基于優勢演員-評論家算法的強化自動摘要模型
2021-03-18 13:45:10
計算機應用 2021年3期
(華東理工大學信息科學與工程學院,上海 200237)
0 引言
互聯網上的信息量正以指數級的速度增長,如何從海量的文本信息中準確、快速地獲取有用信息,是當今人們最迫切的需求[1]。文本自動摘要技術對給定源文本信息進行概括與總結,并產生簡潔、流暢且保留關鍵信息的短文本,這不僅可以緩解搜索引擎檢索導致的冗余問題,而且可以有效解決信息過載的缺陷[2]。
文本自動摘要可分為抽取式方法(Extractive)和生成式方法(Abstractive)。抽取式方法抽取源文本關鍵句組成摘要,如TextRank 算法[3]將句子作為節點,用相鄰邊的權重大小表示節點的語義相似度,選取得分最高的k個節點作為摘要。生成式方法是近年來流行的方法,在理解原文的基礎上,逐詞生成摘要,可得到語義更精確的摘要,通常可用機器學習或深度學習實現,如基于注意力機制的序列到序列(sequence to sequence,seq2seq)模型[4]、利用卷積神經網絡(Convolutional Neural Network,CNN)對源文本編解碼,并引入注意力機制,在DUC數據集上取得了不錯的效果。
目前,研究者們深入研究了自動文本摘要領域,提出了許多新穎的模型。Sharma 等[5]提出實體驅動的生成式摘要模型(System for ENtity-drivEn Coherent Abstractive summarization model,SENECA),利用實體信息產生包含有用信息的連貫摘要。Zhang 等[6]提出通過抽取空缺句的預訓練生成式摘要模型(Pre-training with Extracted GAp-Sentences for abstractive Summarization model,PEGASUS),利用新的預訓練目標(Gap Sentences Generation,GSG)用于摘要總結、空缺句子生成,在所有12 個下游數據集上都達到了最先進的性能。Saito 等[7]提出具有重要標記的條件摘要模型(Conditional summarization model with Important Tokens,CIT),該模型將顯著性模型提取的標記序列顯式地提供給seq2seq 模型作為附加輸入文本。
然而,針對長文本的自動摘要,若采用生成式方法,解碼時間較長,摘要不準確,其原因是過長的源文本導致編碼器不能準確提取輸入文本的語義信息,且生成過程缺少關鍵信息的指導。如文獻[8]的生成式摘要方法采用強化學習框架,輸入整篇文檔,生成的摘要不反映文章核心內容,摘要無法達到與源文本內容等價的效果。若采用抽取式方法,抽取原文中整句作為摘要,其包含較多非摘要內容,得到的摘要信息冗長、不夠精簡且摘要句間不連貫。
