基于生成對抗模仿學習的人機輔助決策系統
2021-03-31 08:56:46楊高光
微型電腦應用 2021年3期
楊高光
(上海交通大學 電子信息與電氣工程學院, 上海 200240)
0 引言
在核電主控室的人機界面操作環境中,人為因素失誤已成為引發工業事故的主要因素[1]。許多經驗表明,提升工業自動化水平是提升生產力、降低人員失誤的有效手段。同時,人機界面輔助決策系統可以降低對專家的依賴水平,緩解人才需求難題。
在輔助決策系統上,傳統方法主要關注兩方面研究:一方面通過調整系統展示宏觀架構;另一方面利用計算機技術將現有的操作規程或者電廠組成架構數字化和可視化。如為指揮中心提供緊急事故情況下的氣象、應急響應動作模擬信息、電廠狀態判斷信息[2];通過建立故障樹為操作員提供可視化系統故障傳播途徑[3]。無論是調整信息展示架構,還是數字化和可視化操作規程,都沒有降低對于界面操作專家的依賴。本文主要關注于通過計算機技術學習專家操作策略,從而降低對于人機界面操作專家的依賴度。相比傳統輔助決策系統,利用計算機學習專家操作策略,一方面可以提高工業自動化水平,降低工業生產對于人力資源的需求,提升生產效率。同時,計算機輔助決策系統在經過實際驗證后可作為智慧決策系統,符合時代發展趨勢;另外,實際生產中對于人類專家的培養往往消耗巨大成本,計算機輔助決策系統可降低對專家的依賴水平。本文通過基于Mujoco的仿真環境進行實驗,驗證了生成對抗模仿學習可以利用少量數據學得專家操作策略。文中首先介紹了將人機界面操作看作馬爾可夫決策過程的理論基礎,然后依次從數據采集、策略表示和對操作策略的學習優化方面介紹了系統模型從理論到學習的過程。最后,在Mujoco仿真環境驗證了基于生成對抗模仿學習[4]來學習人機界面輔助決策系統的有效性。
1 系統構建
人機界面輔助決策系統主要包括5個部分,如圖1所示。
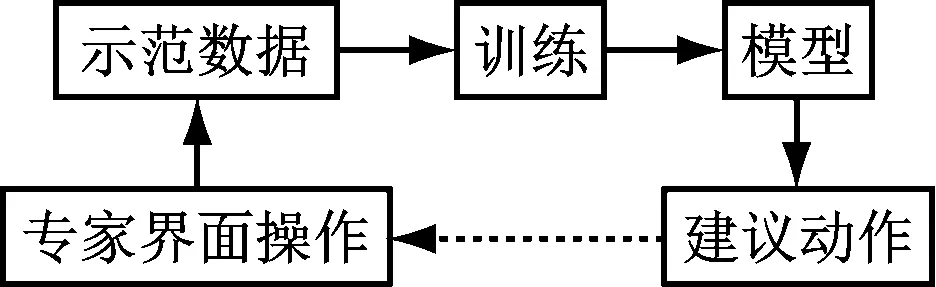
