基于Python的網(wǎng)絡爬蟲與反爬蟲技術的研究
2021-03-16 10:08:22江西科技師范大學張寶剛
電子世界 2021年4期
江西科技師范大學 張寶剛
隨著互聯(lián)網(wǎng)的快速發(fā)展,網(wǎng)絡中的信息量也變得越來越巨大。如何從龐大的互聯(lián)網(wǎng)中快速準確的收集到我們需要的信息,成為了一個巨大的挑戰(zhàn)。因此,網(wǎng)絡爬蟲技術應運而生,相比較于傳統(tǒng)的人工搜集,網(wǎng)絡爬蟲可以快速的持續(xù)的準確的搜集到我們需要的信息。但對于網(wǎng)站內容提供者而言,并不希望自己的數(shù)據(jù)信息被別人搜集到,且爬蟲程序的大量請求,也會對服務器造成一定的壓力,因此就出現(xiàn)了反爬蟲技術。本文將通過一個案例系統(tǒng)的介紹網(wǎng)絡爬蟲的原理,并指出一些有效的反爬蟲技術。
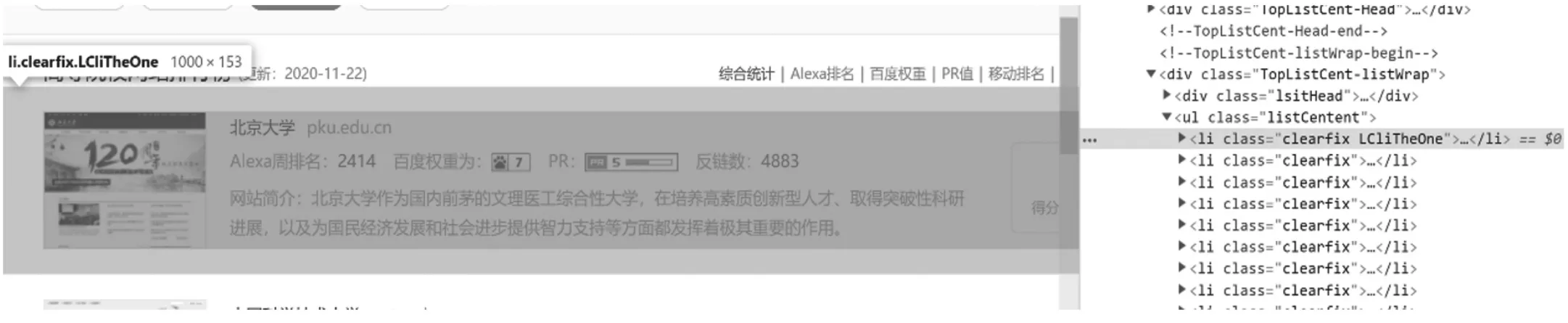
圖1 目標網(wǎng)頁源碼分析
互聯(lián)網(wǎng)中蘊含著大量的信息,如何有效的獲取這些信息并利用這些龐大的信息就變成了一個不小的挑戰(zhàn)。傳統(tǒng)的人工收集信息的方式效率低、易出錯,因此就出現(xiàn)了網(wǎng)絡爬蟲程序,它是一種根據(jù)事先制定好的規(guī)則主動的搜集萬維網(wǎng)中的數(shù)據(jù)的一種程序。我們上網(wǎng)用的搜索引擎采用的就是爬蟲技術,用無數(shù)個爬蟲每天爬取各種各樣的網(wǎng)站,并把這些網(wǎng)站放到數(shù)據(jù)庫中,等著我們去搜索。網(wǎng)絡爬蟲根據(jù)其實現(xiàn)架構大致可分為深層網(wǎng)絡爬蟲(Deep Web Crawler)、通用網(wǎng)絡爬蟲(General Purpose Web Crawler)、聚焦網(wǎng)絡爬蟲(Focused Web Crawler)、增量式網(wǎng)絡爬蟲(Incremental Web Crawler)等。本研究主要通過爬取全國高校官網(wǎng)排名情況來介紹爬蟲技術的使用,并介紹一些有效的反爬蟲技術。
1 爬蟲程序的開發(fā)
1.1 請求網(wǎng)絡數(shù)據(jù)
開發(fā)爬蟲程序的第一步是請求網(wǎng)絡數(shù)據(jù),首先我們要找到要爬取數(shù)據(jù)的目標網(wǎng)頁的url地址,然后利用Requests請求,獲取目標html頁面的源碼。本研究以爬取站長之家的高等院校網(wǎng)站排行榜里的數(shù)據(jù)為例,該頁面地址:https://top.chinaz.com/hangye/index_jiaoyu_daxue.html,我們通過Requests請求該頁面就可以拿到該目標網(wǎng)頁的源代碼了。
1.2 html頁面解析
通過上一個步驟后,我們已經(jīng)獲取到了目標網(wǎng)頁的源代碼,下面我們就可以通過解析源代碼獲取我們想要得到的數(shù)據(jù)了。在解析前,我們還要先分析網(wǎng)頁源代碼,然后才能解析。通過Google Chrome瀏覽器的開發(fā)者模式,我們可以看到整個網(wǎng)頁的源碼,在這里我們可以清晰的看到,我們需要的數(shù)據(jù)在源碼里的什么地方,如圖1所示。

圖2 代碼實現(xiàn)圖
由圖1可以看出,我們需要的的信息,都在class=listCentent的
- 標簽里,
- 標簽里,因此我們在解析時只需要獲取到這個ul標簽的所有SS信息,并遍歷里面的
- 標簽就可以獲取到所有的高校的網(wǎng)站排名信息了。其代碼實現(xiàn)如圖2所示。
