基于網(wǎng)絡(luò)日志的用戶行為檢測(cè)和畫像構(gòu)建系統(tǒng)
2021-03-24 11:26:41倪建偉李偉龍董文潔莊彥誠
計(jì)算機(jī)時(shí)代 2021年2期
倪建偉 李偉龍 董文潔 莊彥誠


摘? 要: 用戶畫像可以幫助企業(yè)更多地了解用戶,從而更好地制定決策。目前,大多數(shù)用戶畫像構(gòu)建模型均依賴于應(yīng)用廠商提的內(nèi)部數(shù)據(jù),而數(shù)據(jù)源的局限性可能難以保證用戶畫像的精準(zhǔn)性。文章利用網(wǎng)絡(luò)設(shè)備中的多源訪問日志,基于知識(shí)數(shù)據(jù)庫構(gòu)建和指紋匹配技術(shù),設(shè)計(jì)了一種新的用戶畫像構(gòu)建架構(gòu),并借助Pyspider和Hadoop分布式框架提高數(shù)據(jù)采集和畫像生成的計(jì)算效率。大量實(shí)驗(yàn)表明,該方法可以比現(xiàn)有模型構(gòu)建出更全面、更準(zhǔn)確的用戶畫像。
關(guān)鍵詞: 用戶畫像; 網(wǎng)絡(luò)日志; 知識(shí)數(shù)據(jù)庫; 指紋匹配; 分布式框架
中圖分類號(hào):TP391.1;TP392? ? ? ? ? 文獻(xiàn)標(biāo)識(shí)碼:A? ? ?文章編號(hào):1006-8228(2021)02-42-04
Abstract: User portrait can help enterprises know more about users and do better decision-making. At present, most user portrait building models rely on the internal data provided by application vendors, and the limitations of data sources may be difficult to ensure the accuracy of user portrait. In this paper, by using the multi-source access logs recorded in the network node equipments, new user portrait architecture based on knowledge database construction and fingerprint matching is designed, meanwhile the computing efficiency of data acquisition and portrait generation is improved with the help of Pyspider and Hadoop distributed framework. A large number of experiments show that this method can build more comprehensive and accurate user portraits than that of the off-the-shelf models.
Key words: user portrait; access log; knowledge database; fingerprint matching; distributed framework
0 引言
隨著信息技術(shù)的不斷發(fā)展,大量的傳統(tǒng)行業(yè)正逐漸向著信息化轉(zhuǎn)型。在此環(huán)境下,越來越多的企業(yè)開始重視通過數(shù)據(jù)對(duì)用戶建立特征認(rèn)知,進(jìn)而更好得為各類業(yè)務(wù)決策進(jìn)行輔助。互聯(lián)網(wǎng)的普及使得PC和移動(dòng)設(shè)備的日常使用頻率大幅上升,在此過程中,各類軟件應(yīng)用記錄了海量的用戶操作日志,包括頁面點(diǎn)擊、瀏覽、添加、關(guān)注等原始用戶交互行為數(shù)據(jù)。此類操作行為日志可以為,給每個(gè)用戶打上標(biāo)簽從而實(shí)現(xiàn)精準(zhǔn)推薦、客戶分類、興趣挖掘等任務(wù)提供有效數(shù)據(jù)支持。
