基于深度神經網絡的噪聲環境下對話行為分類模型
2021-04-07 06:29:00申屠相镕秦會斌
測控技術 2021年3期
申屠相镕, 秦會斌
(杭州電子科技大學 新型電子器件與應用研究所,浙江 杭州 310018)
在現代化的腳步不斷向前邁進的今天,人們對于計算機的依賴程度與日俱增,如何用計算機方法來處理人類的自然語言也成了熱門的研究內容。對話行為分類是實現與數據庫的自然語言對接的一項重要任務,因為說話者的意圖可以用對話行為(與語境無關的語義和依賴于語境的謂語)[1]來表示。
為了解決對話行為分類中的模糊問題,過去20年來學者們提出了各種機器學習模型。文獻[2]研究了稀疏建模方法來改善對話行為分類,提出稀疏對數線性模型,相對于基于規則的基線模型獲得了19.7%的相對改善,并且超過了先進的支持向量機(Support Vector Machines,SVM)模型2.2%。文獻[3]研究了多核SVM模型來處理對話行為識別問題,提出了一種改進的多核SVM模型并在一些開放分類任務和中文對話行為識別任務上進行測試。文獻[4]研究了對話法分類,提出了一種新的生成神經網絡體系結構,在循環神經網絡框架的基礎上結合了一種新的注意技術和序列學習的標簽-標簽連接。文獻[5]證明使用高斯過程(Gaussian Process,GP)的貝葉斯優化超參數可進一步改進結果,并且縮短計算時間。文獻[6]對使用提示短語作為對話行為分類的基礎進行了調查,通過提示短語來定義含義,并描述如何從手動標記的對話語料庫中提取它們。但以上文獻均采用實驗室環境中純凈的原始語音作為測試樣本,實際的對話環境中常常存在噪聲的干擾,因此需要建立一個能夠有效應對噪聲環境的對話行為分類模型。
