藏文文本分類(lèi)技術(shù)研究綜述
2021-03-22 02:53:17蘇慧婧群諾
電腦知識(shí)與技術(shù) 2021年4期
關(guān)鍵詞:機(jī)器學(xué)習(xí)
蘇慧婧 群諾

摘要:該文介紹了藏文文本分類(lèi)技術(shù)的研究與進(jìn)展。首先對(duì)現(xiàn)階段常用的文本表示以及文本特征選擇方法進(jìn)行了分析和比較,接著回顧了藏文在機(jī)器學(xué)習(xí)方面的分類(lèi)算法特點(diǎn),深入討論了不同算法應(yīng)用在藏文文本分類(lèi)技術(shù)上的研究情況,最后指出了當(dāng)前藏文文本分類(lèi)所面臨的問(wèn)題和挑戰(zhàn),并對(duì)未來(lái)的研究提出了建議。
關(guān)鍵詞:藏文文本分類(lèi);文本表示;特征選擇;機(jī)器學(xué)習(xí)
中圖分類(lèi)號(hào): TP391? ? ? ? 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2021)04-0190-03
Abstract :This article introduces the research and development of Tibetan text classification technology. First, it analyzes and compares the commonly used text representation and text feature selection methods at this stage, then reviews the characteristics of Tibetan classification algorithms in machine learning, and discusses the application of different algorithms in Tibetan text classification technology. Finally, it points out the current problems and challenges of Tibetan text classification, and puts forward suggestions for future research.
Key words :Tibetan text classification; text representation; feature selection; machine learning
自然語(yǔ)言是人們?nèi)粘J褂玫恼Z(yǔ)言,是人類(lèi)學(xué)習(xí)生活的重要工具。為此,自然語(yǔ)言處理是人工智能的一個(gè)重要應(yīng)用領(lǐng)域,也是新一代計(jì)算機(jī)必須研究的課題。隨著我國(guó)藏族聚居區(qū)信息化事業(yè)的快速發(fā)展,藏族網(wǎng)民人數(shù)快速增長(zhǎng),以藏語(yǔ)為載體的內(nèi)容也在增多。對(duì)藏文文本分類(lèi)技術(shù)的研究,能夠拓寬藏文信息處理的應(yīng)用領(lǐng)域,推動(dòng)藏文語(yǔ)言文學(xué)在網(wǎng)絡(luò)時(shí)代的發(fā)展。