針對上述問題,長文本自動摘要可先抽取源文本關鍵句,再用生成式方法重寫摘要,以解決摘要的冗余與連貫問題。生成式方法依靠抽取的結果,因此抽取結果的好壞直接影響最后摘要的質量。如果抽取得不好,甚至抽取錯誤將導致摘要不準確、偏離文章中心。對于該問題,本文提出了面向長文本的基于優勢演員-評論家算法[9]的強化自動摘要模型(Reinforced Automatic Summarization model based on Advantage Actor-Critic algorithm,A2C-RLAS),在強化學習框架下用A2C 算法的多次迭代來改進抽取過程,其中用BERTScore(evaluating text generation with Bidirectional Encoder Representations from Transformers)[10]得分較好地評價重寫摘要和參考摘要的語義相似性,反饋抽取質量的改善效果。在CNN/Daily Mail[11]數據集上的實驗結果表明,與基于強化學習的抽取式摘要(Reinforcement learning-based extractive summarization,Refresh)模型、基于循環神經網絡的抽取式摘要序列模型(a Recurrent Neural Network based sequence model for extractive Summarization,SummaRuNNer)和分布語義獎勵(Distributional Semantics Reward,DSR)模型等相比,A2CRLAS 模型在ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[12]和BERTScore 指標上均有提升,其中相較于Refresh 模型和SummaRuNNer 模型,A2C-RLAS 模型的ROUGE-L 值分別提高了6.3%和10.2%;相較于DSR 模型,A2C-RLAS 模型的F1值提高了30.5%。本文模型摘要語義也更加豐富、語言也更加簡潔流暢。
1 問題描述
在長文本自動摘要中,已有的抽取式方法抽取原文句子組成摘要,摘要的長度往往是參考摘要長度的幾倍,例如基于encoder-decoder 的抽取式模型Refresh[13]對數據集CNN/Daily Mail 中測試集樣本進行抽取,結果如表1,參考摘要往往比抽取摘要短,平均每句參考摘要13.5 個詞,平均每句抽取摘要27.8 個詞,平均抽取摘要句的長度是平均參考摘要句長度的2 倍多,表明直接抽取整句作為摘要的方法將導致摘要信息冗長、不夠精簡。
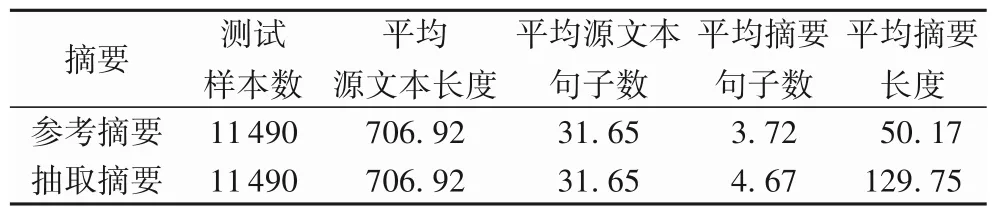
表1 摘要的統計Tab.1 Summary statistics
例1 為該模型抽取的摘要樣例,其中抽取摘要包含的關鍵信息用下劃線標出,抽取摘要包含10 個短句,參考摘要僅包含2 個短句,抽取摘要的長度是參考摘要長度的3~4 倍,而且抽取摘要中同一人名重復出現,句間不夠連貫。因此摘要不應該僅來自于抽取,要得到精煉、簡潔和流暢的摘要需要進一步重寫。
例1
參考摘要:ben powers joined the cast of“good times”for its sixth and final season.he played thelma ' s husband keith anderson.
