基于百度人工智能的拍照切題系統(tǒng)設(shè)計(jì)
2021-03-15 07:01:33吳旭東羅榮良史庭蔚陳云
電腦知識與技術(shù) 2021年3期
吳旭東 羅榮良 史庭蔚 陳云

摘要:近年來教育行業(yè)借助著互聯(lián)網(wǎng)的蓬勃發(fā)展,智能化和信息化的程度大幅提升。而教師對于紙質(zhì)試卷的錯(cuò)題、難題整理依然存在著效率較低的問題,基于百度人工智能拍照切題系統(tǒng)的設(shè)計(jì)充分利用人工智能技術(shù),對圖片自動(dòng)進(jìn)行畸變校正處理和百度OCR圖文識別,并通過訓(xùn)練好的EasyDL平臺對題目的題干和選項(xiàng)進(jìn)行分類,更好地滿足多種不同形式的教學(xué),有效提高教師效率和教學(xué)效果,成為人工智能+教育背景下教師進(jìn)行教學(xué)任務(wù)的好幫手。
關(guān)鍵詞: 百度人工智能; 畸變校正; EasyDL; 百度OCR; 文本分類
中圖分類號: TP181? ? ? ? 文獻(xiàn)標(biāo)識碼:A
文章編號:1009-3044(2021)03-0199-02
Abstract:In recent years, the education industry has greatly increased the degree of intelligence and informatization with the vigorous development of the Internet. The design of the Baidu Artificial Intelligence (AI) camera-based question cutting system makes full use of AI technology to automatically correct distortion and Baidu OCR image recognition, and classifies question stems and options through the trained EasyDL platform to better meet the needs of different forms of teaching and learning. Improve teacher efficiency and teaching effectiveness, and become a good helper for teachers to carry out teaching tasks in the context of AI + education
Key words:Baidu AI; distortion correction; EasyDL; Baidu OCR; text classification
引言
教育培訓(xùn)作為我國教育行業(yè)重要組成部分,在互聯(lián)網(wǎng)浪潮下不斷向信息化、智能化方向轉(zhuǎn)型,實(shí)現(xiàn)了利用圖片進(jìn)行識別搜題的題庫系統(tǒng),但識別搜題結(jié)果未達(dá)到預(yù)期目標(biāo)。就這一問題,本文提出了一種提高圖片搜題識別率的技術(shù)方案,利用畸變校正技術(shù)[1]對問題圖片進(jìn)行校正后調(diào)用百度OCR進(jìn)行圖文識別,調(diào)用訓(xùn)練好的EasyDL平臺文本識別模型對文本信息題干、選項(xiàng)進(jìn)行分類,裁剪出試卷中各個(gè)題目,作為預(yù)處理后的圖像來進(jìn)行識別搜題。
1 系統(tǒng)相關(guān)技術(shù)
1.1 EasyDL開發(fā)平臺
百度自主研發(fā)的飛槳平臺為從事深度學(xué)習(xí)行業(yè)的開發(fā)人員提供了一整套工具。目前飛槳平臺有開源版和企業(yè)版,本文利用開源版本中的EasyDL平臺。飛槳平臺具有快速的請求處理能力以及人性化的操作界面,極大地改善了用戶的體驗(yàn)。
