基于雙排序原理的先進先出數據核銷高速通用算法
2021-03-24 09:56:14王國忠
軟件工程 2021年3期
摘? 要:本文按照軟件中臺的思想,設計了一個針對先進先出(First-In First-Out, FIFO)[1]數據核銷的通用實現框架及其對應的入庫數據模型、消費數據模型和匹配核銷模型。同時,設計了基于雙排序原理的先進先出數據核銷高速實現方法。該方法按照匹配規則先對數據進行排序,然后對兩個有序隊列進行單循環匹配查找,避免了傳統先進先出實現中的雙循環操作,可以大幅度提高運算性能,大幅度節省CPU開銷和存儲開銷,實現超大數據量的快速匹配,可以支持兩個億級數據庫的快速先進先出匹配。
關鍵詞:先進先出;存儲過程;雙排序;面向對象
中圖分類號:TP31? ? ?文獻標識碼:A
Abstract: This paper proposed to design a general implementation framework for FIFO (First-In First-Out) data verification and its corresponding inbound data model, consumption data model and matching verification model based on idea of middle platform. At the same time, a high-speed realization method of FIFO data verification is designed based on the double sorting principle. This method first sorts data according to matching rules, and then performs a single-loop matching search on the two ordered queues, avoiding double-loop operation in traditional FIFO implementation. The proposed method significantly improves computing performance, and greatly saves CPU and storage overheads. As a result, it is capable of processing super large data volume, and can support fast FIFO matching of two databases with large data volume.
Keywords: First-In First-Out (FIFO); storage procedure; double sort; object-oriented
1? ?引言(Introduction)
先進先出是傳統庫存商品成本核算的一個通用方法,商品銷售先選擇最早采購的商品價格作為銷售商品的庫存成本。目前,國內很多企業對于各類消費數據都需要用先進先出的方法進行核算。隨著互聯網新零售大幅度崛起,消費數據從傳統的商品批發零售擴大到很多場景,例如CRM[2](Customer Relationship Management)的積分核銷[3]就是十分典型的一個應用,不同商家的積分產生和使用,需要相互結算。隨著全渠道零售的興起,各個結算主體之間也存在先進先出的結算需求。從軟件實現上來看,數據庫先進先出核銷需要解決模塊化和運算高效的技術難點。先進先出算法的缺陷會使系統運行性能變差,甚至導致系統癱瘓。
