基于大數據技術的大學生學習畫像構建
2021-03-24 09:56:14陳會余馨李琳琳吳蘇徽蔣秀蓮
軟件工程 2021年3期
關鍵詞:數據挖掘
陳會 余馨 李琳琳 吳蘇徽 蔣秀蓮
摘? 要:在信息社會,各行各業的管理控制轉變為以數據、信息為中心。在高等教育領域,高校重視學生信息數據庫的建設,通過學生瀏覽信息的關鍵詞、種類分布和瀏覽主題等多個維度構建學生畫像向量空間模型。本文使用大數據技術構建學生學習畫像基礎模型框架,研究學生學習畫像在個性化學習、問題預警及輔助學校決策等方面的應用,為高校提升學生培養質量提供參考。
關鍵詞:學習畫像;用戶標簽;數據挖掘
中圖分類號:TP311.13? ? ?文獻標識碼:A
Abstract: In information society, it is data and information that manage and control all walks of life. In the field of higher education, universities attach importance to the construction of student information databases. The vector space model of student portraits is constructed through multiple dimensions such as keywords, type distribution and browsing topics of students' browsing information. This article uses big data technology to build a basic model framework for student learning portraits, and studies the aspects of student learning portraits in personalized learning, early warning of problems, and assistance in school decision-making, so as to provide references for colleges and universities to improve the quality of student training.
Keywords: learning portrait; user tags; data mining
1? ?引言(Introduction)
我國普通高等學校素質教育明確提出,高校的教學任務在于不斷提升學生的綜合素質。信息社會下的大學生呈現個性化發展的趨勢[1],他們的學習行為、特長偏好等也相對多樣化。學校對學生的教育方式要適應學生的個性化發展需求,以利于提升學生的綜合素質,為經濟社會培養高質量人才。
當前國內在企業精準營銷以及數據產品個性化推薦領域中,對用戶進行畫像構建的較多。高校對學生的數據搜集、處理以及畫像構建等尚不全面,大多數畫像構建通常停留在數據的描述可視化上[2],并未對學生的教育與改善學習效果起到明顯作用。基于大數據技術的學生學習畫像構建針對學生不同個性發展的獨立性及多樣性,重視學生在思維和行為上的差距,突破對學生綜合評價僅考慮學習成績的局限性,能更加全面地對學生進行評價及打分,可以更好地引導學生,挖掘學生潛能,促進學生全面發展。本文探討研究基于大數據技術的學生學習畫像基礎模型框架的構建,以期在學生個性化學習、學生問題預警及輔助學校有關政策、決策的制定等方面提供數據驅動。