EasyDL是一個(gè)對文本、圖像等進(jìn)行識別并生成算法模型,還能夠精準(zhǔn)匹配用戶識別功能需求的服務(wù)平臺。該平臺的操作界面清晰簡潔,平臺自動(dòng)生成的算法模型對用戶透明,對大多數(shù)沒有深度學(xué)習(xí)基礎(chǔ)的用戶十分友好。在該平臺下,用戶只需要簡單的上傳數(shù)據(jù)并對相關(guān)數(shù)據(jù)打上標(biāo)簽,就能夠輕松獲得一個(gè)專屬的算法模型。
1.2 透視矯正
OpenCV作為一款主流的圖像處理函數(shù)庫,給開發(fā)者提供了豐富的機(jī)器學(xué)習(xí)和計(jì)算機(jī)視覺方面的諸多算法,在圖像識別以及圖像處理領(lǐng)域得到了廣泛應(yīng)用。函數(shù)庫中的Canny邊緣檢測函數(shù)和霍夫直線檢測函數(shù)[2]專門用于獲得圖片輪廓,可用于計(jì)算圖片區(qū)域的定位以及版面區(qū)域的劃分。
為了對圖片進(jìn)行更有效的二值化,圖片需要去噪聲預(yù)處理,使用非局部平均去噪算法(NL-Means)對圖片進(jìn)行去噪處理,使圖片在去噪后能夠最大限度地保持清晰度且不丟失細(xì)節(jié)。其中,函數(shù)庫中的cv2.fastnlmeansdenisingcolored方法為對彩色圖片進(jìn)行去噪處理一種解決方法。
對圖片進(jìn)行二值化處理,一張彩色圖片需要變成灰度圖之后才能進(jìn)行二值化。每張圖片的顏色都可以表示為像素點(diǎn)構(gòu)成的像素矩陣。灰度化是指將一張彩色圖片中的每個(gè)像素點(diǎn)的RGB值變?yōu)橄嗟鹊倪^程,該值就是需要的灰度值。二值化就是根據(jù)設(shè)定的灰度閾值,將灰度圖中高于閾值的灰度值修改為1,低于閾值的灰度值修改為0的過程。二值化的作用是使圖片中的黑白輪廓更加明顯。常用函數(shù)庫中的cvtColor方法對圖片進(jìn)行灰度化,使用threshold方法對灰度圖進(jìn)行二值化。
在同一平面內(nèi),若干平行線通過該平面的投影后相交的一點(diǎn)稱為滅點(diǎn)。滅點(diǎn)可以表示出三維立體的三個(gè)方向,對在二維圖像中構(gòu)建三維立體極為重要。試卷輪廓的四角坐標(biāo),可作為imutils.perspective.fourpointtransform(透視變換)方法的四個(gè)參數(shù),用于對圖片進(jìn)行透視矯正。
1.3 圖像文字識別
百度AI平臺提供的圖文識別技術(shù)能夠獲取附帶文字位置信息的識別結(jié)果還[3]。
2 系統(tǒng)設(shè)計(jì)
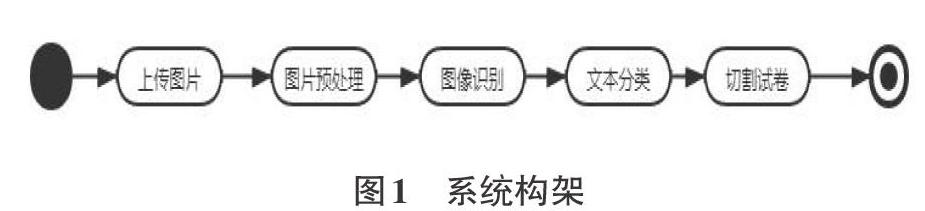
本系統(tǒng)構(gòu)架如圖1所示。
圖中各流程說明如下:
2.1 圖像預(yù)處理
本系統(tǒng)使用OpenCV庫,先對上傳圖片中不規(guī)范書卷進(jìn)行透視矯正,針對雙面試卷進(jìn)行左右分割,然后除噪、二值化預(yù)處理。
2.1.1 透視矯正
上傳的圖片會因?yàn)槿藶榕臄z的因素而出現(xiàn)傾斜的現(xiàn)象,極大影響了圖像識別,因此本系統(tǒng)需要針對傾斜的照片進(jìn)行透視矯正預(yù)處理。
使用OpenCV庫中的Canny邊緣檢測函數(shù)和霍夫直線檢測函數(shù),在原圖中找到試卷輪廓中四角的坐標(biāo),利用透視滅點(diǎn)原理將透視圖轉(zhuǎn)換為正視圖,并根據(jù)四個(gè)點(diǎn)進(jìn)行裁剪圖像,繼而得到規(guī)整的試卷圖像。
2.1.2 雙面試卷分割
百度OCR是按照從左到右的原則對雙面試卷進(jìn)行識別,而按照人類的閱讀習(xí)慣是同頁內(nèi)容優(yōu)先,自左向右再自上而下閱讀。由于兩者讀取順序不同,會直接導(dǎo)致識別結(jié)果以及分割結(jié)果的不同,所以需要對這種試卷進(jìn)行左右分割。
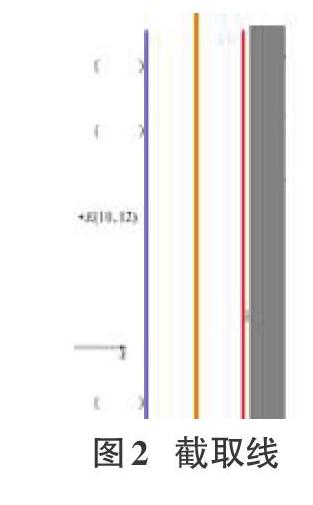
檢測出雙面試卷中存在的空白區(qū)域,以該區(qū)域的中線切割源圖像,具體步驟如下:
導(dǎo)入源圖像,使用OpenCV工具對該圖像進(jìn)行二值化預(yù)處理。根據(jù)預(yù)先設(shè)置的位置截下感興趣的區(qū)域(ROI),獲得ROI區(qū)域每一列黑色像素的比例ArrayRate。遍歷ArrayRate找到所有連續(xù)白色中列數(shù)最多的區(qū)域,即得到一個(gè)連續(xù)并近似純白的區(qū)域[4]。藍(lán)色為起始,紅色為重點(diǎn),默認(rèn)藍(lán)色和紅色正中間是所要的截取線,如圖2所示,還原比例后,通過截取線將雙面試卷截取為左右兩部分。