本文提出了一個使用快速噪聲估計譜減法、卷積神經網絡(Convolutional Neural Network,CNN)和長短期記憶(Long-Short Term Memory,LSTM)網絡的對話行為分類模型。該模型先將原始話語進行語音增強,再通過使用卷積神經網絡將輸入話語概括為嵌入向量,然后通過基于長短期記憶網絡的上下文信息關聯,使用對話行為標簽來標注話語序列。在測試階段,將分別用文獻[2]與文獻[4]的算法對包含噪聲的語音樣本進行測試并對比結果。
1 基于快速噪聲估計的譜減法
快速噪聲估計頻譜相減的基本原理是在短期平穩語音信號和加性噪聲之間彼此獨立的假設前提下,將噪聲的功率譜從包含噪聲的語音功率譜中減去,從而得到更加純凈的語音頻譜[7]。假設s(n)是純語音信號,d(n)是噪音信號,y(n)是包含噪音的語音信號,那么可以得到以下表達式:
y(n)=s(n)+d(n)
(1)
Y(k),S(k)和D(k)分別表示y(n),s(n)和d(n)的離散傅里葉變換結果,如下所示:
Y(k)=S(k)+D(k)
(2)
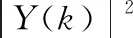
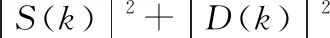
(3)
由于噪聲信號與語音信號是彼此獨立的,而且D(k)是服從E(D(k))的高斯分布,所以可以得到以下等式:
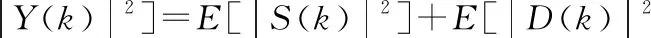
(4)
對于一個具有短時靜止特性的語音信號來說,可以得到:
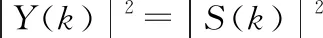
(5)
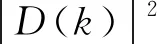
(6)
式中,|S(k)|為增強后的語音信號幅度。
在語音頻譜中第k個頻譜分量的增益函數定義為
(7)
并且后驗信噪比的定義為
(8)
所以可以得到:
(9)
值得注意的是,當γ(k)>1且G(k)<0時,方程將變得無意義。為了避免這種情況,不妨進行以下改寫:
(10)
式中,ε為一個大于0的常數。
從以上方程中可以得出, 頻譜相減的本質是給噪聲的每個含有噪聲的頻譜分量乘以一個系數G(k),G(k)的值與噪聲呈正相關。在高信噪比的情況下有效語音信號的比重較大而噪聲占比較小,因此G(k)是較小的。而在低信噪比的情況下G(k)較大。通過式(1)~式(3)將包含噪聲的語音信號進行快速傅里葉變換,再通過式(4)~式(6)完成噪聲參數估值,通過式(7)~式(10)可以計算獲得語音增強后的增益,最后通過快速傅里葉逆變換即可得到增強后的語音信號,具體的流程框圖如圖1所示。
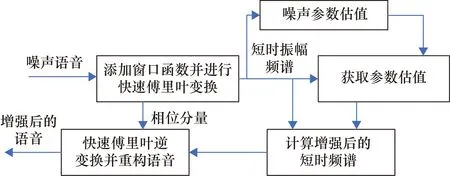
圖1 快速噪聲估計頻譜相減的結構圖
2 基于CNN和LSTM的語音分類模型
為了處理增強后的語音信號,筆者提出了一個使用卷積神經網絡[8]和長短期記憶網絡[9]的語音識別模型。模型利用卷積神經網絡將輸入話語轉化為嵌入向量,然后利用基于長短期記憶神經網絡的上下文信息匹配法對話語行為標簽和話語行為序列進行注釋。