2? 大學生學習畫像(University students' learning portrait)
大學生學習畫像是高校大學生在學習方面的虛擬代表,是建立在一系列真實數據之上的目標用戶模型。通過學生學習數據收集分析了解學生,根據他們的目標、行為和屬性的差異,將他們區分為不同的類型,然后從每種類型學生中抽取出基本信息、內容偏好、學習風格和社交互動行為描述,就形成了一個人物原型即一個學生學習畫像。根據數據的記錄和描述性統計分析可得:在已知學生性別、年齡和專業的前提條件下,依據學生檢索信息的內容、頁面瀏覽的次數以及下載量,甚至包括在社交學習平臺上資源轉發頻率和互動評論內容等,可以計算出每位在校大學生的學習狀態,從而構建學生學習畫像,預測學生學習成效,進而幫助教師更好地關注學生的學習狀態和身心健康。此外,根據統計的數據記錄能夠輔助學校政策的制定,使得制定的政策更加人性化和專業化。
3? ?基于大數據技術的學習畫像構建(Construction of learning portrait based on big data technology)
現行的用戶畫像主要運用網絡流算法檢驗學生的學習狀態,重點運用多層次聚類分析算法進行數據挖掘,運用多元回歸分析和神經網絡算法預測學生學習成績及掛科率。鑒于一些高校對學生考評測評方式僅限于結構化數據的成績分析,且存在數據挖掘意識不強等問題[3],本項目對高校學生學習、消費、網絡使用及生活等行為方面的結構和非結構化數據進行預處理和挖掘,構建學生學習畫像,從而為學生個性化學習、學生問題預警、輔助學校決策等提供數據驅動,以加強高校優良學風建設。學生學習畫像構建步驟如下:
第一步:將目標用戶畫像問題轉化為學生學習畫像問題。
學生學習畫像分析本質上是從學生的角度思考問題,涉及若干學生用戶群體、若干學生用戶行為。網絡課程通常有三種學習用戶——存量學習用戶、流失學習用戶、潛在學習用戶,涉及學生基本信息、學習目的、學習方式、學習態度、學習成效、學習評價和體驗等,因此分門別類解釋邏輯尤為重要。
第二步:宏觀假設驗證。
轉化完問題后,需在拆解以前聚焦假設,先在宏觀上對假設進行檢驗,有效避免無限拆解的錯誤。進行大方向檢驗,可以有效縮小懷疑范圍。懷疑范圍越小,后續對學生用戶分析越精確[4]。當數據不足的時候,能改善數據質量,做出準確分析。
第三步:構建分析邏輯。
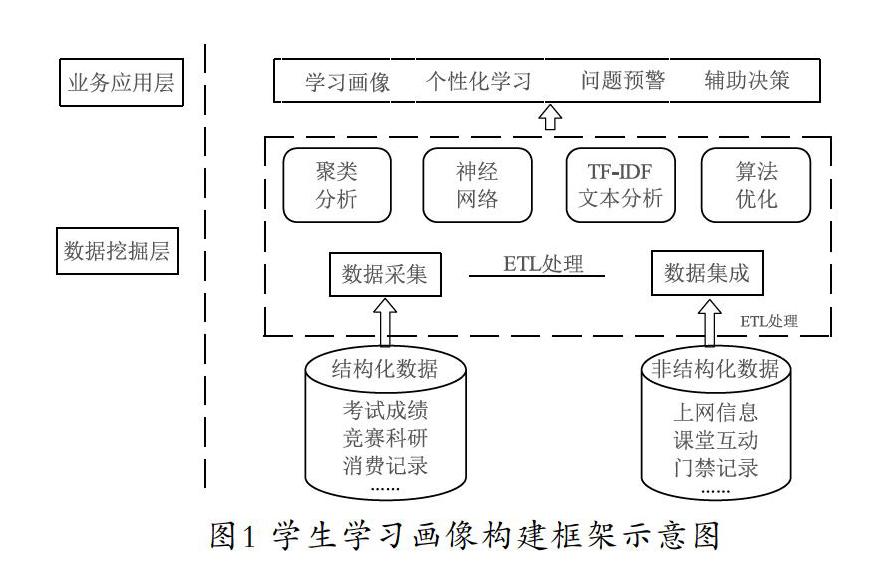
宏觀驗證以后,可基于已驗證的結論,構建更細致的分析邏輯。在這個階段,實際上已經把原本龐大的問題聚焦為一個個小問題。學生學習畫像構建框架可劃分為三個層次:數據源層、數據挖掘層和業務應用層。數據源層需要對結構化和非結構化的數據進行提取;數據挖掘層則需對所提取的數據建模,針對所建立的模型和運算結果進行充分應用,是業務應用層的基礎。學生學習畫像構建框架具體如圖1所示。
3.1? ?學生學習畫像的數據預處理
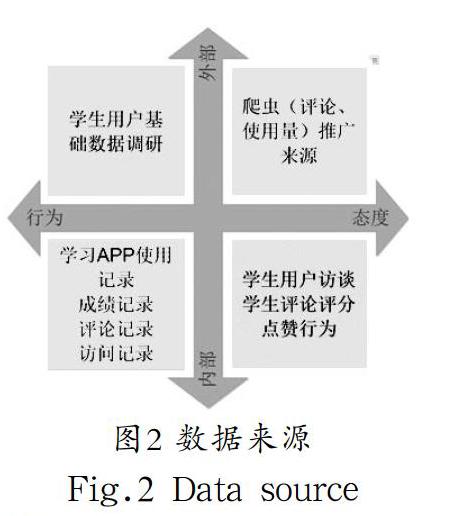