為了節省服務器的計算時間,需要設計一個通用的高速核銷引擎,方便應用程序直接調用,大幅度降低普通程序員對出入數據核銷實現的門檻。目前數據基本上都存儲在數據庫中,而程序開發工具大部分是Java或C語言等,通過JDBC/ODBC和數據庫連接讀取和寫入數據。由于數據庫和開發工具都具備運算能力,因此先進先出引擎可以利用開發工具能力,也可以利用數據庫能力,以及兩者混合能力來實現。
本文按照軟件中臺的思想,設計了一個針對先進先出數據核銷的通用實現框架及其對應的入庫數據模型、消費數據模型和匹配核銷模型。同時,為了克服傳統先進先出數據核銷中的雙循環操作瓶頸,設計了基于雙排序原理的先進先出數據核銷高速實現方法,通過先排序后先進先出,把先進先出算法從乘法變成加法,實現超高速的計算引擎[4],可以滿足超大數據的先進先出需求。
2? ?先進先出通用模型設計(Design of FIFO general model)
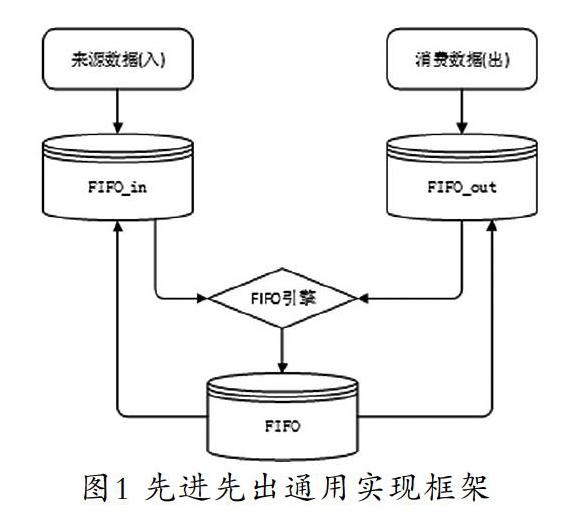
為了實現通用的先進先出引擎,本文設計了一個先進先出通用實現框架[5]。如圖1所示,該框架包含來源數據模型FIFO_in、消費數據模型FIFO_out和匹配核銷模型FIFO三個模塊。任何需要使用先進先出算法的系統,只要將數據按照要求存入兩個出入表,然后調用先進先出引擎運行,即可得到結果。
入庫數據模型FIFO_in,存儲來源數據。例如對于商品,就是采購入庫數據;對于顧客積分,就是顧客消費產生的積分。為了標識來源數據唯一性,該表需要加入來源數據的唯一主鍵信息,主要字段為:先進先出種類(用于區分應用場景,例如商品出入庫、顧客積分等)、來源數據關鍵詞(一般是入庫單號+商品+日期或產生積分的銷售小票單號+顧客信息+日期)、來源數據的數值(數量、金額、成本、積分等)、來源數據的優先級(解決FI的不同場景,例如后進先出,只需要調整優先級即可)、已核銷的數值(被FO匹配到的數值)、未被核銷的數值等。
消費數據模型FIFO_out,存儲使用數據。對于商品,就是銷售或批發數據;對于顧客積分,就是使用積分(包括積分抵現、退貨、積分換券等用掉的積分)。為了標識目標數據唯一性,該表需要加入消費數據的唯一主鍵信息,主要字段為:先進先出種類(商品出入庫或積分核銷等場景)、消費數據關鍵詞(一般是銷售單號或積分使用單號,加上產品或顧客信息)、消費數據的數值(數量、金額、成本、積分等)、消費數據的優先級(解決哪些數據優先處理的問題)、已匹配數據(已經匹配到的數值)等。
匹配核銷模型FIFO,存儲匹配記錄,即消費數據和來源數據核銷關系。這需要通過運行先進先出引擎從FIFO_out循環,逐行從FIFO_in表尋找。FIFO匹配核銷模型主要信息為:先進先出種類、出方關鍵詞、入方關鍵詞及核銷數據。
3? ?五種先進先出算法(Five FIFO algorithms)
傳統數據核銷大部分是單個數據發生后,通過某些條件去尋找來源,這樣實現比較簡單。例如,顧客使用積分抵現,由于積分可能是其他商家產生的,這樣就需要針對使用積分找到提供積分的商家銷售單進行結算。實現單個數據尋找算法很簡單,就是找到這個顧客以前的積分記錄,把未核銷的積分按照先進先出原則排序,逐個匹配,將匹配到的記錄存在數據庫中,并標記已經核銷的記錄,防止重復核銷。然而當數據數量非常龐大時,先進先出引擎算法的效率直接決定了整個系統的運算性能,一個有缺陷的先進先出算法會使系統運行性能變差甚至導致系統癱瘓。
傳統的先進先出數據核銷采用雙循環機制,運算量大,不適用于處理大規模的數據。為了解決這個問題,本文設計了基于雙排序原理的先進先出數據核銷高速實現方法。該方法按照匹配規則先對數據進行排序,然后對兩個有序隊列進行單循環匹配查找,避免了傳統先進先出實現中的雙循環操作,可以大幅度提高運算性能,節省CPU開銷和存儲開銷,實現超大數據量的快速匹配,可以支持兩個億級數據庫的快速先進先出匹配。本節從先進先出數據核銷算法演進的角度,對以下五種算法的原理和優缺點進行說明。
