基于EMD特征提取與隨機森林的煤矸識別方法
2021-03-30 02:50:58竇希杰王世博劉后廣陳錢有鄒文才盧召棟
工礦自動化 2021年3期
竇希杰, 王世博, 劉后廣, 陳錢有, 鄒文才, 盧召棟
(1.中國礦業大學 機電工程學院, 江蘇 徐州 221116;2.中國礦業大學 礦山智能采掘裝備協同創新中心, 江蘇 徐州 221116)
0 引言
放頂煤過程的智能化是制約智能化綜放開采的主要技術瓶頸[1-2]。在放頂煤過程中,根據煤層賦存條件變化進行煤矸精準識別,并根據識別結果實時自動調整放煤口啟閉,是實現自動化放煤的關鍵[3],不僅能夠降低混矸率,提高煤炭質量,還能使放煤工人遠離綜放工作面,減少惡劣環境對工人健康的影響。
對放頂煤過程中產生的振動信號進行辨識是實現煤矸識別的有效手段之一。近年來,學者們針對該方法進行了大量研究。文獻[4]分析了煤和矸石沖擊產生的振動信號頻譜特征,得出了2種振動信號頻率不同的結論,但未根據頻譜特征進一步研究煤矸識別技術。文獻[5]分析了放頂煤過程中液壓支架后尾梁及刮板輸送機處采集的振動信號,認為液壓支架后尾梁更適合作為煤矸沖擊振動信號測點,進一步分析了不同工況下振動信號的時域特征,得出了方差、偏度與峭度指標對工況變化敏感的結論,但放頂煤過程的復雜性使得尾梁振動信號具有非平穩特性,時域特征不能準確地表征振動信號。文獻[6]采用小波分析方法對煤和矸石沖擊產生的振動信號進行特征提取,設計了神經網絡模型實現煤矸識別,但建模時使用的訓練樣本和測試樣本較少,模型有效性有待進一步驗證。
本文提出了一種基于經驗模態分解(Empirical Mode Decomposition,EMD)特征提取和隨機森林(Random Forest,RF)的煤矸識別方法。該方法對綜放現場采集的大量煤和矸石沖擊液壓支架尾梁產生的振動樣本信號進行EMD,在分解產生的本征模態函數(Intrinsic Mode Function,IMF)上進行特征提取與篩選,形成最優化的特征數據集訓練RF模型,提高了煤矸識別的準確性;與BP神經網絡、支持向量機等機器學習算法相比,采用的RF算法可直接對特征數據集進行分類,無需進一步處理,保證了煤矸識別效率。
1 基于EMD的特征提取
1.1 EMD基本原理
EMD是N. E. Huang等[7-8]在對瞬時頻率概念研究基礎上提出的一種自適應分解的信號處理方法,在機械故障診斷[9]、模態參數識別[10]等工程領域得到了廣泛應用。EMD可將信號中不同時間尺度的波動逐級分解出來,產生一系列IMF。各個IMF需滿足2個條件[11]:① 數據序列中極值點和過零點最多相差1個。② 任一時刻由信號的局部極大值與局部極小值定義的包絡平均值為0。原始信號S經EMD后可表示為
(1)
式中:n為分解得到的IMF個數;cj為第j個IMF;r為殘差信號,代表信號的平均趨勢。
1.2 特征提取
