基于Expectimax 搜索與Double DQN 的非完備信息博弈算法
2021-03-18 08:04:16雷捷維王嘉旸閆天偉
計算機工程 2021年3期
雷捷維,王嘉旸,任 航,閆天偉,黃 偉
(1.南昌大學信息工程學院,南昌 330031;2.江西農業大學軟件學院,南昌 330000)
0 概述
博弈論是研究具有斗爭或競爭性質現象的數學理論和方法,是經典的研究領域之一。博弈問題存在于人們生活各個方面。例如,商品定價可看作商人和顧客之間的博弈,國家之間的經濟與軍事競爭也可視為博弈問題。現實中博弈問題比較復雜,人們通常將其經過抽象處理轉化為便于研究的游戲模型再加以解決。博弈主要分為完備信息博弈和非完備信息博弈。在完備信息博弈中,玩家可看到全部游戲狀態信息,不存在隱藏信息。例如,圍棋、國際象棋和五子棋等均為完備信息博弈。在非完備信息博弈中,玩家僅可看到自身游戲狀態信息和公共信息,而無法獲取其他游戲信息。例如,麻將、橋牌和德州撲克等均為非完備信息博弈。由于現實中許多博弈問題無法獲取全部信息而被歸類為非完備信息博弈,因此非完備信息博弈問題受到廣泛關注。研究非完備信息博弈,可解決金融競爭[1]、交通疏導[2]、網絡安全[3]和軍事安全[4]等領域的問題。
近年來,關于完備信息博弈和非完備信息博弈的研究在多個應用領域取得突破性進展。在圍棋應用方面,Google 公司DeepMind 團隊開發出AlphaGo、AlphaGoZero 和AlphaZero 等系列圍棋博弈程序,并結合蒙特卡洛樹搜索與深度強化學習算法[5-7]進行實現。2016 年,AlphaGo 以4∶1 擊敗韓國專業圍棋選手李世石引發社會關注。在德州撲克應用方面,2015 年BOWLING 等人[8]在《Science》雜志發表關于CFR+算法的論文,證明該算法已完全解決兩人受限的德州撲克博弈問題。2017 年,阿爾伯塔大學開發出DeepStack系統,結合CFR 算法與多層深度神經網絡(Deep Neural Network,DNN)[9]解決了德州撲克一對一無限注博弈問題。此外,人們還對《星際爭霸II》等多人非合作游戲進行研究,取得眾多研究成果[10-12]。
相關研究顯示,麻將的復雜度要高于圍棋和德州撲克[13],然而目前關于麻將研究較少,大多數麻將程序僅基于人工經驗進行設計,未結合最新的強化學習等方法。目前麻將程序設計主要采用Expectimax 搜索算法[14-15]。2008 年,林典余[16]根據Expectimax 搜索算法以贏牌最快為原則設計麻將程序LongCat。2015 年,荘立楷[17]提出轉張概念對LongCat進行改進,利用所得麻將程序VeryLongCat進一步提升LongCat的贏牌效率,并贏得該年度臺灣計算機博弈比賽和國際計算機博弈比賽的冠軍。然而在麻將游戲中要想贏牌,除了提高贏牌效率之外,還需提高贏牌得分。目前LongCat 和VeryLongCat 的剪枝策略和估值函數均基于人工先驗知識設計,由于人類經驗中常存在不合理的決定或假設[18-19],因此設計更合理的剪枝策略和估值函數成為亟待解決的問題。
