基于物聯網的種鴨育成測定數據平臺的設計與實現
2021-04-18 21:25:27劉慶武付美艷張萬民
科技風 2021年10期
關鍵詞:物聯網
劉慶武 付美艷 張萬民

摘 要:對種鴨育成期的養殖過程中的數據進行人工處理存在強度大、效率低甚至數據錯誤等問題。采用軟件即服務的模式,參照Lambda數據處理架構,將物聯網技術與生物統計技術相結合,設計并實現種鴨育成測定數據平臺,通過非介入、動態、實時的方式采集、分析與處理數據,充分挖掘數據的價值,為種鴨精準飼養和科學化管理提供必要的數據支撐。
關鍵詞:種鴨;育成測定;物聯網;生物統計;Lambda;數據平臺;平滑處理
我國肉鴨消費具有多元化特點,瘦肉型與肉脂型北京鴨、優質小體型肉鴨、番鴨與半番鴨的年出欄量超過35億只,產值約1000億元。[1]肉鴨養殖在解決糧食危機、提高農民收入、保障優質蛋白供給以及促進農村穩定等方面發揮了重要作用。種鴨是肉鴨生產的基礎,只有種質優良、體質健壯的種鴨,才能生產出更多的優質商品鴨苗。育成期是父母代種鴨生長中最重要的時期,也是決定種鴨能否獲得高產、穩產的關鍵。這一階段飼養的特點是對種鴨進行限制性飼養,即有計劃地控制飼喂量(量的限制)或限制日糧的蛋白質和能量水平(質的限制)。[2]當前我國種鴨養殖分散、信息化水平低、基礎設施投資不足,且應用企業引進的管理系統以單機版為主,各系統缺乏統一的接口而互不通用,造成信息孤島,致使已有的信息化投入不能產生規模效應。[3]
物聯網是基于計算機互聯網的延伸與擴展,它是利用RFID(射頻識別)、傳感器等技術隨時隨地捕獲物體的標識信息,通過各種通信網絡進行可靠傳輸與信息共享,并借助智能的數據處理技術進行挖掘與分析,最終實現智能化控制與決斷的覆蓋世界上萬事萬物的“Internet of Things”。[4-5]
采用軟件即服務(SaaS)模式,構建基于物聯網的種鴨育成測定數據平臺,將物聯網技術與生物統計技術相結合,根據種鴨育成期的養殖過程的數據,通過生物統計分析與處理得到精準的飼料需求,為種鴨精準飼喂和科學化管理提供必要的數據支撐。
一、設計
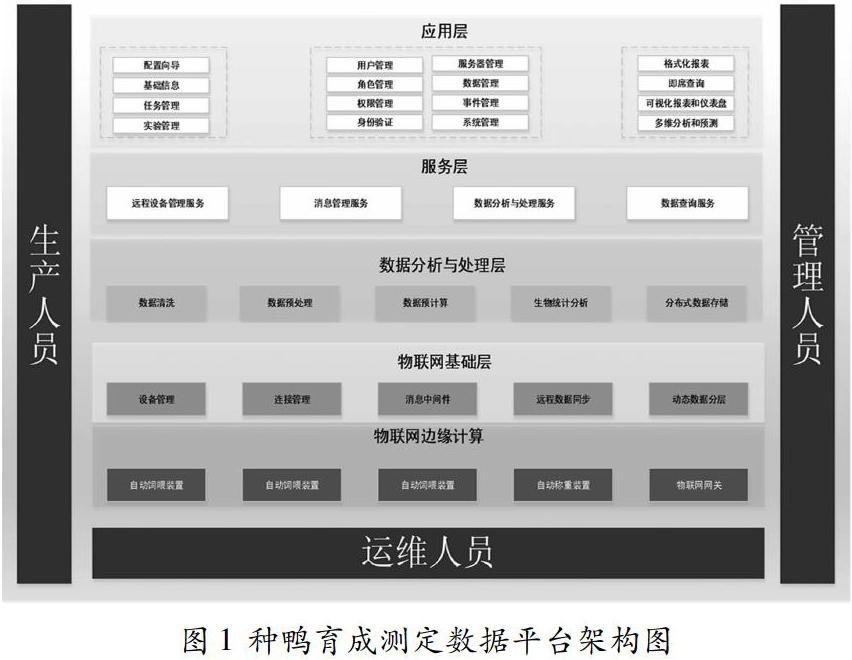
體系結構:遵循開放性、擴展性、安全性和可靠性等設計原則,種鴨育成測定數據平臺采用“統一支撐平臺框架、多個平臺應用模組”的架構,如圖1所示。
(1)物聯網邊緣計算(IoT Edge):是平臺的數據來源,包括自動飼喂裝置、自動稱重裝置、飼料余量監測以及物聯網網關。通過物聯網網關(IoT Gateway,可以是Rasberry Pi、Smart Phone、Local PC、Remote Server等)實現測定裝置的互聯互通以及實時數據緩存。
(2)物聯網基礎層(IoT Foundation):在物聯網客戶端的物理基礎上,使用設備管理和連接管理功能實現設備集成,創建并且提供安全可靠的數據鏈路;通過消息中間件(MQTT、Kafka等)和遠程數據同步獲取育成測定數據;根據訪問數據的頻次,實現不同“溫度”數據的動態分層存儲。
