基于深度學習的二維人體姿態估計研究進展
2021-03-18 08:03:00張建林徐智勇魏宇星
計算機工程 2021年3期
劉 勇,李 杰,張建林,徐智勇,魏宇星
(1.中國科學院大學電子電氣與通信工程學院,北京 100049;2.中國科學院光電技術研究所,成都 610209)
0 概述
二維人體姿態估計是計算機視覺領域的主要研究方向,在行為識別、姿態跟蹤等領域有著重要研究價值和應用前景,其本質是研究如何從給定圖像中精確識別目標人體并獲得目標人體姿態估計的問題,是姿態估計研究領域的重要分支。
二維人體姿態估計的研究方法可劃分為早期傳統的基于圖結構模型的方法以及目前主流的基于深度學習的方法。傳統的人體姿態方法通過圖模型建立人體姿態架構,參考人體運動學與人體姿態學等理論約束并優化人體姿態模型,但其需要根據樣本的具體情況來選擇姿態信息的特征描述子,如尺度不變特征描述子(Scale Invariant Feature Transform,SIFT)[1]以及方向梯度直方圖描述子(Histogram of Oriented Gradient,HOG)[2]。這些特征提取策略難以應對視角不同、外觀不同以及遮擋等情況的干擾。此外,人體可表達的姿態豐富程度使得其變化更為復雜多樣,這為相關姿態特征信息的提取造成了很大挑戰。傳統姿態估計方法可被視為一種基于圖結構優化后的代數求解問題,當人體姿態過于復雜時,針對同一樣本案例的圖結構優化將存在多組解,使得估計結果不再具有唯一性。
而卷積神經網絡(Convolutional Neural Network,CNN)[3]對二維圖像中的人體進行特征提取則可以獲得更為精確和穩定的卷積特征。多層卷積疊加可以控制特征感受野的信息感知范圍,從而獲得不同尺度下的特征信息。深度卷積神經網絡通過有策略地對樣本進行學習,可以獲得圖像與標簽信息間的復雜映射關系,提取更為豐富的關聯信息,使得相關人體姿態估計結果更為精準穩定。
目前基于深度學習方法的人體姿態估計算法普遍通過卷積神經網絡估計人體中各個特征關鍵點的種類和位置,對關鍵點按指定的策略進行關聯,獲得二維人體樣本目標的姿態估計結果。基于關鍵點和周圍局部特征間的關系、關鍵點間的空間約束關系和人體姿態結構關系,文獻[4]提出標準的人體姿態骨架模板,后續人體關鍵點的標注準則基本都是在此模板的基礎上進行合理的增刪。
本文對近十年來有關二維人體姿態估計在深度學習領域的相關工作進行整理分類,介紹相關人體姿態數據集基準,對相關思路方法進行對比分析,描述相關測評指標,總結該領域的研究現狀,并對二維人體姿態估計的發展趨勢進行展望。
1 相關數據集基準
由于研究早期資源的缺乏以及對人體姿態量化描述的差異,人體姿態數據集多集中于對單人局部姿態的標注,LSP[5]和FLIC[6]即為針對人體肢體姿態標注的數據集。隨著人體姿態估計課題逐步受到關注,更多研究機構陸續開始數據集基準的設計。數據集MPII[7]將人體關鍵點標注個數完善到16 個,作為訓練和評估單人姿態估計網絡的基準。該基準對人體姿態的量化描述逐步趨于統一完善,樣本數量初具規模,能支持全身范圍的單人姿態估計以及多人姿態估計的研究。
MSCOCO[8]是2014 年發布的用于深度學習的綜合性數據集。該數據集在2016 年對專門用于多人姿態估計的數據集進行完善,于2017 年發布人體關鍵點的標注并在隨后幾年對其進行相關維護。其將人體姿態的關鍵點標注增至17 個,并對每個人體樣本標注了分割掩膜,使得標注信息更加完備準確,無論是在單人還是多人姿態估計方面,其在當前研究領域皆被公認為是最可靠的基準指標之一。
AI Challenger[9]給出與MPII 標準相似的用于競賽的人體姿態數據集,其包含了海量的訓練測試圖像。Crowd Pose[10]從現有數據集中[7-9]共篩選出約20 000 張有關人體姿態研究的圖片,統一采用14 個關鍵點進行標注,作為擁擠場景下人體姿態數據集。
常用人體姿態數據集成分對比情況如圖1 所示,一方面數據集基準的擴充與完善推動研究方法的改進優化,另一方面研究方法的改進優化又對數據集基準提出更具體的要求,從而推動人體姿態估計研究的不斷發展。
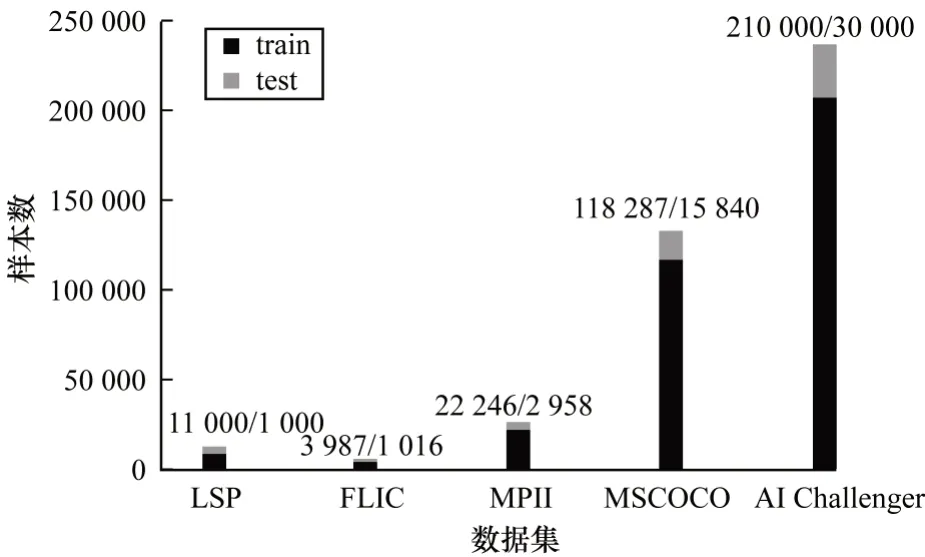
圖1 常用人體姿態數據集的成分對比Fig.1 Composition comparison of commonly used human posture datasets
2 二維人體姿態估計的深度學習方法
通過深層卷積網絡模型對樣本圖像進行特征提取,使得二維人體姿態估計方法可實現對人體的檢測和關鍵點的定位,最終對關鍵點進行聚類關聯,獲得人體姿態估計結果。其依據所給定的標注信息對模型的預測結果進行測評,并通過反傳誤差信息更新人體姿態估計網絡模型的參數,對人體姿態估計算法模型進行優化。基于深度學習的二維人體姿態估計方法按研究對象數目,將人體姿態估計問題劃分為單人姿態估計方法和多人姿態估計方法。
在單人姿態估計問題方面,多幅圖中同種類人體姿態關鍵點間的尺度差別通常較大,這種尺度差異性會對網絡特征提取模塊的設計造成一定的困難。因遮擋和不包含在圖片上等情況所造成的關鍵點遺失,會對姿態估計網絡的特征識別定位能力以及相關算法的后處理能力提出一定的要求,而且卷積神經網絡規模普遍較大,所導致的反向傳播梯度消失問題以及對姿態估計網絡架構的改進和輕量化等問題也需要相關解決措施。
而對于多人姿態估計而言,在單人姿態估計中所遇到的諸多問題會被復雜化。在一幅圖像中可以出現同種類但尺度差異懸殊的人體姿態關鍵點;不同人體之間的遮擋和重疊也會使相關網絡模塊與后處理算法對關鍵點的定位、所屬以及分類產生歧義;而且隨著圖像中人體樣本的增加,對卷積神經網絡的特征提取能力也進一步提高,由此產生的網絡參數規模擴大問題也難以避免。
