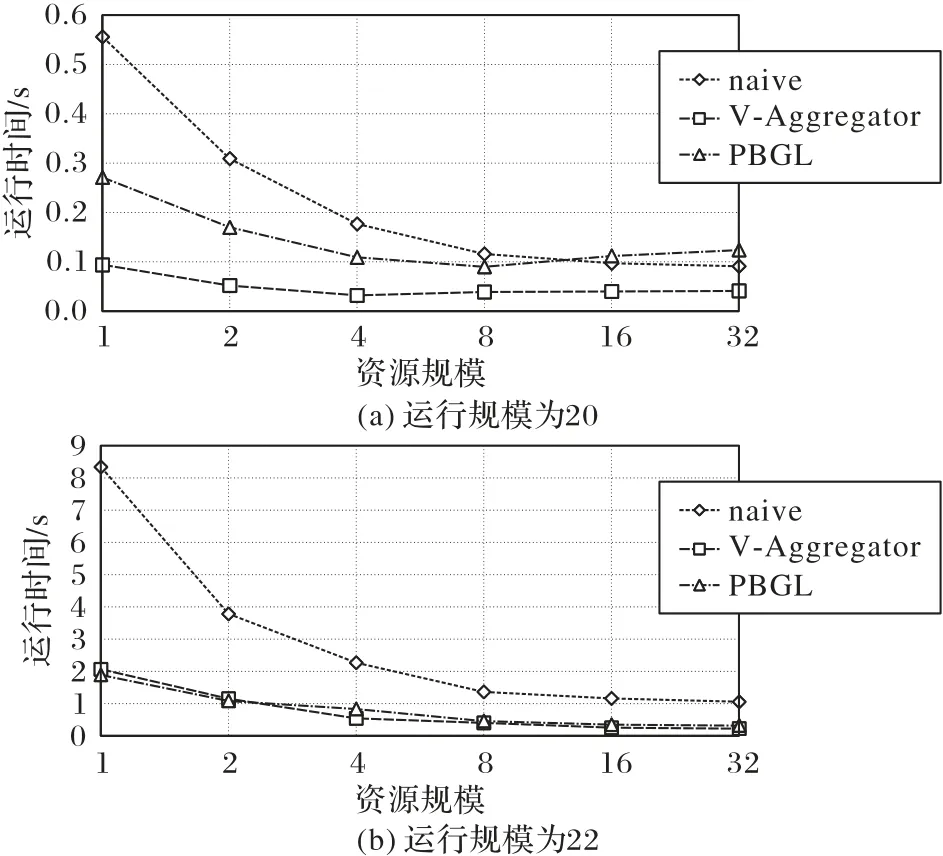
圖7 不同運行規(guī)模時BFS算法的測試結(jié)果Fig.7 Test results of BFS algorithm under different running scales
3)CC算法。
通過使用自動調(diào)優(yōu)工具確定:節(jié)點數(shù)量在1 至2 時,最優(yōu)策略為1 維虛擬拓撲結(jié)構(gòu),緩沖區(qū)大小為2 KB;節(jié)點數(shù)量在4至16 時,最優(yōu)策略為2 維虛擬拓撲結(jié)構(gòu),緩沖區(qū)大小為2 KB;節(jié)點數(shù)量為32時,最優(yōu)策略為3維虛擬拓撲結(jié)構(gòu),維度大小分別為4、8 和8,緩沖區(qū)大小為4 KB。強可擴展性測試結(jié)果如圖8所示。
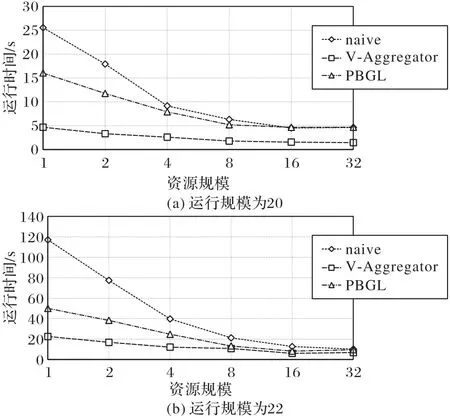
圖8 不同運行規(guī)模時CC算法的測試結(jié)果Fig.8 Test results of CC algorithm under different running scales
4.3 結(jié)果分析
V-Aggregator相對PBGL加速比如表2所示。
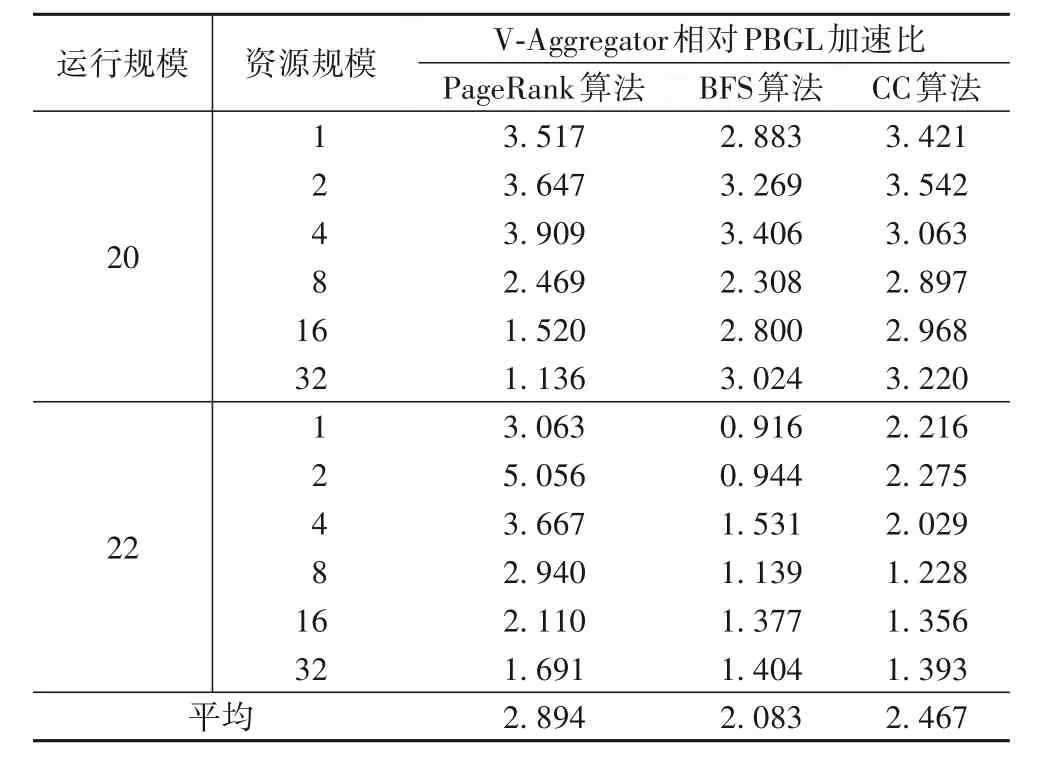
表2 運行規(guī)模為20和22時V-Aggregator相對PBGL加速比Tab.2 Acceleration ratio of V-Aggregator to PBGL at running scale of 20 and 22
可以得到以下結(jié)論:
1)AGGraph 圖計算平臺可以有效支持應用開發(fā)人員方便、快捷、正確地實現(xiàn)圖計算算法,在節(jié)點數(shù)量32 以內(nèi)可擴展性良好。