(3)數據分析與處理層(Data Analyse and Process Layer):是平臺的核心層,包括數據清洗、數據預處理、數據預計算、生物統計分析與分布式數據存儲。數據清洗用于刪除原始采食數據集和原始稱重數據集中的無關數據、重復數據,平滑噪聲數據,處理缺失值和異常值;數據預處理包括與企業管理信息系統的數據集成,對采集時間、采食量以及稱重值的規范化處理。還需要利用基本屬性構造出新的屬性,例如個體日增重、個體日采食量、個體日累積采食量、個體日料肉比、個體日采食次數、個體日采食時長、個體日采食效率等。數據預處理一方面提高了數據質量,另一方面讓數據更好地適應數據分析與處理的需要;另外,數據分析與處理層還包括生物統計中常用的假設檢驗和置信區間估計方法(參數假設檢驗、非參數假設檢驗、Bootstrap方法等),常用的回歸方法(線性回歸分析、非線性回歸分析等)以及數據的分類、聚類分析(邏輯回歸、支持向量機、隨機森林的分類方法、K-Means等)。同時,將預處理后數據、預計算與統計分析的結果做進一步分布式存儲。
(4)服務層(Serving Layer):包括遠程設備管理服務、消息管理服務、數據分析與處理服務與數據查詢服務。通過屏蔽不同類型設備的技術參數,為上一層(應用層)提供標準、統一的設備管理接口;通過屏蔽底層數據存儲的差異性,為應用層提供標準、統一、方便、安全的數據查詢接口;使用消息管理服務協調遠程設備管理服務、數據分析與處理服務以及數據查詢服務的協同作業。
(5)應用層(Application Layer):與服務層的統一標準不同,應用層提倡定制化與百花齊放。從數據源到數據采集、數據清洗、數據預處理、數據預計算、數據存儲、數據服務,最終到數據應用,數據的價值只有在應用層才能真正得以體現。
應用層主要包括集中管理控制臺CMC(Central Management Console)、企業配置向導與商業智能BI(Business Intelligence)。其中,集中管理控制臺是基于Web的管理工具,用于執行大部分日常管理任務,例如角色管理、用戶管理、權限管理、身份認證、數據管理和服務器管理等;企業配置向導是企業用戶使用平臺功能的前提和基礎,包括注冊企業基本信息、創建企業賬號信息(包括企業管理員和任務管理員)、完善養殖企業的組織機構信息(包括養殖場信息、棟|舍信息、欄|圈信息、企業品種信息、企業品系信息、企業飼料信息以及企業個體信息等)、實驗管理以及任務管理等;商業智能提供格式化報表、即席查詢、可視化報表和儀表盤以及多維分析和預測等多種可視化數據分析與探索工具。
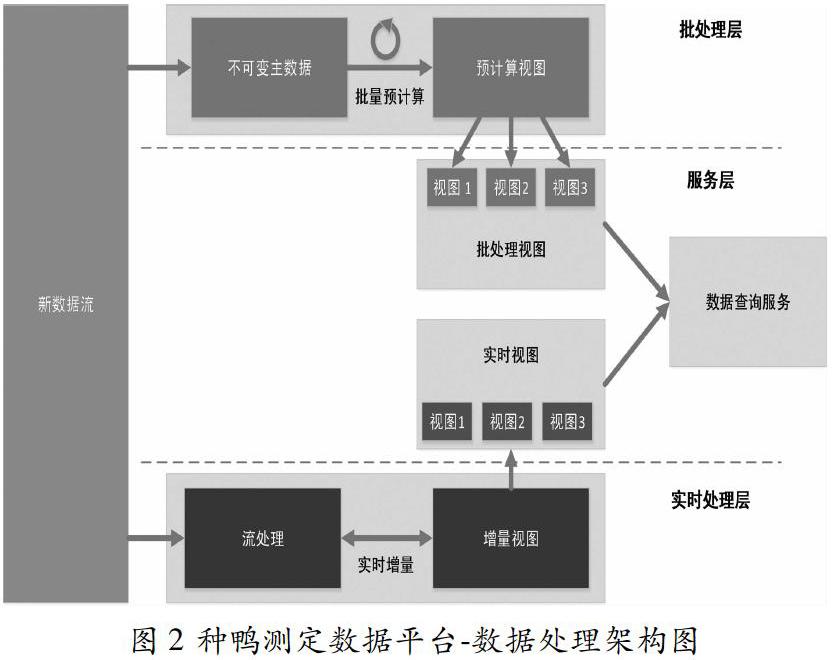
二、數據處理架構
參照Lambda架構設計思想,將數據處理架構分為批處理層(Batch Layer)、實時處理層(Speed Layer)、服務層(Serving Layer)。Lambda架構最重要的特征有:
(1)容錯性:即使出現故障,仍然能夠實際滿足需要(如果出現故障,數據不會丟失,可以從主數據集重新計算);
(2)橫向擴容:當數據量/負載增大時,可以通過增加更多的硬件資源來保證性能。也就是通常所說的線性可擴展,采用Scale out(即通過增加機器的個數)而不是Scale up(通過增強機器的性能);
(3)低延遲的讀寫過程:采用并行計算,盡量縮短了系統響應的延遲時間;
(4)快速查詢:需要能夠方便、快速地查詢所需要的信息。
平臺數據處理架構如圖2所示:
(5)批處理層。輸入的新數據將被導入批處理層和實時處理層。在批處理層,輸入數據將被添加到Master數據集。批處理層對Master數據集進行迭代計算。當批處理層對全部數據進行批處理計算后,可以得到批處理視圖,并且通過數據查詢服務對外提供標準、統一、方便、安全的數據查詢接口。批處理層通過定時任務的方式更新批處理視圖,以保證數據的高容錯性。
(6)實時處理層。實時處理層負責實時處理增量數據,通過實時計算更新實時視圖,彌補了批量視圖更新的較高延遲。