設C1,n為一個包含n個對話的對話集,設S1,n為對話集內的一個語義,P1,n是一個包含了C1,n中謂語的集合。從而可以建立以下公式:
DA(C1,n)=argmaxS1.n,P1,nP(S1,n,P1,n|C1,n)
(11)
可以假設一句話的語義和一個謂語是相互獨立的[10]。基于這個假設,將式(11)簡化為
DA(C1,n)=argmaxS1.n,P1,nP(S1,n|C1,n)P(P1,n|C1,n)
(12)
式(12)又可以通過以下兩個假設簡化為式(13):
① 一階馬爾可夫假設,即當前類別(即當前語義或當前謂詞)依賴于前一類別(即先前的語義或先前的謂語);
② 條件獨立假設,即當前類別僅依賴于當前話語的觀察信息。
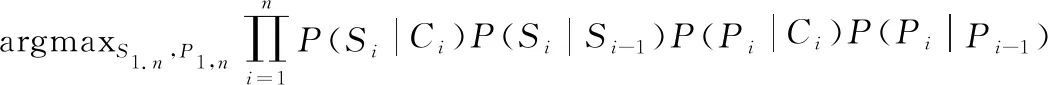
(13)
在式(13)中,由于說話人在真實對話中根據個人語言意義使用各種句子表面形式表達相同的內容,所以不可以直接計算P(Si|Ci)和P(Pi|Ci)。為了克服這個問題,本文使用CNN模型將說話人的話語概括為嵌入向量,如圖2所示。
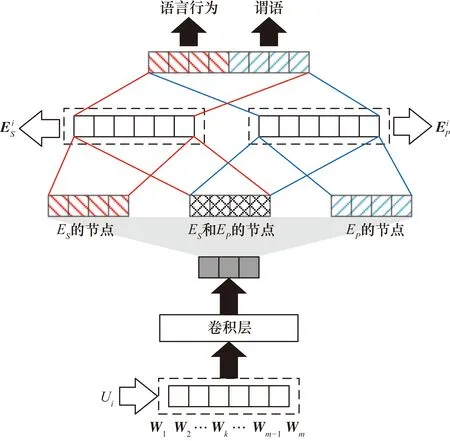
圖2 使用CNN的語言嵌入
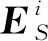
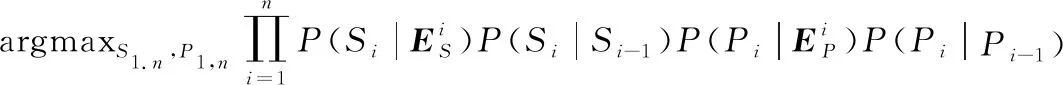
(14)
