多示例學習下的多任務分類方法
2021-03-16 10:08:14廣東工業大學自動化學院林志全
電子世界 2021年4期
廣東工業大學自動化學院 林志全
多示例學習已應用于許多場景,如圖像分類、惡意軟件分類、文檔分類、對象檢測等。在多示例學習中,訓練數據集中的每個數據都是一個包,包由多個示例組成。包有類別標簽,實例沒有類別標簽。而學習的最終目標是給出新包的類別預測。我們以圖像分類為例,每個圖像都被視為一個包,圖像被分成多個部分,每個部分可以看作是其中一個示例,對應多個示例在袋子里。如果圖像是我們需要的圖像,那么這個包就是一個正包,具有此圖像特征的示例就是一個正示例。
傳統的分類學習方法,往往都是單個任務進行。而在現實生活中,分類任務往往是多個相似任務一起進行,對此研究人員提出來多任務學習(MTL)。通過共享相關任務之間的共同因素,可以使模型更好地對原始任務進行總結從而提高任務的泛化能力,從而提升分類器的判別度。例如,S.Pan等人提出了FELMUG框架,分析了任務間特征的敏感性,并將圖數據分為子圖挖掘中的3個特征:公共特征、輔助特征和唯一特征,在圖數據分類上取得了很好的效果。
1 定義和預處理
在多示例學習中,訓練集由一組分類標簽的包組成,如果包中至少含有一個正示例,則該包被標記為正包。如果多示例包的所有示例都是負示例,則該包被標記為負包。
(1)對于多示例學習中,我們用代表一組訓練集,是包的集合,代表有N個包,其中BN代表第N個包,YN是包的標簽,。包BN是示例的集合,其中bN是代表第N個示例,yN是示例的標簽。
(2)對于多任務學習,我們用T=1,2,…t代表t個任務。對于第t個任務,來代表任務t的包的集合。
(3)我們利用基于單個示例的相似性,挑選每個包中,最有可能為正的示例。假設給定示例x和一個子集S,可以用公式來計算,x和子集S的相似度。
2 方法
我們首先將多任務學習應用到SVM中,假定第t個任務的方程為,在這種分類下,它的結果yit的結果是代表輸入xi的分類結果是正的還是負的。接著我們把多個任務結合起來形成一個新的目標方程。考慮到任務是相互關聯的,我們使用通用功能、輔助功能和專有功能,表示wt的特征。



得到最終的目標方程后,為了改善決策邊界和提高分類器的學習性能,我們采用了一種啟發式策略,一種基于交替優化的方法來更新正候選。
第一步,選擇初始正例候選作為初始正候選,根據初步的正選正示例,去解決目標方程,并得到原始拉格朗日乘子。
第二步,固定得到拉格朗日乘子α,正候選值更新如下:

第三步,重復以上2個步驟,直到滿足下面條件:
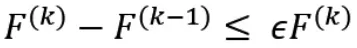
其中,F是目標方程的求解,表示第k次迭代的目標方程的解。而是自己設閾值,在實驗中我們給予的值是0.01。
3 實驗結果
為了檢驗本文提供的方案,我們利用5個多示例的數據集,Musk、Fox、tiger、Elephant去檢測本文方案的精確度,并用MI-SVM,EM-DD,FMT-MIL,MTML-MIL進行比較實驗。

表1 分類準確度對比
實驗結果由表1所示,結果表明:
(1)對比MI-SVM,EM-DD兩個多示例學習,FMT-MIL,MTML-MIL以及我們提出的方法,有更好的分類結果。說明相對于多示例分類,多任務學習應用于多示例學習時,能得到更好的分類效果。
(2)我們的方法,相對于FMT-MIL和MTML-MIL,得到更好的分類效果,分類精度有顯著的提升,比其他模型能得到更好的性能。
結論:在本文中,我們在研究多示例學習中,充分考慮到多個相似任務之間的關系,提出了基于多示例的多任務學習方法。在多示例學習中,引入樹模型,和SVM分類器,將相似任務聯系起來,重構目標方程。由實驗結果表明,我們提出的方法能夠獲得更好的分類結果,是有效可行的。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