為了獲取表征原始信號的特征向量,對各樣本信號進行EMD,根據分解結果選取有效IMF,進一步提取IMF能量、峭度、矩陣奇異值及對應的熵作為特征向量,并對各特征向量的提取效率及有效性進行比較,完成特征篩選,建立特征數據集。
IMF能量為
(2)
式中:N為樣本包含的數據點數;m為有效IMF個數;cj(i)為第j個有效IMF的第i個數據點。
IMF峭度為
(3)
式中:E(·)為期望函數;μj為第j個有效IMF的均值;σj為第j個有效IMF的標準差。
根據奇異值分解定義[12],可對各有效IMF組成的m×N矩陣C進行奇異值分解:
C=UQVH
(4)
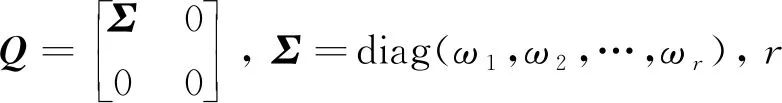
(5)
依據式(5),可求得IMF能量熵、奇異值熵及峭度熵。
2 RF原理
RF的實質是一個包含多棵決策樹的組合分類器,在一定程度上克服了單分類器的局限性[16-17],通過集成提高了分類器的穩定性。RF采用Bootstrap方法進行重采樣[18],產生多個訓練集;利用每個訓練集生成對應的決策樹,在構建決策樹時采用隨機分裂屬性集方法。使用訓練好的RF模型可直接對特征數據集進行分類,簡化了計算環節,減少了特征提取耗時。
2.1 Bootstrap重采樣
設集合T中有k個樣本,若每次有放回地從該集合中抽取1個樣本,抽取k次形成的新集合T*中不包含第t(t=1,2,…,k)個樣本的概率為
(6)
當k趨于無窮時,有
(7)
由式(7)可知,雖然T*與T中樣本數均為k,但T*中可能包含了重復樣本,且T*中約包含T中63.2%的樣本。
2.2 RF算法流程
RF算法流程如圖1所示。

圖1 RF算法流程
采用Bootstrap方法對特征數據集進行重采樣,產生s個訓練集。之后利用訓練集生成對應的決策樹,在每個非葉子節點選擇分裂屬性之前,從特征數據集中隨機抽取q個特征作為當前節點的分裂屬性。使每棵樹完整生長,不進行剪枝操作,最終所有決策樹構成一個RF。當有測試集樣本輸入時,RF中每棵決策樹都會輸出一個結果,采用投票方法將s棵決策樹中輸出最多的類別作為測試集樣本的類別輸出。
3 煤矸識別流程
基于EMD特征提取和RF的煤矸識別流程如圖2所示。首先,對放頂煤過程中采集的振動信號進行等長度截取預處理,得到一系列放煤和放矸石振動樣本信號;其次,對各樣本信號進行EMD,根據分解結果選取有效IMF,提取IMF能量、矩陣奇異值、峭度及對應的熵作為特征向量;再次,使用各特征向量獨立訓練RF模型,并將測試集樣本數據輸入訓練好的RF模型測試特征向量的有效性,根據識別結果完成特征向量篩選,建立特征數據集;最后,使用特征數據集訓練RF模型,通過訓練好的RF模型實現煤矸識別。

圖2 煤矸識別流程
4 煤矸識別試驗
4.1 數據采集