當(dāng)下,用戶畫像是使用范圍最廣的用戶偏好刻畫的概念,其概念最早由交互設(shè)計(jì)之父Alan Cooper提出,通過對(duì)現(xiàn)實(shí)生活中用戶的各類數(shù)據(jù)的建模,最終以標(biāo)簽的形式對(duì)用戶進(jìn)行畫像刻畫。目前,用戶畫像已在互聯(lián)網(wǎng)金融、電商營銷等領(lǐng)域均取得了較好成效[1]。同時(shí),當(dāng)前用戶畫像的構(gòu)建的數(shù)據(jù)源多是采用企業(yè)內(nèi)部數(shù)據(jù),因此所得畫像存在一定的局限性。
除了各類應(yīng)用廠商所掌握的內(nèi)部數(shù)據(jù)外,網(wǎng)絡(luò)設(shè)備中記錄的訪問日志來源更廣泛,信息量更加豐富。運(yùn)營商、各類公用wifi、公共交換機(jī)等所捕捉的訪問日志中存在著諸多信息,此類數(shù)據(jù)通常為一系列的http請(qǐng)求記錄,通過分析這些訪問請(qǐng)求,可以獲取其子網(wǎng)內(nèi)部(例如一個(gè)商場(chǎng)、一個(gè)機(jī)構(gòu))所有用戶的畫像。但同時(shí),這些數(shù)據(jù)又十分繁雜和抽象,難以直接從中獲取有價(jià)值的信息。郭俊霞等提出了一種針對(duì)用戶網(wǎng)頁瀏覽日志數(shù)據(jù)的查詢和行為分析方法[2],但是沒有挖掘出用戶查詢?cè)L問網(wǎng)頁的主題。基于上述問題,本文面向公共網(wǎng)關(guān)數(shù)據(jù),提出了完整構(gòu)建用戶畫像的解決方案。
1 整體架構(gòu)
用戶畫像是對(duì)現(xiàn)實(shí)世界中用戶的數(shù)學(xué)建模,把用戶的一些行為進(jìn)行量化,用數(shù)學(xué)的手段來進(jìn)行統(tǒng)計(jì)[3]。用戶畫像的本質(zhì)是深入分析客戶,掌握具有實(shí)用價(jià)值的數(shù)據(jù),找到目標(biāo)客戶,根據(jù)客戶需求制定產(chǎn)品,并利用數(shù)據(jù)實(shí)現(xiàn)價(jià)值變現(xiàn)[4]。用戶畫像的構(gòu)建過程主要包括對(duì)用戶的基本信息、行為等數(shù)據(jù)的采集、過濾、挖掘分析,以標(biāo)簽的形式對(duì)用戶進(jìn)行畫像刻畫,最終依據(jù)不同分類標(biāo)準(zhǔn)形成用戶特定類型,進(jìn)而根據(jù)不同需求來設(shè)計(jì)用戶畫像平臺(tái)的使用功能和應(yīng)用流程。
在各類應(yīng)用的使用過程中,產(chǎn)生的GET、POST等請(qǐng)求均在網(wǎng)關(guān)服務(wù)器節(jié)點(diǎn)的日志中有留存[5]。這些記錄涉及到各類用戶操作行為,其中蘊(yùn)含了大量的用戶行為、興趣偏好等內(nèi)容。與此同時(shí),這些數(shù)據(jù)又十分抽象和混亂,通常為一串URL集合,無法快速刻畫出用戶畫像,需要對(duì)其進(jìn)行清洗、篩選、映射、匹配等步驟才能轉(zhuǎn)換成有價(jià)值的信息。
本文基于上述問題提出了一套基于知識(shí)庫指紋匹配用戶畫像構(gòu)建模型(如圖1),主要包括知識(shí)庫管理模塊、指紋匹配模塊、用戶畫像模塊。通過一定操作將每一個(gè)URL與知識(shí)庫指紋映射,得到對(duì)應(yīng)用戶的標(biāo)簽信息,最終實(shí)現(xiàn)基于用戶行為日志的畫像構(gòu)建。
2 知識(shí)庫構(gòu)建