抽取摘要:ben powers joined the cast of“good times”for its sixth and final season from 1978 to 1979 season,playing keith,a professional football player .his character and thelma are wed on the third episode that year,but he injures his leg while walking out of the church,straining their relationship .ben powers,who played thelma's husband keith anderson on the final season of the classic cbs sitcom“good times”,has died .he was 64.
生成式摘要允許摘要中包含新的詞語或短語,靈活性高、更連貫,但是在面臨長文本摘要時,輸入整篇文檔影響了生成過程,導致解碼緩慢,通常會出現關鍵信息丟失、摘要不準確的問題。如文獻[8]采用生成式方法,提出分布語義獎勵(Distributional Semantics Reward,DSR)模型,實驗結果表明,輸入是整篇長文檔時,輸出摘要無法涵蓋輸入長文本中的全部關鍵信息。但生成式摘要對短文本生成效果好,可以生成準確流暢的摘要。例2 為DSR 模型生成的摘要樣例,模型生成摘要與參考摘要幾乎一致,且摘要準確流暢、可讀性強。因此對于長文本,通過重寫原文關鍵句,不僅可以保留原文中最重要的信息,而且可達到更加簡潔流暢的摘要目標。
例2
源文本:european finance ministers on saturday urged swedes to vote“yes”to adopting the euro,saying entry into the currency bloc would be good for sweden and the rest of europe.
參考摘要:european finance ministers urge swedes to vote yes to euro
生成摘要:eu finance ministers urge swedes to vote yes to euro
在摘要生成過程中,關鍵句經重寫后得到摘要,重點在于如何抽取出關鍵句,抽取結果影響生成的摘要質量,抽取出非關鍵句將導致摘要無法概括文章核心內容。如文獻[14]通過抽取任務中估計的顯著性來約束生成任務中學習的注意力,以增強它們的一致性,重新生成后減少了抽取式摘要包含的冗余信息,但沒有多次迭代的過程,導致抽取出非關鍵句,以至于摘要沒有準確把握原文核心思想。可以采用強化學習來解決,通過A2C算法多次迭代改進抽取過程,使抽取器獲得更準確的句子用于重寫。
2 基于A2C算法的強化自動摘要模型
在強化學習框架下,本文提出面向長文本的基于A2C 算法的強化自動摘要模型(A2C-RLAS),如圖1 所示。基于抽取器(extractor)和重寫器(rewriter)過程得到新的摘要,作為A2C算法的actor,critic基于actor抽取關鍵句的行為評判該行為的得分,評價器(evaluator)通過BERTScore值評價重寫摘要與參考摘要的語義相似性,作為獎勵,actor 則根據critic 的評分修改選行為的概率,最終改進抽取過程。