2.2 圖像識別
本系統(tǒng)選用了百度OCR通用文字識別帶位置版,用于獲取附帶文字位置信息的識別結(jié)果。
2.3 文本分類
EasyDL經(jīng)典版支持創(chuàng)建8種模型:單標(biāo)簽文本分類、情感傾向分析、多標(biāo)簽文本分類、聲音分類、視頻分類、圖像分割、物體檢測和圖像分類。本系統(tǒng)是基于EasyDL平臺[5]的單標(biāo)簽文本分類技術(shù)的模型,經(jīng)過訓(xùn)練后可用于區(qū)分試卷中的題干與選項(xiàng)。具體流程分為5個(gè)步驟,分別是:
1) 創(chuàng)建模型,確定模型名稱,并填寫模型的功能描述。
2) 準(zhǔn)備數(shù)據(jù),上傳數(shù)據(jù)集,并對數(shù)據(jù)集加上標(biāo)簽,按照標(biāo)簽對數(shù)據(jù)集進(jìn)行分類。
3) 訓(xùn)練模型,選擇對應(yīng)的數(shù)據(jù)標(biāo)簽進(jìn)行模型訓(xùn)練。訓(xùn)練完成后查看模型評估報(bào)告,然后對模型功能進(jìn)行校驗(yàn)。
4) 迭代模型,結(jié)合模型評估報(bào)告和校驗(yàn)結(jié)果不斷擴(kuò)充數(shù)據(jù),再通過調(diào)整訓(xùn)練數(shù)據(jù)和算法進(jìn)行多次訓(xùn)練,得到較好的模型效果。
5) 發(fā)布模型,將訓(xùn)練完成的模型部署在服務(wù)器上。
2.4 切割試卷
每個(gè)經(jīng)過百度OCR處理后的圖片返回的識別結(jié)果對象包含文本內(nèi)容Text、文本位置Location,其中Location中又包含了top、left、height、width四個(gè)位置信息。通過文本分類模型,對題干與選項(xiàng)進(jìn)行標(biāo)記,使用以下步驟來劃分題目:
1) 如果某一行被判斷為題干,則表示該行為新題的區(qū)域。上一題的所有內(nèi)容(該內(nèi)容包括文本和位置信息)已經(jīng)全部保存在一個(gè)question content集合中。
2) 將上一題的question content集合插入result集合后,清空question content集合并開始新題內(nèi)容的保存。
識別對象被正確地歸到一道題中時(shí),利用四個(gè)位置信息得到一個(gè)整體的區(qū)域,如圖3所示。
3 結(jié)論
本文深入研究了試題的拍照識別與分類過程中所遇到的問題。針對圖片上傳不規(guī)范、識別準(zhǔn)確度較低等問題,通過百度人工智能技術(shù)、畸變校正以及EsayDL平臺的綜合運(yùn)用,設(shè)計(jì)了該系統(tǒng),大幅提高了試卷錄入、分類的效率,減少了教師的工作量。具有較高的研究價(jià)值。
參考文獻(xiàn):
[1] 唐維,任國強(qiáng).基于射影矩陣變換的名片透視圖像矯正[J].電腦知識與技術(shù),2013,9(25):5711-5715.
[2] 周雨楠,張俊偉.基于Tensorflow和OpenCV的手寫體閱卷系統(tǒng)[J].電子世界,2020(13):99-101.
[3] 唐濤,馬澤.基于OCR的空間坐標(biāo)自動(dòng)提取——以廣東省清遠(yuǎn)市清新區(qū)不動(dòng)產(chǎn)存量數(shù)據(jù)整合為例[J].江西科學(xué),2018,36(6):1024-1028,1038.
[4] 魏傳義,陳勤,張旻.基于投影的文本圖像版面分割算法研究[J].現(xiàn)代計(jì)算機(jī)(專業(yè)版),2016(10):33-38.
[5] 劉洋,史煜,曹雪倩,等.自動(dòng)化機(jī)器學(xué)習(xí)在眼部疾病識別及分類中的初步應(yīng)用[J].中國數(shù)字醫(yī)學(xué),2019,14(3):44-45,49.
【通聯(lián)編輯:唐一東】