構(gòu)建用戶畫像需要精準(zhǔn)的標(biāo)簽體系、真實(shí)的數(shù)據(jù)來源和可靠的邏輯架構(gòu)。網(wǎng)關(guān)日志中的數(shù)據(jù)均為URL記錄,獲取每個(gè)URL背后隱含的信息需要預(yù)先構(gòu)建對(duì)應(yīng)的知識(shí)庫,即站點(diǎn)知識(shí)庫和每個(gè)站點(diǎn)下的二級(jí)網(wǎng)站知識(shí)庫。站點(diǎn)知識(shí)庫體現(xiàn)URL對(duì)應(yīng)域名的信息,包括站點(diǎn)名稱、站點(diǎn)類別標(biāo)簽等。網(wǎng)站知識(shí)庫體現(xiàn)更具化的信息,包括用戶每次訪問的單品信息和對(duì)應(yīng)的用戶標(biāo)簽。
2.1 站點(diǎn)知識(shí)庫構(gòu)建
每個(gè)域名的基本信息和站點(diǎn)類別標(biāo)簽都存儲(chǔ)在站點(diǎn)知識(shí)庫中,這些信息可以利用數(shù)據(jù)采集技術(shù)從各類網(wǎng)站資源門戶中獲取。通過與站點(diǎn)知識(shí)庫的匹配,可以大致映射出用戶對(duì)每個(gè)領(lǐng)域的興趣程度,為用戶貼上基礎(chǔ)標(biāo)簽。對(duì)于如何構(gòu)建站點(diǎn)信息的標(biāo)簽體系,程元堃等預(yù)先定義了八大主題,構(gòu)建基于Word2vec的詞向量模型,通過詞頻統(tǒng)計(jì)和計(jì)算詞中心向量的方法確定各主題的特征詞及其詞向量, 實(shí)現(xiàn)了網(wǎng)站主題分類[6],劉如娟基于用戶自定義標(biāo)簽并通過聚類提高標(biāo)簽針對(duì)性[7]。
2.2 網(wǎng)站知識(shí)庫構(gòu)建
與站點(diǎn)知識(shí)庫匹配獲得的標(biāo)簽適用性較廣,若要獲取更細(xì)化的網(wǎng)站內(nèi)部信息來刻畫標(biāo)簽,則需要構(gòu)建出包含所有站點(diǎn)的網(wǎng)站知識(shí)庫。基于所構(gòu)建的網(wǎng)站知識(shí)庫,利用指紋匹配技術(shù)對(duì)每一次日志行為進(jìn)行知識(shí)庫映射并匹配出對(duì)應(yīng)標(biāo)簽。
網(wǎng)站知識(shí)庫構(gòu)建中,最核心的是數(shù)據(jù)采集模塊,利用網(wǎng)絡(luò)爬蟲技術(shù)將站點(diǎn)知識(shí)庫中每個(gè)域名下不同網(wǎng)站的網(wǎng)頁信息爬取下來。在對(duì)網(wǎng)站正文進(jìn)行數(shù)據(jù)處理后,結(jié)合網(wǎng)站分類標(biāo)準(zhǔn)進(jìn)行文本分析,得到該網(wǎng)站的標(biāo)簽,導(dǎo)入并更新網(wǎng)站知識(shí)庫。如果中間有任何一個(gè)步驟失敗則提交人工進(jìn)行查看。
在信息每天都以爆炸式速度增長的今天,網(wǎng)站信息數(shù)據(jù)源過于龐大和分散,同時(shí)信息也以極高的頻率持續(xù)更新,采取傳統(tǒng)單節(jié)點(diǎn)線性爬蟲框架來抓取網(wǎng)站信息會(huì)消耗大量時(shí)間和資源,導(dǎo)致效率低下。因此本文采用了基于Pyspider的分布式網(wǎng)絡(luò)爬蟲架構(gòu),進(jìn)而大大提高了并發(fā)抓取的性能。同時(shí)使用了非關(guān)系型MongoDB數(shù)據(jù)庫和Redis消息隊(duì)列搭建了一套分布式爬蟲環(huán)境,構(gòu)建多源數(shù)據(jù)采集框架,提高數(shù)據(jù)采集的效率和穩(wěn)定性。