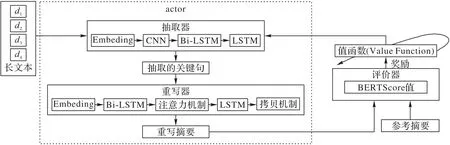
圖1 A2C-RLAS模型Fig.1 A2C-RLAS model
2.1 抽取器
抽取器基于encoder-decoder框架,如圖2所示。分層文檔編碼器讀取輸入序列并生成結合全局上下文語義信息的句向量;解碼器結合指針機制獲取原文中每個句子被抽取的概率,同時抽取出若干關鍵句,組成短文本。
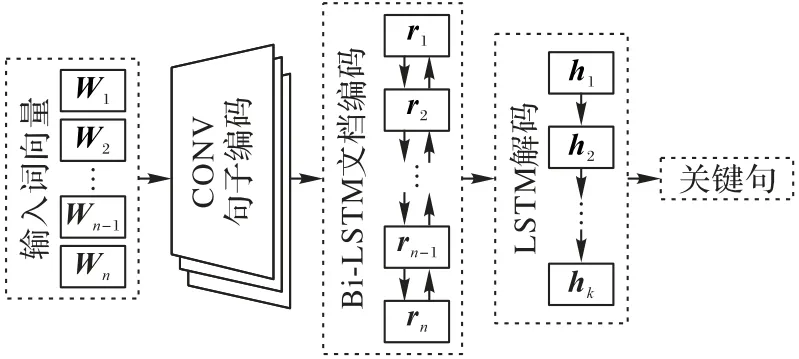
圖2 抽取器模型Fig.2 Extractor model
2.1.1 分層文檔編碼器
由于抽取器要抽取源文本整句,因此模型輸入需要句向量表示源文本中的每一個句子。采用文獻[15]提出的時間卷積模型得到源文本中每個句子的句向量。具體地,對于源文本中每一個句子,由句中每個詞的詞向量得到句子矩陣,通過卷積、非線性激活和最大池化操作,卷積網絡輸出第i個句子的句向量ri。
為了進一步整合文檔的全局上下文信息并捕捉句子間長期語義依賴,將句向量ri送入雙向長短期記憶(Long Short-Term Memory,LSTM)網絡[16]進行訓練,生成包含上下文語義信息的句向量hi,進而使用hi來表示源文本中第i個句子。
2.1.2 解碼器
得到句向量hi后,使用基于LSTM 的指針網絡[17]作為解碼器,進行關鍵句的選擇。對于每個抽取時間步t,源文本中每個句子被抽取的概率是:
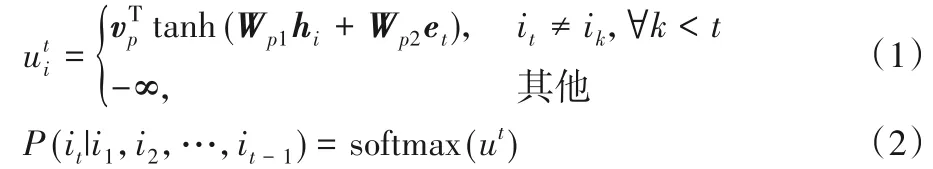
其中et是指針網絡在抽取時間步t時的輸出,具體如下:
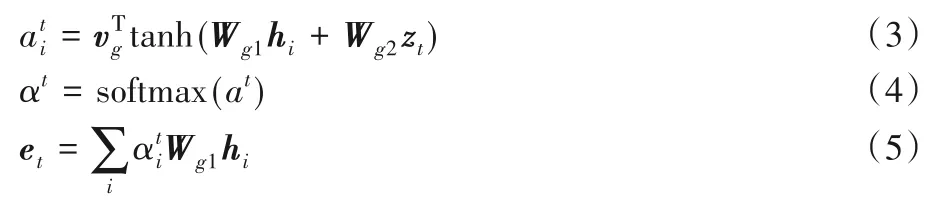
其中:zt是單層LSTM 的輸出,W和v均為可學習參數。抽取模型可看作一個二分類問題,即對源文本中每個句子分為摘要句和非摘要句。
2.2 重寫器
為得到簡短、流暢的摘要,抽取器提取出關鍵句構成短文本后,重寫器對短文本進行生成式改寫。重寫器采用標準的基于注意力機制的encoder-decoder 模型[18],輸入短文本x={x1,x2,…,xM},輸出摘要序列y={y1,y2,…,yN}。為考慮當前詞的上下文狀態,編碼器采用雙向長短期記憶網絡(Bidirectional Long Short-Term Memory network,Bi-LSTM)。引入注意力機制,使解碼時可以選擇性地讀取編碼后的語義向量的信息。
針對未登錄詞(Out-Of-Vocabulary,OOV)問題,采用拷貝機制[19]解決。在解碼端設置指針開關,指針開關為拷貝模式P,則復制原文單詞;指針開關為生成模式G,則從詞表生成一個新詞。其模型結構如圖3所示。
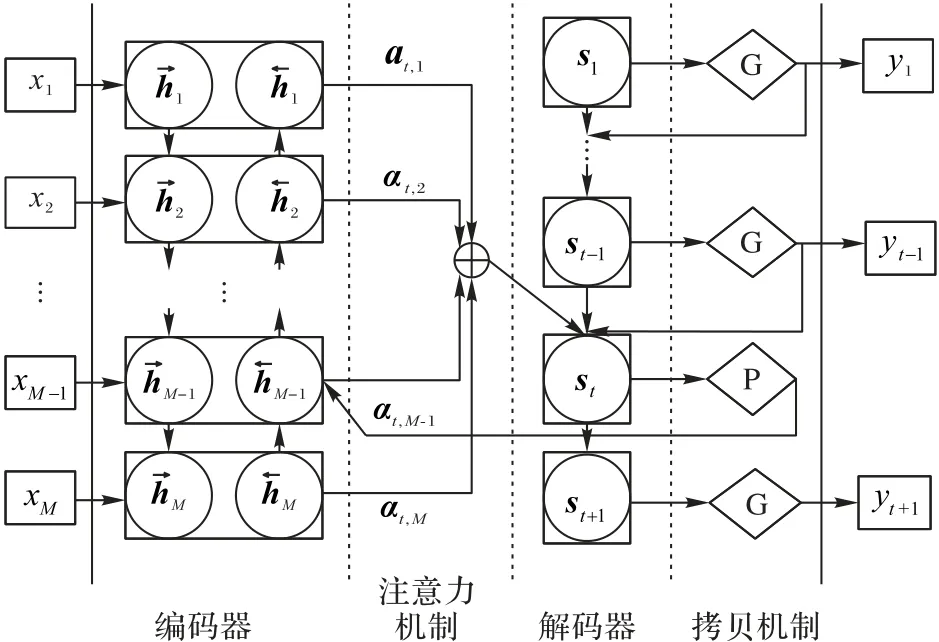
圖3 重寫器模型Fig.3 Rewriter model
2.3 強化學習
在長文本摘要過程中,需要對抽取過程進行多次迭代,采用強化學習中Advantage Actor-Critic(A2C)算法。相較于REINFORCE 算法[20],A2C 算法增加評論家網絡,可解決高方差問題,從而有效地提高抽取的關鍵句的質量。