(1)軟件對象雙循環匹配查找:基于面向對象的軟件開發思想,先將來源數據和消費數據分別映射成開發工具環境的兩個對象,通過應用軟件(Java/C#)雙循環進行匹配查找,然后把結果寫到數據庫中。
(2)軟件調用數據庫命令交互查找匹配:應用軟件負責寫SQL查找和修改語句,交互式調用數據庫進行查找運算。這個方法中開發工具不存儲大量數據,全部利用數據庫的存儲和SQL能力,進行循環調用。
(3)數據庫內部雙循環匹配查找:利用數據庫的PL/SQL[6]能力,實現雙循環匹配查找,不需要非數據庫的開發語言代碼。
(4)開發語言雙排序單循環匹配查找:首先通過面向對象的開發語言排序,然后進行排序匹配查找,最后批量寫到數據庫中。
(5)數據庫排序單循環匹配查找:通過PL/SQL,利用數據庫的排序能力,直接在數據中排序快速匹配,不需要應用開發工具反復調用數據庫計算能力。
3.1? ?方法1:軟件對象雙循環匹配查找
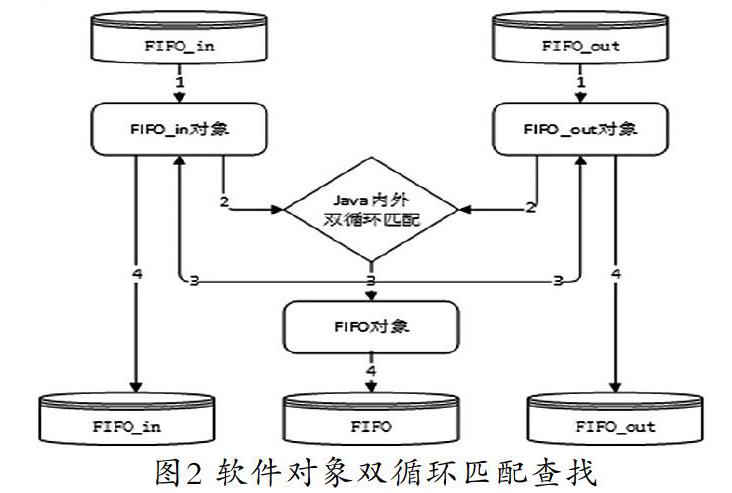
這是最傳統的面向對象的方法,利用應用開發工具,例如Java、C++[7]或.net,將來源數據和消費數據分別映射成開發工具環境的兩個對象,然后采用雙循環方法,對兩個對象進行匹配,最后將匹配結果存在FIFO對象并刷新FIFO_in和FIFO_out對象的已匹配數量,把對象保存到數據庫的表中,如圖2所示。
上述方法利用開發工具能力雙循環,總體的計算次數為:出數據記錄×進數據記錄,所以,總體運算量比較大,效率很低。其優點是方便理解,調試運維效率高。
3.2? ?方法2:軟件調用數據庫命令交互查找匹配
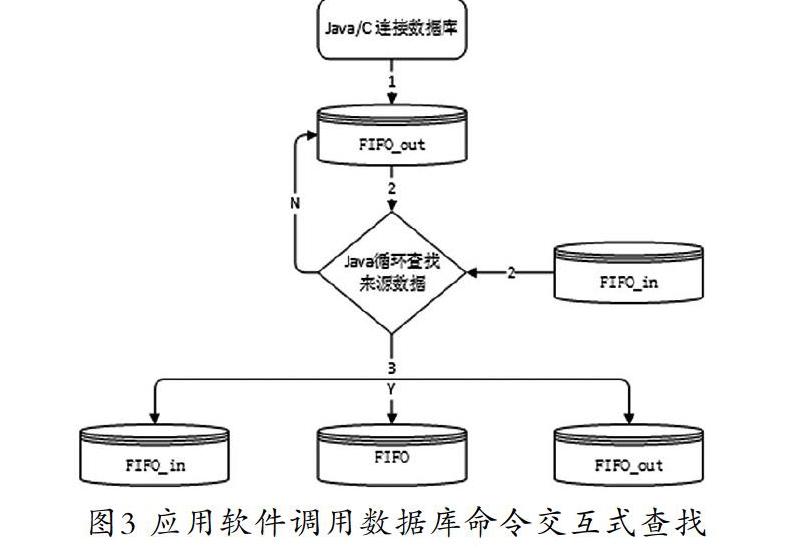
本方法也是傳統的算法,消費數據和來源數據不需要映射到對象,通過逐條把數據庫消費數據讀取到內存,然后根據條件從來源數據匹配,匹配到的直接寫入數據庫,如圖3所示。這個方法的特點是開發工具部署的應用環境內存消耗很低,存儲全部運用數據庫的能力,指示命令都是應用程序下達給數據庫的。這個方法類似傳統的C/S架構,客戶端發命令,數據庫運算,并且一次命令對應一個匹配運算。
這個方法的優點是調試方便,容易運維;缺點是運行效率很低,應用軟件和數據庫反復交互,每次SQL運行都需要編譯,代價比較大。這個算法一般是系統開發初期使用,成熟后需要升級到方法3。
3.3? ?方法3:數據庫內部雙循環匹配查找
本方法是方法2的改進,將開發工具的循環代碼通過
PL/SQL[8]翻譯成數據庫的存儲過程,在數據庫內部實現雙循環匹配查找,如圖4所示。這樣客戶端和數據庫只需要交互一次,具體循環全部在存儲過程中,大幅度減少了網絡交互的開銷和SQL反復編譯的代價。
該方法存儲過程的優點是運行效率很高,SQL代碼都是預編譯好的,大幅度節省了數據庫編譯SQL的時間,同時節省了開發語言和數據庫交互的網絡時延代價;缺點是出現問題時調試運維不方便,所以需要等方法2成熟后,再翻譯成存儲過程比較好。
3.4? ?方法4:開發語言雙排序單循環匹配查找
前面三個方法的特點是運用內外雙循環的傳統算法,運算量都是消費記錄和來源記錄的乘積,對于數據量很大的場景運算非常慢。特別是匹配出現異常,需要重新匹配的時間很長,無法快速高效支撐大型企業的應用,所以理論上只能停留在實驗室,不能投入生產系統。
先進先出本質上是兩個大表的匹配,雖然不是Join,實際上可以利用排序Join的思想,將運算量從乘法變成加法,極大提高運算的效率,有力支撐企業先進先出各種場景的應用,包括BI(Business Intelligence)分析需要的先進先出應用。