針對以上問題,基于深度學習的二維人體姿態估計方法被分成單人姿態估計方法和多人姿態估計方法,如表1 與圖2 所示。單人姿態估計多是對網絡結構的設計和對輸出結果的后處理,優化網絡結構可以提高人體關鍵點特征的提取效率,豐富所提取到的特征內容,對輸出特征信息的后處理可以提高預測結果的信噪比,并結合先驗知識以及傳統機器學習方法獲得網絡難以學到的關聯信息。多人姿態估計按照對全局信息與局部信息執行順序的不同,主要分為自底而上(Bottom-up)與自頂而下(Top-down)兩種模式。自底而上的模式通過卷積網絡檢測并定位所有關鍵點,結合先驗知識對關鍵點進行聚類和匹配,從而獲得多人姿態估計結果。自頂而下的模式通過將多人目標檢測和單人姿態估計方法進行結合從而實現多人姿態估計。
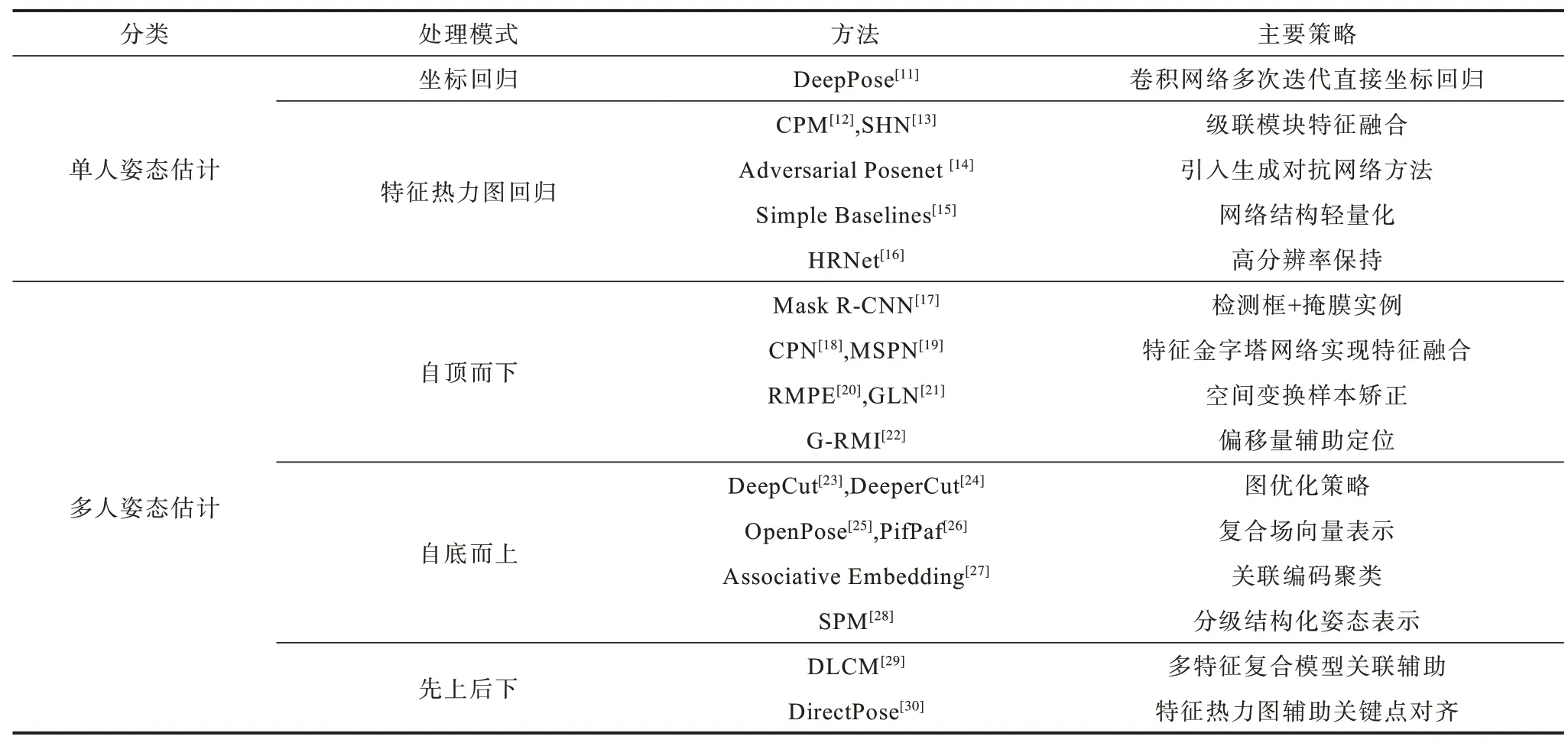
表1 二維人體姿態估計方法分類Table 1 Classification of two-dimensional human pose estimation methods

圖2 近十年基于深度學習的二維人體姿態估計研究發展時間線Fig.2 Research and development timeline two-dimensional human pose estimation based on deep learning in the past ten years
此外,最近相關研究提出一種將兩種模式相結合的多人姿態估計算法模式。由于該模式多數先以自底而上的模式提取所有的人體關鍵點獲得初步的姿態估計結果,再自頂而下地對人體關鍵點進行精確定位,因此將其稱為先上后下的多人姿態估計模式。
2.1 單人姿態估計
單人姿態估計的深度學習方法策略主要分為對網絡結構的設計與對輸出結果的處理。通常較深的卷積神經網絡結構設計,可以提取更具體更深層的特征信息來解決同種類關鍵點的多尺度分布問題,有利于提高姿態估計模型的魯棒性,單人姿態估計網絡結構的設計大都采用多階段的卷積網絡級聯架構;而針對如何對姿態關鍵點進行準確檢測和定位,對輸出結果的處理方法則可以分為以坐標回歸為主的方法和以特征熱力圖回歸為主的方法。其中,為了同時提高網絡對人體姿態圖像的局部特征和全局特征的提取,在特征熱力圖回歸方法的基礎上出現了許多有關多尺度特征的優化和多分辨率處理的方法。為避免網絡估計得到現實中不存在的問題,基于生成對抗網絡相關技術被應用于人體姿態估計方法。隨著級聯網絡架構研究的不斷加深,研究人員提出并改進減少人體姿態估計網絡參數規模的方法。
2.1.1 坐標回歸方法
坐標回歸方法通過多階段的卷積網絡級聯架構進行特征提取,在全連接神經網絡上直接進行坐標回歸,并進行多次迭代后得到姿態關鍵點的坐標估計結果。文獻[11]將多階段的卷積網絡級聯架構與人體姿態估計問題相結合,為人體姿態估計在特征提取方法上提出新的可能。文獻[31]是一種多階段卷積網絡級聯架構與馬爾科夫隨機場模型[40]相結合的單人姿態估計方法,多階段卷積網絡級聯架構所輸出的特征信息將被傳輸給馬爾科夫隨機場模型進行信息關聯處理,最終仍由全連接網絡對處理后的特征圖像信息直接回歸估計出坐標位置結果。
由于人體姿態信息紛繁復雜,僅靠直接坐標回歸的方法很難得到精確的人體姿態關鍵點。雖然直接對關鍵點坐標進行回歸求解的方法忽視了人體姿態關鍵點之間的特征關聯信息,使得算法模型的泛化性能較差,但其多組卷積網絡級聯的姿態估計架構能夠有效提取到豐富的人體姿態特征信息。這種以深度神經網絡作為人體姿態特征提取器的方法在隨后的相關研究中逐漸成為主流并衍生出多種經典的人體姿態估計網絡架構。
2.1.2 特征熱力圖回歸方法
為獲得特征信息更為豐富的特征響應輸出,網絡需要對輸入圖像在更大的特征范圍上進行特征提取,增大網絡的特征感受野[41]是一種有效策略。通常可通過擴大池化層、卷積核尺寸和增加卷積層的策略增大網絡的特征感受野。但是這些策略都有一定的缺陷:擴大池化層會導致原始特征信息損失,并對關鍵點定位的精度造成不可逆的影響;擴大卷積核尺寸則會使網絡參數成倍增加,影響網絡運行效率;而不斷增加卷積層則會導致網絡進行誤差反向傳播時的梯度消失問題。因此,在獲得較大特征感受野的基礎上盡量抑制其所產生的副作用是設計和改良人體姿態估計網絡架構所要攻克的技術難點,目前較為經典的設計方法有:基于VGGNet[42]的多層卷積池化的下采樣模塊,通過多尺度特征級聯的方式來彌補池化操作中的特征信息損失;基于ResNet[43]的殘差模塊結構,通過前饋連接策略保證反傳梯度,確保網絡層數持續加深。
以VGGNet為特征提取網絡架構基礎的卷積姿態機(Convocational Pose Machine,CPM)[12]構造了一個由多組卷積網絡模塊構成的級聯網絡架構。每組卷積模塊通過采用多次卷積操作與池化處理不斷擴張感受野尺度,提取獲得特征感受野更大的人體姿態特征響應結果,結合之前網絡模塊的輸出結果對特征圖像進行像素級別的特征信息融合,其卷積核參數以及各層對特征感受野的擴張效果如圖3 所示。
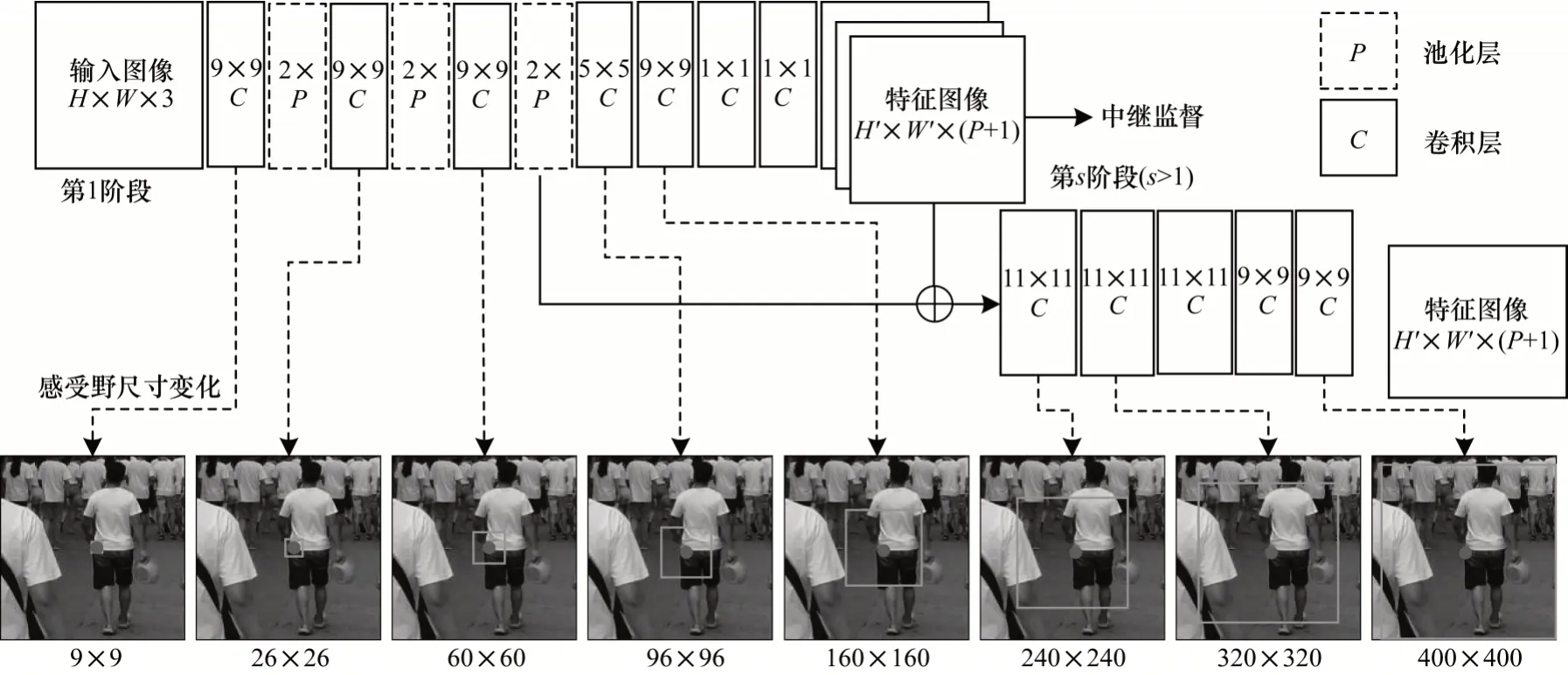
圖3 CPM 網絡模塊中感受野尺寸變化與多尺度特征融合Fig.3 Receptive field size change and multi-scale feature fusion in the CPM network module
然而,為擴大特征感受野進行設計的多階段級聯架構使得網絡過深。為防止誤差反向傳播時出現梯度消失,研究人員提出損失函數中繼監督策略,即對每一組的輸出計算損失函數,最終評判指標取決于各組累加的損失。基于空間的多尺度級聯卷積神經網絡架構,不再過分依賴于馬爾科夫模型空間的復雜聯系,一定程度上減少了算法復雜度。這種多尺度特征融合的思想被后續的相關研究所繼承。