(7)服務層。服務層的任務是根據查詢條件為用戶查詢提供支持。服務層隨機訪問視圖,將批處理視圖和實時視圖的結果結合起來,最后反饋給應用層。
三、關鍵技術
個體稱重數據的平滑處理方法。在育成測定應激期內,個體間存在不同程度的應激反應,也會出現多只擠入稱重裝置的現象。不可避免地導致干擾成分混雜進個體稱重數據,通常這些干擾成分往往呈現非線性、非平穩性和非光滑性等特點,給后續數據分析和處理帶來了誤差甚至會導致錯誤。
為了從稱重數據快速、高效地提取有用的特征信息,必須對稱重數據進行平滑處理,即消除或抑制干擾成分的影響。使用局部加權回歸散點平滑法(locally weighted scatterplot smoothing,LOESS),擬合一條連續的曲線,以該曲線作為基準,偏離較遠的則標記為異常值點。MATLAB是美國Mathworks公司開發的應用軟件,具有強大的科學及工程計算能力。[6]它不但提供了專門用于數據平滑處理的smooth函數,而且通過MATLAB引擎可以調用MATLAB中大量的數學計算函數,完成復雜的計算任務,從而簡化用戶程序設計的任務。
個體稱重數據平滑處理流程圖如圖3所示。
(1)從歷史稱重數據表和實時稱重數據內存表中獲取指定個體的歷史稱重數據和實時稱重數據,合并成完整的個體稱重數據集;
(2)從平臺配置信息中分別讀取兩次平滑處理的SPAN值(即窗寬值)與基于參照稱重值的上下相對浮動范圍;
(3)使用MATLAB引擎,調用封裝后的smooth函數(MATLAB提供了多種調用格式,實際使用Z=smooth(Y,SPAN,METHOD),其中Z為平滑處理后的個體參照稱重數據;Y為個體稱重數據,SPAN為窗寬值,取0.2;METHOD為平滑方法,取lowess,即加權線性擬合,一階回歸)對個體稱重數據集進行第一次平滑處理;
(4)遍歷個體稱重數據集,逐一判斷該值是否偏離設定1允許的范圍。如果已偏離,則標記為異常稱重數據(只作標記,不刪除)。遍歷后,篩選出第一次平滑處理后新的個體稱重數據集(不含已標記異常值的稱重數據);
(5)重復(3)~(4),得到經過兩次平滑處理的個體稱重數據集。
四、分布式關系型數據庫
種鴨育成測定數據平臺在SAP的SQLAnywhere網絡數據庫的基礎上,通過橫向擴展的方式,構建“集中管理系統數據庫—企業基本信息數據庫—企業育成測定數據庫”的三級、分布式關系型數據庫。
(一)集中管理系統數據庫(CMC System Database)
CMC系統數據庫用于存儲與維護種平臺運行的所需公共基礎信息,包括:幣種信息、國家信息、區域信息、時區信息、語言信息、畜種信息、品種信息、品系信息、設備制造商信息、設備類型信息;企業信息、角色信息、權限信息、用戶信息、用戶個性化信息;企業基本信息數據庫的路由信息、系統參數信息和服務器信息。
(二)企業基本信息數據庫(Enterprise Master Database,Scalable)
企業基本信息數據庫用于存儲與維護養殖企業基礎信息,包括養殖場信息、棟舍信息、欄圈信息、生物個體信息、群組信息、群組成員信息、設備信息、測定任務信息、飼料信息、飼料價格變動信息、原料信息、原料價格變動信息等;在育成測定過程中必要的操作信息,包括:個體健康狀態標記、個體淘汰、更換飼料、更換個體耳標;以及企業育成測定數據庫路由信息。
(三)企業育成測定數據庫(Enterprise Slave Database,Scalable)