在爬蟲實(shí)際操作過程中,寫入存儲(chǔ)介質(zhì)前需要預(yù)先判斷寫入內(nèi)容是否已存在于介質(zhì)中,剔除重復(fù)的URL。因此,本文采用Redis消息隊(duì)列來實(shí)現(xiàn)數(shù)據(jù)的增量爬取,對(duì)爬取到的網(wǎng)站進(jìn)行唯一標(biāo)識(shí),并將唯一標(biāo)識(shí)存儲(chǔ)至Redis的set中。在每一次數(shù)據(jù)爬取前,首先對(duì)將要發(fā)起請(qǐng)求的URL是否存在于set中做出判斷,如果存在則不進(jìn)行請(qǐng)求。此外,爬取到網(wǎng)站數(shù)據(jù)后且持久化存儲(chǔ)前,先判斷該數(shù)據(jù)的唯一標(biāo)識(shí)是否存在于Redis的set中,再?zèng)Q定是否進(jìn)行持久化存儲(chǔ)。
將MongoDB中存儲(chǔ)的網(wǎng)站信息數(shù)據(jù)經(jīng)過字段驗(yàn)證、字段映射、字段清洗,存入較為規(guī)整的關(guān)系型數(shù)據(jù)庫MySQL中,并為同一域名下的不同二級(jí)路由建立各自專屬的網(wǎng)站知識(shí)庫表,存放網(wǎng)站信息和標(biāo)簽信息,以便對(duì)記錄的于指紋匹配。
3 指紋匹配
指紋庫起著將用戶、站點(diǎn)知識(shí)庫、網(wǎng)站知識(shí)庫連接起來的作用。針對(duì)操作日志中每一條用戶瀏覽歷史記錄,從中提取URL依次與站點(diǎn)庫、指紋庫、網(wǎng)站知識(shí)庫進(jìn)行匹配,提取出標(biāo)簽信息為后續(xù)的用戶標(biāo)簽構(gòu)建提供必要的信息。
3.1 指紋庫構(gòu)建
指紋庫表中每一條記錄都需要有域名信息,從而與站點(diǎn)知識(shí)庫相映射。同時(shí)也需要有不同Patten所對(duì)應(yīng)的網(wǎng)站知識(shí)庫信息。指紋庫樣例如表1。
3.2 指紋匹配過程
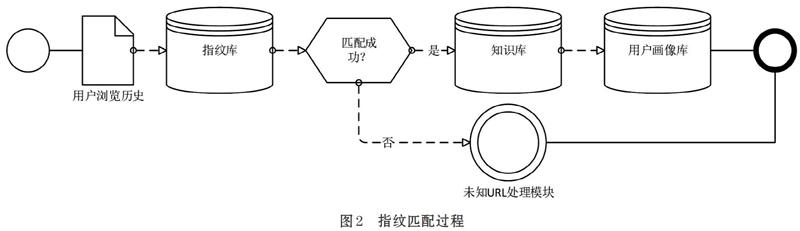
整個(gè)匹配過程包括了知識(shí)庫匹配、指紋庫匹配。針對(duì)每一條用戶瀏覽歷史記錄,從中提取URL信息與知識(shí)庫、指紋庫中的數(shù)據(jù)進(jìn)行逐級(jí)匹配。如果匹配成功將網(wǎng)站標(biāo)簽提取并用于下一步用戶畫像構(gòu)建,若失敗則轉(zhuǎn)入未知URL處理模塊,將網(wǎng)站URL置入爬蟲隊(duì)列,如圖2。
譬如url為http://www.*****.com/tour/210018300的一條記錄:
第一步:首先切出域名www.*****.com,然后與站點(diǎn)知識(shí)庫進(jìn)行匹配,得相應(yīng)記錄,該站點(diǎn)屬于交通旅游,旅游網(wǎng)站類別。
第二步:將該url的路由部分/tour/210018300與指紋庫中host=www.*****.com的記錄進(jìn)行正則匹配,匹配到對(duì)應(yīng)的patten, /tour/(\d+),其對(duì)應(yīng)的知識(shí)庫為traval_A2_wjx。
第三步:在相應(yīng)的知識(shí)庫中查詢符合id=210018300的記錄,再提取網(wǎng)站的標(biāo)簽信息。
第四步:如果無法在網(wǎng)站知識(shí)庫和指紋庫中匹配到的URL,則發(fā)送給相應(yīng)的模塊,再次進(jìn)行網(wǎng)站信息的爬取,并更新網(wǎng)站知識(shí)庫和指紋庫。
4 用戶畫像構(gòu)建
4.1 分布式計(jì)算框架
借助上述知識(shí)庫構(gòu)建和指紋匹配可以實(shí)現(xiàn)單條URL的網(wǎng)站匹配和正文信息提取和標(biāo)簽提取,但是在實(shí)際生產(chǎn)過程中,操作日記的記錄量往往是上百萬條,采用單URL匹配過程會(huì)使得時(shí)間復(fù)雜度過于巨大,因此本文提出一套基于Hadoop框架的分布式用戶畫像構(gòu)建方法。基于Hadoop分布式并行計(jì)算框架能支持高吞吐量的數(shù)據(jù)訪問,與本文所涉及的海量數(shù)據(jù)應(yīng)用場(chǎng)景所契合,有助于在指紋匹配過程中采用分布式框架提取URL并進(jìn)行匹配,提高整體處理效率。