級聯沙漏網絡(Stacked Hourglass Network,SHN)[13]采用以殘差模塊為單元的多段級聯式沙漏模型。其對U-Net[44]的網絡拓撲結構進行改進,設計出的四階沙漏模塊用于對圖像中的特征信息在各個尺度上進行充分提取。圖4 所示為各個階段的統一沙漏模塊結構,通過級聯多個殘差模塊來同時增加卷積層的深度以及卷積核的數量,不斷擴大感受野。在沙漏模塊的第四階段得到最低分辨率和最大感受野的特征圖像后,其仿照U-Net 的短連接(shortcut)策略,將模型前半部分的最終輸出對應等尺度地傳遞給模型的后半部分。后半部分在分辨率較低的特征圖像上采樣到對應尺度,并與相應的前端輸出在不改變特征通道數的前提下等尺度地進行疊加。然后再次通過相同的殘差模塊進行特征提取,形成與模型前半部分相對稱的沙漏結構。
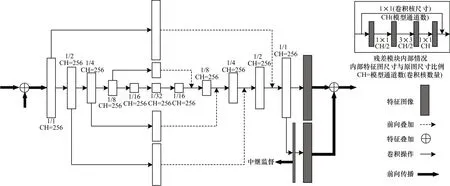
圖4 SHN 架構中的四階沙漏模塊Fig.4 Fourth-order hourglass module in SHN architecture
為防止網絡過深而造成的梯度消失問題,SHN同樣采用了中繼監督的訓練策略。各階段獲得相應的特征熱力圖后,在訓練過程中這些熱力圖響應結果將結合真實標注信息進一步獲得其在各位置的置信度,并與本階段網絡的輸入圖像和最終輸出圖像進行融合,作為下一階段的輸入特征。而在之后各階段的監督中也將進一步學習之前各階段所提取到的特征信息。沙漏網絡模型因其輸入輸出的等尺度結構極具可嵌入性,被后續諸多研究作為人體姿態特征提取器并加以優化和借鑒:其中基于沙漏模型提出的金字塔殘差模型(Pyramid Residual Module,PRM)[32]通過多個分支網絡下采樣獲取多尺度特征信息,并引入膨脹卷積替換池化過程所造成的信息丟失,使得因池化下采樣所損失的原始圖像特征信息能被加以利用。
簡易網絡架構基準(Simple Baselines)[15]對以上網絡架構進行了更簡易的改良。其前端采用ResNet進行特征提取,后端采用3 層尺寸為4×4 的轉置卷積核來還原網絡輸入分辨率,最終達成端到端的人體姿態估計效果。由于其在調參、數據增強等方面使用了諸多技巧,如其對最終估計結果結合了特征熱力圖的最大值點朝向次大值點方向的偏移量,使得其在網絡結構簡易的情況下依然能夠獲得很好的人體姿態估計結果。
2.1.3 多尺度與多特征融合的優化策略
人體姿態估計不僅需要結合高級語境特征,還需要結合具體而細致的低級特征。由于視角的不同以及關鍵點類別差異,卷積網絡對相同姿態關鍵點在不同尺度下的特征提取效果會打折扣,甚至出現錯誤的估計結果。文獻[33]采用多語境注意力機制將沙漏模型優化為沙漏殘差單元(Hourglass Residual Unit,HRU),使每個沙漏網絡階段均可輸出多尺度注意力映射圖像與多語義注意力的特征映射圖像,將整體注意力模型得到的全局個體和局部注意力模型得到的人體局部姿態進行組合,實現多尺度端到端的人體姿態估計網絡架構。多尺度結構感知(Multi-Scale Structure-Aware,MSSA)[35]網絡在沙漏模型的基礎上添加多尺度監督來加強語義特征學習融合多尺度的特征。此外,結構感知損失模塊可以提高關鍵點的匹配程度并獲得鄰近關鍵點間的關聯信息,對多尺度輸出進行優化調整提升了姿態關鍵點的全局一致性。
從特征熱力圖到坐標的轉換過程同樣也會產生量化誤差,因此,特征熱力圖到關鍵點坐標的解碼過程至關重要。分布式感知坐標的姿態估計方法(DARKPose)[39]將輸入人體姿態圖像進行下采樣以降低分辨率。為準確預測各關鍵點在原始圖像中的位置,在得到特征熱力圖的預測結果后,需要對分辨率進行恢復后再轉換回原始坐標空間。該方法能預測特征熱力圖的先驗分布結構,并推斷最大的潛在激活位置,從而獲得精準的坐標預測。
采用卷積或池化操作降低圖像分辨率來提高特征感受野范圍的方法通常在采樣過程中會產生量化誤差,以致級聯網絡會將量化誤差逐級傳遞,影響整體精度。高分辨率網絡(High-Resolution Network,HRNet)[16]給出一種保持高分辨率的新型多層網絡結構,以彌補原始圖像信息因為特征感受野的擴大而造成的損失。如圖5 所示,其在始終保持初始特征熱力圖分辨率的前提下,令不同層的級聯網絡在不同分辨率下對圖像進行特征提取。通過不同層間特征信息的融合來獲得更多的關聯信息與語義信息以及精確的人體關鍵點定位,體現了空間分辨率的重要性。文獻[45]對分辨率中高層獲得的特征熱力圖進行特征再提取,進一步增加模型的魯棒性和精確度。
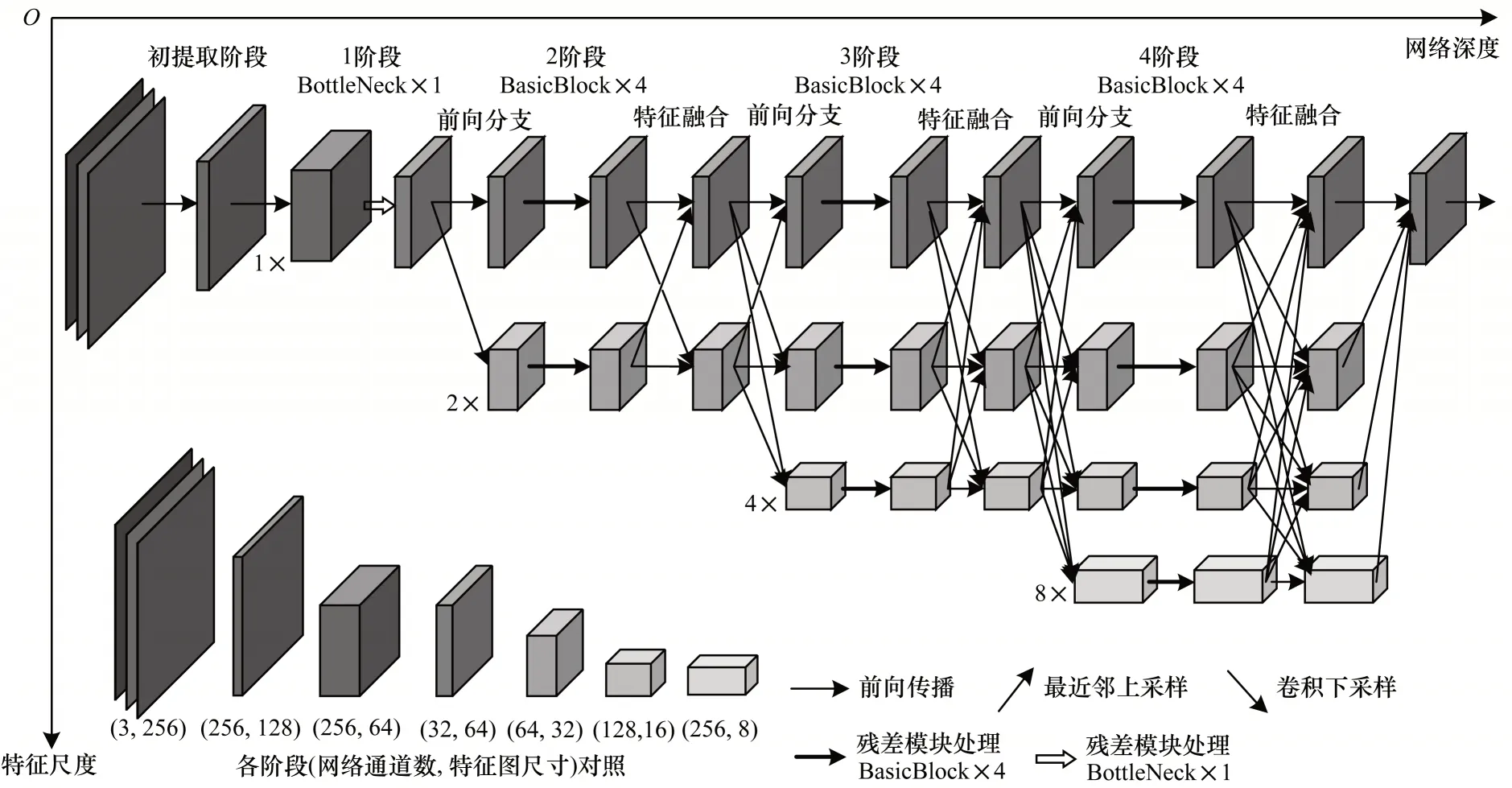
圖5 HRNet 網絡架構Fig.5 Architecture of HRNet network
2.1.4 生成對抗網絡方法與輕量化姿態網絡模型
由于人體部位的遮擋和重疊,在姿態估計中會產生許多虛假姿態結果。參考生成對抗網絡的思想,通過姿態發生器產生人體姿態結果,利用關鍵點間的幾何關系來加以約束設計鑒別器,便可判別人體的真實姿態和虛假姿態。生成姿態網絡[14]即采用了這一思路,在其基礎上進行改進的自對抗訓練方法[28]利用沙漏模型級聯網絡架構分別組建人體姿態生成器和姿態判別器。前者用于人體姿態的模擬生成與估計,后者則結合人體姿態樣本的真實結果對生成器的姿態估計結果進行判別,并將生成對抗誤差反傳回生成器,使生成器能通過學習獲得二維人體姿態結果。