在解析的過程中主要使用的是BeautifulSoup庫。 BeautifulSoup默認使用Python標準庫里的HTML解釋器,它還可以支持一些其他的第三方解釋器,比如lxml、html5lib等,這里我們使用的是lxml解釋器,它具有速度快,文檔容錯能力強的特點。在解析時,我們先用BeautifulSoup的find函數(shù)將標簽名和樣式名傳入進去,這樣就可以得到我們要爬取的信息所在的
- 標簽所有的
- 標簽列表了,通過對網(wǎng)頁的分析我們可以發(fā)現(xiàn),每個
- 標簽對應著一條高校網(wǎng)站排名信息數(shù)據(jù),因此,我們只需要遍歷
- 標簽就可以獲取所有的高校網(wǎng)站的具體排名信息了。每一條數(shù)據(jù),我們只獲取名稱、鏈接、alexa、bd_weight、反鏈數(shù)、網(wǎng)站簡介這幾個數(shù)據(jù)。
2 數(shù)據(jù)的存儲
通過以上的操作,我們已經(jīng)成功的獲取到了我們想要的信息。接下來,我們要做的就是將我們獲取到的信息保存下來,避免反復爬取浪費資源。本研究將數(shù)據(jù)保存在MySQL數(shù)據(jù)庫,MySQL是一種開源的、關系型數(shù)據(jù)庫,它使用結構化查詢語言SQL進行數(shù)據(jù)庫管理。在使用MySQL存儲數(shù)據(jù)前,我們要先建立一張表,用來存放我們解析到的數(shù)據(jù)。建表語句如圖3所示。

圖3 建表語句圖
我們設置id為主鍵,并且其是自動遞增的,用id作為每一條數(shù)據(jù)的唯一識別碼。name代表高校的名稱,link為高校官網(wǎng)的網(wǎng)頁鏈接,chain_num為反鏈接數(shù),info為高校簡介。創(chuàng)建完數(shù)據(jù)表后,我們就可以往表里插入我們解析到的數(shù)據(jù)了。
3 反爬蟲技術
網(wǎng)絡爬蟲不僅可以輕松的“竊取”別人發(fā)布到網(wǎng)上的資源,更會給服務器帶來額外的壓力。因為網(wǎng)絡爬蟲會無休止的訪問目標服務器,其帶來的傷害相當于DDOS攻擊,消耗目標服務器的帶寬、內存、磁盤和cpu等資源,導致正常用戶的網(wǎng)絡請求異常。因此,我們需要反爬蟲程序來幫助我們抵御爬蟲程序。
3.1 User-Agent控制請求
User-Agent中可以攜帶一串用戶設備信息的字符串,包括瀏覽器、操作系統(tǒng)、cpu等信息。我們可以通過在服務器設置user-agent白名單,只有符合條件的user-agent才能訪問服務器。它的缺點就是很容易被爬蟲程序偽造頭部信息,進而被破解掉。
3.2 IP限制
我們知道爬蟲程序請求服務器速度是特別快的,并且訪問量也特別大,正常用戶不可能在短時間里有這么大的訪問量,通過這個特點,我們可以在服務器設置一個閾值,將短時間內訪問量大的IP地址加入黑名單,禁止其訪問,以達到反爬蟲的目的。其缺點也很明顯,容易誤傷正常訪問的用戶,而且爬蟲程序也可以利用IP代理實現(xiàn)換IP的目的,避免其IP被加入黑名單。
3.3 session訪問限制
session是用戶請求服務器的憑證,網(wǎng)絡爬蟲往往通過攜帶正常用戶session信息的方式,模擬正常用戶請求服務器。因此,我們同樣可以根據(jù)短時間內的訪問量的大小判斷是否為爬蟲程序,將疑似爬蟲程序的用戶的session加入黑名單。此方法缺點就是爬蟲程序可以注冊多個賬號,用多個session輪流進行請求,避免被加入黑名單。
3.4 蜘蛛陷阱