由于傳統的摘要評價指標ROUGE 只能計算候選摘要與參考摘要之間的n元短語重疊度,無法捕捉摘要的語義關系。而本文方法要重寫關鍵句,顯然ROUGE不再適用于重寫摘要的評價。因此,采用評價器(evaluator)計算重寫摘要和參考摘要的BERTScore 值,作為強化學習中基于語義的獎勵,以提高抽取器抽取句子的質量。
2.3.1 基于語義的獎勵
BERTScore[10]利用來自BERT(Bidirectional Encoder Representations from Transformers)的預訓練上下文嵌入,并通過余弦相似性匹配參考摘要和候選摘要中的單詞,被定義為:
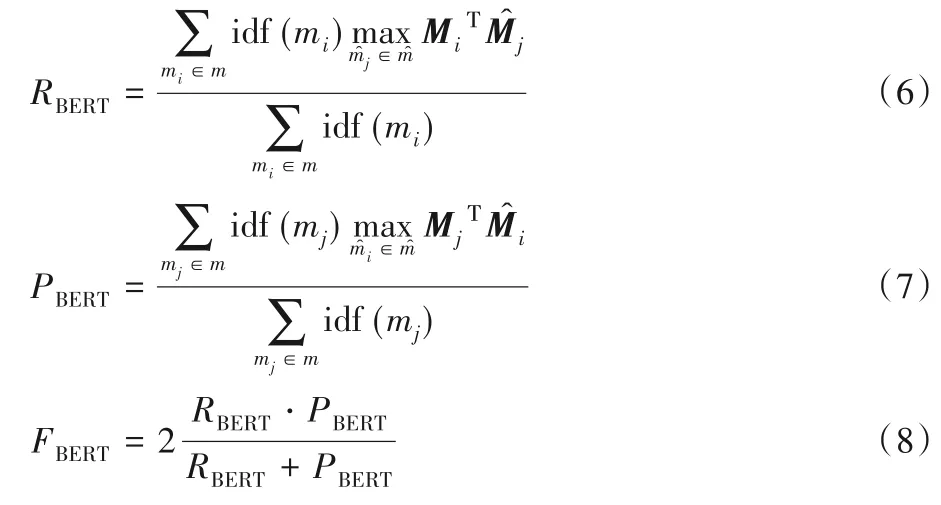
其中:M和表示參考摘要中詞m和候選摘要中詞來自BERT的上下文詞嵌入;函數idf(?)用于計算逆文檔頻率。
2.3.2 A2C算法
采用強化學習A2C(Advantage Actor-Critic)算法,actor 是指策略函數πθ(s,a)。在每一個抽取時間步t,抽取網絡的當前狀態是已抽取出的關鍵句di的集合,actor 通過觀察當前狀態ct=根據策略πθ(s,a)采樣一個動作it~πθ(ct,i),從原文D中抽取下一個句子di,critic 網絡評價當前重寫后摘要句與參考摘要bt對應句子的BERTScore值作為獎勵:
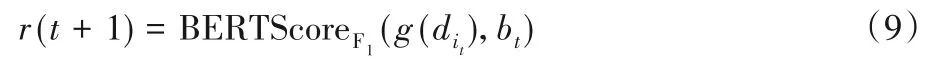
而一次摘要過程為一個回合,對滿足策略πθ(s,a)的實際采樣行為的評價通過反算、折扣后可得到整個摘要的總回報Rt:

其中:N表示抽取的關鍵句數目;γ是折扣因子,為一個常數。
Rt作為動作值函數的估計,A2C算法選取僅基于狀態的狀態值函數作為基準(baseline)函數,得到Advantage函數:
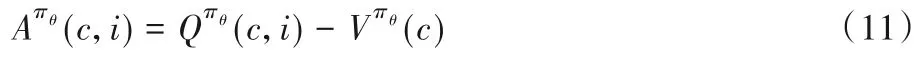
Advantage 函數記錄了在狀態ct時采取行為it會比在狀態ct多出的價值,這與策略改善的目標是一致的,策略目標函數梯度可表示為:
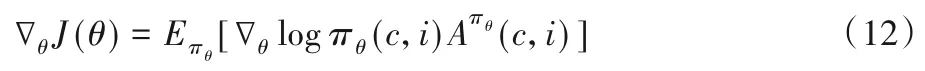
由Advantage 函數得到的策略梯度有正有負,為正時鼓勵抽取該句子,為負時不會鼓勵抽取該句子。
此時,actor的損失函數為:
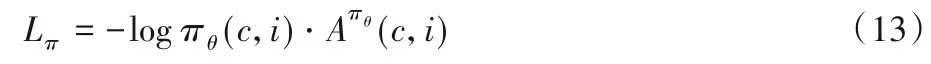
而critic 可以直接使用均方誤差MSE 作為損失函數。在每步更新中,策略函數的參數θ更新如下:
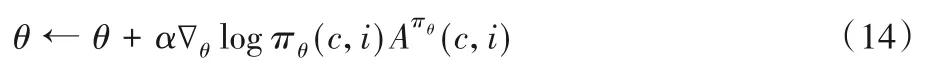
3 實驗與結果分析
3.1 數據集
實驗評估使用CNN/Daily Mail 數據集[11],由美國有線新聞網(Cable News Network,CNN)和每日郵報網新聞(Daily Mail)組成,如表2。該數據集包含287 227 對訓練集、13 368對驗證集和11 490 對測試集。本文用訓練集來訓練模型,保存多個訓練效果較好的模型用驗證集來挑選出最優模型,在測試集上測試得出最終結果。

表2 CNN/Daily Mail數據集Tab.2 CNN/Daily Mail dataset
3.2 評價指標