企業育成測定數據庫用于存儲與維護在育成測定過程中生成的原始數據、預處理后的數據、預計算以及生物統計分析的計算結果,包括:原始稱重數據、原始空腹稱重數據、原始采食數據、原始環境數據、原始設備狀態數據、預處理后的稱重數據、預處理后的采食數據、預處理后的環境數據、個體日結數據、群體日結數據、設備報警信息等。
五、防錯與出錯處理
在參照Lambda架構的基礎上,通過多級分布式存儲和基于生命周期的動態管理相結合的方式存儲和維護育成測定過程中的數據(包括原始數據、預處理后的數據、日結數據以及生物統計分析數據),不僅可以啟動、結束育成測定任務,而且可以暫停(支持多次)、重啟(支持多次),有效地避免人為操作失誤或其他未知原因造成的異常和錯誤。
另外,種鴨育成測定平臺以“事件”的方式按照預設的事件類型,詳細記錄事件發生源、事件類型、是否已啟用報警、事件的文字描述、事件發生的時間以及處理結果。
六、應用案例
種鴨育成測定數據平臺配合中國農業科學院北京畜牧獸醫研究所先后完成北京鴨Z10(測定起止時間:2019-09-01 11:48:51~2019-09-26 05:56:56,測定鴨只數量:38),Z78(測定起止時間:2020-05-27 16:04:41~2020-03-25 11:45:24,測定鴨只數量:483)以及Z4(測定起止時間:2020-04-07 17:09:06~2020-04-30 03:29:37,測定鴨只數量:407)的育成測定任務。一方面提高了養殖企業的自主智能化程度,大大降低人力成本和勞動強度;另一方面改變了養殖場傳統的人工處理方式,徹底解脫了管理人員煩瑣的、重復的、甚至不準確的手工匯總統計工作,為種鴨育成期的精準飼養和科學化管理提供必要數據支撐。
參考文獻:
[1]侯水生.我國水禽產業技術的發展戰略[J].水禽世界,2011(6):8-9.
[2]張武鵬.育成期種鴨的飼養管理技術[J].養殖與飼料,2007(1):17-18.
[3]韓紅蓮,張敏.發達國家畜牧業物聯網模式對我國的啟示[J].黑龍江畜牧,2015(5)28-29.
[4]沈彥君.物聯網技術在智能圖書館中的應用[J].國家圖書館學刊,2012,21(02):51-54.
[5]王艷軍,呂志勇,黃蕾.基于物聯網傳感器的城市交通狀態預測[J].武漢理工大學學報,2010,32(20):108-111.
[6]張亮均,等.MATLAB數據分析與挖掘實戰[M].北京:機械工業出版社,2015(6):7-8.
作者簡介:劉慶武(1977— ),男,山東濟寧人,碩士,工程師,研究方向:軟件技術生物統計;付美艷(1980— ),女,山東平度人,碩士,副教授,研究方向:計算機應用技術;張萬民(1959— ),男,山東壽光人,碩士,教授,研究方向:物聯網軟件工程。
猜你喜歡
軟件導刊(2016年9期)2016-11-07 21:56:29
軟件導刊(2016年9期)2016-11-07 21:32:45
中國科技博覽(2016年22期)2016-11-01 15:02:01
中國科技博覽(2016年22期)2016-11-01 13:21:09
中國科技博覽(2016年19期)2016-10-19 14:58:22
電腦知識與技術(2016年21期)2016-10-18 22:33:02
科技視界(2016年22期)2016-10-18 17:23:30
中國新通信(2016年16期)2016-10-18 11:01:39
中國新通信(2016年16期)2016-10-18 11:00:54
科學與財富(2016年28期)2016-10-14 01:24:06