圖1 人機界面輔助決策系統框圖
將專家在界面上的操作作為示范數據,訓練神經網絡模型,學習專家在界面上的操作策略,利用學得的模型來為界面上的操作給出建議:提高人員操作的可靠性;降低人為因素失誤發生概率。
1.1 問題理論描述
專家在界面上的操作過程可以看作是一個馬爾可夫決策過程,其中界面上顯示的數據用狀態s表示,所有狀態構成一個狀態空間s∈S。專家在看到狀態s采取的動作用a表示,所有動作組成一個動作空間A,則a∈A假設初始時刻為0,對應的狀態和動作記為s0,a0。專家在時刻t看到狀態st并且采取動作at后由系統模型P(st+1|st,at)得到下一個狀態st+1。假設專家的操作策略表示為πE,即at=πE(st)。假設專家完成一項任務需要的時間長度為T,那么專家每次進行操作所遇到的狀態動作序列可以表示為τ={(s0,a0),(s1,a1},…,(sT,aT)}。其中,τ稱為專家的操作軌跡或者示范軌跡。雖然這是一次完整的狀態動作操作序列,但是這并不能表示這是專家的操作策略。因此,我們用多個專家的示范軌跡來表示專家的示范數據:τdemo={τ0,τ1,…,τm-1},其中m表示示范樣本數據集大小。
1.2 訓練數據采集
由于專家可以從界面的各種符號標記與大腦中記憶的相應符號的含義,以及現場工藝流程的模塊連接方式相對應,因此人類專家可以通過界面上窗口相應位置的符號、文字標識、對應的狀態數字或者圖形來獲取當前現場狀態。但是計算機只能識別數字信息,不能夠識別界面上的標識,也不了解現場工藝流程。由于計算機和人類專家的這種認知差異,我們在利用計算機進行模仿學習時即不再是這種狀態讀取方式。受DeepMind星際爭霸啟發,我們將所有界面展開成一個界面,即將服務器端傳入界面的所有狀態數據作為當前狀態,所有界面的控制指令作為當前的動作集,如圖2所示。
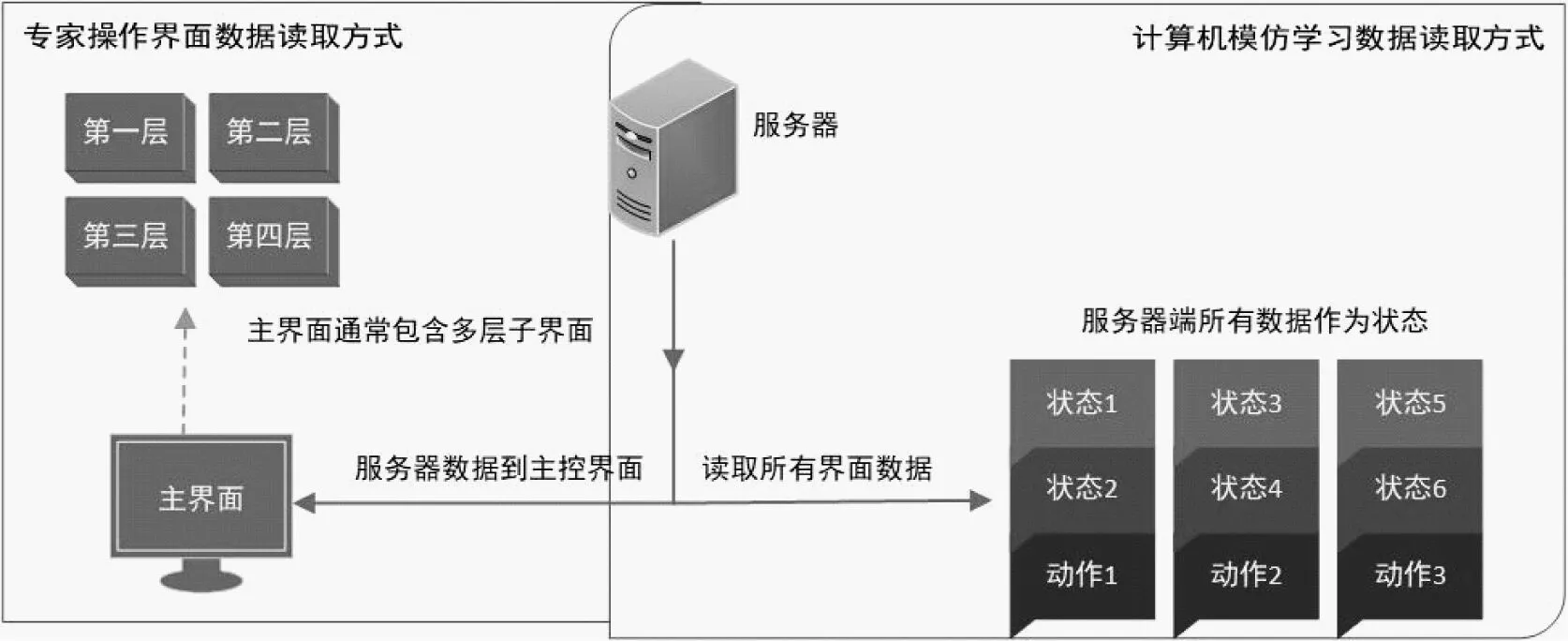