為了獲得最大化方程(14)的序列標簽S1,n和P1,n,本文采用LSTM模型,如圖3所示。
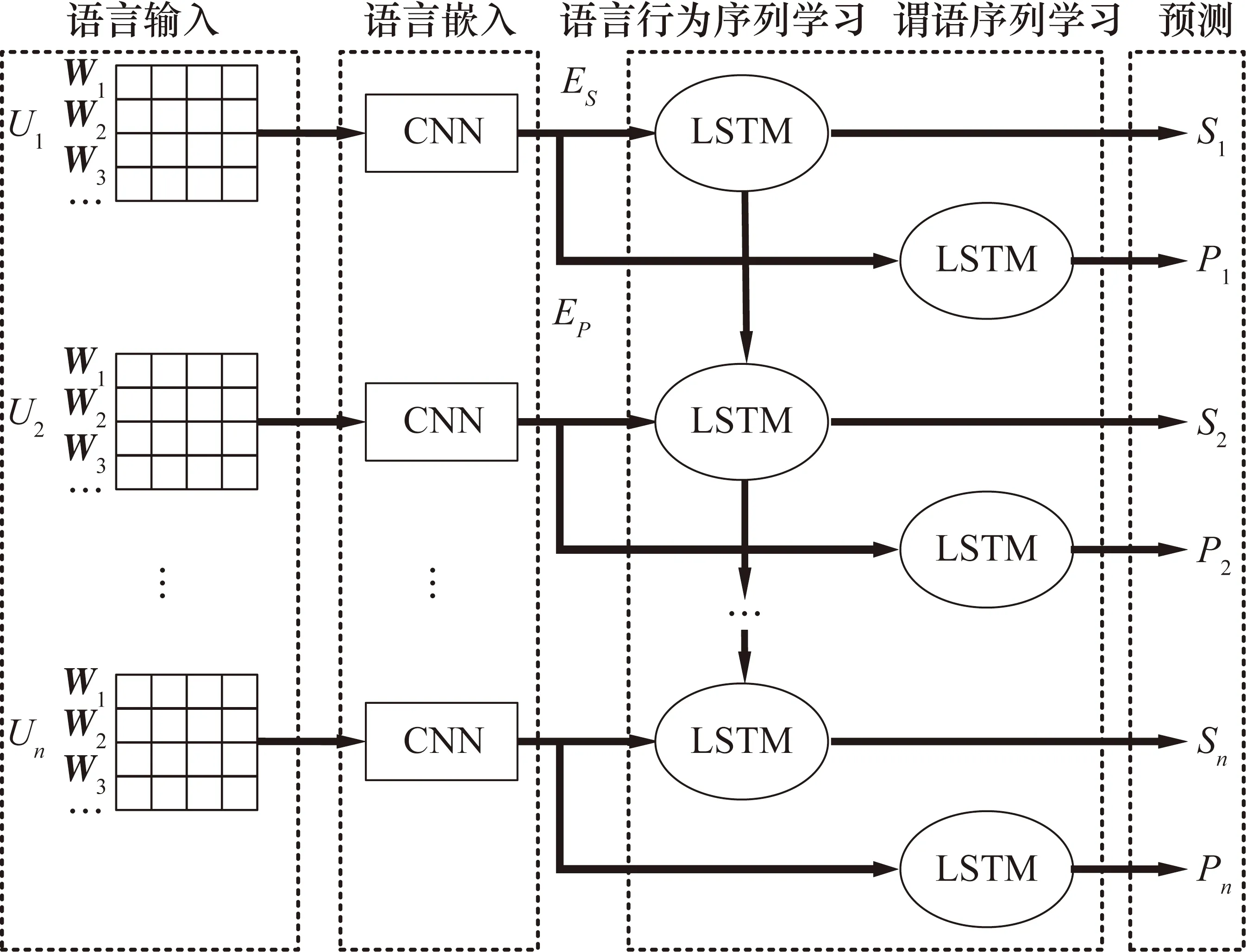
圖3 使用LSTM進行序列標記
3 實驗與仿真
為了進行實驗,測試人員收集了例如行程安排、日常活動、娛樂交際等方面的中文日常對話并加入初始語料庫中[14]。通過刪除初始語料庫中日常對話的感嘆詞和錯誤表達來獲得對話語料庫。在對話中,一位參與者作為一個“用戶”,隨便地詢問另一位參與者關于其每天的日程安排的問題,另一位參與者擔任回答問題的“系統”,使用初始語料庫提前提供的信息進行回答。共有4名測試人員扮演“系統”的角色。
獲得的對話語料庫由956組對話和21336句話語組成(每個對話22.3句話語)。用語義(11種)和預測(47種)在對話中手動注釋每句話語。為了使用所提出的模型進行實驗,將注釋的語料庫分成訓練語料庫和測試語料庫,比例為9∶1,然后進行10倍交叉驗證。
采用4種評估方法:準確率(Accuracy)、宏觀精確率(Macro Precision)、宏觀召回率(Macro Recall)和宏觀F1度量(Macro F1-Measure)來評估所提出模型的性能。準確率是返回正確值的比例;宏觀精確率是每個類別返回的正確值的平均比例;宏觀召回率是每個類別正確返回值的平均比例;宏觀F1度量將宏觀精度和宏觀召回率與以下形式的等量加權相結合:F1=(2.0×宏觀精確率×宏觀召回率)/(宏觀精確率+宏觀召回率)。