優先選擇參數規模較小的網絡模型作為特征提取網絡架構是一種較為直接而有效的方法。空間短連接網絡(Spatial Shortcut Network,SSN)[37]以U-Net為基礎網絡架構,通過建立特征信息的遠程空間依賴關系提高了網絡的淺層探測能力。其對特征映射信息的處理主要分為用于特征移位的主模塊和預測特征間關系的特征移動模塊中,實現空間信息的低成本流動。網絡壓縮也可以實現姿態估計網絡架構的輕量化。快速人體姿態估計模型[38]將沙漏模塊的規模縮小一半獲得快速姿態蒸餾模型,然后采用知識蒸餾的策略使原生級聯沙漏網絡來引導學生網絡進行訓練,最終得到的輕量級模型幾乎不損失精度。
2.2 多人姿態估計
多人姿態估計方法的基本策略按照對全局信息與局部信息執行策略的順序不同被分成自頂而下和自底而上兩種模式,以及對兩種思想綜合利用的先上后下模式。
自頂而下的多人姿態估計模式借助已有多人目標檢測方法對圖像多個人體區域進行檢測和提取,之后再使用單人姿態估計方法對逐個人體檢測區域進行關鍵點的識別和估計。因為事先進行多人目標檢測的原因,采用自頂而下模式的多人姿態估計網絡所得到的結果很大程度上避免了多人姿態估計結果的歧義性,但由于其在檢測后還要進行多組單人姿態估計,且受限于多人目標檢測方法的時效性,采用自頂而下策略的多人姿態方法在實時性上仍尚需改進,其改進策略多針對目標檢測方法與姿態估計方法的匹配關系。
自底而上的多人姿態估計模式則是直接對圖像中所有人體姿態關鍵點進行檢測和定位,再結合姿態關鍵點之間的先驗關系,使用相關的算法對人體姿態關鍵點進行篩選以及相互匹配,最終實現對多個人體的姿態估計。雖然自底而上的模式對所有關鍵點采取一次性提取的措施可以極大地提升多人姿態估計方法的時間效率,但是在對多組不同點中間進行特征關鍵點匹配時,多個相同種類的關鍵點間會對算法匹配造成很大的干擾。因此,如何降低相同關鍵點之間的干擾,并對不同種類的姿態關鍵點進行最優匹配是對自底而上的多人姿態估計方法進行改進與優化的難點。
與自頂而下和自底而上的模式不同,先上后下的模式結合了當前兩種多人姿態估計模式的特點,先自底而上地對圖像進行各關鍵點的特征位置提取,再采用自頂而下的方法對各個人體姿態估計進行進一步的組合與定位。這種采用人體目標檢測與關鍵點提取對多人姿態聯合進行估計的策略,可以有效提升最終的定位精確度。因此,如何對兩者進行協調和結合是先上后下模式要解決的問題。
2.2.1 自頂而下方法
最初被用于多人姿態估計方法的多人目標檢測模型為faster R-CNN[47]。Mask R-CNN[17]在其基礎上進行檢測框回歸,并使用像素到像素對齊的方式對每個感興趣區域都增加一個像素級別的實例分割預測,在逐像素地獲得對應的二進制編碼掩膜后,便可對已有的目標檢測對象進行多人姿態估計。這種借助人體目標檢測與實例化分割的姿態估計策略保證了多人場景姿態估計的準確性,但對所檢測到的多個人體目標進行重復估計的方法占用了大量的空間資源,在追求高準確率與高精度的同時一定程度上犧牲了檢測效率。
Mask R-CNN 的特征提取網絡為增大特征感受野,而聚合空間特征信息所采用的降采樣操作會影響網絡輸出的特征響應熱力圖與輸入圖像之間的位置對應關系并造成量化誤差。同樣以faster R-CNN作為人體目標檢測器的G-RMI[22]人體姿態估計,則運用對關鍵點的坐標定位信息與坐標偏移量進行結合的人體姿態估計方法。其對特征熱力圖通過雙線性插值方法將關鍵點間的坐標短程偏移量(shortrange offset)與坐標定位信息以霍夫投票的形式進行高度化的特征局部激活。這種采用關鍵點位置響應與偏移量的聚合方法明顯改善了特征下采樣操作所導致的量化誤差問題。
針對多人姿態估計中因遮擋或重疊導致的實際關鍵點不可見等問題,級聯金字塔網絡(Cascaded Pyramid Network,CPN)[18]通過應對困難關鍵點的檢測定位進行優化處理。在利用多人目標檢測器獲得檢測邊界框后,使用級聯的特征金字塔網絡對人體檢測邊界框內的信息進行關鍵點檢測。如圖6 所示,CPN 被分成對邊界框中人體圖像信息關鍵點進行粗提取的特征金字塔全局網絡(GlobalNet),以及用于后續對不同層間關鍵點粗提取信息進行特征融合后再對關鍵點綜合精確定位的優化網絡(RefineNet)。對于特征可見的易分辨人體關鍵點可以通過GlobalNet 直接獲得,而對于因遮擋而不可見的或是因背景復雜而難以分辨的人體關鍵點,則需要通過RefineNet 進一步增大感受野來對GlobalNet定位誤差較大的關鍵點進行修正。
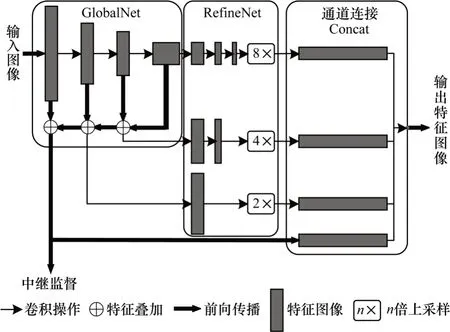
圖6 級聯金字塔網絡模塊Fig.6 Module of cascaded pyramid network
多階金字塔網絡(Multi-Stage Pyramid Networks,MSPN)[19]則是對GlobalNet 進行多級堆疊,得到的特征熱力圖金字塔融合了更多尺度特征,即通過加深網絡深度以擴大粗提取階段的特征感受野,并不斷進行多尺度特征融合對不同層間的特征信息加以關聯。層數較深的RefineNet 獲得的高層特征信息的感受野較大,可用來推斷不可見的困難關鍵點,而通過多組級聯后加深的GlobalNet 所提取到的低層特征信息,不是僅對各關鍵點進行粗提取,而是以其較高的分辨率以及較為豐富的多特征融合信息來精確地定位關鍵點。
然而級聯金字塔網絡只考慮采用不同尺度間的特征融合來提升網絡對困難關鍵點的檢測性能,并未對通道間的信息進行關聯融合。空間信息與增強通道(Enhanced Channel-Wise and Spatial Information,ECWSI)方法[48]以級聯金字塔網絡作為基礎網絡架構,為增強GlobalNet 各層之間特征圖像的跨通道關聯,其先用尺寸為1 的卷積核將每層提取的特征維度升至256,再對這些特征連接并使用通道隨機重組的操作進一步融合這些來自不同層級的特征,之后對融合后的特征信息依次進行分組并再次映射到原始的特征維度,最終再次使用尺寸為1 的卷積核對融合各層特征的信息進行聚合,獲得最終的表示結果。在學習空間位置特征的權重時,與級聯金字塔網絡對目標邊進行邊界框的特征粗提取方式不同,其利用通道特征隨機重組的方式對人體目標檢測結果的每個位置進行學習,最后的估計結果也較級聯金字塔網絡有所提高。
