基于神經(jīng)網(wǎng)絡(luò)的高校科研項(xiàng)目前景預(yù)測系統(tǒng)研究與設(shè)計(jì)
2021-03-24 09:56:14王漢元姜英
軟件工程 2021年3期
王漢元 姜英

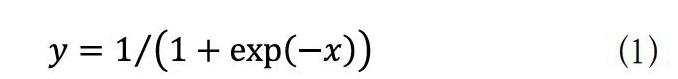

摘? 要:為了對(duì)高校科研項(xiàng)目前景進(jìn)行有效預(yù)測,進(jìn)一步提升科研成果轉(zhuǎn)化率,本文提出了基于神經(jīng)網(wǎng)絡(luò)結(jié)合科研項(xiàng)目共享的網(wǎng)絡(luò)平臺(tái),構(gòu)建可靠的科研項(xiàng)目前景預(yù)測系統(tǒng)。通過將各類大量科研項(xiàng)目的特征參數(shù)化,利用BP(反向傳播)神經(jīng)網(wǎng)絡(luò)的非線性映射能力、自適應(yīng)能力和對(duì)離散數(shù)據(jù)的泛化能力生成模型后,用于從多維度對(duì)一個(gè)新項(xiàng)目生成可靠的前景預(yù)測。實(shí)驗(yàn)表明,BP神經(jīng)網(wǎng)絡(luò)算法在大量學(xué)習(xí)經(jīng)過預(yù)處理的樣本后所產(chǎn)生的預(yù)測結(jié)果是具有較高準(zhǔn)確性的,且能夠隨著新的樣本輸入不斷更新和適應(yīng),因此該方法具有較強(qiáng)的可行性。
關(guān)鍵詞:高校科研項(xiàng)目;前景預(yù)測;神經(jīng)網(wǎng)絡(luò)
中圖分類號(hào):TP183? ? ?文獻(xiàn)標(biāo)識(shí)碼:A
Abstract: This paper proposes to build a reliable prospect forecast system for scientific research projects in order to effectively predict prospects of scientific research projects in universities and further improve conversion rate of scientific research results. The system is based on neural networks and a network platform shared by scientific research projects. A model is generated by parameterizing characteristics of a large number of various scientific research projects, using the non-linear mapping ability, adaptive ability and generalization ability of BP (Back Propagation) neural network. Then, the model is used for reliable forecast of a new project from multiple dimensions. Experiments show that the prediction results, produced by the BP neural network algorithm after learning a large number of pre-processed samples, have high accuracy, and can be updated and adapted with new sample input. Therefore, this method is highly feasible.
Keywords: university scientific research projects; prospect prediction; neural network
1? ?引言(Introduction)