為解決上述非完備信息博弈問題,本文以麻將為例進行研究。目前麻將程序主要采用Expectimax搜索算法,其計算時間隨著搜索層數的增加呈指數級增長,且其剪枝策略與估值函數基于人工先驗知識設計得到。本文提出一種結合Expectimax 搜索與Double DQN 算法的非完備信息博弈算法,利用Double DQN[20]算法給出的子節點預估得分,為Expectimax 搜索算法設計更合理的估值函數與剪枝策略,并將游戲實際得分作為獎勵訓練Double DQN網絡模型以得到更高得分與勝率。
1 相關理論
1.1 Expectimax 搜索算法
Expectimax搜索樹[14-15]是一種常見的搜索算法,廣泛應用于非完備信息博弈游戲,其結構如圖1所示。在此類游戲中,由于某些信息具有隨機性和隱藏性,因此無法使用傳統的minimax搜索樹算法[21]來解決。針對該問題,Expectimax 搜索算法中設計了max 節點和chance 節點。其中,max 節點和chance 節點的效用值分別是其全部子節點效用值的最大值與加權平均值(即當前節點到達每個子節點的概率)。例如,對于圖1中值為39 的max 節點,39 為其所有子節點(chance 節點)的最大值;對于值為14的chance節點,14為其所有子節點(max節點)的加權平均值,即:14=20×0.4+10×0.6。Expectimax 搜索算法與大多數游戲樹搜索算法類似,也是通過啟發式估值函數計算各節點估值。
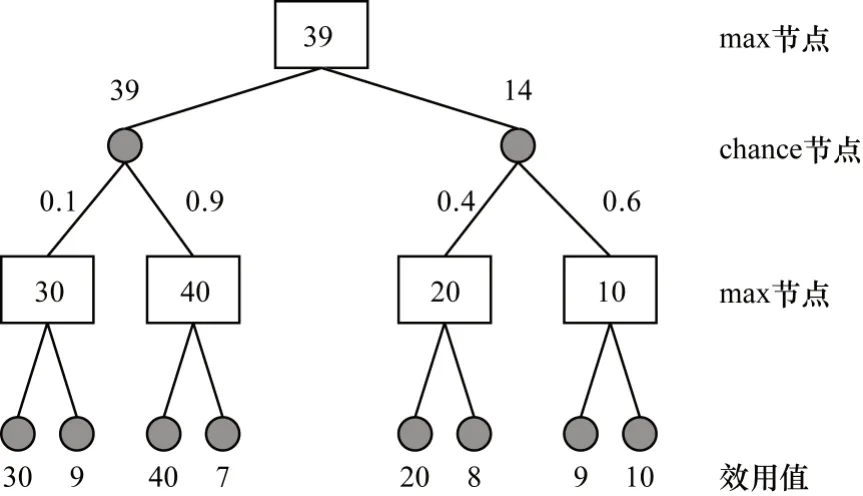
圖1 Expectimax 算法的搜索樹結構Fig.1 Search tree structure of Expectimax algorithm
1.2 Double DQN 強化學習算法
強化學習源于智能體對人類學習方式的模仿,是智能體通過與環境交互不斷增強其決策能力的過程。強化學習算法主要包括動態規劃算法[22]、時序差分算法[23]、蒙特卡洛算法[24]和Q 學習算法[25]。這些算法均存在局限性:動態規劃算法雖然數學理論完備,但是其使用條件非常嚴格;時序差分算法可在無法獲取環境全部信息的情況下得到較好效果;蒙特卡洛算法需對當前未知環境進行采樣分析,由于時間與空間具有復雜性,因此其很難應用于解決時序決策問題;Q 學習算法是通過計算每個動作的Q 值進行決策,但是其存在過估計問題。
隨著對強化學習研究的不斷深入,研究人員對Q 學習算法改進后提出深度Q 學習算法DQN[26-27],該算法與Q 學習算法一樣,也是通過計算每個動作的Q 值進行決策,仍存在過估計問題。為解決該問題,研究人員在DQN 基礎上提出雙重深度Q 學習算法Double DQN[20]。