文本特征的表示方法和分類(lèi)器模型的設(shè)計(jì)是有關(guān)文本分類(lèi)技術(shù)的關(guān)鍵步驟,本文簡(jiǎn)要提出了文本分類(lèi)系統(tǒng)的各個(gè)功能,依據(jù)現(xiàn)階段藏文文本分類(lèi)技術(shù)的研究進(jìn)展,詳細(xì)分析了文本表示以及特征選擇的不同方法和多種分類(lèi)器模型的算法特點(diǎn)和應(yīng)用前景。目前,我國(guó)對(duì)藏文古籍文獻(xiàn)的經(jīng)典信息需求量很大,因此,針對(duì)藏文文本,深入研究高效精準(zhǔn)的文本分類(lèi)技術(shù),具有十分重要的現(xiàn)實(shí)價(jià)值和歷史意義。
1 藏文文本分類(lèi)研究現(xiàn)狀和發(fā)展趨勢(shì)
在信息化時(shí)代背景下,藏文文本分類(lèi)技術(shù)作為藏文信息處理的一個(gè)重要組成部分,在情感分類(lèi)、檢測(cè)垃圾郵件、用戶意圖識(shí)別、客服工單自動(dòng)分類(lèi)等方面應(yīng)用廣泛。賈會(huì)強(qiáng)[1]等人提出了基于規(guī)則的藏文文本分類(lèi)方法;才讓加[2,3]等人對(duì)藏文語(yǔ)料進(jìn)行分詞標(biāo)注并利用詞性特征建立分類(lèi)語(yǔ)料庫(kù);孟祥和[4]提出了基于改進(jìn)的聚類(lèi)算法和KNN分類(lèi)算法實(shí)現(xiàn)藏文網(wǎng)站話題發(fā)現(xiàn)與跟蹤;袁斌[5]提出選用不同情感特征表示,基于SVM+TF-IDF進(jìn)行藏文微博情感分類(lèi)能達(dá)到比較不錯(cuò)的效果;周登[6]采用基于N-Gram模型的藏文文本分類(lèi)技術(shù);安見(jiàn)才讓等人[7]實(shí)現(xiàn)了互聯(lián)網(wǎng)藏文信息輿情分析的系統(tǒng)設(shè)計(jì);胥桂仙等人[8]設(shè)計(jì)了基于欄目的藏文網(wǎng)頁(yè)文本自動(dòng)分類(lèi)系統(tǒng)。賈宏云等人[9,10,11]分別選用藏文詞以及n-gram的藏文音節(jié)作為文本特征,采用信息增益算法、前向逐步回歸算法篩選最優(yōu)特征子集進(jìn)行文本表示,基于Logistic回歸模型、SVM模型以及AdaBoost模型實(shí)現(xiàn)藏文文本分類(lèi)并取得了不錯(cuò)的進(jìn)展。王莉莉等人[12]采用長(zhǎng)短時(shí)記憶加條件隨機(jī)場(chǎng)模型的方法對(duì)藏文分類(lèi)文本進(jìn)行分詞,運(yùn)用TF-IDF公式計(jì)算特征權(quán)重得到向量空間模型以進(jìn)行文本表示,通過(guò)互信息方法提取和選擇特征,基于多種深度神經(jīng)網(wǎng)絡(luò)模型得到了較好的分類(lèi)結(jié)果,但是該文選用的數(shù)據(jù)集在類(lèi)別數(shù)量以及文本規(guī)模上都相對(duì)較少,這將使得分類(lèi)模型性能不夠穩(wěn)定,泛化能力較低。