自動摘要評價采用通用的摘要評測準則ROUGE[12]。ROUGE 指標計算參考摘要與候選摘要之間的N元短語重疊度來衡量摘要的質量。ROUGE 評價指標主要由ROUGE-N(N可取1、2、3等)和ROUGE-L組成。
本文采用ROUGE-1(unigram)和ROUGE-2(bigram)以衡量摘要信息的豐富性,ROUGE-L 代表參考摘要和候選摘要的最長公共子序列,用于衡量摘要內容的流暢性。
3.3 參數設置
對于所有的實驗,基于word2vec[21]訓練詞向量,詞向量的維數為128,LSTM 的隱藏單元向量維數為256,單詞表使用30 000個單詞。在訓練階段使用Adam優化器[22]訓練模型,學習速率設置為0.001,動量參數設置為β1=0.9,β2=0.999 和ε=10-8,折扣因子設置為0.95,batch-size 設置為32,解碼時使用Beam大小為5的集束搜索(Beam search)。
3.4 對比模型
為驗證A2C-RLAS 方法生成摘要的性能,選取目前表現良好的抽取式模型和生成式模型進行對比驗證。各對比模型的詳情如下:
1)Lead-3:直接抽取源文本的前三句組成文章摘要。
2)SUMO(Structured sUmmarization MOdel)[23]:將抽取式文本摘要看作樹歸納問題,利用結構化注意(structured attention),基于迭代結構改進方法來學習文本表示。
3)Refresh[13]:將單文檔摘要問題抽象為句子排序任務,提出一種通過強化學習對ROUGE 評價標準進行全局優化的抽取式文本自動摘要模型。
4)Pointer-generator+coverage[24]:基于encoder-decoder 框架,通過指針從原文復制單詞以解決OOV 問題,并引入coverage機制,避免生成重復。
5)SummaRuNNer[25]:基于門控循環單元-循環神經網絡(Gate Recurrent Unit-Recurrent Neural Network,GRU-RNN)的抽取式模型,提出了一個新穎的生成式訓練機制,可以不需要在訓練階段引入抽取式標簽。
6)BERT-ext+abs[26]:將BERT 預訓練方法應用于解決文本自動摘要問題,提出一種兩階段自動摘要模型。
3.5 對比實驗結果
采用傳統的評測準則ROUGE 評價對比實驗結果,如表3,分為抽取式模型、生成式模型和本文模型三組,指標最高的分數用加粗數字標出。由表3 可以看出,本文模型在ROUGE-1 和ROUGE-L 評分上是所有模型中最好的,表明本文模型的整體表現最好。相較于抽取式模型SUMO,本文模型在ROUGE-1 和ROUGE-L 指標上分別提高了0.33 和1.69個百分點;相較于生成式模型Pointer-generator+coverage,本文模型在ROUGE-1、ROUGE-2 和ROUGE-L 指標上分別提高了1.80、0.93 和2.51 個百分點,表明本文模型抽取出的關鍵句內容更加全面。與BERT-ext+abs 模型相比,本文模型在ROUGE-1、ROUGE-2、ROUGE-L 指標上分別提升了1.19、0.34 和1.06 個百分點,表明基于強化學習的A2C-RLAS 模型摘要的信息性和流暢性更好。但在ROUGE-2 評分上A2CRLAS 沒有達到最高水平,相較于SUMO 模型差了0.19 個百分點。R-AVG 評分是ROUGE-1、ROUGE-2 和ROUGE-L 的平均值,本文模型的R-AVG 評分是32.81,取得了相較于基線模型的最好效果。綜合上述對比實驗可知,本文模型性能取得了一定的提升,達到了最好效果。