DQN 算法具有原始網絡和目標網絡兩個神經網絡,雖然其結構相同,但是權重更新不同步。DQN算法的權重更新使用均方誤差(Mean Squared Error,MSE)定義損失函數,其表達式如下:
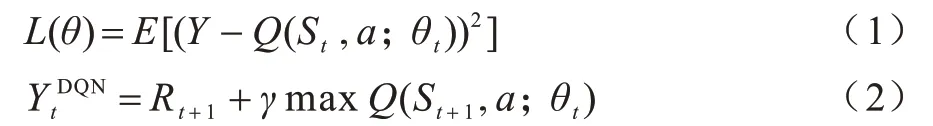
其中,a為執行動作,Rt+1為獎勵分數,St為當前游戲狀態信息,St+1為下一個游戲狀態信息,θ為網絡權重,γ為折扣因子,Q(S,a)為狀態S下執行動作a的估值。
由于Q 學習算法和DQN 算法中Max 操作使用相同值選擇和衡量一個動作,可能選擇估計值過高的動作導致過估計問題。為此,Double DQN 算法對動作的選擇和衡量進行解耦,將式(2)改寫為以下形式:
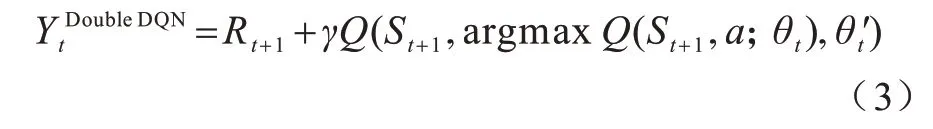
2 本文算法
2.1 基于Expectimax 搜索的麻將決策過程
由于麻將游戲過程中存在發牌隨機性等不確定因素,因此其規則比較復雜。在麻將游戲中,玩家可通過捉牌、吃牌、碰牌和杠牌等方式獲得一張牌,隨后需再打出一張牌,后續重復上述步驟,直到游戲結束為止。如果將吃牌、碰牌和杠牌視為特殊的捉牌,則麻將中所有動作均可用序列<捉牌,打牌,捉牌,打牌…>來表示。其中,捉牌動作記錄捉牌玩家的用戶ID 以及捉哪張牌等信息,打牌動作記錄打牌玩家的用戶ID 以及打哪張牌等信息。
假設A、B、C 和D 代表4 名玩家,其中A 為當前玩家,B、C、D 為其他玩家。如果A 捉牌“9 萬”后打牌“6 萬”,B 碰牌“3 萬”后打牌“7 筒”,A 碰牌“7 筒”后打牌“1 萬”,那么上述動作序列可表示為。
實際上,如果在決策中考慮所有玩家的動作,則Expectimax 算法的搜索樹很大,從而無法在有限時間內做出決策。為解決該問題,通常將整個游戲博弈過程進行抽象處理,僅考慮當前玩家的捉牌與打牌動作,并以此構建Expectimax 算法的搜索樹。此外,為進一步簡化搜索樹,將吃牌、碰牌和杠牌也作為特殊的捉牌,則上述動作序列表示為。
通過上述方法,本文將麻將游戲過程簡化為捉牌和打牌兩個動作。結合Expectimax 搜索算法,將捉牌動作看作chance 節點,打牌動作看作max 節點。例如,假設當前玩家手中持有的牌(以下稱為手牌)為1 萬、2 萬、4 萬、9 萬和9 萬,那么基于Expectimax算法的麻將搜索樹結構如圖2 所示。
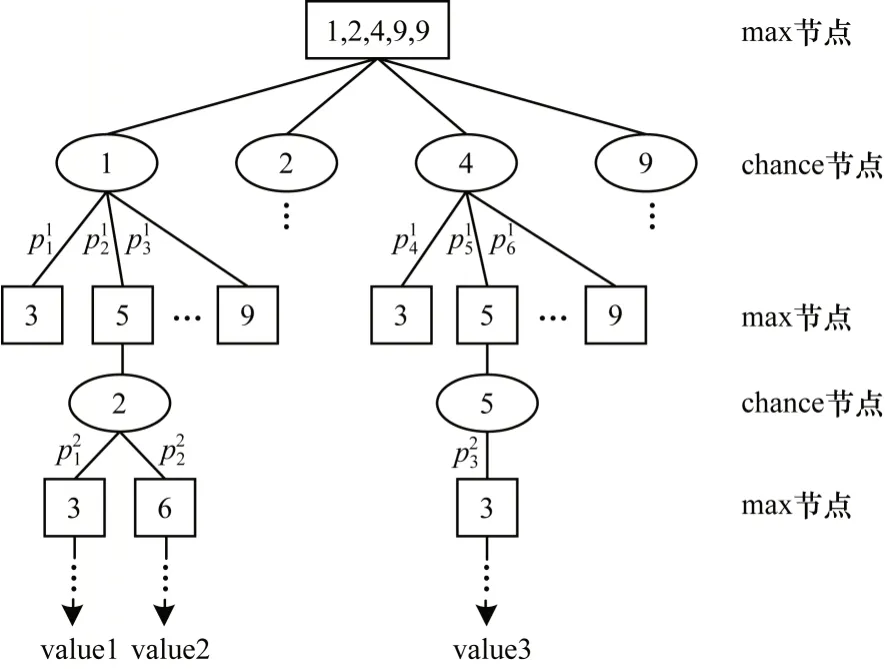
圖2 基于Expectimax 算法的麻將搜索樹Fig.2 Mahjong search tree based on Expectimax algorithm