鑒于本文所需爬取的數據均存在于高校的學生信息數據庫和各大學習網絡平臺上,且各大學習網絡都提供了API,在數據爬取前申請key,以json形式返回文檔,方便解析。通過各種學習、社交平臺和上網流量監控,對學生的學習數據進行爬取。若數據呈結構化狀態則直接提取,若數據呈非結構化狀態則先對其進行賦值,再做數據無量綱化處理。利用模糊c均值聚類法和詞云圖過濾掉大量的文本信息及異常值,數據爬取時盡可能獲取全量的學生學習數據,為教師對學生學習成績的分析提供堅實的數據基礎,如學生成績數據、學生上網數據、學生消費數據、學生課堂行為數據及教師反饋數據等相關數據。數據來源如圖2所示。提取相應的數據,量化后建立標簽。
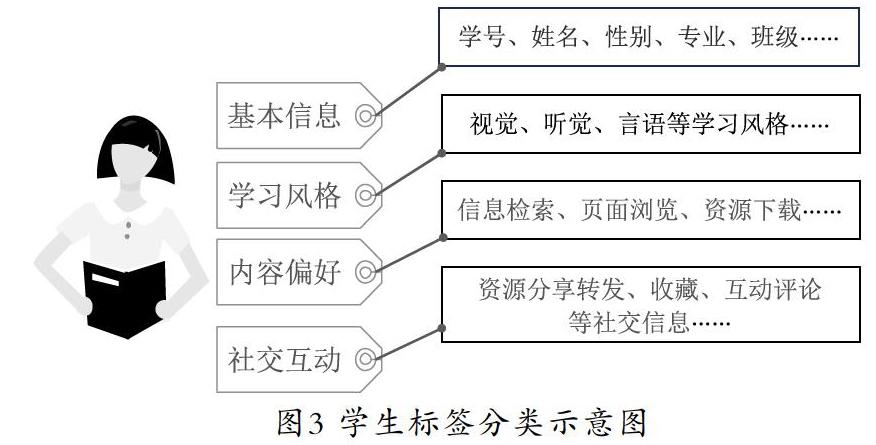
(1)基本信息標簽
基本信息是指一個學生的基本信息和變更頻率較低的代表性指標,此處提取學生的學號、姓名、性別、專業、班級及所關注的方向等,這些指標可以直接獲取。
(2)學習風格標簽
學習風格是學生用戶非常重要的一個方面,學生對學習方式的偏好及喜愛程度是學生學習畫像最重要的信息之一,是對用戶和學習方式之間的關系進行深度刻畫的重要標簽,其中最典型的是視覺(影視網課)、聽覺(語音錄播)、言語(交流討論)。
(3)內容偏好標簽
內容偏好記錄的是大學生學習、瀏覽、關注的內容。學生的瀏覽內容行為包括信息檢索、頁面瀏覽和資源下載等。由于這些瀏覽內容行為種類繁多且和不同的學習平臺、不同的模塊交互,不同時間進行不同操作,導致行為屬性更加復雜。針對如何能夠全面梳理,怎樣才能集成抽取出學生的內容偏好,可以按照圖2所示的分類方法來進行。
(4)社交互動標簽
學生學習時會進行社交、分享等一系列互動活動,主要有資源分享轉發、收藏、互動評論等。在該過程中,有些學生會瀏覽比較陌生的領域知識,而有些內容要通過一定知識量和案例的引導才會促使學生更深入地學習。通過建立社交活動標簽,可對不同專業的學生推送合理的學習資源,保證資源被學生最大化利用,使得投資回報率最大。該標簽下多種不同屬性的敏感度代表大學生對學習平臺的敏感程度,也是典型的挖掘類標簽。
學生標簽分類示意圖如圖3所示。
3.2? ?學生個性化學習模塊
構建學生學習個性化推薦模塊的核心任務之一是準確分析學生的興趣、特長、潛能,用完備且準確的屬性標簽對學生學習情況進行全覆蓋,從而極大促進精準學生個性化學習模塊推薦。根據數據源層抽取的數據并且結合已構建的學習畫像,利用KNN與樸素貝葉斯模型形成推薦列表。根據已確立的標簽存入數據訓練樣本集,每條數據記錄都有其對應的屬性及標簽。當輸入新的學生記錄時,此時該條數據不具備標簽,將新數據中的樣本與該條記錄最相似的數據進行比對,從而提取標簽集,故可根據新建后的標簽進行聚類分析。提取學生學習時的特征即上述不同標簽下的子屬性計算學生學習偏好與學習數據庫中的學習資源之間的相似度,再運用KNN分類器,按照遠近距離分配學習資源給不同的用戶群,形成學習資源的個性化推薦。針對學習資源推薦,分類的任務即為特定學生尋找合適的學習資源,用準確率(Precision)和召回率(Recall)衡量推薦成效,準確率表示學生對該項學習資源感興趣的概率,召回率為學生感興趣的資源被成功推薦的概率,準確率和召回率值越大表示推薦效果越好。用F表示準確率和召回率的調和平均值,其值越大表示推薦質量越高。
具體計算模型如下:
上式中,表示成功推薦給學生S的有效學習資源數量,表示推薦學習資源數量,表示符合學生需求的推薦學習資源數量,Precision代表準確率,Recall代表召回率。
召回步驟完成初篩,幫助分析學生學習興趣偏好,為進入下一流程進行粗排和精排做準備。對學生學習、消費、網絡使用及生活等行為數據進行分析,完成打分,從而最終推斷出學生大致的學習風格,達到為學生推薦個性化學習資源的目的。