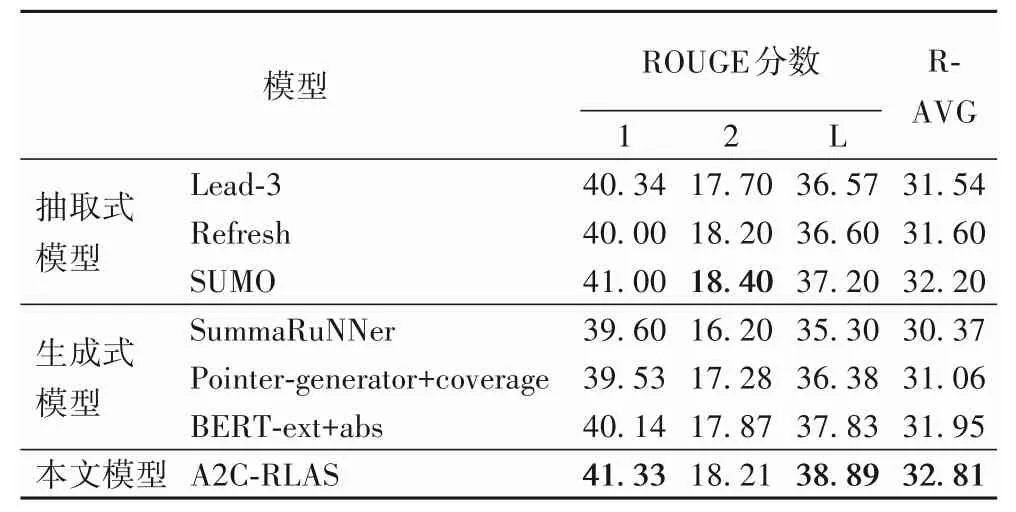
表3 不同模型的ROUGE評價指標對比 單位:%Tab.3 Comparison of ROUGE evaluation indicator of different models unit:%
不采用傳統的評測準則ROUGE,增加以BERTScore 為評測指標的對比實驗,結果如表4,指標最高的分數用加粗數字標出。文獻[8]在以交叉熵損失(cross-ENTropy loss,XENT)訓練模型和以ROUGE作為獎勵訓練模型的基礎上,提出DSR模型,引入分布式語義獎勵,生成語義正確的短語。文獻[27]在指針生成(Pointer-Generator,PG)網絡和基于覆蓋機制的指針生成網絡(Pointer-Generator network with the coverage mechanism,PG+Cov.)的基礎上,引入新的注意力機制,提出基于遞減注意力機制的指針生成模型(Pointer-Generator model with the diminishing attention mechanism,PG+DimAttn),利用子模塊函數的特性提高神經抽象摘要的覆蓋率。
在精確率Precision、召回率Recall和F1值上,本文模型超過了各對比實驗模型。相較于DSR 模型,本文模型在Precision(P)、Recall(R)和F1 值(F1)上分別提高了20.46、19.94 和20.39 個百分點,在ROUGE-L 指標上提高了7.93 個百分點。與PG+DimAttn 模型相比,本文模型的F1 值提高了0.05 個百分點,在ROUGE-L 指標上提高了1.95 個百分點。綜合ROUGE 指標和BERTScore 指標結果表明,基于語義的獎勵方法能夠提高摘要語義信息,摘要信息性和流暢性也得到進一步提升。
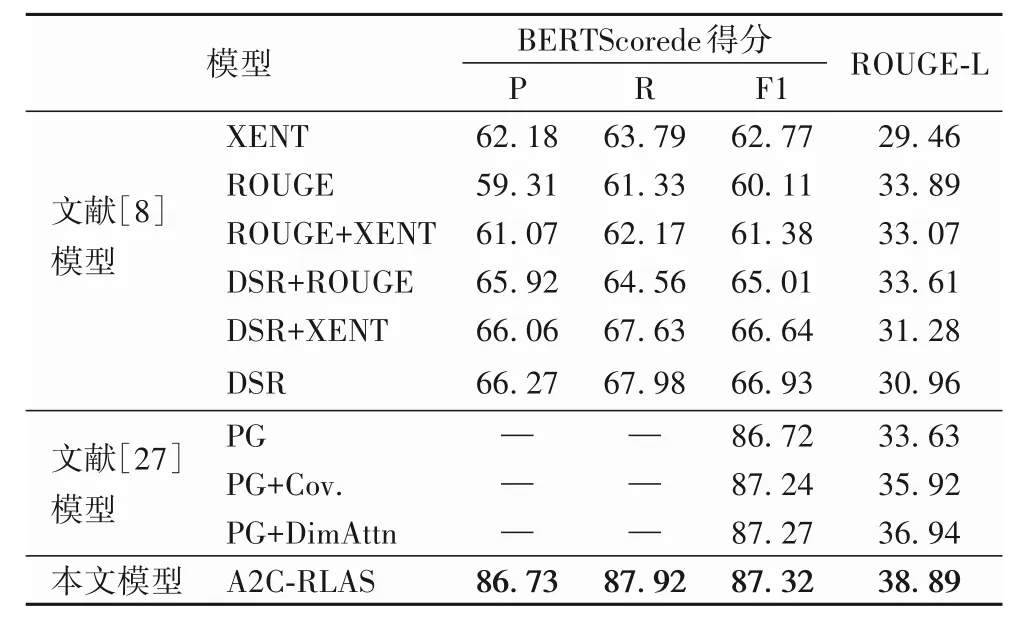
表4 不同模型的BERTScore和ROUGE-L評價指標對比 單位:%Tab.4 Comparison of BERTScore and ROUGE-L evaluation indicators of different models unit:%
3.6 消融實驗
本節對A2C-RLAS 模型中的重寫器(rewriter)和強化學習(RL)進行消融分析,結果如表5所示,指標最高的分數用加粗數字標出。在ROUGE-1、ROUGE-2和ROUGE-L指標上,A2CRLAS 相較于A2C-RLAS(no RL)分別提高了2.95、2.09 和2.85 個百分點,相較于A2C-RLAS(no rewriter)分別提高了0.16、0.05 和1.13 個百分點,相較于A2C-RLAS(no RL,no rewriter)分別提高了1.16、0.10 和2.48 個百分點。在BERTScore 的Precision、Recall 和F1 值指標上,A2C-RLAS 相較于A2C-RLAS(no RL)分別提高了5.49、5.29和5.39個百分點,相較于A2C-RLAS(no rewriter)分別提高了0.32、0.57 和0.44 個百分點,相較于A2C-RLAS(no RL,no rewriter)分別提高了2.41、1.71和2.07個百分點。