在目前藏文文本分類(lèi)研究中,已有少量基于規(guī)則和使用傳統(tǒng)機(jī)器學(xué)習(xí)方法的分類(lèi)研究,將神經(jīng)網(wǎng)絡(luò)模型應(yīng)用于藏文文本分類(lèi)的研究仍處于最淺顯層面,又因?yàn)槠脚_(tái)上缺乏開(kāi)源的藏文語(yǔ)料,而每個(gè)研究人員所使用的語(yǔ)料也大不相同,因此使得實(shí)驗(yàn)研究數(shù)據(jù)缺乏可比性,其分類(lèi)準(zhǔn)確率難以評(píng)估與分析。通過(guò)借鑒中英文中較為成熟的文本分類(lèi)方法,如何在資源不足的條件下訓(xùn)練模型,如何將人類(lèi)的先驗(yàn)知識(shí)融入神經(jīng)網(wǎng)絡(luò)中是藏文文本分類(lèi)面臨的挑戰(zhàn)和亟待解決的難題。
2 藏文文本分類(lèi)相關(guān)技術(shù)
藏文文本分類(lèi)由四個(gè)模塊組成:藏文語(yǔ)料獲取、文本表示以及特征選擇、模型訓(xùn)練、模型性能評(píng)價(jià)。
2.1 藏文語(yǔ)料獲取
在對(duì)文本進(jìn)行分類(lèi)之前,首先要獲取藏文語(yǔ)料,建立藏文數(shù)據(jù)集。我們可以從網(wǎng)上爬取藏文語(yǔ)料或者下載別人整理好的數(shù)據(jù)集,對(duì)其進(jìn)行預(yù)處理,通過(guò)預(yù)處理過(guò)程,減少特征維數(shù)、去除噪聲特征,以此提高機(jī)器學(xué)習(xí)算法的精準(zhǔn)度和分類(lèi)效果。過(guò)程包括分詞、剔除符號(hào)和停用詞,按類(lèi)別進(jìn)行人工分類(lèi),再按一定比例劃分訓(xùn)練集和測(cè)試集。
2.2 分詞
在英語(yǔ)的分詞中,詞與詞之間具有很自然的空格作為標(biāo)記,而對(duì)于藏文分詞,藏文與漢語(yǔ)相同,文檔的詞語(yǔ)之間沒(méi)有明顯的分隔標(biāo)志。藏文分詞領(lǐng)域的主要困難在于詞義消歧、命名實(shí)體識(shí)別。藏文自動(dòng)分詞技術(shù)主要有以下4類(lèi):
①通過(guò)最小匹配或最大匹配、正向匹配或逆向匹配方法切分字符串的機(jī)械分詞方法;
②根據(jù)字符串的語(yǔ)義、句法信息進(jìn)行詞性標(biāo)注的基于規(guī)則的分詞方法;
③通過(guò)匹配方法然后將統(tǒng)計(jì)語(yǔ)言模型引入分詞過(guò)程的基于統(tǒng)計(jì)的分詞方法;
④基于統(tǒng)計(jì)與規(guī)則相結(jié)合的方法,目前使用最為廣泛的是第四種方法。
2.3 剔除符號(hào)和停用詞
在文本預(yù)處理過(guò)程中,會(huì)剔除掉對(duì)分類(lèi)結(jié)果沒(méi)有實(shí)際意義的詞語(yǔ)和符號(hào),比如藏文文本中存在的一些特殊符號(hào)、標(biāo)點(diǎn)符號(hào)以及數(shù)字等。通過(guò)構(gòu)造停用詞表剔除掉這些對(duì)文本分類(lèi)無(wú)意義的詞項(xiàng),利用已建好的藏文語(yǔ)料庫(kù),使用公式n/N來(lái)計(jì)算權(quán)重,(n表示文檔中出現(xiàn)詞w的文檔數(shù),N表示總的文檔數(shù)),把其中權(quán)重高過(guò)某一閾值的詞列入停用詞表,閾值將由具體實(shí)驗(yàn)確定。