本文使用TensorFlow 1.4.0來實現模型訓練,訓練和預測都是以句子為最小單位完成的。將圖3中每個Word2Vec嵌入向量的大小設置為50,訓練長度為300個周期。通過小批量隨機梯度下降法來尋找最佳模型,每個小批量包含15個句子,學習率固定為0.001。
測試用的實驗電路由以下模塊組成:輸入前置放大器、增益調節為0~40 dB的校準電路、步進為5 dB的線性輸出衰減器,以及范圍為0~100 dB的SPL、50 Wclass-T數字功率放大器、PIC18F2550微控制器、一個2行×20個字符的顯示器和一個鍵盤。
測試環境中包含兩個位于45°處(測試人員的左側和右側)的麥克風和一個位于測試人員180°用于產生競爭噪聲的揚聲器,在兩側的麥克風處各放置一個錄音設備,將測試人員發出的自然語言錄下,用以分析。具體如圖4所示。
圖4 測試環境
識別測試包含3種情況:
① 無噪聲環境下的語句列表;
② 信噪比為0 dB噪聲環境下的語句列表;
③ 信噪比為5 dB噪聲環境下的語句列表。
將1號麥克風收集到的語音信號經過處理后輸入給本文提出的語言分類模型,將2號麥克風收集到的語音信號經過處理后輸入給先前文獻的模型。對無噪聲(對照)的測試結果與噪聲在0 dB和5 dB比率下的準確率、宏觀精確率、宏觀召回率和宏觀F1度量進行分析和比較。
4 結果分析
實驗中的講話部分在安靜的環境中用麥克風記錄,內容是“我下午去跑步”。通過16 ms采樣的PCM編碼將語音定量為數字信號,數據長度為12000 bit。得到了輸入信噪比(0 dB和5 dB)與高斯白噪聲成比例混合的噪聲語音,然后利用128 bit交替的256 bit長(16 ms)漢明窗函數得到256 bit長的語音幀。在實驗中分別采用普通譜減法與基于快速噪聲估計的譜減法得到的降噪語音,比較模擬結果如圖5和圖6所示。