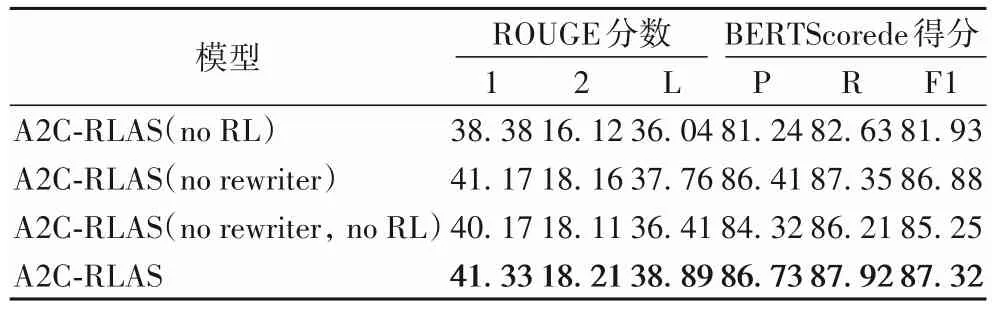
表5 不同模型的ROUGE評價指標對比 單位:%Tab.5 Comparison of ROUGE evaluation indicator of different models unit:%
上述性能提升的原因是不含重寫器的模型直接抽取原文關鍵句組成摘要,而原文整句往往過長,沒有重寫關鍵句導致摘要包含過多冗余信息,并且參考摘要往往是重寫過的,比較精簡,導致計算參考摘要和抽取摘要的精確匹配時ROUGE值較低,相應的BERTScore 值也較低。不含強化學習的模型的抽取過程沒有多次迭代,導致抽取出非關鍵句,經重寫后無法與參考摘要相匹配,ROUGE 評分低,此時參考摘要和模型生成摘要的語義相似度也較低。上述實驗驗證了重寫器(rewriter)和強化學習(RL)存在的必要性。
3.7 模型摘要示例
表6展示了本文模型和其他對比模型的摘要樣例。從摘要內容可以發現,A2C-RLAS模型摘要更加全面、高度貼近參考摘要,表明該模型經過強化學習的A2C算法多次迭代后,抽取器成功抽取出全部關鍵句,且關鍵句經重寫后,去除了冗余信息,保留核心內容且簡潔流暢。經計算,A2C-RLAS模型在BERTScore的Precision、Recall和F1值的評價指標上有明顯優勢,表明本文模型摘要語義幾乎和參考摘要語義一致,達到了摘要目的。
綜合表4、5 和表6 可知,A2C-RLAS 充分發揮了抽取式方法的優勢,摘要內容緊扣文章中心;重寫器充分發揮了生成式方法的優勢,得到精簡流暢的摘要,且沒有句內重復及OOV詞,對原文內容有較好的覆蓋,總體表現良好。

表6 不同模型生成的摘要示例Tab.6 Examples of summaries generated by different models
4 結語
本文提出了面向長文本的基于A2C算法的強化自動摘要模型A2C-RLAS,該模型基于CNN 和RNN 混合神經網絡的抽取器從原文中提取出關鍵信息,指導基于拷貝機制和注意力機制的重寫器的重寫,使用強化學習連接兩個網絡,結合基于語義的獎勵方式訓練整個模型。實驗結果表明,A2C-RLAS模型在長文本自動摘要任務中,生成的摘要內容更準確,包含更多原文關鍵信息,摘要語言更加流暢,且有效避免了生成內容的重復。
此外,本文模型可以考慮進一步改進:首先,詞嵌入可以使用預訓練模型BERT;然后,為考察生成式摘要的“事實性”,可在模型中融入事實性的知識。最后,可考察本文模型對不同場景下的新數據集的適用性,比如學術論文摘要。
猜你喜歡
中學生數理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
NBA特刊(2014年7期)2014-04-29 00:44:03
語文知識(2014年1期)2014-02-28 21:59:13
中國商人(2013年1期)2013-12-04 08:52:52