在圖2 中:max 節點表示打牌節點;chance 節點表示捉牌節點;將“打牌節點,捉牌節點”作為搜索樹的一層;value 值表示游戲結束時當前游戲樹分支獲得的分數表示當前第i層捉牌節點(父節點)轉移到第j個打牌節點的概率。計算公式如下:
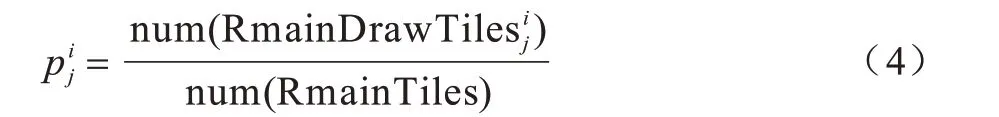
其中,num(RmainTiles)表示牌庫中剩余牌的數量,表示使第i層捉牌節點轉移到第j個打牌節點的麻將牌。而表示該麻將牌在牌庫中的剩余數量。由圖2 和式(4)可計算出每個捉牌節點與打牌節點的值。
捉牌節點的值等于其所有子節點分數的加權平均值,計算公式為:
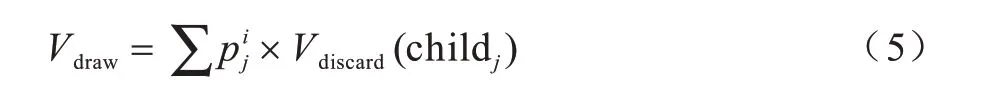
打牌節點的值等于其所有子節點的最大分數,計算公式為:

在有限時間內通常無法完全搜索整個游戲樹,為使算法能在限定時間內響應,主要采取兩種方法:1)限制搜索樹深度并用估值函數評估當前節點的值;2)設計一種合理的剪枝策略對游戲樹進行剪枝。由于Expectimax 搜索算法的估值函數與剪枝策略均基于人工先驗知識而設計,因此該算法的決策水平在很大程度上取決于設計者對麻將的理解。為擺脫人工先驗知識的局限性,進一步提高算法決策水平,本文結合Double DQN 算法對傳統的Expectimax 搜索算法進行改進。
本文將Double DQN 算法所用神經網絡設為fθ。其中,參數θ表示神經網絡的權重,神經網絡的輸出是一個34 維的數據,表示34 種出牌對應的分數(Q值)。
1)對Expectimax 搜索算法中剪枝策略進行改進,如圖3 所示。對于當前玩家的手牌,可通過神經網絡fθ(S)計算每個打牌動作對應的Q值。
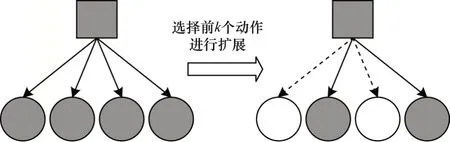
圖3 改進Expectimax 搜索算法的剪枝策略Fig.3 The pruning strategy of the improved Expectimax search algorithm
在搜索樹擴展的過程中,先通過神經網絡的估值對所有打牌動作從大到小進行排序,再將前k個動作擴展為子節點,余下動作不再擴展,從而達到剪枝的目的。k值的計算公式如下:
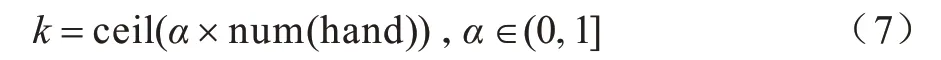
其中,num(hand)表示當前玩家手牌的牌數。由于神經網絡能估算出每個動作的Q值,因此通過為每個動作的Q值排序,只擴展前k個動作來減小搜索樹的廣度,從而實現對搜索樹剪枝,使計算機在有限時間內將更多時間用于搜索樹的深度擴展。
2)改進Expectimax 搜索算法的估值函數,如圖4所示。若麻將搜索樹某個分支在限定搜索層數內能到達游戲結束狀態并獲得分數,則將該分支的值設置為游戲實際分數;否則需設計合理的評估函數,并將其估值作為該分支的值。
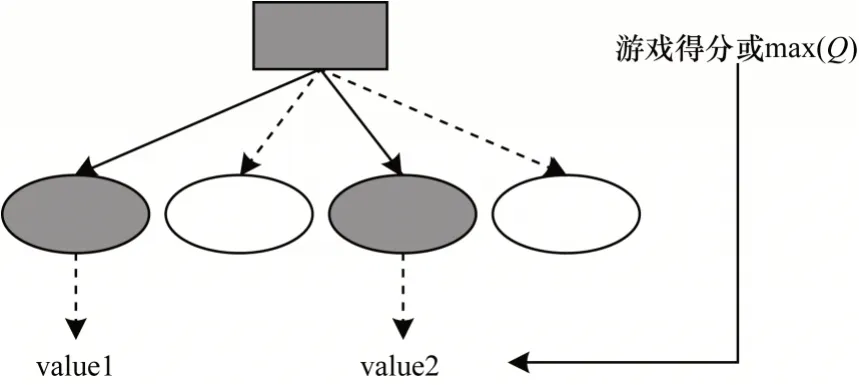