2.4 藏文文本分類(lèi)特征工程
對(duì)于計(jì)算機(jī)而言,它不能夠識(shí)別普通的文本中的字符串所要表達(dá)的信息,因此必須對(duì)文本中的字符串進(jìn)行處理,這樣的過(guò)程稱(chēng)為文本表示。藏文文本一般以音節(jié)為特征單位,按照一定的描述模型對(duì)文本進(jìn)行表示,使機(jī)器能夠?qū)ξ谋具M(jìn)行處理和運(yùn)算。
2.4.1 文本表示
在藏文文本分類(lèi)過(guò)程中,主要采用向量空間模型進(jìn)行文本表示。向量空間模型以空間上的相似度表達(dá)語(yǔ)義的相似度,表示如下:[V(d)=((t1,a1),(t2,a2),...,(tn,an))],其中,[ti]為文檔 d 中的特征項(xiàng),[ai] 為[ti] 的特征值,一般取為詞頻的函數(shù)。有了這樣的表示以后,就可以用分類(lèi)器對(duì)樣本分類(lèi)。
2.4.2 文本特征選擇
藏文語(yǔ)料文本經(jīng)過(guò)處理,從文本中產(chǎn)生的特征數(shù)量可能非常龐大,特征空間的維數(shù)會(huì)高達(dá)幾萬(wàn)維甚至幾十萬(wàn)維。如果用這些特征向量來(lái)進(jìn)行分類(lèi)訓(xùn)練,不但會(huì)占用很大的存儲(chǔ)資源,造成時(shí)間和空間的浪費(fèi),而且還會(huì)極大地影響分類(lèi)算法的運(yùn)行速度和降低分類(lèi)準(zhǔn)確度。為此可構(gòu)造一個(gè)評(píng)價(jià)函數(shù),通過(guò)實(shí)驗(yàn)設(shè)定一個(gè)閾值α,當(dāng)評(píng)估分?jǐn)?shù)低于閾值α就予以刪除,高于閾值α的若干特征項(xiàng)重新組成一個(gè)新的低維特征空間。利用特征評(píng)價(jià)函數(shù)來(lái)計(jì)算每個(gè)特征的重要程度。目前,在藏文文本分類(lèi)的研究過(guò)程中,常被運(yùn)用的特征選擇評(píng)估函數(shù)有逆文檔頻率(TF-IDF)、文檔頻率(DF)、互信息(MI)、信息增益(IG)、c2統(tǒng)計(jì)(CHI)、期望交叉熵(ECE)等。
大量的實(shí)驗(yàn)結(jié)果表明,過(guò)高的特征維數(shù)會(huì)導(dǎo)致時(shí)間空間復(fù)雜度急劇增加,造成更大的計(jì)算代價(jià);特征項(xiàng)維數(shù)過(guò)低則可能造成文檔重要信息的丟失,對(duì)文本的分類(lèi)效果造成影響。所以如何高效地選擇和提取特征,進(jìn)行文本特征表示需要綜合多種算法,反復(fù)實(shí)驗(yàn)。
2.5 分類(lèi)器的選擇與訓(xùn)練
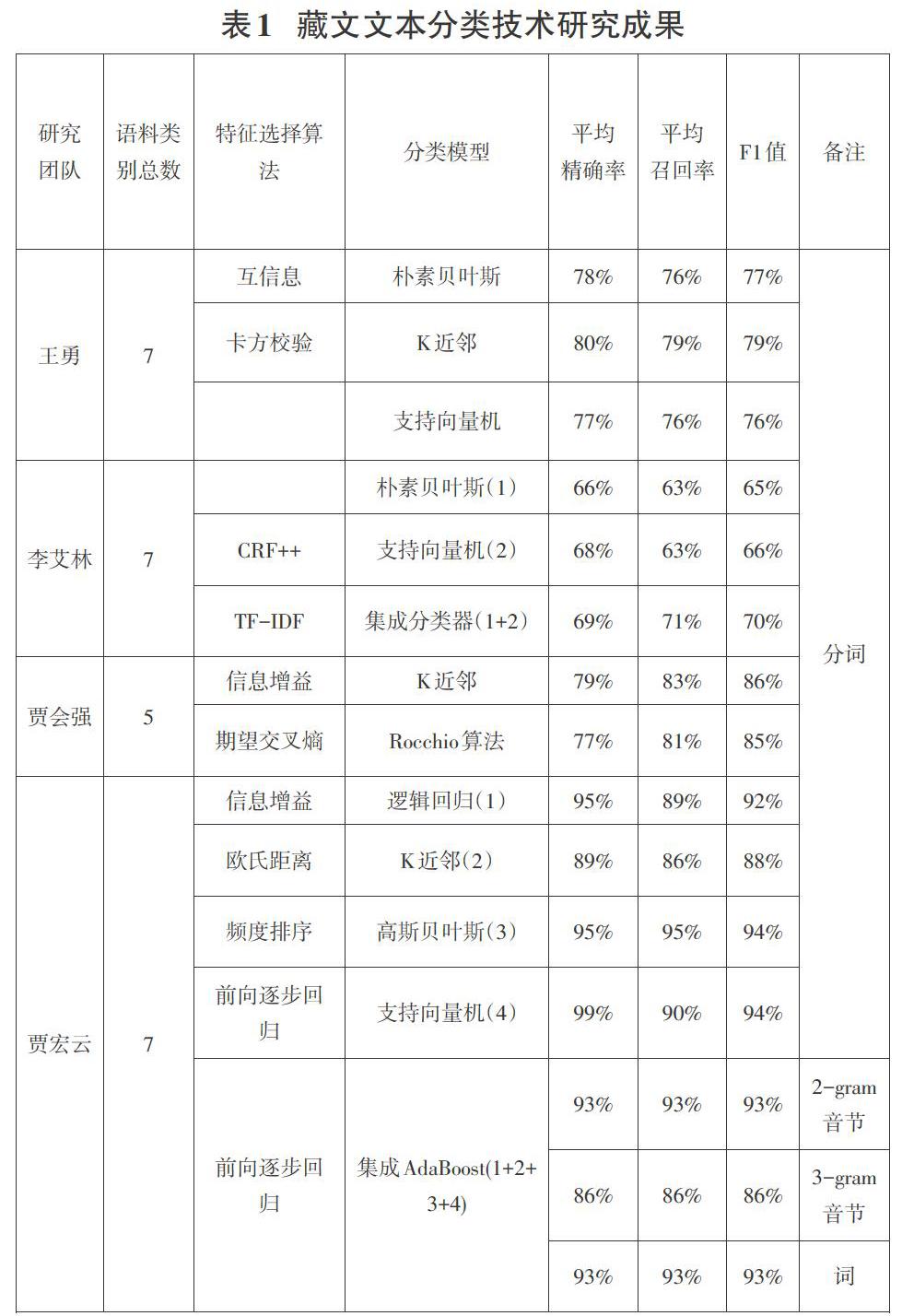
現(xiàn)階段,有關(guān)中英文的文本分類(lèi)模型種類(lèi)很多,實(shí)際應(yīng)用也相當(dāng)成熟,在藏文文本分類(lèi)研究領(lǐng)域,最近幾年藏文文本分類(lèi)技術(shù)研究的成果見(jiàn)表1所示。