在我國,科研成果轉(zhuǎn)化率低已是老生常談的話題,2018年4月18日國務(wù)院常務(wù)會(huì)議確定了“加大對(duì)科技成果轉(zhuǎn)化的政策激勵(lì)”的政策方針并提出了若干辦法。但由于科研評(píng)價(jià)機(jī)制不合理、選題立項(xiàng)重復(fù)度高、科研資金管理存在漏洞[1]等問題,導(dǎo)致科研成果轉(zhuǎn)化率低的現(xiàn)象至今依然存在。提高科研成果轉(zhuǎn)化率,企業(yè)的參與是至關(guān)重要的,然而企業(yè)為了規(guī)避風(fēng)險(xiǎn)很注重項(xiàng)目的成熟度,偏向于投資前景已清晰的項(xiàng)目。這樣便導(dǎo)致很多優(yōu)秀的項(xiàng)目由于找不到投資者止步在“原始創(chuàng)新成果”階段,失去了產(chǎn)業(yè)化、商品化的機(jī)會(huì)。而各個(gè)高校的科研項(xiàng)目展示頁面更注重展示本校科研項(xiàng)目的創(chuàng)新性和技術(shù)高度,而忽略了展示方案的實(shí)現(xiàn)成本及產(chǎn)業(yè)化的難度[2],這讓企業(yè)難以理解其價(jià)值。
本文中所研究的采用SSM+MongoDB技術(shù)搭建的基于BP神經(jīng)網(wǎng)絡(luò)(反向傳播神經(jīng)網(wǎng)絡(luò))算法的高校科研項(xiàng)目前景預(yù)測系統(tǒng),可實(shí)現(xiàn)對(duì)科研項(xiàng)目進(jìn)行可靠的前景預(yù)測,幫助正在進(jìn)行中的科研項(xiàng)目更直觀地展示自身價(jià)值,降低企業(yè)投資風(fēng)險(xiǎn),提高科研成果的轉(zhuǎn)化率[3]。
2? ?技術(shù)簡介(Technical brief)
基于BP神經(jīng)網(wǎng)絡(luò)算法的高校科研項(xiàng)目前景預(yù)測系統(tǒng)的技術(shù)選型使用SSM框架,數(shù)據(jù)庫采用MySQL+MongoDB的形式,核心功能的實(shí)現(xiàn)使用了BP神經(jīng)網(wǎng)絡(luò)算法。
2.1? ?BP神經(jīng)網(wǎng)絡(luò)
BP神經(jīng)網(wǎng)絡(luò)是19世紀(jì)80年代由David Runelhart等科學(xué)家提出的概念,是一種對(duì)感知機(jī)網(wǎng)絡(luò)的改進(jìn)算法,解決了簡單感知器不能解決的異或(Exclusive OR, XOR)和非線性學(xué)習(xí)等問題。BP神經(jīng)網(wǎng)絡(luò)在訓(xùn)練過程中通過反復(fù)調(diào)整系統(tǒng)中各種參數(shù)的值形成自己的學(xué)習(xí)能力,并將這種能力應(yīng)用于更多樣本的分類,因此被廣泛應(yīng)用于分類和識(shí)別領(lǐng)域。從收集到的資料可以得知:神經(jīng)網(wǎng)絡(luò)算法是一種對(duì)績效評(píng)價(jià)比較理想的方法,而且很多開發(fā)者在不同領(lǐng)域中應(yīng)用這種方法,如企業(yè)績效評(píng)價(jià)、動(dòng)態(tài)供應(yīng)鏈績效評(píng)價(jià)、高校院系績效評(píng)價(jià)等。其學(xué)習(xí)流程可簡單概括為:
(1)輸入經(jīng)過預(yù)處理的樣本數(shù)據(jù)。
(2)乘以權(quán)重,增加偏置并激活,逐層傳遞。
(3)得到預(yù)測值并對(duì)比真實(shí)值得到損失值。
(4)利用損失值對(duì)偏置和權(quán)重求偏導(dǎo)。
(5)利用梯度下降的方法更新參數(shù)。
(6)循環(huán)以上流程直到損失值達(dá)到標(biāo)準(zhǔn)。
(7)訓(xùn)練完成。
BP神經(jīng)網(wǎng)絡(luò)的優(yōu)勢(shì)在于:(1)非線性映射能力:BP神經(jīng)網(wǎng)絡(luò)實(shí)質(zhì)上實(shí)現(xiàn)了一個(gè)從輸入到輸出的映射功能,數(shù)學(xué)理論證明三層的神經(jīng)網(wǎng)絡(luò)就能夠以任意精度逼近任何非線性連續(xù)函數(shù)。這使得其特別適于求解內(nèi)部機(jī)制復(fù)雜的問題。(2)容錯(cuò)能力:BP神經(jīng)網(wǎng)絡(luò)在其局部的或者部分的神經(jīng)元受到破壞后,對(duì)全局的訓(xùn)練結(jié)果不會(huì)造成很大的影響,也就是說即使系統(tǒng)在受到局部損傷時(shí)還是可以正常工作的,即BP神經(jīng)網(wǎng)絡(luò)具有一定的容錯(cuò)能力。但是BP神經(jīng)網(wǎng)絡(luò)仍有一些缺陷,比如:容易陷入局部極小值;神經(jīng)網(wǎng)絡(luò)收斂速度緩慢;神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)選擇沒有統(tǒng)一的解決方案,只能憑經(jīng)驗(yàn)判斷;神經(jīng)網(wǎng)絡(luò)預(yù)測能力和訓(xùn)練能力的矛盾,可能導(dǎo)致“過擬合”的情況。這些缺陷有的已經(jīng)有了解決方案,而有些缺陷的解決方案還有待探索。