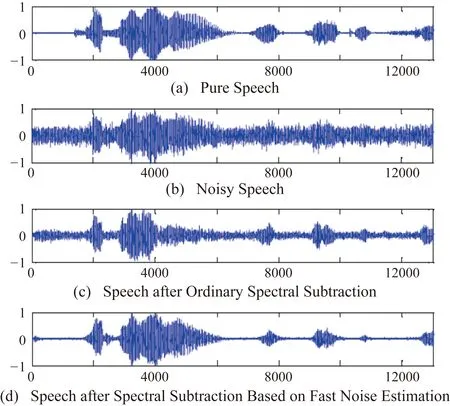
圖5 輸入信噪比為0 dB的信號時的模擬結果
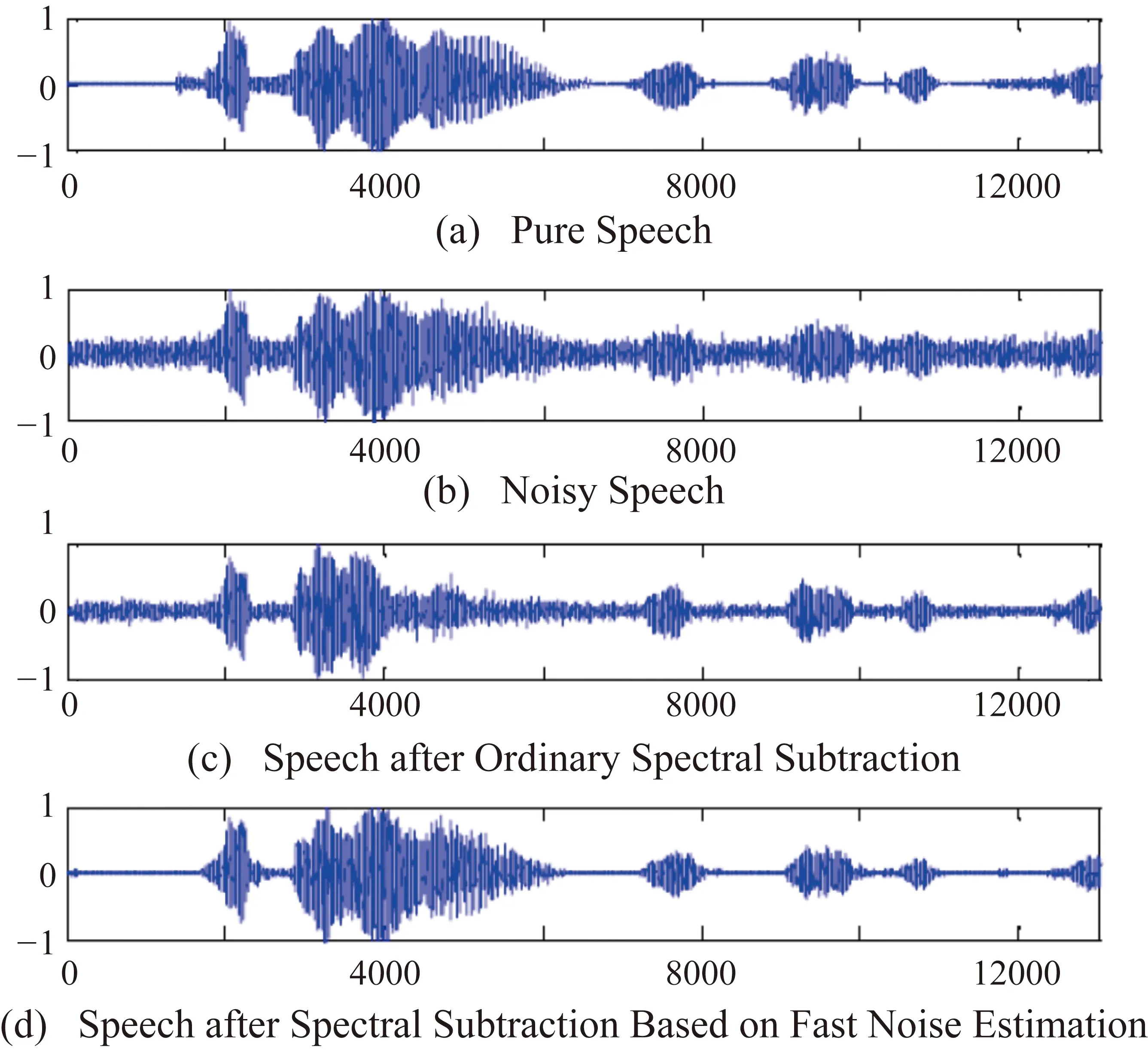
圖6 輸入信噪比為5 dB的信號時的模擬結果
與普通譜減法相比,基于快速噪聲估計的譜減法顯著提高了語音質量。它可以在背景噪音抑制中獲得好的結果。它具有易于實施和計算量少的優點。該算法能夠很好地估計非平穩環境下的噪聲功率譜。
通過使用相同的訓練和測試語料庫比較不同信噪比的噪聲環境對本模型性能的影響,結果如圖7和圖8所示。
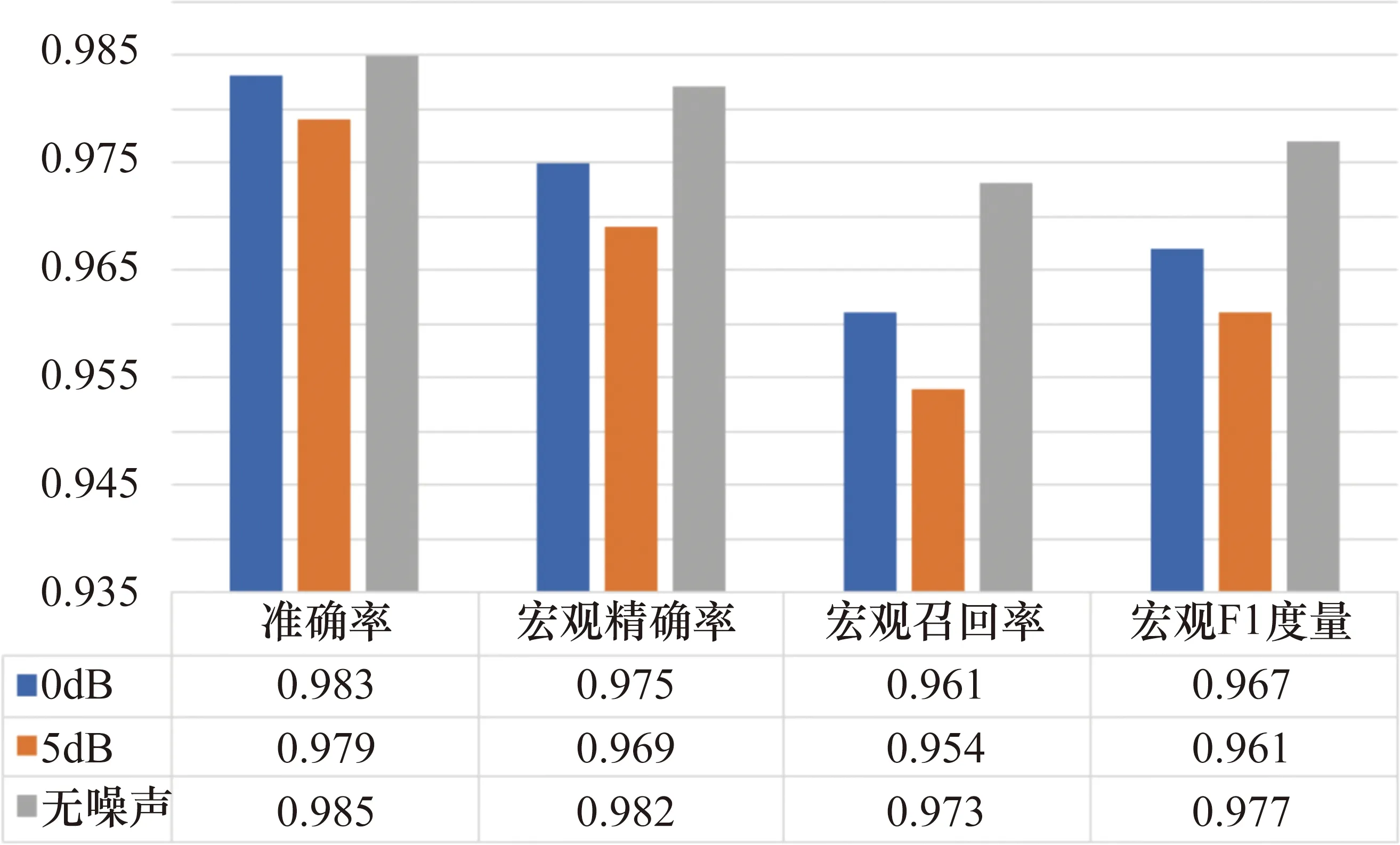
圖7 模型在不同噪聲環境下語義分類的表現
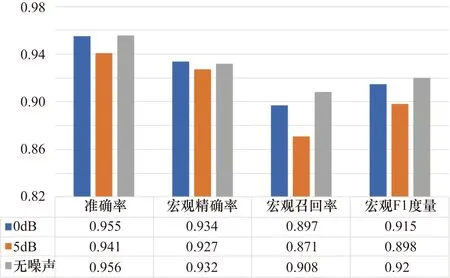
圖8 模型在不同噪聲環境下謂語分類的表現
在圖7所示的語義分類中,噪聲對宏觀召回率的影響比較大,無噪聲與5 dB信噪比環境之間產生了0.019的概率差,但在準確率方面噪聲對模型產生的影響較小。圖8所示的謂語分類結果則表現出模型具有較強的抗噪聲能力,0 dB信噪比環境對模型產生的影響很微小,而在5 dB信噪比環境下也有較好的表現。
在0 dB信噪比環境下使用相同的訓練和測試語料庫將本文提出的模型與先前的模型進行比較。圖9和圖10顯示了本文提出的模型和以前的模型之間的性能差異。