表1實(shí)驗(yàn)中針對(duì)實(shí)際語(yǔ)料,選用特定特征選擇算法進(jìn)行特征降維和提取有效特征,基于淺層機(jī)器學(xué)習(xí)模型進(jìn)行文本分類(lèi),可以看出將多種算法集成的分類(lèi)模型可以有效提升分類(lèi)效果。但這些算法大都需要人工參與定制規(guī)則,并且分類(lèi)模型泛化能力較低。樸素貝葉斯算法簡(jiǎn)單,分類(lèi)效果穩(wěn)定;所需估算的參數(shù)少,但此算法適用于小規(guī)模數(shù)據(jù)的訓(xùn)練,且需要假設(shè)屬性之間相互獨(dú)立,而實(shí)際中往往難以成立。支持向量機(jī)可用于高維數(shù)據(jù)的計(jì)算,但對(duì)缺失數(shù)據(jù)較敏感;針對(duì)非線性問(wèn)題沒(méi)有通用的解決方案。近年來(lái)興起的深度神經(jīng)網(wǎng)絡(luò)具有較強(qiáng)的并行處理能力,自學(xué)習(xí)能力強(qiáng),能解決復(fù)雜的非線性關(guān)系,具有記憶的功能,但是在神經(jīng)網(wǎng)絡(luò)訓(xùn)練過(guò)程中需預(yù)先確定大量參數(shù),且所得信息高度編碼不易被解讀,輸出結(jié)果難以解釋。
綜合分析以上算法的優(yōu)缺點(diǎn),本文選用K近鄰(KNN)、高斯貝葉斯(Gaussian NB)兩種淺層機(jī)器學(xué)習(xí)模型算法和多層感知機(jī)(MLP)、深度可分離卷積(SepCNN)兩種神經(jīng)網(wǎng)絡(luò)模型進(jìn)行分類(lèi)實(shí)驗(yàn),整理實(shí)驗(yàn)數(shù)據(jù),得到表2。
從表2實(shí)驗(yàn)數(shù)據(jù)可以看出,在大規(guī)模數(shù)據(jù)集下,基于深度學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)模型比基于淺層機(jī)器學(xué)習(xí)的單一模型分類(lèi)效果要好,避免了煩瑣的人工特征工程,節(jié)省了部分人力開(kāi)銷(xiāo)。因此研究文本分類(lèi),其方法與模型的選擇和要解決的問(wèn)題及問(wèn)題的規(guī)模有關(guān),根據(jù)文本分類(lèi)的各個(gè)流程采取對(duì)應(yīng)的解決辦法,是當(dāng)前藏文文本分類(lèi)研究的重要方向。
2.6 分類(lèi)結(jié)果的評(píng)價(jià)與反饋
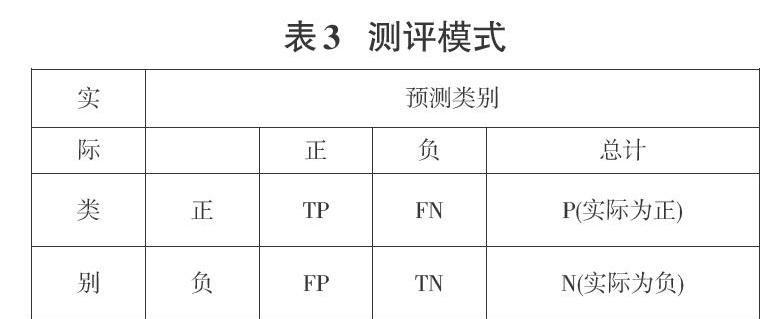
模型最終常用準(zhǔn)確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1值來(lái)對(duì)分類(lèi)器的性能進(jìn)行綜合評(píng)價(jià)。假設(shè)只有兩類(lèi)樣本,即正例(positive)和負(fù)例(negative)。TP表示將實(shí)際正類(lèi)預(yù)測(cè)為正類(lèi)預(yù)測(cè)正確的數(shù)值,F(xiàn)N表示將實(shí)際正類(lèi)預(yù)測(cè)為負(fù)類(lèi)預(yù)測(cè)錯(cuò)誤的數(shù)值,F(xiàn)P表示將實(shí)際負(fù)類(lèi)預(yù)測(cè)為正類(lèi)預(yù)測(cè)錯(cuò)誤的數(shù)值,TN表示將實(shí)際負(fù)類(lèi)預(yù)測(cè)為負(fù)類(lèi)預(yù)測(cè)正確的數(shù)值[13]。形成表3如下所示。