2.2? ?SSM框架
SSM框架是一種常用且經(jīng)典的以MVC模式搭建網(wǎng)站的框架組合,其中包含三個(gè)框架:Spring、SpringMVC、MyBatis。Spring負(fù)責(zé)管理集成的框架、呈現(xiàn)切面、管理事務(wù)處理和Bean的生命周期;SpringMVC負(fù)責(zé)轉(zhuǎn)發(fā)請(qǐng)求、傳遞頁面中動(dòng)態(tài)數(shù)據(jù)和業(yè)務(wù)處理;MyBatis負(fù)責(zé)和MySQL數(shù)據(jù)庫的交互,將表轉(zhuǎn)換成類,將字段轉(zhuǎn)換成類的屬性以方便程序員對(duì)數(shù)據(jù)庫的CRUD[4]。
2.3? ?MongoDB數(shù)據(jù)庫
MongoDB是一個(gè)非關(guān)系型數(shù)據(jù)庫,在數(shù)據(jù)的存儲(chǔ)結(jié)構(gòu)上卻與關(guān)系型數(shù)據(jù)庫和非關(guān)系型數(shù)據(jù)庫都有相似之處。即使之前對(duì)NoSQL的概念知之甚少的開發(fā)者也能快速上手。其優(yōu)勢(shì)在于清晰、便于理解的表結(jié)構(gòu),松散的存儲(chǔ)方式可以方便地存儲(chǔ)一些關(guān)系復(fù)雜的數(shù)據(jù),而其作為非關(guān)系型數(shù)據(jù)庫也具有大數(shù)據(jù)量處理、高性能讀寫的先天特性[5]。
3 BP神經(jīng)網(wǎng)絡(luò)在核心功能模塊中的應(yīng)用(Application of BP neural network in core function module)
使用BP神經(jīng)網(wǎng)絡(luò)進(jìn)行前景預(yù)測的原因在于,通過研究發(fā)現(xiàn),在特定類別的科研項(xiàng)目中,最終成功轉(zhuǎn)化的科研項(xiàng)目在某些特征上具有共性,而不甚成功的科研項(xiàng)目同樣在某些特征上具有另一些共性[6]。這種數(shù)據(jù)關(guān)系與BP神經(jīng)網(wǎng)絡(luò)的工作模式非常符合,因此選用BP神經(jīng)網(wǎng)絡(luò)來完成前景預(yù)測功能。
由于神經(jīng)網(wǎng)絡(luò)的輸入數(shù)據(jù)需要經(jīng)過預(yù)處理,而計(jì)算機(jī)難以實(shí)現(xiàn)對(duì)科研項(xiàng)目的特征進(jìn)行評(píng)估,因此在設(shè)計(jì)時(shí)增加了評(píng)論功能,通過這個(gè)功能的設(shè)計(jì)幫助富有經(jīng)驗(yàn)的用戶以規(guī)范的格式對(duì)項(xiàng)目進(jìn)行全面且理性的評(píng)價(jià)。在經(jīng)過一段時(shí)間,取得評(píng)論達(dá)到一定數(shù)量后,對(duì)評(píng)論取均值即得到一個(gè)項(xiàng)目信息較為準(zhǔn)確客觀的特征數(shù)據(jù)(取得了樣本的特征值);而在項(xiàng)目結(jié)束后,會(huì)有合作的企業(yè)或者專業(yè)的測評(píng)人員按照評(píng)分標(biāo)準(zhǔn)給項(xiàng)目進(jìn)行最終評(píng)分(取得了樣本的真實(shí)值)。這樣便收集到了訓(xùn)練神經(jīng)網(wǎng)絡(luò)所需樣本的所有數(shù)據(jù),經(jīng)過預(yù)處理后的部分樣本數(shù)據(jù)如表1所示。
訓(xùn)練神經(jīng)網(wǎng)絡(luò)時(shí)輸入數(shù)據(jù)必須格式統(tǒng)一,因此經(jīng)過研究設(shè)定了描述一個(gè)科研項(xiàng)目的五項(xiàng)特征:“選題”“經(jīng)費(fèi)”“人員”“可行性”“市場需求”。從這些角度評(píng)價(jià)可以全面地概括一個(gè)科研項(xiàng)目的各項(xiàng)特征,這五項(xiàng)特征的值對(duì)應(yīng)BP神經(jīng)網(wǎng)絡(luò)輸入層的五個(gè)神經(jīng)元。
由于采用上述特征值收集方式使得特征值相差并不大,因此BP神經(jīng)網(wǎng)絡(luò)的傳播方式采用Log-Sigmoid激活函數(shù),如公式(1)所示:
Math.exp為Java內(nèi)用于返回自然數(shù)底數(shù)e的參數(shù)次方。而為了避免出現(xiàn)由于神經(jīng)網(wǎng)絡(luò)層數(shù)過深,在反向傳播時(shí)出現(xiàn)梯度消失的情況,隱含層(Hidden-layer)采用三層神經(jīng)元。隱含層的神經(jīng)元個(gè)數(shù)由輸入層和輸出層神經(jīng)元個(gè)數(shù)決定,具體公式如公式(2)所示:
Math.sqrt()為Java內(nèi)獲取參數(shù)正平方根的方法,hdNum為隱含層神經(jīng)元個(gè)數(shù),inNum為輸入層神經(jīng)元個(gè)數(shù),outNum為輸出層神經(jīng)元個(gè)數(shù),ADJUST為節(jié)點(diǎn)調(diào)節(jié)常數(shù),這樣的設(shè)計(jì)保證了在特征數(shù)量增加時(shí)程序的可擴(kuò)展性。
在確定了神經(jīng)網(wǎng)絡(luò)的形狀之后是規(guī)定隱含層神經(jīng)元的計(jì)算規(guī)則,如公式(3)所示:
其中,為l層神經(jīng)元的輸出值,為激活函數(shù),為層神經(jīng)元的權(quán)重,為層神經(jīng)元的輸出值,為層的偏置值。在得到最終輸出值后與真實(shí)值比較取得損失值的損失函數(shù),如公式(4)所示:
其中,為預(yù)測值,為真實(shí)值,為樣本個(gè)數(shù)。隨后使用梯度下降的方式更新網(wǎng)絡(luò)中各節(jié)點(diǎn)的權(quán)值與偏置,并再次訓(xùn)練,重復(fù)直至損失值達(dá)到預(yù)設(shè)的標(biāo)準(zhǔn)[7]。
4? ?系統(tǒng)設(shè)計(jì)(System design)
整個(gè)網(wǎng)站平臺(tái)在SSM的框架下搭建,在此介紹用于實(shí)現(xiàn)科研項(xiàng)目前景預(yù)測的主要功能模塊的設(shè)計(jì)。
4.1? ?功能模塊結(jié)構(gòu)
系統(tǒng)所涉及的主要功能模塊包含科研項(xiàng)目信息模塊、評(píng)論模塊和評(píng)分模塊。科研項(xiàng)目模塊主要包含的功能為創(chuàng)建和修改科研項(xiàng)目信息、查看項(xiàng)目詳情和項(xiàng)目前景預(yù)測。評(píng)論模塊和評(píng)分模塊包含的功能為記錄用戶對(duì)科研項(xiàng)目各項(xiàng)特征的描述,這些數(shù)據(jù)將為科研項(xiàng)目信息模塊使用BP神經(jīng)網(wǎng)絡(luò)進(jìn)行前景預(yù)測提供重要的數(shù)據(jù)支撐。
4.2? ?核心模塊的工作流程
首先,高校科研人員用戶會(huì)使用平臺(tái)上傳科研項(xiàng)目信息,科研項(xiàng)目信息模塊會(huì)對(duì)這些信息進(jìn)行整理,之后存入數(shù)據(jù)庫,然后其他用戶在瀏覽科研項(xiàng)目信息后留下評(píng)論,這些評(píng)論由若干標(biāo)簽構(gòu)成。這些標(biāo)簽被預(yù)先設(shè)置好放在編寫評(píng)論界面的下方備選,標(biāo)簽的內(nèi)容為科研項(xiàng)目在若干特征上的表現(xiàn),如描述項(xiàng)目“經(jīng)費(fèi)”特征的標(biāo)簽有“經(jīng)費(fèi)不足”“經(jīng)費(fèi)合適”“過分充裕”;描述項(xiàng)目“選題”特征的標(biāo)簽有“意義重大”“價(jià)值一般”“毫無意義”。此外還有描述其他多個(gè)特征的若干標(biāo)簽。標(biāo)簽界面設(shè)計(jì)如圖1所示。
這些標(biāo)簽被賦予不同的分值以衡量項(xiàng)目在若干特征上的表現(xiàn)。采用這種標(biāo)簽的評(píng)論方式可以借助評(píng)論者的知識(shí)對(duì)項(xiàng)目給出相對(duì)客觀、全面且標(biāo)準(zhǔn)化的描述。項(xiàng)目與企業(yè)進(jìn)行合作后,企業(yè)用戶會(huì)根據(jù)評(píng)分標(biāo)準(zhǔn)給出一個(gè)科研項(xiàng)目的最終評(píng)價(jià)。一個(gè)項(xiàng)目在收集若干評(píng)論數(shù)據(jù)后,這些評(píng)論將取均值作為該項(xiàng)目的特征值,而最終評(píng)價(jià)則作為項(xiàng)目的真實(shí)值。在獲得足夠的樣本后,這些數(shù)據(jù)被用于訓(xùn)練BP神經(jīng)網(wǎng)絡(luò)和測試其準(zhǔn)確度。BP神經(jīng)網(wǎng)絡(luò)訓(xùn)練完成后就可以通過一個(gè)科研項(xiàng)目的評(píng)論數(shù)據(jù)預(yù)測其前景。