在圖9中,文獻[3]提出的模型是一個基于SVM的模型,其中最佳特征用于言語行為分類。在圖9和圖10中,文獻[2]提出的模型是一個基于SVM的分類模型,其中通過使用相互再訓練方法增加了語義識別和謂語識別的性能。文獻[4]提出的模型是一個基于神經網絡的綜合模型,其中謂語識別的結果被用作語義識別的輸入。如圖9和圖10所示,所提出的模型表現出比以前的模型更好的性能,并且沒有進行任何特征工程。此外,本文提出的模型雖然沒有采用任何二次訓練方法來緩解語義與謂語之間的獨立性假設,但其表現優于文獻[2]提出的模型。這一結果顯示出所提出的CNN體系結構(即與公共節點的部分連接)為緩解獨立性假設提供了一些幫助。
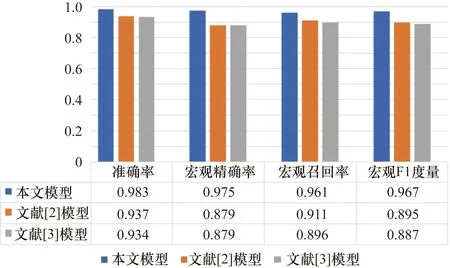
圖9 0 dB噪聲環境下語義分類的表現比較
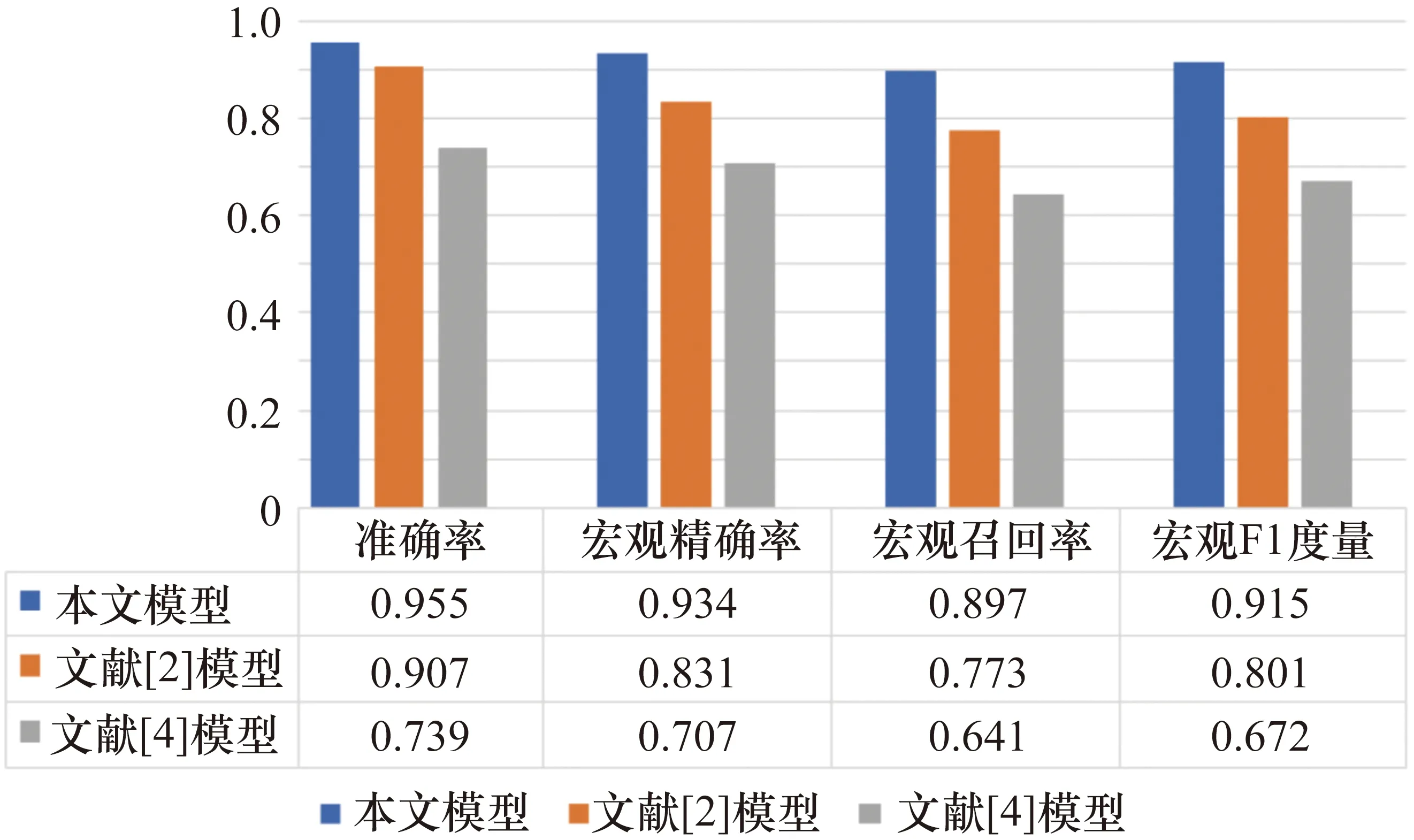
圖10 0 dB噪聲環境下謂語分類的表現比較
5 結束語
本文為對話行為分類提出了一種深度神經網絡模型。所提出的模型使用基于快速噪聲估計的譜減法來進行語音增強;使用基于CNN的新的語言嵌入方法,以緩解語義和謂語之間的獨立性假設;使用基于LSTM的序列標注方法來標注話語序列。在中文日常對話語料庫的實驗中,本文提出的模型在沒有進行任何特征工程和二次訓練的情況下,表現出了優于先前文獻所提出模型的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