圖4 改進Expectimax 搜索算法的估值函數架構Fig.4 Evaluation function architecture of the improved Expectimax search algorithm
傳統Expectimax 搜索算法的估值函數大部分是基于人工先驗知識而設計,存在不合理的決定或假設。本文采用Double DQN 神經網絡的Q值解決該問題。如果麻將搜索樹的一個分支在限定搜索層數內無法到達游戲結束狀態,則可通過神經網絡計算當前節點的Q值作為該分支的值,即:構造一個打牌節點,再根據神經網絡計算出每個動作的Q值,并選擇最大的Q值max(Q) 作為該分支的值。改進Expectimax 搜索算法的估值函數架構如圖4 所示。
2.2 基于Double DQN 的麻將模型訓練過程
2.2.1 基于麻將先驗知識的特征編碼
在麻將游戲中,由于當前玩家對其他玩家的手牌以及牌庫內的牌不可見,因此麻將是典型的非完備信息博弈游戲,如何只根據游戲部分信息進行正確決策是需要考慮的問題。
以下介紹基于麻將先驗知識的特征編碼,如表1所示。這些特征包括當前玩家的手牌、當前玩家的副露、其他玩家的副露、所有玩家的棄牌以及游戲輪數等。基于麻將相關先驗知識可描述當前游戲全部可見信息,從而加快麻將模型訓練速度。本文使用ResNet 網絡[28]模型進行訓練,因此,需要將特征重塑為二維矩陣,即以填零的方式將特征向量轉換為19×19的二維矩陣,并將其輸入到ResNet 網絡。

表1 基于麻將先驗知識的特征編碼Table 1 Feature coding based on mahjong prior knowledge
2.2.2 Double DQN 麻將模型的訓練過程
圖5 為結合Expectimax 搜索算法的Double DQN網絡模型訓練過程,其具體步驟如下:
1)獲取游戲中當前玩家的手牌、當前玩家的副露、其他玩家的副露、所有玩家的棄牌、游戲輪數、牌庫剩余牌數等全部可見信息。
2)根據麻將的先驗知識,將可見信息編碼為特征數據。
3)將編碼后的特征數據輸入Double DQN 神經網絡,從而獲得每個動作的估值。
4)基于每個動作的估值,使用改進的Expectimax搜索算法精確計算出具有最高得分的推薦動作,然后執行該動作。
5)動作執行完畢即可獲得下一個游戲狀態信息與該動作的獎勵分數。
6)根據執行動作、獎勵分數、當前游戲狀態信息和下一個游戲狀態信息,結合梯度下降算法對Double DQN神經網絡進行訓練后得到麻將強化學習模型。其中,梯度下降算法在Double DQN 神經網絡中需最小化的損失函數如式(1)所示,Double DQN 算法中Y值按照式(3)進行計算。
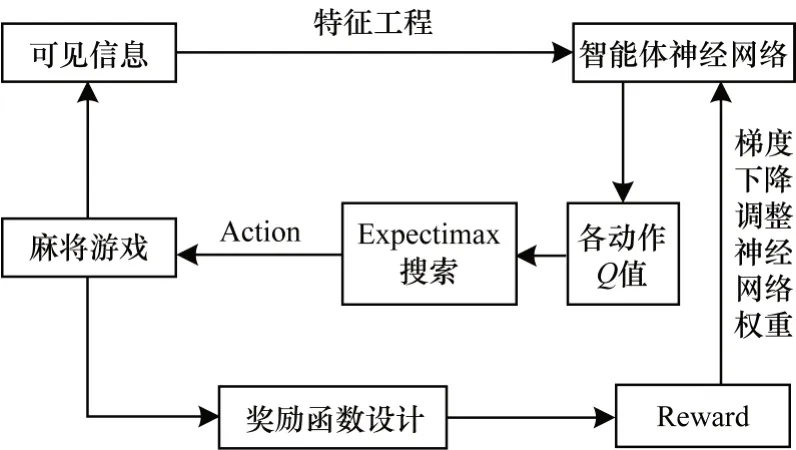
圖5 Double DQN 麻將模型的訓練過程Fig.5 Training procedure of Double DQN mahjong model