圖2 專家界面數據讀取和模仿學習數據讀取
常規界面顯示由于幅面限制,只能將數據分類在多層界面多個子界面顯示,而計算機模仿學習由于不需要在界面顯示狀態數據,可以每次讀取全部狀態數據。
1.3 模型結構與優化
a.行為克隆
行為克隆(Behavioral Cloning,BC)算法是一種利用專家示范數據學習從環境狀態到專家動作映射關系的一種模仿學習方法。雖然BC算法較為簡單,但是卻對示范數據需求較大。BC算法是一種有監督學習方法,利用線性規劃或者神經網絡等方法學習從環境狀態到專家示范動作之間的關聯。其常用的網絡結構部分,如圖3所示。
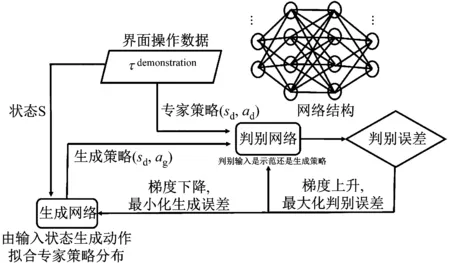
圖3 GAIL模型結構
以環境狀態s為輸入,將示范動作a看作是環境狀態的函數,如式(1)。
(1)
式中,wij表示權重系數;si表示環境狀態變量單元。相對于生成對抗模仿學習,這種模仿學習方式需要利用大量的示范數據擬合權重系數。(對BC算法的介紹,并且簡要說明BC和GAIL算法的區別。關于兩種算法的區別在實驗分析部分會結合實驗數據進一步說明)
b.生成對抗模仿學習
訓練模型,如圖3所示。生成對抗網絡(GAIL)的網絡結構主要包含兩部分:生成網絡πθ和判別網絡Dψ,兩者均采用全連接網絡。其中,生成網絡為目標學習專家策略網絡,用來生成學習策略:ag=πθ(sd);Dψ判別當前策略為專家策略πE還是生成策略πθ。梯度上升用來增強對πθ和πE的分辨能力;梯度下降用來降低πθ和πE的誤差。πθ的因果熵為H(π),其中,πθ生成學習策略ag=πθ(sd)來對分辨網絡進行欺騙,提升分辨網絡分辨能力的同時也提升生成網絡生成欺騙策略的能力。利用這個不斷博弈的過程使得生成網絡逐漸生成和專家策略一致的策略。當ag=ad時,πθ=πE。