4.3? ?系統(tǒng)測試結(jié)果
在測試中使用的訓(xùn)練集包含160條樣本,測試集包含40條樣本,訓(xùn)練完成后的BP神經(jīng)網(wǎng)絡(luò)預(yù)測準(zhǔn)確率最高可達(dá)到95.0%,該次訓(xùn)練結(jié)果如圖2所示。
4.4? ?數(shù)據(jù)存儲(chǔ)
由于MySQL作為關(guān)系型數(shù)據(jù)庫能夠保證數(shù)據(jù)的ACID特性,因此用于存儲(chǔ)用戶的賬戶相關(guān)信息;而MongoDB則用于存儲(chǔ)科研項(xiàng)目的相關(guān)信息,如科研項(xiàng)目的介紹、附件、其他用戶的評(píng)論等需要頻繁進(jìn)行CURD操作的數(shù)據(jù)。
5? ?結(jié)論(Conclusion)
由于系統(tǒng)所需數(shù)據(jù)需要平臺(tái)正式上線并在具有相當(dāng)影響力后才能取得,真實(shí)數(shù)據(jù)難以收集,且本文中對(duì)科研項(xiàng)目前景預(yù)測的設(shè)計(jì)僅為給相關(guān)工作者提供參考思路,因此在測試設(shè)計(jì)有效性時(shí)使用了模擬數(shù)據(jù)。這樣的結(jié)果說明BP神經(jīng)網(wǎng)絡(luò)在理想的條件下并不能百分之百的實(shí)現(xiàn)對(duì)實(shí)驗(yàn)樣本的準(zhǔn)確分類,但是實(shí)驗(yàn)結(jié)果中該算法展現(xiàn)較高的準(zhǔn)確率已然表明,在高校科研信息共享平臺(tái)的開發(fā)中,BP神經(jīng)網(wǎng)絡(luò)應(yīng)用于前景預(yù)測是具有較高可行性的。
參考文獻(xiàn)(References)
[1] 趙紅梅.基于新形勢(shì)下的高新技術(shù)企業(yè)科研經(jīng)費(fèi)管理探究[J].財(cái)經(jīng)界(學(xué)術(shù)版),2018(4):84-86.
[2] 于曉棠.簡述高校科研成果轉(zhuǎn)化存在的問題及對(duì)策[J].科技資訊,2020,18(12):217-218.
[3] 高敏.基于BP神經(jīng)網(wǎng)絡(luò)的績效評(píng)價(jià)應(yīng)用研究[D].蘭州:西北師范大學(xué),2016.
[4] 王燕貞,沈毅波.基于SSM框架的高校學(xué)生綜合測評(píng)系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)[J].通化師范學(xué)院學(xué)報(bào),2020,41(04):58-63.
[5] 黃承明.基于MongoDB文檔模型的教學(xué)資源數(shù)據(jù)的建模研究[J].軟件工程,2020,23(05):46-49.
[6] 李言榮.科研評(píng)價(jià)要減少“人”的因素[N].中國科學(xué)報(bào),2020-06-03(001).
[7] D. J. C. MacKay. A practical Bayesian framework for back-propagation networks[J]. Advances in Neural Information Processing Systems, 1992, 4(3):448-472.
作者簡介:
王漢元(1998-),男,本科生.研究領(lǐng)域:軟件工程,Java.
姜? ?英(1978-),女,碩士,副教授.研究領(lǐng)域:軟件工程.

- 軟件工程的其它文章
- 軟件實(shí)訓(xùn)教學(xué)系統(tǒng)設(shè)計(jì)
- 智慧公路工程中信息資源規(guī)劃
- 體育競賽實(shí)時(shí)數(shù)據(jù)分享系統(tǒng)儲(chǔ)存方案設(shè)計(jì)與優(yōu)化
- 基于主動(dòng)探測的非關(guān)系型數(shù)據(jù)庫風(fēng)險(xiǎn)感知系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
- 基于改進(jìn)多層感知機(jī)模型的港口吞吐量預(yù)測研究
- 基于大數(shù)據(jù)技術(shù)的大學(xué)生學(xué)習(xí)畫像構(gòu)建