由于麻將游戲在結束時才能獲得獎勵分數,在游戲期間沒有任何獎勵,因此麻將是一種典型的獎勵稀疏游戲。為改變這一狀況,本文設計獎勵函數如下:

其中,VExpectimax為通過Expectimax 搜索算法計算得到的推薦動作效用值。在式(8)中,將游戲結束時實際得分設置為模型的獎勵,并將游戲中的獎勵設置為0.1×VExpectimax。
由上述可知,Expectimax 搜索算法使用Double DQN 神經網絡輸出的Q值來設計剪枝策略與評估函數。而在強化學習模型訓練過程中,使用Expectimax 搜索算法改進Double DQN 算法的探索策略與獎勵函數。在該過程中,Double DQN 算法和Expectimax 搜索算法相互結合與促進,進一步提高麻將模型的決策水平。
3 實驗與結果分析
3.1 數據描述和數據預處理
將本文算法與其他監督學習算法進行對比,并討論參數α的設置對模型的影響。實驗環境為:3.6.5 Python,1.6.0 tensorflow,GTX 108 顯卡,16 GB RAM 內存以及Ubuntu 16.04 系統。從某麻將游戲公司篩選大量高水平玩家的游戲數據(只篩選游戲得分排名前1 000 的玩家游戲記錄,且每位玩家至少已贏得500 場比賽)對監督學習算法的網絡模型進行訓練,共篩選出360 萬條游戲數據,按照數量比例3∶1∶1 將數據分為訓練集、測試集和驗證集,并根據表1 中特征編碼處理數據。值得注意的是,對于CNN、DenseNet 和ResNet 等具有卷積層結構的網絡模型,需采用填零的方式將特征轉換為19×19 的二維矩陣。
3.2 對比實驗
將本文提出的Expectimax搜索+Double DQN算法(以下稱為本文算法)與線性分類(Linear)、支持向量機(SVM)[29]、FC[30]、CNN、DenseNet-BC-190-40[31]、ResNet-1001[32]、DQN、Double DQN 以及Expectimax 搜索等算法進行對比。其中,DQN、Double DQN 和本文算法(以下稱為第1 類算法)均使用20 層的ResNet作為神經網絡。為便于比較,上述算法實驗參數設置相同,如表2 所示。

表2 第1 類算法的實驗參數設置Table 2 Experimental parameter setting of the first kind of algorithm
對于Linear、SVM、FC、CNN、DenseNet、ResNet-1001算法以及本文算法中的Expectimax搜索部分(第2類算法),相關參數設置如表3所示。其中,參數α采用多次實驗得到的最佳值(關于參數α設置的討論見3.3節)。

表3 第2 類算法的實驗參數設置Table 3 Experimental parameter setting of the second kind of algorithm