表中AB模式:第二個(gè)符號(hào)表示預(yù)測(cè)的類(lèi)別,第一個(gè)表示預(yù)測(cè)結(jié)果對(duì)了(True)還是錯(cuò)了(False)。分類(lèi)準(zhǔn)確率(accuracy):分類(lèi)器正確分類(lèi)的樣本數(shù)與總樣本數(shù)之比, 精確率(Precision)反映了模型判定的正例中真正正例的比重,召回率(Recall)反映了總正例中被模型正確判定正例的比重[13]。F值是精確率和召回率的調(diào)和平均。各測(cè)評(píng)標(biāo)準(zhǔn)如表4所示。
3 面臨的問(wèn)題與挑戰(zhàn)
目前藏文文本分類(lèi)技術(shù)依舊面臨著諸多問(wèn)題與挑戰(zhàn)。由于藏文信息處理技術(shù)缺乏統(tǒng)一規(guī)范化的標(biāo)準(zhǔn),導(dǎo)致部分網(wǎng)頁(yè)藏文資源字符編碼方式不統(tǒng)一,使得計(jì)算機(jī)不能有效處理藏文字符;現(xiàn)階段該領(lǐng)域還未能研究出較為成熟的分詞技術(shù);藏文文本分類(lèi)的相關(guān)技術(shù)大都借鑒漢語(yǔ)、英語(yǔ)的處理方法,針對(duì)藏語(yǔ)自身的特點(diǎn)和規(guī)律研究欠缺;近年來(lái)發(fā)展較成熟的word2vec詞向量預(yù)訓(xùn)練模型在藏文方面的遷移應(yīng)用研究尚淺;藏文信息方面不僅缺少開(kāi)源語(yǔ)料,也缺少基于深度學(xué)習(xí)取得的成果,這些問(wèn)題都制約了藏文文本分類(lèi)技術(shù)的研究與發(fā)展。
4 結(jié)束語(yǔ)
本文總結(jié)了到目前為止藏文文本分類(lèi)技術(shù)的研究現(xiàn)狀,分析了當(dāng)前研究所面臨的問(wèn)題與困難,并針對(duì)問(wèn)題的解決和未來(lái)的研究提出了建設(shè)性的建議。藏文文本分類(lèi)系統(tǒng)和其他語(yǔ)種的文本分類(lèi)系統(tǒng)相比還存在著很大的差距,對(duì)于藏文自身的語(yǔ)言特點(diǎn),適用于大語(yǔ)種的研究方法并不能完全適用于藏文的研究。因此,對(duì)藏文在文本分類(lèi)的基本理論和處理模型上進(jìn)行針對(duì)性的創(chuàng)新是我們未來(lái)的研究方向。后續(xù)希望研究者能夠不斷對(duì)比各種分類(lèi)技術(shù)并且參考各領(lǐng)域最新的文本分類(lèi)的研究成果,在深度學(xué)習(xí)方法上,尋求突破,探討實(shí)踐出更加優(yōu)化的藏文文本分類(lèi)系統(tǒng)。
參考文獻(xiàn):
[1] 賈會(huì)強(qiáng),李永宏.藏文文本分類(lèi)器的設(shè)計(jì)與實(shí)現(xiàn)[J].科技致富向?qū)В?010(12):30-31.