煤矸識別試驗使用的放煤和放矸石振動信號來源于同煤大唐塔山煤礦有限公司8222綜放工作面。工作面全長230.5 m,平均煤層厚度為14.36 m。夾矸6~17層,夾矸單層厚度為0.05~0.82 m。各可采煤層的物理性質相似,呈碎塊狀、塊狀、條帶狀結構,弱玻璃光澤,水平層理,煤層堅固性系數為2.7~3.7。夾矸多為灰褐色高嶺巖、灰白色高嶺質泥巖、灰黑色炭質泥巖,堅固性系數為4.0~4.5。
采用1A946E型IEPE壓電式加速度傳感器及DH5925N型便攜式數據采集儀對放頂煤過程中頂煤和矸石沖擊ZF17000/27.5/42D型液壓支架尾梁產生的振動信號進行采集與記錄。儀器設置位置如圖3所示。采用螺紋安裝方式將加速度傳感器安裝在液壓支架尾梁背面,并通過信號線將加速度傳感器與數據采集儀連接,如圖4所示。數據采集儀布置在液壓支架兩立柱之間,如圖5所示。
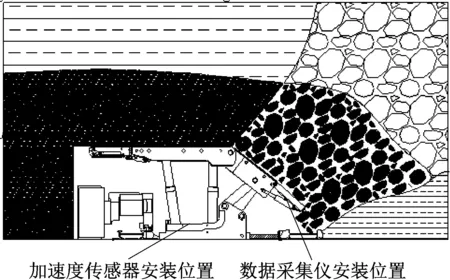
圖3 振動采集儀器布置

圖4 加速度傳感器安裝現場

圖5 數據采集儀安裝現場
試驗開始時,將數據采集儀的采樣頻率設置為25.6 kHz,采集并存儲放頂煤過程中煤和矸石沖擊液壓支架產生的振動信號,并根據放煤工人的提示記錄放煤和放矸石2種工況的開始及結束時刻。放煤和放矸石振動信號時域波形如圖6所示。
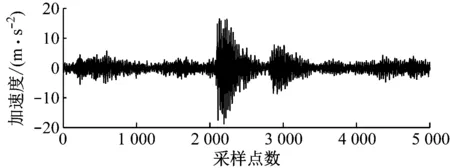
(a) 放煤振動信號
4.2 振動信號特征提取及特征數據集構建
對放頂煤過程中采集的放煤和放矸石2種工況下的振動信號進行EMD,結果如圖7所示。可看出2種振動信號經EMD后各得到10個IMF及1個殘差分量,且對應的IMF幅值和波形具有明確區別。另外放煤和放矸石振動信號的能量均集中在前8個IMF中,因此將前8個IMF作為有效IMF,提取IMF能量、峭度、矩陣奇異值及對應的熵作為特征向量。
對采集的原始振動信號進行預處理,以5 000點作為1個樣本長度,共得到放煤和放矸石振動信號各1 100個樣本數據。從原始樣本中隨機抽取放煤和放矸石振動信號各1 000個樣本作為訓練集、100個樣本作為測試集,將放煤狀態標簽設置為1、放矸石狀態標簽設置為0,進行RF模型訓練及測試。

(a) 放煤振動信號
為驗證所提取特征的有效性,使用各特征向量分別訓練RF模型。設置RF所含決策樹數量s=500,分裂屬性集中屬性個數q=M/2(M為特征總數)。為保證識別結果的可靠性,每次均使用隨機產生的訓練集及測試集進行建模及識別,并將10次識別的準確率平均值作為最終結果。采用不同特征向量進行RF建模及識別的結果見表1。
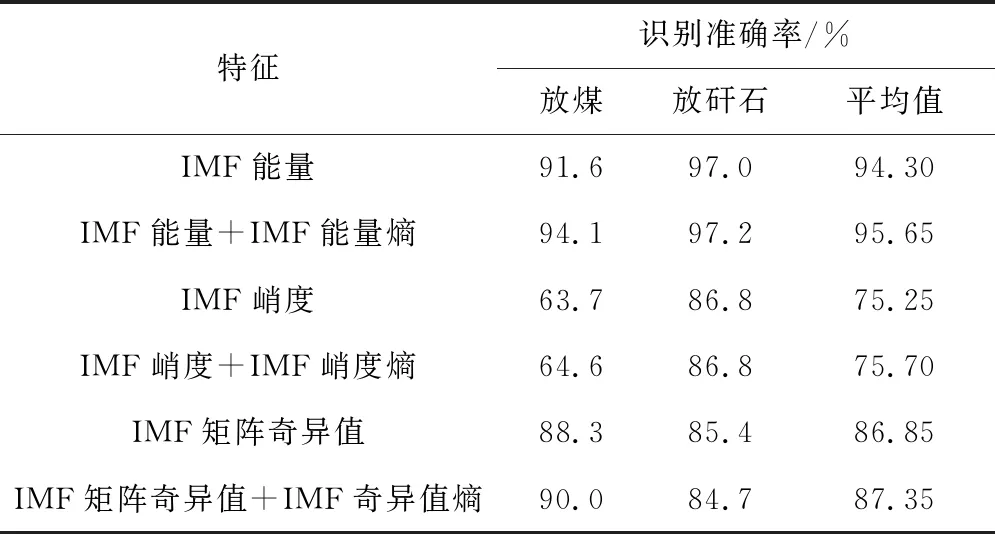
表1 采用不同特征向量的煤矸識別結果
由表1可知,使用IMF能量訓練得到的RF模型對測試集樣本的識別準確率最高,達94.30%;采用IMF峭度訓練得到的RF模型識別準確率最低,僅為75.25%;各特征向量加入對應的熵特征再進行訓練得到的RF模型識別準確率均小幅提升。將IMF峭度特征剔除,使用IMF能量(8維)、IMF能量熵(1維)、IMF矩陣奇異值(8維)、IMF奇異值熵(1維)共18維數據建立特征數據集,由特征數據集訓練得到的RF模型對放煤和放矸石各100組振動樣本的識別準確率達96.5%。