本文采用臺灣麻將游戲平臺進行實驗。與大部分麻將游戲不同,臺灣麻將在開局時,每位玩家持有16 張牌,且有花牌等特殊牌型。臺灣麻將贏牌的方式較簡單,只有平胡,但其得分計算較復雜,計算公式如下:
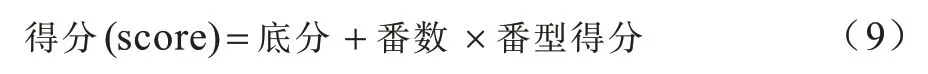
其中,底分與番型得分需要玩家在游戲開始前設置,番數取決于玩家最后贏牌時的牌型,例如清一色、四暗刻等。本文排除臺灣麻將中的花牌來簡化游戲流程,將底分和番型得分分別設置為1 000 和500,使用2對2 的形式進行3 000 場4 人臺灣麻將比賽。在對局中,采用兩個算法為基準算法,另外兩個算法為實驗算法,同時輪流交換不同玩家的相對位置以確保游戲的公平性。將不同實驗模型與基準模型進行對比來分析其優劣性。
本文實驗使用Expectimax搜索算法作為基準算法,上述不同算法的實驗結果如表4 所示。可以看出本文算法在對比實驗中表現最佳。對比ResNet-1001 和其他監督學習模型可知,隨著模型復雜度的提高,監督學習模型決策水平也相應提升。但是橫向比較后發現,監督學習算法不如強化學習算法和Expectimax 搜索算法,這是因為監督學習算法的網絡模型是通過收集用戶數據進行訓練,盡管已設置標準來篩選高水平玩家的游戲數據,但仍然無法保證數據質量,而強化學習算法和Expectimax 搜索算法的網絡模型無需用戶游戲數據進行訓練,可避免人類先驗知識造成的偏誤。
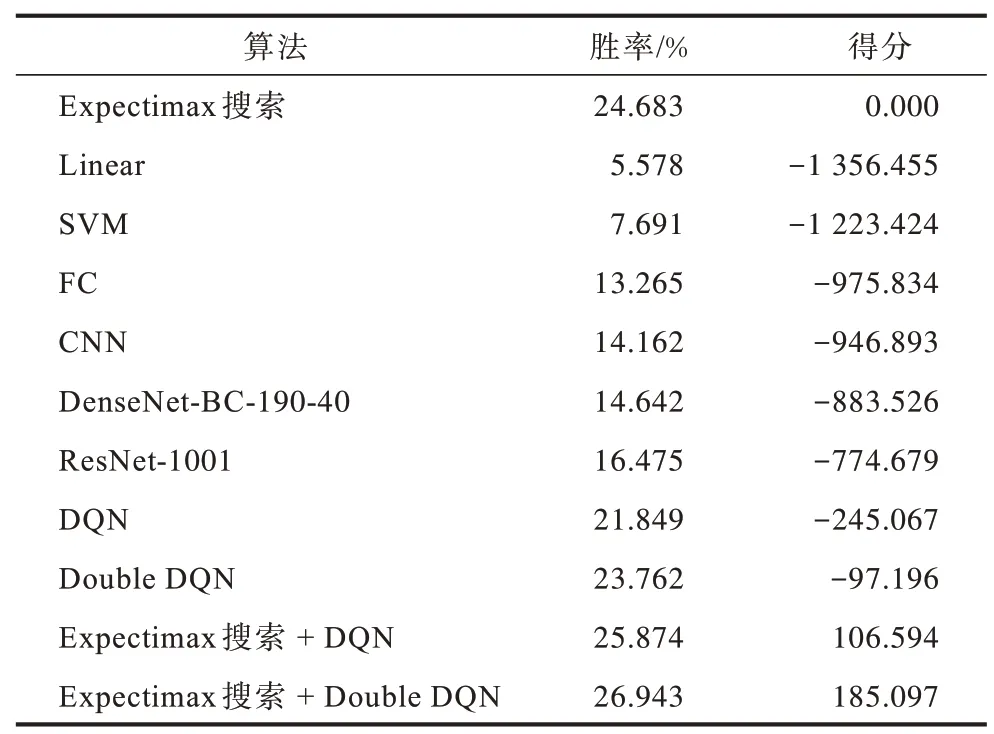
表4 不同算法的實驗結果Table 4 Experimental results of different algorithms
由表4 還可以看出:Double DQN 算法的性能優于DQN 算法,這是因為Double DQN 算法改善了DQN 算法的過估計問題;本文算法比Expectimax 搜索+DQN 算法的表現更好;本文算法的勝率比Expectimax 搜索算法高出2.26 個百分點,平均每局得分多185.097 分,這是因為本文算法將Expectimax搜索算法與強化學習算法Double DQN 相結合,在游戲訓練過程中不斷迭代優化,從而提高勝率和得分。
3.3 參數α 的設置對模型的影響
本文在3.1節提出根據k值對搜索樹進行剪枝的策略,由式(7)可知k值取決于參數α的設置。以下分別從耗時、勝率和得分討論參數α對本文算法的影響。
將參數α分別設置為0.2、0.4、0.6、0.8 和1.0,搜索樹限定層數分別設置為1 層和2 層,比較不同搜索層數下α值大小對本文算法的耗時、勝率和得分3 個方面的影響,結果如表5~表7 所示。
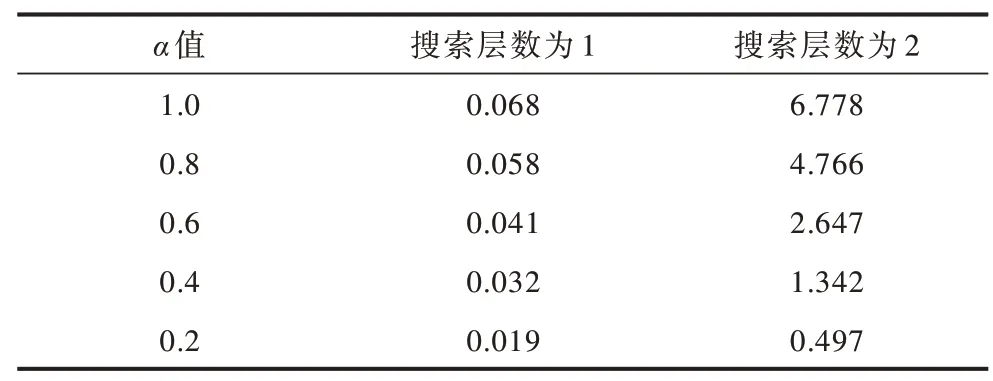