3.3? ?問題預警模塊
根據已構建的學習畫像,結合學生在校線上及線下統計數據建模,對學生課堂學習、上網信息、門禁記錄等結果進行量化分析。運用BP神經網絡、RBF徑向基模型,輸入相應向量訓練網絡以達到局部逼近任意連續函數[5]。考慮到在訓練過程中分布逐漸偏移變動降低收斂速度,為防止模型過分擬合,故添加Batch Normalization層,為的是將輸入的學生成績數據數值進行標準化,緩解后期DNN訓練中的梯度消失問題,加快模型的訓練速度,使輸出的特征圖均勻度提升,增大梯度,提升收斂度,讓模型趨于穩定,從而根據學生個人屬性綜合趨勢對成績穩定性和掛科率進行預測。分析學生學習效率與掛科率、網絡使用、消費情況及失聯記錄等之間的關系,進而設立預警條件,達到預警目的。
3.4? ?輔助學校決策模塊
學生畫像的構建,可重點結合學校管理實際需求,分析所關聯的學生數據。可以進行問卷調查,從而完成描述性統計,并結合上文所構建的學生學習畫像模型[6]進行比對,直至提出最有利于學生的有關決策方案,為學校實現淺層干預與深層干預相結合的目標提供支撐,使制度政策能更好地服務于學生。
4? ?結論(Conclusion)
構建大學生學習畫像,建立合理有效的數據挖掘模型,根據模型輸出結果對學生進行個性化指導,具有一定的針對性和可操作性,并對改善學生學習效果、提高學生培養質量、發現有潛質的人才、提高學生綜合素質具有重要的現實意義。大學生學習畫像為高校管理者、教師提供了參考,有助于引導學生全面發展并發揮特長,為經濟社會輸送高質量、專業能力強的人才[7]。
參考文獻(References)
[1] 錢愛娟,董笑菊,沈綺文,等.高校圖書館用戶畫像與行為可視化分析[J].圖書館雜志,2020,39(10):82-88.
[2] 魏孔鵬,谷洪彬,李嘯龍,等.學生綜合素質評價的用戶畫像構建研究[J].計算機時代,2020(03):96-98.
[3] 呂挫挫.智慧校園視域下高校用戶畫像探究[J].大眾標準化,2020(19):45-48.
[4] 楊光瑩,杜敏,楊東梅,等.基于校園行為數據分析的學生畫像系統初步構建研究[J].教育教學論壇,2020(41):44-45.
[5] 張麗,呂康銀.智慧城市公共服務數據畫像及應用模式研究[J].情報科學,2020,38(10):61-67;89.
[6] 金岡增,李娜,鄭建兵,等.科研人員畫像系統設計與實現[J].軟件工程,2018,21(09):28;41-43.
[7] Ye Sun, Rongqian Chai. An Early-Warning Model for Online Learners Based on User Portrait[J]. Ingénierie des Systèmesd' Information, 2020, 25(4):26-43.
作者簡介:
陳? ? 會(1999-),男,本科生.研究領域:智慧校園.
余? ? 馨(2000-),女,本科生.研究領域:數據分析.
李琳琳(1999-),女,本科生.研究領域:信息經濟.
吳蘇徽(1998-),女,本科生.研究領域:數據分析.
蔣秀蓮(1968-),女,本科,高級工程師.研究領域:信息管理,信息經濟.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