[2] 才讓加.藏語(yǔ)語(yǔ)料庫(kù)加工方法研究[J].計(jì)算機(jī)工程與應(yīng)用,2011,47(6):138-139,146.
[3] 才讓加,吉太加.藏語(yǔ)語(yǔ)料庫(kù)的詞性分類(lèi)方法研究[J].青海師范大學(xué)學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版),2005,27(4):112-114.
[4] 孟祥和.藏文網(wǎng)站話題發(fā)現(xiàn)與跟蹤技術(shù)研究[D].西北民族大學(xué),2013.
[5] 袁斌.藏文微博情感分類(lèi)研究與實(shí)現(xiàn)[D].西北民族大學(xué),2016.
[6] 周登.基于N-Gram模型的藏文文本分類(lèi)技術(shù)研究[D].西北民族大學(xué),2010.
[7] 安見(jiàn)才讓?zhuān)耄瑢O琦龍.互聯(lián)網(wǎng)藏文信息輿情分析系統(tǒng)設(shè)計(jì)[J].微處理機(jī),2017,38(2):56-58,63.
[8] 胥桂仙,向春丞,翁彧,等.基于欄目的藏文網(wǎng)頁(yè)文本自動(dòng)分類(lèi)方法[J].中文信息學(xué)報(bào),2011,25(4):20-23.
[9] 群諾,賈宏云.基于Logistic回歸模型的藏文文本分類(lèi)研究與實(shí)現(xiàn)[J].信息與電腦(理論版),2018(5):70-73.
[10] 賈宏云,群諾,蘇慧婧,等.基于SVM藏文文本分類(lèi)的研究與實(shí)現(xiàn)[J].電子技術(shù)與軟件工程,2018(9):144-146.
[11] 賈宏云.基于AdaBoost模型的藏文文本分類(lèi)研究與實(shí)現(xiàn)[D].西藏大學(xué),2019.
[12] 王莉莉,楊鴻武,宋志蒙.基于多分類(lèi)器的藏文文本分類(lèi)方法[J].南京郵電大學(xué)學(xué)報(bào)(自然科學(xué)版),2020,40(1):102-110.
[13] 鄭雅文. 基于特征選擇和支持向量機(jī)的乳腺癌診斷研究[D].太原理工大學(xué),2019.
【通聯(lián)編輯:唐一東】
猜你喜歡
電子技術(shù)與軟件工程(2016年22期)2016-12-26 21:36:42
時(shí)代金融(2016年27期)2016-11-25 17:51:36
科教導(dǎo)刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學(xué)與財(cái)富(2016年28期)2016-10-14 21:19:17
電腦知識(shí)與技術(shù)(2016年20期)2016-08-19 18:49:49
電腦知識(shí)與技術(shù)(2016年12期)2016-06-14 00:45:31
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 19:17:03
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識(shí)與技術(shù)(2016年3期)2016-04-07 16:12:55