表5 參數α 對算法耗時的影響Table 5 Influence of parameter α on the time consumption of the algorithms

表6 參數α 對算法勝率的影響Table 6 Influence of parameter α on the winning rate of the algorithm%
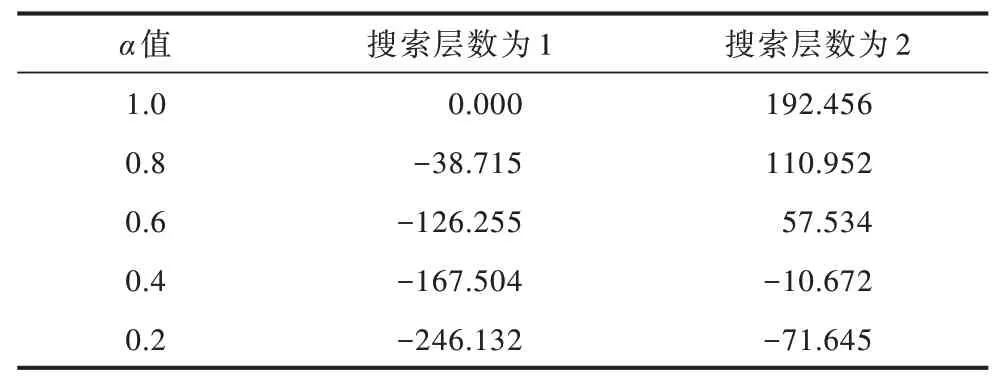
表7 參數α 對算法得分的影響Table 7 Influence of parameter α on the score of the algorithm
在表5 中,當參數α設置為1.0 時,相當于完全展開整個搜索樹,此時算法在搜索層數為1 和2 時決策時間分別為0.068 s 和6.778 s。可以看出,如果不修剪搜索樹,則決策時間會呈現指數級增長,因此,需要合理地對搜索樹進行剪枝從而減少算法耗時。由表5 還可以看出,隨著α值的減小,算法在不同搜索層數下決策時間不斷減少。由表6 和表7 可以看出,隨著搜索層數的增加,本文算法的勝率和得分相應增加,而結合表5 可知算法的耗時隨著搜索層數增加也在增長。因此,為使算法在3 s 內做出響應,本文算法選取α=0.6 且搜索層數為2。
4 結束語
麻將作為典型的非完備信息博弈游戲,主要通過Expectimax 搜索算法實現,而該算法中剪枝策略與估值函數基于人工先驗知識而設計,存在不合理的假設。本文提出一種結合Expectimax搜索與Double DQN 的非完備信息博弈算法。利用Double DQN 強化學習算法改進Expectimax 搜索樹的剪枝策略和估值函數,并通過Expectimax 搜索改進Double DQN 模型探索策略與獎勵函數。實驗結果表明,與Expectimax 搜索算法相比,該算法在麻將游戲上勝率提高2.26 個百分點,平均每局得分增加185.097 分。由于本文算法剪枝策略中參數α需借助人工先驗知識來選擇,因此后續將使用自適應方法進行改進,以提高算法的準確性。
猜你喜歡
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
中華手工(2017年2期)2017-06-06 23:00:31
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
初中生學習·低(2016年10期)2016-11-25 04:51:34
飛碟探索(2016年11期)2016-11-14 19:34:47
作文大王·笑話大王(2016年8期)2016-08-08 11:28:22
小學科學(2015年7期)2015-07-29 22:29:00
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
中外會展(2014年4期)2014-11-27 07:46:46