對于更為復雜的人群擁擠場景,由于人體之間的重疊密度過大,導致檢測器所獲得的定位區域內含有其他人體關鍵點的信息,且所檢測到的人體姿態不如單人姿態估計規范,從而出現傾斜或者大范圍區域不可見的情況。為此,區間多人姿態估計(Regional Multi-Person Estimation,RMPE)方法[20]選用SSD(Single Shot MultiBox Detector)[51]為檢測器,級聯沙漏模塊為姿態估計網絡架構,構成自頂而下的多人姿態估計模型AlphaPose。為解決多人關鍵點的匹配問題,其在獲得多人檢測結果后采取并行網絡,并采用空間變換網絡(Spatial Transform Network,STN)[50]進行正則化矯正以便獲得更精確的人體姿態估計結果。
同樣對人體目標檢測器輸出的人體檢測結果進行規范化處理,全局與局部規范化(Global and Local Normalization,GLN)[21]的優化思路并非先對整個人體姿態圖像進行空間信息規范化后再進行關鍵點檢測,而是先通過簡單的全卷積神經網絡對檢測到的各單人人體姿態圖像進行初步的關鍵點定位,然后對人體朝向、軀干與四肢采用白化處理的方法進行空間特征規范化處理,并再次使用全卷積神經網絡對各關鍵點進行定位上的微調,進而獲得精確的姿態估計結果。
2.2.2 自底而上方法
人體姿態關鍵點之間的連接可以被視為加權的圖模型,因此針對多人姿態估計問題,在通過特征提取網絡獲得所有的關鍵點響應之后,可以采用圖優化的方法完成各關鍵點間的匹配連接。文獻[23]構建一種DeepCut 的多人姿態估計網絡架構,其采用自適應的fast R-CNN,首先對人體關鍵點的局部候選區域進行初步的特征提取,所有被提取檢測獲得的候選點都將被視為節點,對提取到的所有候選點進行全連接,然后將屬于同一人的節點歸為一類,對所檢測的節點標記,確定其所屬關鍵點類別,通過對其連接權重采用整數線性規劃(Integer Linear Programming,ILP)進行求解,最終將對應的關鍵點聚類為人體姿態,但采用目標檢測器提取關鍵點策略和線性規劃的關鍵點連接優化策略的計算復雜度非常大,導致DeepCut 實際處理人體姿態估計問題的速度過低。文獻[24]對文獻[23]方法進行相應改進并提出DeeperCut 架構,其特征提取部分改用ResNet 進行關鍵候選點提取,采用圖像成對匹配策略,通過候選點之間的歐式距離進行判斷,將眾多相距過于接近的候選區域內的節點進行合并壓縮,減少了候選區節點的數量并有效提升了模型效率。
另外,采用目標檢測器進行關鍵點位置信息提取的還有姿態提名網絡(Pose Proposal Network,PPN)[34],其將YOLO(You Only Look Once)[51]與CPM 相結合,把姿態檢測定義為目標檢測問題。PPN 將一幅人體關系復雜的圖像分解為多幅相對簡單的多人圖像,分別生成多人關鍵點匹配關系,實現了對視頻圖像的實時多人姿態估計。但通常圖像中人的數量、位置和尺度大小都是未知的,人與人之間的交互遮擋會影響檢測效果,且運行時間隨著圖像中個體數量增加,很難做到實時檢測。
文獻[25]借鑒CPM 模塊,構建OpenPose 并聯網絡架構。首先運用VGG 網絡對圖像進行特征粗提取,以CPM 為基礎組成并聯網絡模塊,用以提取人體關鍵點位置特征與所定義關鍵點的連接特征。每組支路網絡分別進行6 次網絡級聯,獲得關鍵點定位信息的局部置信度圖(Part Confidence Maps,PCMs)以及關鍵點間關聯信息的局部親和域(Part Affinity Fields,PAFs)。然后根據候選關鍵點響應值與對應肢體連接向量采用匈牙利算法[52]進行多組最優二分圖匹配,選擇最小數量的邊來獲得人體姿態的骨架而非使用關鍵點的全連接圖,將匹配問題進一步分解為多組二分匹配子問題,并獨立確定相鄰部位節點的匹配關系,最終獲得所有人體姿態估計的結果。
為防止多階段級聯所造成網絡訓練中梯度誤差消失的情況,兩組支路都采取了中繼監督的策略,在各階段的每個分支結尾,分別對所獲得的關鍵點響應熱力圖和肢體連接關系響應圖按類別進行加權的歐氏距離誤差計算。此外,在進行下一階段的特征提取之前,各支路前一階段的輸出結果需要與最初的粗提取特征圖以及同一階段另一支路輸出的特征圖進行融合,豐富特征圖各尺度的信息。對于各關鍵點的PCMs 的標注采用高斯函數作為掩膜,遇到同時被兩個相同關鍵點影響的情況則采用具有較大響應值一方的策略;而對PAFs 標注的設置則采用向量表示方法,距離信息用來表示關鍵點間的關聯程度,角度信息則表示估計結果與真實結果間的匹配程度。
后續相關的研究[53]針對OpenPose 的特征提取網絡模塊進行調整優化,將原有的并聯結構改為先進行對局部關聯特征的提取,再結合原始粗提取特征進行關鍵點位置特征的提取。這種結構有效地減少了原始并聯網絡中的多次特征融合,且因為依舊采用中繼監督的策略,使得網絡由并聯到級聯的改動對于訓練時的誤差反向傳播并未造成較大的影響。隨著圖像中人數的增加,OpenPose 會隨著人數的增加而呈線性增長,進行級聯改進后的算法運行時間則隨著人數的增加基本保持不變。