蜘蛛陷阱通過引導爬蟲程序陷入無限循環(huán)的陷阱,消耗爬蟲程序的資源,導致其崩潰而無法繼續(xù)爬取數(shù)據(jù)。此方法的缺點就是會新增許多浪費資源的文件和目錄,而且對正常網(wǎng)站排名有影響,會造成搜索引擎的爬蟲程序也無法爬取信息,進而導致在搜索引擎的網(wǎng)站排名靠后。
3.5 驗證碼
在用戶登錄或訪問某些重要信息時可以使用驗證碼來阻擋爬蟲程序。驗證碼分為圖片驗證碼、短信驗證碼、數(shù)值計算驗證碼、滑動驗證碼、圖案標記驗證碼等。這些驗證碼都可以有效的阻擋爬蟲程序,區(qū)分機器和正常用戶,使用戶可以正常訪問服務器,而爬蟲程序因識別不了驗證碼,所以爬蟲程序不能進一步訪問服務器,以達到反爬蟲的目的。驗證碼的缺點是影響用戶體驗。
3.6 動態(tài)加載數(shù)據(jù)
前面介紹的通過Python的Requests函數(shù)庫請求網(wǎng)頁,只能獲取到靜態(tài)網(wǎng)頁的數(shù)據(jù)。如果我們的網(wǎng)頁通過js動態(tài)的加載數(shù)據(jù),爬蟲程序要爬取我們的數(shù)據(jù)就沒有那么簡單了。但是,爬蟲程序可以通過抓包的形式得到url請求鏈接,然后模擬url請求進行數(shù)據(jù)抓取。
3.7 數(shù)據(jù)加密
前端請求服務器前,將請求參數(shù)、user-agent、cookie等參數(shù)進行加密,用加密后的數(shù)據(jù)請求服務器,這樣的話網(wǎng)絡爬蟲程序不知道我們的加密規(guī)則,就無法進行模擬請求我們的服務器。但是,這種方式的加密算法是寫在js代碼里的,很容易被用戶找到并且破解。
以上的反爬蟲技術,都可以在一定程度上實現(xiàn)反爬蟲的目的,給爬蟲程序增加一定的困難。在實際應用中,如果能將以上技術組合起來使用,反爬蟲的效果會更佳。當然現(xiàn)在還沒有任何一種通用的反爬蟲技術可以抵御所有的爬蟲,開發(fā)人員應該根據(jù)實際情況選擇合適的反爬蟲技術。
結語:使用Python語言編寫爬蟲程序是一種人工智能大數(shù)據(jù)時代下進行數(shù)據(jù)采集與分析的重要方式。本文以爬取站長之家中的全國高校網(wǎng)站排名信息為例,介紹了簡單Python爬蟲程序的爬蟲原理,以及一些反爬蟲的技術和它的優(yōu)缺點。爬蟲技術和反爬蟲技術,天生的相生相克、相輔相成,它們之間并沒有誰對誰錯、誰好誰壞,主要看使用他們的人是出于什么目的。
猜你喜歡- 試論我國未決羈押程序的立法完善
人大建設(2019年12期)2019-05-21 02:55:44- “程序猿”的生活什么樣
瞭望東方周刊(2017年42期)2017-12-05 18:49:38- 訂閱信息
中華手工(2017年2期)2017-06-06 23:00:31- 英國與歐盟正式啟動“離婚”程序程序
環(huán)球時報(2017-03-30)2017-03-30 06:44:45- 關注用戶
商用汽車(2016年11期)2016-12-19 01:20:16- 關注用戶
商用汽車(2016年6期)2016-06-29 09:18:54- 關注用戶
商用汽車(2016年4期)2016-05-09 01:23:12- 創(chuàng)衛(wèi)暗訪程序有待改進
中國衛(wèi)生(2015年3期)2015-11-19 02:53:32- 如何獲取一億海外用戶
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25- 展會信息
中外會展(2014年4期)2014-11-27 07:46:46 - 試論我國未決羈押程序的立法完善
- 標簽里以列表的形式放著各個學校的排名信息放在