專家的示范數據必然只是操作策略空間中的部分狀態動作,往往不能夠包含全部特征。這時,學習過程中必然會面臨當前狀態不屬于示范狀態空間的情況。文獻[6]表明,當前狀態不屬于狀態分布策略空間時,采取均勻概率分布策略,即對所有動作采取相同動作概率,可以收獲最大信息熵。因此,以判別網絡的信息熵更新πθ和πE,最大最小化判別網絡和生成網絡,可以使得學得的πθ對τdemonstration中沒有的示范數據按照均勻概率分布處理如下。
πθ=πθ-π[ψlog(Dψ(s,a))]+πE[ψlog(1-Dψ(s,a))]
πE=πE+π[ψlog(Dψ(s,a))]+πE[ψlog(1-Dψ(s,a))]
以減小和專家界面操作策略的誤差。
2 仿真實驗
Hopper控制界面,如圖4所示。
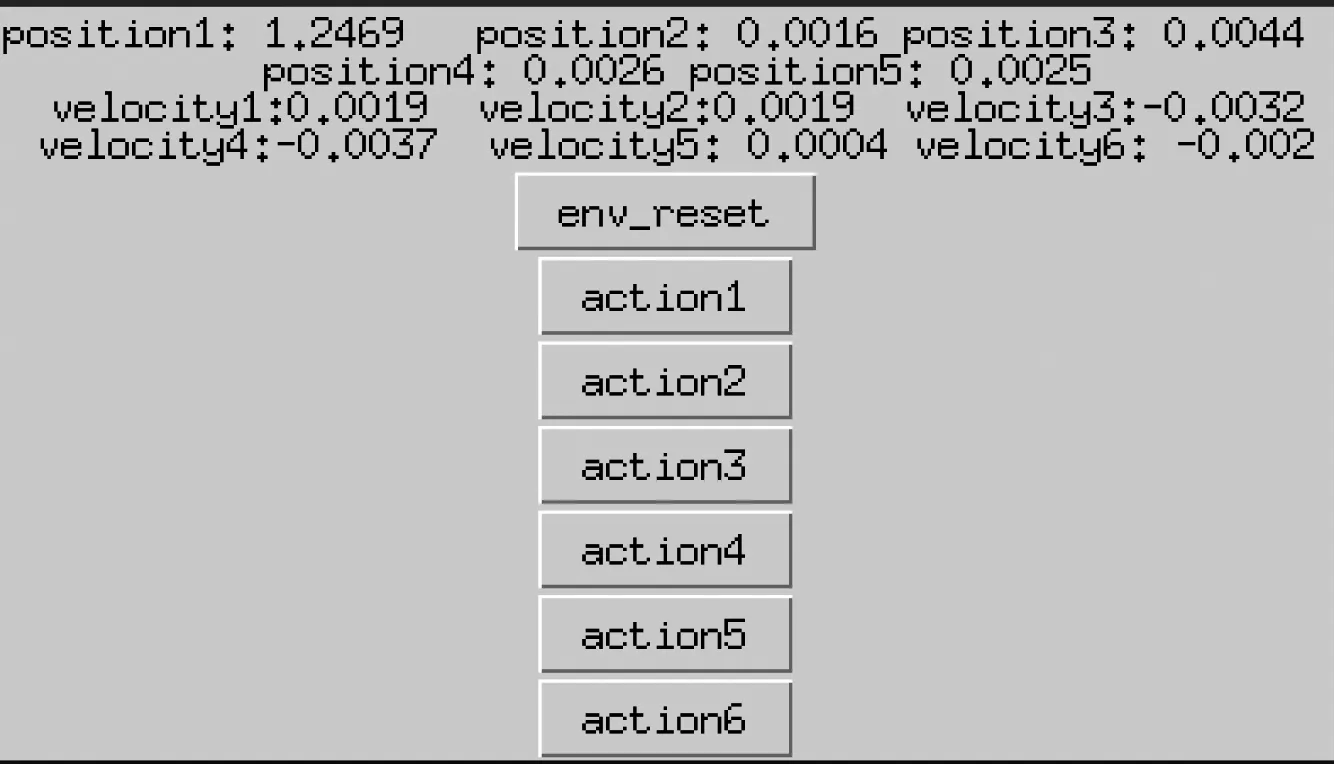
圖4 Hopper控制界面
本實驗基于Mujoco平臺構建的仿真模型作為界面控制對象,對比驗證了GAIL和BC兩種算法在低維(跳躍機器人,Hopper。狀態空間11維,動作空間3維)和高維(類人機器人,Humanoid。狀態空間376維,動作空間17維)控制環境下進行模仿學習的表現。(實驗數據包含兩部分,低維環境實驗和高維環境實驗)基于信賴區間最優化方法(Trust Region Policy Optimization,TRPO)[5]算法在Openaigym平臺下學得的模型作為專家,從而為模仿學習提供示范數據。專家以在有限步驟內獲得累計最大化獎勵為目標,通過界面控制機器人運動。每次示范取最大步驟限制為1 000步,使得專家在界面上進行1到50次示范。(實驗數據樣本)將不同數量的專家示范數據用于GAIL和BC算法的模仿學習訓練,并且以專家每次示范的平均獎勵來對學得的模型進行評價。(模型的評估標準)其中,GAIL和BC算法的網絡模型均采用100個單元的雙層全連接網絡,以tanh作為激活函數。兩種算法分別在兩種操作任務和不同訓練樣本下學習的模型表現,如圖5所示。