為保證定位精度,文獻[36]提出PresonLab 方法,基于ResNet 對所有的人體姿態關鍵點進行特征提取以及偏移量預測,引入中程偏移量來應對實例間的特征關聯問題。文獻[26]則同時借鑒了OpenPose 中的PAFs 和描述關鍵點偏移信息的局部響應強度(PIFs)。通過PIFs 獲得類似偏移信息的全部候選點,并根據PAFs 獲得各候選點間的關聯信息,以高斯核函數代替G-RMI 中的雙線性插值方法,匹配獲得各人體的姿態估計,進一步提升關鍵點定位精度。
采用關鍵點偏移信息策略的單階段姿態模型(Single-stage Pose Model,SPM)[28]如圖7 所示。通過對級聯沙漏網絡進行改進,獲得結構化姿態表示模型并在此基礎上進行特征信息提取,輸出的關鍵點特征僅包含一個人體基準關鍵點的位置信息,該基準點分別指向其余各關鍵點的偏移量。為避免個別關鍵點偏離基準點過遠而造成模型難以收斂,模型輸出進行以下具體優化:采用關鍵點分級策略,在類別位置相鄰最近的關鍵點間通過偏移量建立位置依賴并相互牽制。最終按約束構建的多人姿態估計網絡因其關鍵點間形成多級制約提高了人體關鍵點的匹配準確度。
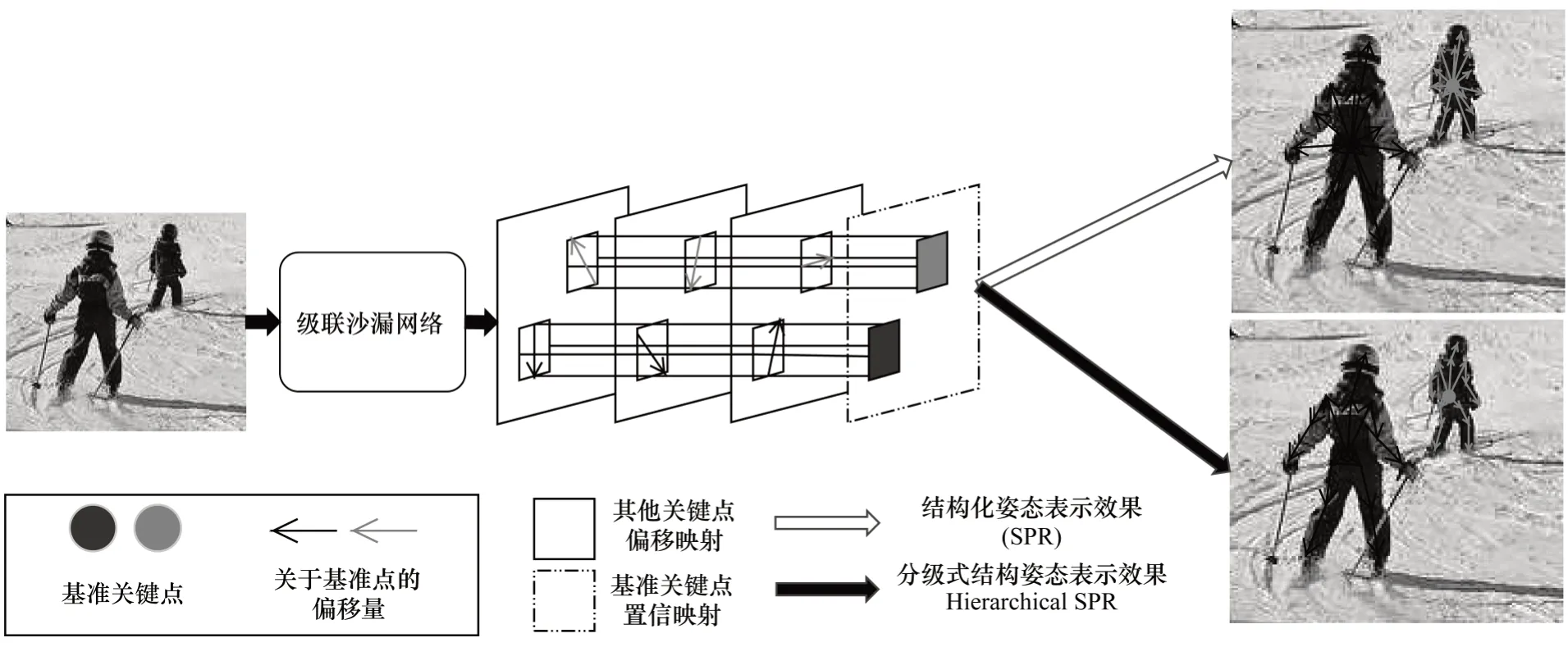
圖7 SPM 網絡架構Fig.7 Architecture of SPM network
除采用偏移量進行個人姿態范圍的約束外,運用類似分類網絡的編碼方式對同屬一個人體下的不同種類關鍵點進行聚類的方法,能夠有效解決多人姿態估計中的關鍵點匹配問題,如圖8 所示。關聯編碼方法[27]也是采用級聯沙漏網絡提取特征信息獲得各個部位的關鍵候選點,根據關聯信息嵌入方法,對各候選點都輸出一個嵌入式編碼標簽,使同屬一人的關鍵點的嵌入式標簽數值盡可能相近,不同人的盡可能不同,并將多人姿態估計問題轉化為對特定關鍵點的聚類問題。
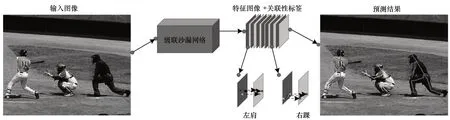
圖8 Associative Embedding 網絡架構Fig.8 Architecture of Associative Embedding network
2.2.3 先上后下方法
近年來,研究人員提出不依賴anchor-free 基準框的目標檢測理論并得到證實。不同于faster RCNN 等依賴anchor-based 目標基準框的目標檢測方法,anchor-free 利用對圖像特征點的定位信息實現目標檢測。對于人體姿態估計而言,人體的姿態關鍵點可被視為具有至少2 個邊緣點的特殊邊界框。因此,通過將姿態估計網絡的輸出附加到基于anchor-free 的目標檢測網絡,能夠更好地解決人體關鍵點定位任務,即先自底而上后自頂而下的姿態估計策略,DirectPose[30]是一種端到端的關鍵點檢測框架,如圖9 所示。該框架可以直接把輸入圖像映射到所對應的人體實例關鍵點上,既不依賴先驗的人體檢測框,也不需將檢測到的關鍵候選點進行分配,而是在目標檢測算法FCOS(Fully Convolutional One-Stage)[54]的基礎上添加關鍵點對齊模塊,將特征熱力圖響應與目標關鍵點對齊,然后采用直接坐標回歸的方法得到目標關鍵點的坐標,最終獲得姿態估計結果。DirectPose 不依賴自頂而下中先驗的人體目標檢測框,且與自底而上中啟發式地將檢測到的關鍵點匹配到對應的人體實例不同。該算法無需對特征響應圖進行預測而是直接對坐標進行回歸,這樣避免了使用特征響應圖所帶來的固有編解碼偏差。
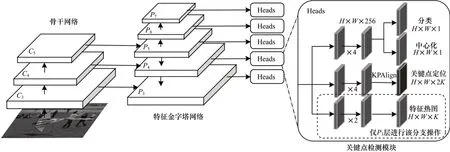
圖9 DirectPose 網絡架構Fig.9 Architecture of DirectPose network
為了盡量解決通用的姿態估計網絡結構因遮擋、人體之間接觸以及背景雜亂所導致的錯誤,進一步提高多人姿態估計的精度和效果,文獻[29]對級聯沙漏模型的姿態估計網絡模塊進行微調,并引入關鍵點組合方法,獲得先上后下的組合模型(Deeply Learned Compositional Model,DLCM)。模型對自底而上的模式進行調整,定義每個關鍵點為最低級部件,低級部件可以組合為高級部件,最終組合為一個個完整人體。首先對圖像進行低級部件的初步提取,再依次迭代估計高級部件的特征信息,在進行自頂而下過程中的低級部件的特征信息可以從高級部件信息中估計獲得,最終實現以高級部件為主的人體關鍵點關聯約束和以低級部件為主的關鍵點定位。
但是對低級部件組合為高級部件的行為不加以合理的約束會引發組合爆炸問題。DLCM 根據沙漏模型網絡的結構提出一個五階段的卷積網絡模型,前三階段進行自底而上的從低級部件到高級部件的特征復合,后兩個階段則是自頂而下地將獲得的高級部件特征還原為低級的關鍵點特征,同時進行基于各級部件的中繼監督。此外,在自頂而下的過程中,當前部件的特征圖像將結合自底而上所生成的同級部件的特征圖像后再進行下一階段的特征還原。自底而上的改進過程有效地解決了關鍵點的誤匹配問題,且在中繼監督中采用了類似OpenPose 中包含方向、尺度等信息的特征響應熱力圖,其在應對因遮擋等干擾情況時使得模型的姿態估計結果魯棒性更強。
3 相關研究方法對比與總結
縱觀二維人體姿態估計在深度學習領域從單人姿態估計到多人姿態估計的發展情況,在轉向多人姿態估計研究進程中,其分化成自頂而下與自底而上兩大主流模式。前者推動了目標檢測領域的發展,后者則推動新的匹配策略的出現,而兩者結合又產生了先上后下的新姿態估計模式。
從改良人體姿態估計的方式來區分,又可分為對姿態估計網絡架構的改進與對網絡輸出特征的處理策略的設計。前者主要針對網絡拓撲結構的改進,致力于尋找最優的網絡結構,不斷挖掘神經網絡可發揮的潛能;后者則更加關注網絡的輸出表示,突破固有框架尋找能進一步提升性能的經驗和技巧,而損失函數的選取也會影響到網絡的收斂性能。
3.1 網絡架構設計