2)基于V-Aggregator 模塊實現(xiàn)的典型圖計算算法比使用原有通信框架時性能大幅提升,比目前常用的圖計算平臺PBGL 提升100%以上。PBGL 圖計算平臺使用了傳統(tǒng)的消息聚合方法,因此AGGraph 相對于它的加速比可以體現(xiàn)本文所提出的基于虛擬拓撲的消息聚合方法的優(yōu)勢。
3)基于V-Aggregator 模塊實現(xiàn)的典型圖計算算法中,PageRank 算法加速效果最好,BFS算法加速效果最差,區(qū)別在于PageRank 算法比BFS 算法更加規(guī)整,主要是由于本平臺沒有考慮非規(guī)則性方面的優(yōu)化。
5 結(jié)語
本文根據(jù)圖計算應用“大規(guī)模流式非規(guī)則隨機細粒度消息”的通信特征提出了基于虛擬拓撲的結(jié)構(gòu)動態(tài)的消息聚合和路由技術(shù),并給出了該方法的適用范圍。本文提出了運行時系統(tǒng)面向消息聚合的網(wǎng)絡虛擬化技術(shù),對原有通信接口做微小改動后即可支持消息聚合方法,便于應用開發(fā)人員使用。該運行時支持自動調(diào)優(yōu),可以方便地用于從多個候選策略中選擇最佳策略,真正意義上實現(xiàn)“結(jié)構(gòu)動態(tài)”。基于上述技術(shù),本文設計并實現(xiàn)了一個基于消息聚合技術(shù)的圖計算平臺,可以實現(xiàn)根據(jù)軟硬件條件自動地選擇最優(yōu)通信策略,支持以頂點為中心的編程模型,并開發(fā)了若干圖計算算法。最后,通過大量實驗驗證了本文所提算法的有效性和實用性。
本文選取的對比平臺時間并不能代表圖計算平臺的最前沿技術(shù),下一步會基于消息聚合運行時設計更加先進的圖計算平臺,重點解決圖計算應用通信的非規(guī)則性和動態(tài)性問題,然后再和業(yè)界領(lǐng)先的圖計算平臺作橫向比較。
猜你喜歡
工業(yè)設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