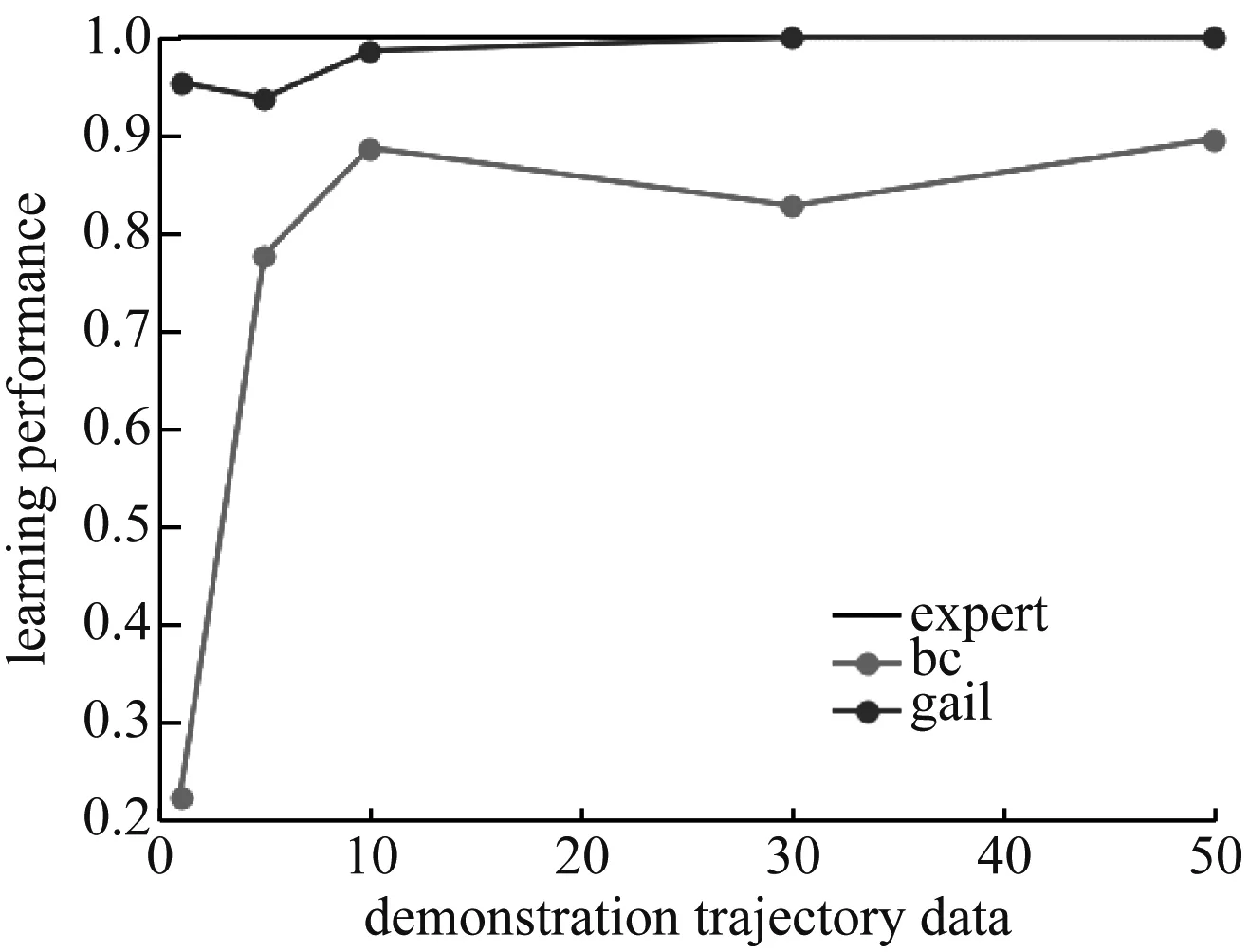
圖5 不同算法對應不同訓練樣本下學得模型的精度曲線(不同訓練樣本的結果)
從圖5可以看出,當使用單次操作示范數據來訓練時,BC算法在簡單和復雜操作任務中所學得模型與專家模型的相似度表現均不到30%;而GAIL算法在復雜任務中使用單次示范數據時學得的模型與專家模型的相似度表現雖然只有91%,但是在簡單操作任務中學得模型與專家模型的相似度可達96%。當有10次專家示范數據時,BC和Gail算法的模型都趨于穩定。從利用10到50次示范數據訓練效果看,BC算法在復雜任務中模仿學習的表現明顯不如簡單操作任務。而GAIL算法無論是在簡單操作任務還是在復雜操作任務中,都能夠達到99%的專家操作效果。由此可見,相比直接利用專家誤差進行學習,將判別網絡和生成網絡結合,通過不斷自我對抗的學習方法不僅能夠學得更加接近專家操作策略的模型,還能夠應對復雜環境。(不同訓練數據樣本的結果對比分析,GAIL和BC算法的區別)
3 總結
筆者提出了用生成對抗模仿學習的方法來構建人機界面輔助決策系統的方法。生成對抗模仿學習可以通過最大熵優化,以及生成網絡和分辨網絡的博弈降低對示范數據的依賴,從而可以僅利用少量專家示范數據來學得專家操作策略的分布函數。仿真結果表明:該方法具有數據利用率高、數據需求量小、學習精度高和學習模型穩定等特點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
當代陜西(2020年13期)2020-08-24 08:22:02
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
制造技術與機床(2017年5期)2018-01-19 02:49:17
濰坊學院學報(2016年2期)2016-12-01 13:00:11
光學精密工程(2016年6期)2016-11-07 09:07:19