如表2 所示,二維人體姿態估計方法按姿態估計網絡架構可分為以CPM 為主的多階段級聯式結構、以SHN 為主的沙漏模塊級聯式結構、以CPN 為主的兩段式結構和以HRNet 為主的多分辨并聯結構。
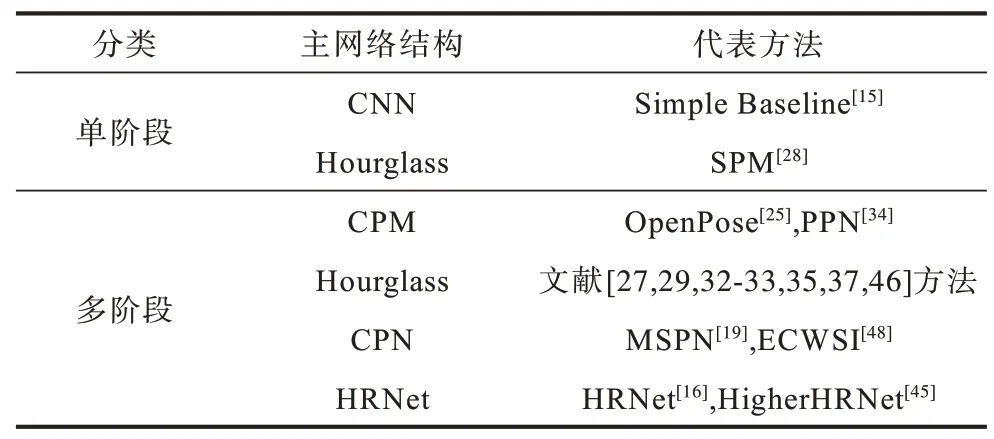
表2 經典人體姿態估計網絡架構對比Table 2 Comparison of canonical human pose estimation network architectures
CPM 衍生出諸如OpenPose 多人姿態估計的經典方法,構建了多階段級聯姿態估計網絡架構,PPN則將其與YOLO 相結合實現對高幀頻視頻的多人姿態估計。而有關沙漏模型的拓展研究則更多,無論是自頂而下模式中的單人姿態網絡,還是自底而上模式中的主題網絡架構,或是用于知識蒸餾中的教師網絡,除性能優良外,其優美的設計結構也獲得業界的承認,類似情況還有目標檢測領域的YOLO 和語義分割領域的U-Net。
CPN 特征金字塔架構的兩段網絡結構分別對應自頂而下模式中的目標檢測和姿態估計,如MSPN和ECWSI,前者是將前端的特征提取結構GlobalNet進行多階段堆疊,提高了檢測精度,后者則在CPN 上添加注意力機制模塊,實現了多尺度特征融合的均衡化。而HRNet 的多分辨網絡并聯結構則避免了之前網絡結構中頻繁使用采樣和池化導致尺度信息改變而造成的量化誤差。
3.2 特征處理的輸出表示
如表3 所示,人體姿態估計方法可按輸出結果分為坐標回歸輸出表示、特征熱力圖輸出表示和特征熱力圖及其他信息的輸出表示。
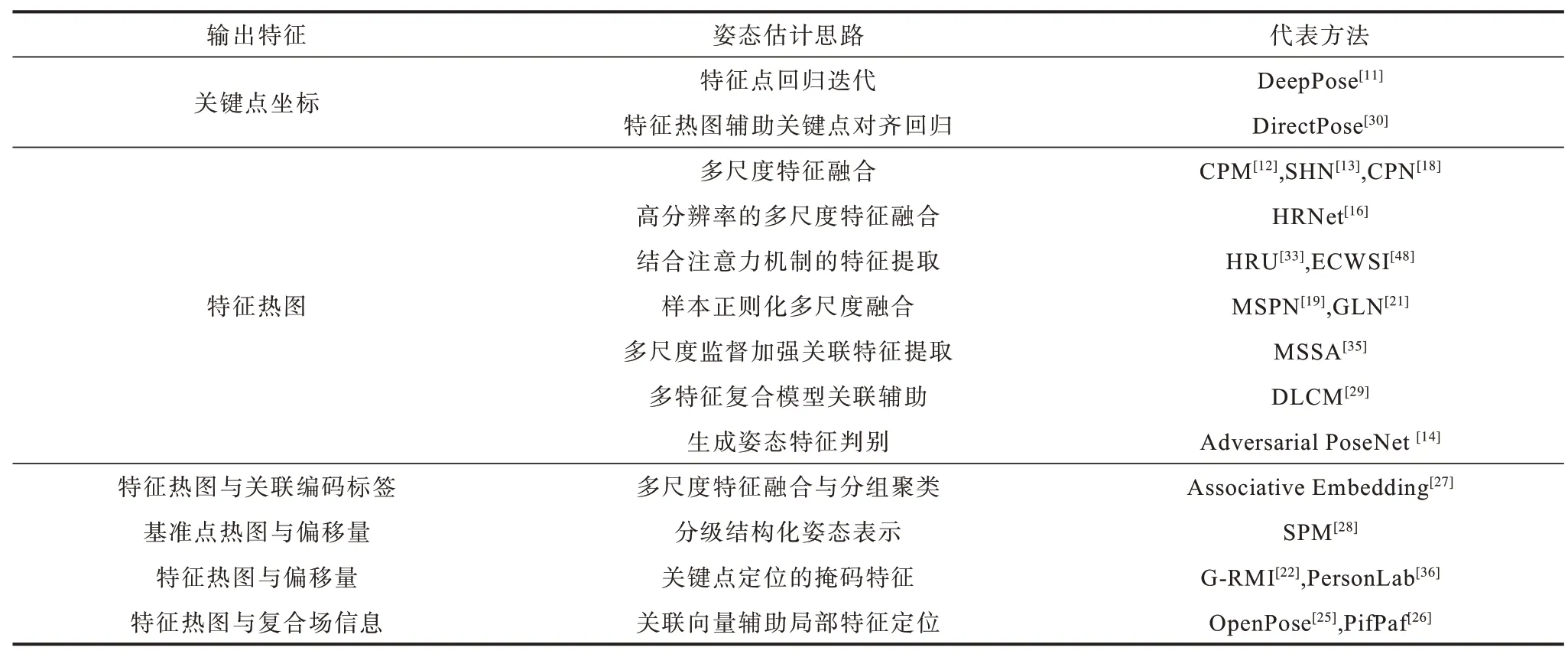
表3 人體姿態估計輸出特征對比Table 3 Comparison of human pose estimation output features
直接坐標回歸輸出表示是最直觀的一種思路,最初將深度學習方法用于人體姿態估計的DeepPose 便是使網絡通過有監督的訓練回歸獲得關鍵點坐標。但由于直接訓練所得的關鍵點回歸網絡其泛化能力較差,直到DirectPose 在坐標回歸方法中引入關鍵點對齊機制前,特征熱力圖的表示方式才逐漸占據主流。CPM 將多階段特征熱力圖通過融合獲得各關鍵點的特征熱圖。其后的沙漏模塊、CPN 等網絡結構均采取相同的方法。在評估損失時其對估計結果保證了一定柔性,使得網絡的泛化性能提高。
而在特征熱力圖的基礎上同時生成向量場嵌入信息則需要在一定程度上擴大網絡結構,OpenPose和PifPaf 中的PAFs 便是通過多階段神經網絡提取出各關鍵點間關系向量,類似的還有生成人體關聯編碼標簽的Associative Embedding 方法。
姿態網絡基本以人體的各個關節點特征提取為主,DLCM 將姿態估計網絡提取到的粗略關鍵點估計結果進行多次迭代提取高階部件信息,通過部件關聯輔助其所有關鍵點的定位。SPM 是獲得各人體的基準關鍵點和基準點與其他關鍵點的偏移信息來表示人體姿態,而G-RMI 則是引入偏移信息來輔助關鍵點進行精確定位。
3.3 損失函數選取
損失函數用于評估預測值與真實值之間的差異,能對模型進行有效的指導。二維人體姿態估計損失函數的裁定與設計需要參考姿態估計方法所采用的網絡結構和預測結果,如表4 所示。
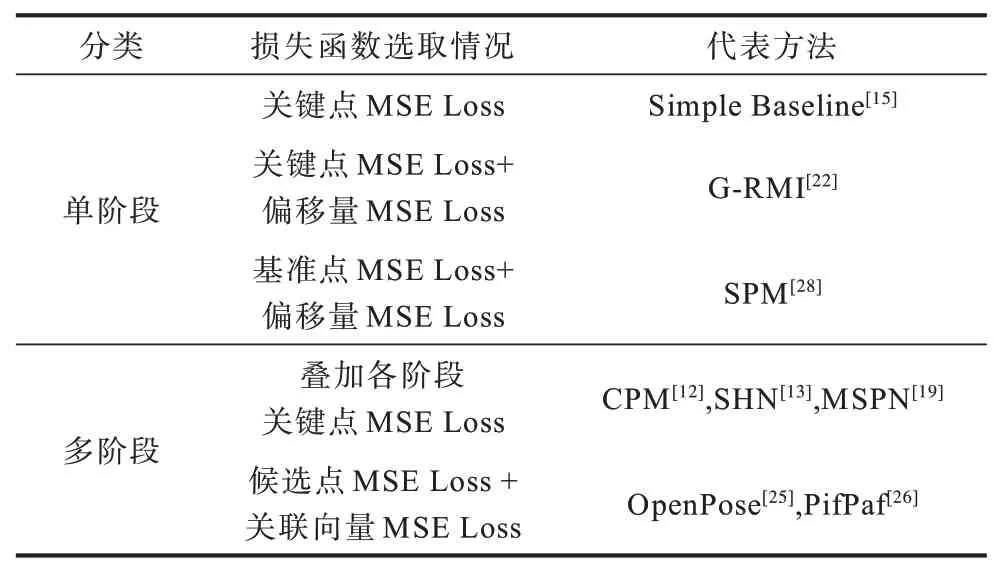
表4 不同策略中損失函數的選取Table 4 Selection of loss function in different strategies
人體姿態估計方法按網絡結構大致可分為單階段與多階段。其中單階段結構的損失函數僅需對網絡最終輸出計算一次便可評估模型,而多階段由于網絡的不斷加深,若僅對網絡最終結果的輸出計算損失,則因網絡過深導致的梯度消失問題會使網絡參數更新停滯。而在各網絡階段添加合適的損失函數可有效緩解該問題,即引入損失函數對網絡的中繼監督策略。多階段結構姿態估計的中繼監督損失函數計算如式(1)所示:
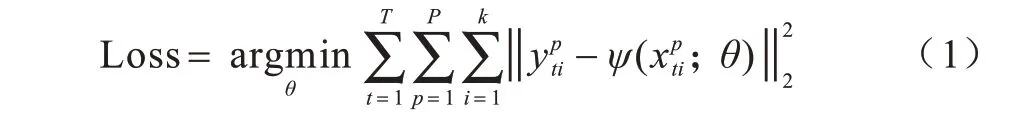
其中,k是關鍵點種類數,P是預測候選點數,T是網絡結構階段數,y為網絡輸入樣本x的真實標簽,ψ(·)為網絡模型,θ為模型相關參數。
姿態估計方法按輸出預測結果可分為回歸坐標方式、回歸特征熱力圖方式和回歸特征熱力圖及其他信息的方式。回歸模型的損失函數以均方誤差函數為主,而坐標和特征熱力圖在本質上輸出的是關鍵點位置信息,當正負樣本信息均衡時,誤差信息一般多以L2 范數的形式表示。
此外,在線困難關鍵點挖掘[55]是針對樣本中的困難關鍵點進行監督而不再是所有的關鍵點,其在CPN 等網絡的訓練過程中均被采用。Focal Loss[56]則是為了解決數據集中正負樣本比例嚴重失衡的問題,其主要是在針對擁擠人群情況下被采用。
4 評測標準
早期數據集LSP 和FLIC 主要是對部分肢體關鍵點進行標注,故而最早的度量評價指標PCP(Percentage of Correctly estimated body Parts)[57]是依據肢體的標注長度進行,如式(2)所示:
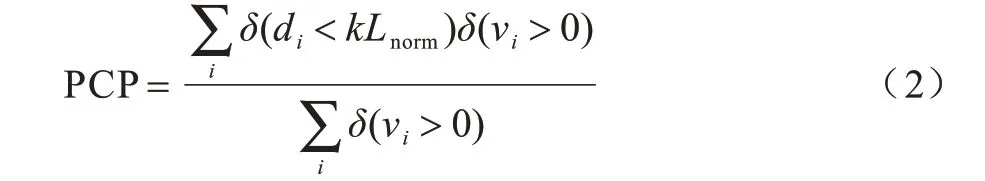
如果關鍵點i的預測位置與真實位置間的歐式距離di小于標準肢體長度Lnorm的一定比例k(通常為0.5),則判定預測準確(通常表示為PCP@0.5)。PCP用以劃定肢體關鍵點檢測的閾值,值越高,模型對關鍵點的定位效果越好。由此改進的PDJ(Percentage of Detected Joints)規定,關鍵點的預測位置與真實位置間的距離小于軀干對角點的長度Ldiag的一定比例,則判定預測準確。
MPII定義的PCK(Percentage of Correct Keypoints)規定,將關鍵點的預測位置與真實位置間的距離小于頭部長度Lhead作為歸一化參考,稱為PCKh,如式(3)所示:
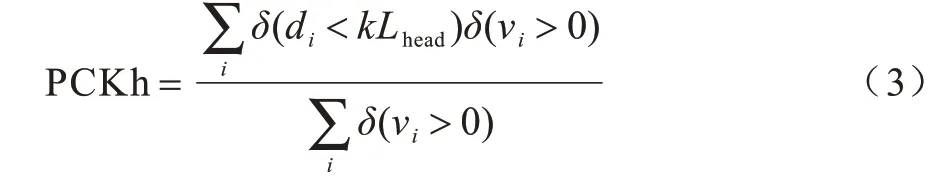
隨著多人姿態數據集的普及,尤其是MSCOCO發布后,一系列以固定閾值作為判定依據的評測標準不再適用于對同一幅圖中的人體尺度差異較大的情況。因此,MSCOCO 設計了測評標準目標關鍵點相似度(Object Keypoint Similarity,OKS),其定義如式(4)所示:
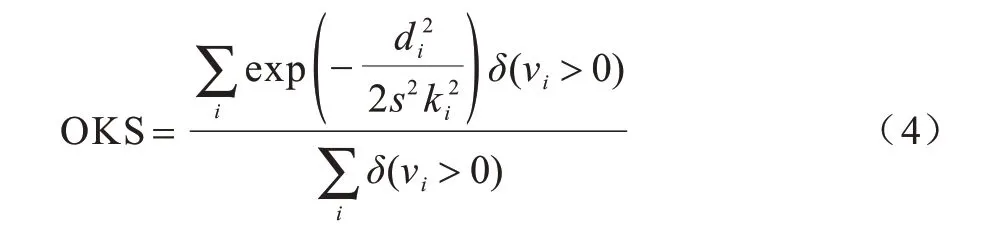
其中,di是關鍵點檢測位置與標注位置之間的歐式距離,vi>0 代表關鍵點i在圖上被標注,s是尺度參數,ki是控制各關鍵點響應衰減程度的超參數。
按照不同尺度對人體目標中各類關鍵點進行高斯分布,分別定義標準化的閾值評測標準并設計目標關鍵點相似度,使用不同的精度閾值來補償關鍵點的定位信息。
上述兩種有關人體姿態估計的評測標準都針對關鍵點的歐式距離誤差,其中PCK 更注重建立固定的歸一化閾值標準,而OKS 對不同尺度目標的相同關鍵點進行歸一化處理。表5 和表6 為不同人體姿態估計方法在相關數據集上的測評結果,其中,“—”表示沒有官方數據。
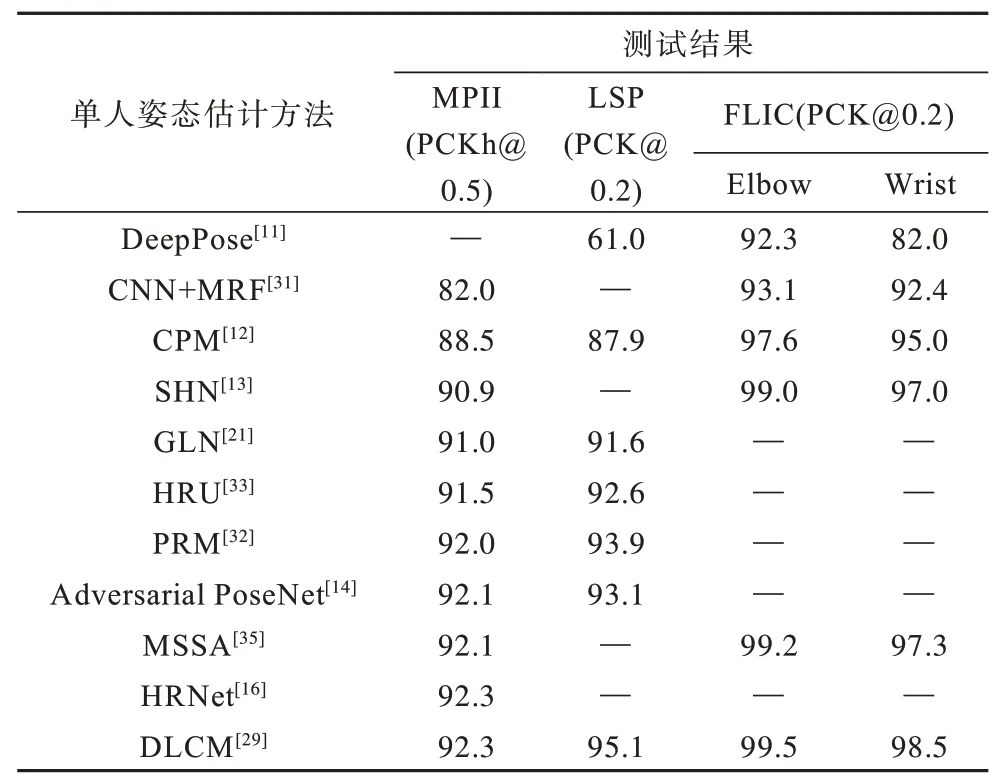
表5 單人姿態估計方法在LSP、FLIC 和MPII 數據集上的測試結果Table 5 The test result of single-human pose estimation method on LSP,FLIC and MPII dataset %
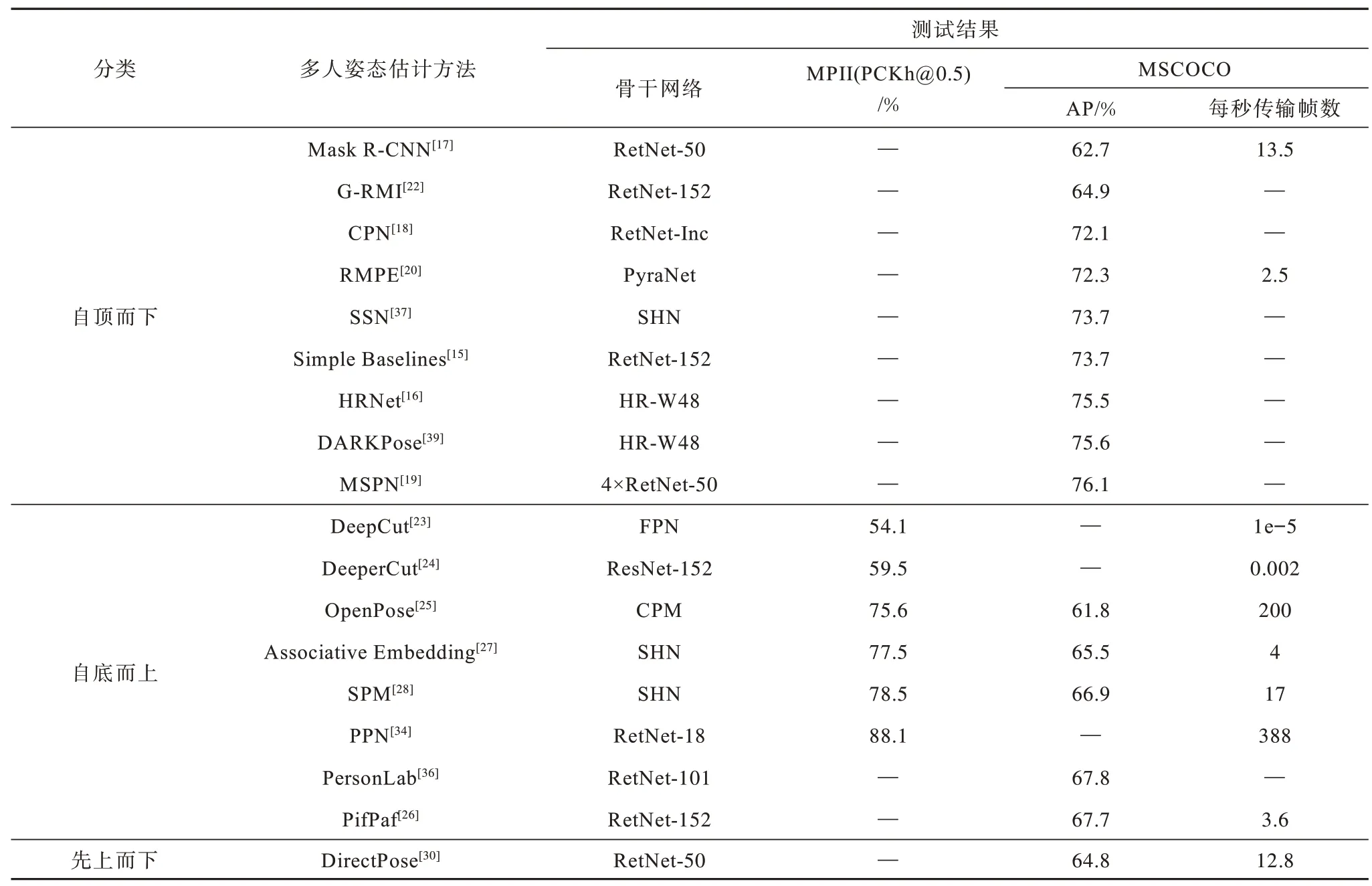
表6 多人姿態估計方法在MPII 和MSCOCO 數據集上的測試結果Table 6 The test result of multi-human pose estimation method on MPII and MSCOCO dataset
5 發展與展望
近年來隨著深度學習的發展,國內外有關安防監控、醫療康復、自動駕駛等應用技術得到廣泛應用,一方面推動了二維人體姿態估計在深度學習領域的創新,另一方面對算法的計算效能和結果的預測精度提出了更高的要求[58]。
1)網絡模型優化
有關人體姿態估計相關算法的網絡模型的優化將是未來關于該主題下實現更少模型參數的研究方向。原有的網絡架構將隨著模型壓縮,如量化剪枝、知識蒸餾等技術的應用而得到改善[59],隨著NAS(Neural Architecture Search)[60]的提出,以先驗知識結合神經網絡結構搜索的技術將使設計架構更加自動便利。
2)算法策略創新
遵循自頂而下模式的人體姿態估計方法由于過于依賴人體目標檢測器的性能和效率,其時效性略遜于自底而上模式下的人體姿態估計方法。而諸如OpenPose 和PifPaf 引入復合場概念,其設計思路更具可解釋性,故而更符合與卷積神經網絡相結合。在高維向量基礎上預測人體姿態,設計保持期望一致性的關聯得分公式,再加之有效的匹配策略,將能夠彌補自底而上模式中人體姿態估計精度較低的不足,進而提升實時的高精度人體姿態估計效果。
3)三維姿態估計
基于深度學習的二維人體姿態估計的研究是許多三維人體姿態估計研究的鋪墊,其中的人體關鍵點定位技術也是三維人體重建的必備技術。而且目前部分三維人體姿態估計依然借鑒了二維人體姿態估計的網絡架構及研究思想,如文獻[61]中的網絡架構就是基于級聯沙漏網絡進行的改進。
4)無監督訓練
近年來采用無監督的方式處理二維人體姿態問題[62]的方法隨著相關技術的發展成為一種新趨勢。因為人體姿態可以看成圖像中的特征簇,其視覺連通性具備高維空間獨立性。若加上光流等輔助信息,則可以通過大量無標簽的圖像構建人體部件的特征、部件到整體的特征以及人體運動的時序特征,這將是一種解決人體姿態估計任務的新方案。
5)剛體姿態估計
基于深度神經網絡的二維圖像人體姿態估計,要求網絡所學到的人體姿態應滿足模型的幾何約束,其本質上是一個對高維特征空間的非線性流形學習過程。深度神經網絡是一個代數計算系統,既然可以獲取諸如人體關鍵點的內部關聯以及高階耦合的幾何特征等人體復雜信息,那么對于一些特定剛體部件的關鍵點定位與姿態估計也將在相應網絡與算法中實現。而海量的剛體姿態處理需求則能夠推動姿態估計相關研究的發展與革新。
6 結束語
基于深度學習的二維人體姿態估計通過深度卷積神經網絡獲得姿態關鍵點局部特征信息,并根據具體情況選擇合適的關鍵點特征處理策略進行相應的特征聚合與特征匹配,實現對人體特征關鍵點的定位與姿態估計。本文對基于深度學習的二維人體姿態估計研究進展進行綜述,分類與評估相關姿態估計方法,并從網絡架構設計、輸出特征處理以及損失函數選取方面進行比較與分析。分析結果表明,卷積神經網絡提取到的人體姿態特征對于局部定位具有很高的預測精度,結合多尺度特征融合方法并在訓練過程中引入中繼監督策略能夠增加對人體姿態估計結果的整體預測精度,進一步提升模型的魯棒性。多人姿態估計通過構建合適的特征提取模型與相應的特征分配方法,對定位精度與估計效率進行權衡,而在對多尺度姿態特征的提取保持高精準度的同時,穩步提升姿態估計的檢測效率成為基于深度學習的二維人體姿態估計在后續研究中的主要發展方向,而網絡模型優化、無監督學習的研究發展也將對二維人體姿態估計從實驗研究到應用實現起到重要的推動作用。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年2期)2014-11-12 13:00:16
語文知識(2014年7期)2014-02-28 22:00:26
河南科技(2014年23期)2014-02-27 14:19:15