方法4通過開發語言將數據進行排序,然后基于排序后的隊列進行匹配查找,最后將結果批量寫到數據庫。圖5首先將來源和消費兩個大表數據映射成開發工具環境的兩個對象(類似方法1),然后分別按照匹配規則排序,變成兩個隊列。后續匹配算法變成了兩個隊列從頭開始同時向下循環,把雙循環變成單循環,運算量最大就是兩個隊列記錄數的總和。
排序是本方法的主要代價,需要利用已有的優秀排序算法進行快速排序,這樣才可以將兩個對象按照各自的排序進行單循環匹配。匹配過程是消費數據對象外循環,來源數據(進數據)為內循環。和雙循環的主要區別是,這兩個循環是同步進行的,誰匹配完一個就移到下一個,所以總的循環次數是兩個相加。匹配完成后,需要將匹配結果的對象寫回數據庫。
3.5? ?方法5:數據庫排序單循環匹配查找
方法4的缺點是需要將大量的數據讀到應用服務器的內存,匹配完還需要將大量的匹配數據寫回數據庫,代價比較大。所以方法5通過PL/SQL將方法4的代碼轉換成數據庫的存儲過程,利用數據庫的排序能力,可以大幅度提高運算性能,實現超大數據量的快速匹配,大幅度節省CPU開銷和存儲開銷。
圖6是數據庫排序匹配方法的流程圖,排序只需要數據庫建一個索引,每秒可以處理十萬條記錄。然后定義兩個Cursor,分別對應消費數據和來源數據,兩個循環組成單循環,第一個循環和第二個循環同時進行匹配,整個計算量最多是兩個表的記錄數相加,所以可以支持兩個億級數據量的快速先進先出匹配。
4? ?結論(Conclusion)
本文按照軟件中臺的思想,設計了一個針對先進先出數據核銷的通用實現框架及其對應的入庫數據模型、消費數據模型和匹配核銷模型,并對五種先進先出數據核銷的實現方法進行了闡述。對于企業應用,大部分采用方法5。先進先出作為企業級應用,模塊化價值比較高,可防止不同應用場景重復開發,造成額外開發量以及性能潛在的風險。不同算法對系統的要求不一樣,效果差異很大。普通程序員很容易使用前面運行效率低的算法,在系統開始運行幾個月后,造成系統癱瘓。對于有一定規模的企業應用數據,數據庫使用效率是十分重要的。先進先出只是數據庫應用中比較常用的一種方法,其他人工智能的算法也需要充分利用數據庫能力,合理設計算法。如果超過一個數據庫能力,就需要用多個數據庫以及大數據的方法解決。
參考文獻(References)
[1] 闞運奇.營銷零售行業先進先出算法設計[J].無線互聯科技,2012(12):98.
[2] 李靜.基于數據挖掘技術的電子商務CRM研究[J].現代電子技術,2015(11):126.
[3] 蔣文書.運用數據挖掘技術,精準把握客戶需求[J].軟件和集成電路,2018(Z1):20.
[4] 侯寧.大數據環境下并行化先進先出成本算法研究[J].軟件導刊,2019,18(06):85.
[5] 許桂平.基于數據庫的通用驅動程序自動編寫算法研究[J].電子設計工程,2019(15):166-169;174.
[6] CJ Fernandez Candel, J Garcia Molina, FJ Bermudez Ruiz, et al. Developing a model-driven reengineering approach for migrating PL/SQL triggers to Java: A practical experience[J].The Journal of Systems and Software,2019(151):38-64.
[7] 鐘玲玲,劉冬雪,黃小平,等.基于C語言的學生信息管理系統設計與實現[J].河南科技學院學報(自然科學版),2019(04): 62-67;78.
[8] 周嵐.Oracle中基于Java的存儲過程[D].合肥:安徽大學,2006.
作者簡介:
王國忠(1971-),男,碩士,講師.研究領域:大型分布式數據庫應用,企業級應用.