4.3 RF模型性能評估
RF模型決策樹數量對其泛化性能有一定影響。為獲得RF模型的最優決策樹數量,對包含不同數量決策樹的RF模型進行評估。具體方法:設置步長為50,使決策樹數量在50~1 000范圍內變動;對于每個確定的決策樹數量,均使用4.2節中得到的特征數據集建立100個RF模型,取其識別結果的平均值作為當前RF模型的識別準確率。決策樹數量不同的RF模型識別準確率如圖8所示。可看出當決策樹數量設置為100或150時,RF模型識別效果最優,此時對測試集樣本的識別準確率達97%。
考慮到綜放工作面煤矸識別的實時性需求,對特征數據集中各特征向量的提取耗時及RF模型對測試集樣本的識別耗時進行統計。具體方法:從測試集樣本中隨機抽取10組數據,統計10組數據特征提取的平均耗時;將10組數據特征向量輸入RF模型,計算其平均識別耗時。統計結果見表2。
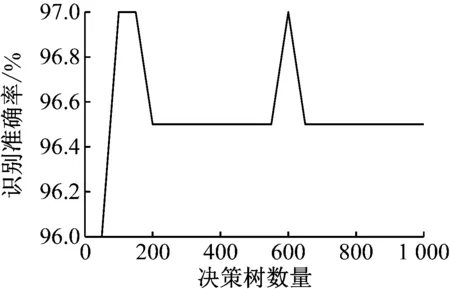
圖8 決策樹數量對RF模型識別性能的影響
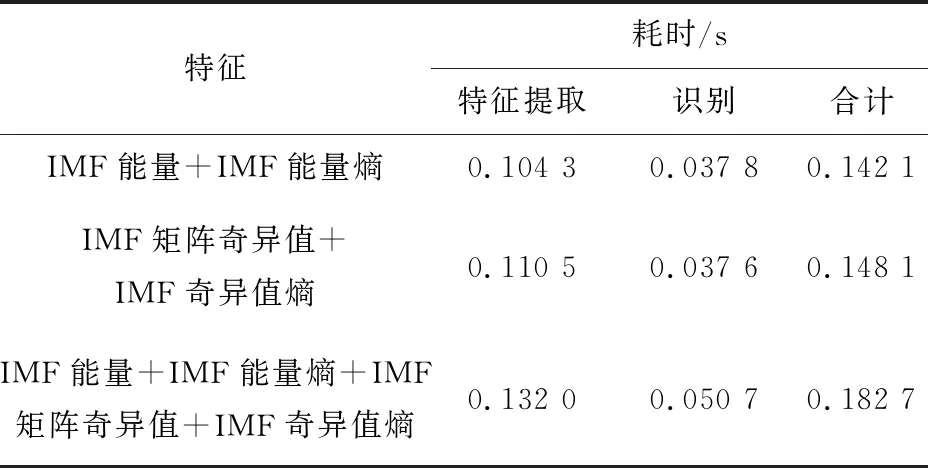
表2 特征提取及識別耗時統計
由表2可知,使用IMF能量及其熵組成的特征向量訓練RF模型時,模型對測試集樣本進行特征提取與識別的耗時為0.142 1s,使用IMF矩陣奇異值及其熵組成的特征向量訓練時耗時為0.148 1s,使用組合特征向量訓練時耗時為0.182 7 s。
5 結論
(1) 在綜放現場采集了大量的煤、矸石沖擊液壓支架尾梁產生的振動信號,對振動信號進行EMD,采用IMF能量、峭度、矩陣奇異值及對應的熵對振動信號進行定量描述,并采用不同的特征向量訓練RF模型,根據RF模型對未知樣本的識別能力篩選特征,由此建立特征數據集。根據特征數據集建立RF模型,對200組測試集樣本進行識別,準確率達96.5%。
(2) 從泛化能力和識別效率2個方面研究了RF模型的性能,結果表明當決策樹數量設置為100或150時,RF模型的識別準確率最高,達97%,同時對測試集樣本進行特征提取與識別的耗時不超過0.2 s。研究結果驗證了本文方法可快速、準確地實現煤矸識別。
猜你喜歡
科學大眾(2023年17期)2023-10-26 07:39:14
天天愛科學(2020年6期)2020-09-10 07:22:44
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學物理學報(2017年6期)2018-01-22 02:26:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
計算物理(2014年2期)2014-03-11 17:01:44