4.2 用戶畫像可視化
標(biāo)簽體系應(yīng)當(dāng)具有原始數(shù)據(jù)層、事實(shí)層、模型層和預(yù)測(cè)層的層級(jí)結(jié)構(gòu)[8]。在指紋匹配完成時(shí),從站點(diǎn)知識(shí)庫和網(wǎng)站知識(shí)庫中得到的標(biāo)簽構(gòu)成了用戶動(dòng)態(tài)行為屬性信息,將之與用戶靜態(tài)屬性信息結(jié)合,可以構(gòu)建一個(gè)相對(duì)立體、精準(zhǔn)的用戶畫像數(shù)據(jù)標(biāo)簽體系。再借助一定算法構(gòu)建該用戶畫像,對(duì)比原有畫像庫,如果有差異則進(jìn)行更新。在系統(tǒng)的最終實(shí)現(xiàn)過程中,當(dāng)用戶來訪時(shí),通過ID匹配用戶畫像庫,借助Echarts將用戶的上網(wǎng)頻次、支付行為、活躍時(shí)間和一周興趣變化等行為數(shù)據(jù)用圖形化語言表現(xiàn)出來。最終呈現(xiàn)的畫像頁面如圖3所示。
5 結(jié)束語
本文針對(duì)繁雜的公共網(wǎng)關(guān)數(shù)據(jù),提出了一種基于知識(shí)庫構(gòu)建和指紋匹配技術(shù)的新型用戶畫像構(gòu)建機(jī)制,同時(shí)采取分布式存儲(chǔ)和計(jì)算框架提高了計(jì)算效率。整個(gè)系統(tǒng)高效充分提煉了用戶操作日志信息中的網(wǎng)站信息和時(shí)間信息,更加便捷和準(zhǔn)確得構(gòu)建用戶畫像。系統(tǒng)對(duì)于龐大的用戶畫像庫和網(wǎng)站知識(shí)庫,在利用方式上還不是很成熟和完善,可以在最終的呈現(xiàn)方式和利用方式上再加以改進(jìn)。
參考文獻(xiàn)(References):
[1] 周光華,辛英,張雅潔等.醫(yī)療衛(wèi)生領(lǐng)域大數(shù)據(jù)應(yīng)用探討[J].中國衛(wèi)生信息管理雜志,2013.10(4):296-300,304
[2] 郭俊霞,高城,許南山等.基于網(wǎng)頁瀏覽日志的用戶行為分析[J].計(jì)算機(jī)科學(xué),2014.41(3):110-115
[3] MobasherB, Dai H, Luo T, et al. Integrating web usage and content mining for more effective personalization[C]//Proceedings of the international conference on e-commerce and web technologies,2000:165-176
[4] 王曉霞,劉靜沙,許丹丹.運(yùn)營商大數(shù)據(jù)用戶畫像實(shí)踐[J].電信科學(xué),2018.34(5):127-133
[5] 黃雅萍,馬可辛,周余洪,劉曉強(qiáng).面向中小企業(yè)的電商平臺(tái)挖掘系統(tǒng)設(shè)計(jì)[J].計(jì)算機(jī)時(shí)代,2015.4:18-20
[6] 程元堃,蔣言,程光.基于word2vec的網(wǎng)站主題分類研究[J].計(jì)算機(jī)與數(shù)字工程,2019.47(1):169-173
[7] 劉如娟.基于標(biāo)簽聚類與用戶模型的個(gè)性化推薦方法研究[J].現(xiàn)代情報(bào),2016.36(6):74-78,99
[8] Ng T W H, Lam S S K, Feldman D C. Organizational citizenship behavior and counterproductive work behavior:Do males and females differ?[J].Journal of Vocational Behavior,2016.93(4):11-32
