基于知識圖譜的四大名著人物關系的構建
2021-03-14 00:51:02王家樂宋龍生
現代計算機 2021年36期
王家樂,宋龍生
(西藏大學信息科學技術學院,拉薩 850000)
0 引言
近年來,隨著人工智能技術的發展和大數據時代的到來,知識圖譜技術得到極大的發展,大量的知識圖譜被構建出來并廣泛應用在多種場景之中。四大名著作為我國古代杰出的文學作品,里面包含的人物眾多,不同的人物之間又具有錯綜復雜的關系,要想讀懂這幾部經典著作,必須將其中的人物關系梳理清楚。
為了解決這個問題,本文利用知識圖譜把四大名著中復雜的人物關系結合在一起。通過問答系統也可以為用戶找出想要獲取的某人的準確信息以及和親屬之間的聯系,為用戶提供更有價值的深層次信息。
1 系統開發環境及相關技術的介紹
1.1 Python
Python 作為一種跨平臺的計算機程序設計語言,Python 語言簡潔易讀、擴展性好容易維護,它不像C 語言那樣對格式的要求嚴謹,它的風格比較隨意,很多的層次結構用空格就可以實現,對于開發者而言比較友好。同時Python 具有很好的可移植性,能夠適應于多種平臺,因此選擇Python語言進行本設計開發。
1.2 Flask框架
與Python 中常用的框架Django 相比較而言,Flask框架可以定義為一個輕量級的框架,重要的是它顯得簡潔、輕巧而且靈活度高。Flask框架適合做分層比較少、邏輯簡單的項目。本系統中采用Flask框架比較適合。
1.3 圖形數據庫Neo4j
圖數據庫存儲和查詢數據是通過圖這種數據結構來實現的[1],數據都是以節點的形式來保存,它是通過指針來說明兩個節點之間的關系,具有任意性。圖數據庫的數據存儲方式和查詢方式都是以圖論為基礎的[2]。本文使用圖數據庫Neo4j來實現對四大名著人物關系的存儲。
1.4 MySQL數據庫
在存儲可視化展示界面和單個人物的事跡與簡介的數據時采用MySQL 數據庫。MySQL 是一種關系型數據庫管理系統[3]。在存儲關系型數據時,MySQL仍然是首要的選擇。
1.5 知識圖譜
知識圖譜經歷了早期語義網時代的發展、積累,最后才發展衍生出了這一概念。知識圖譜有助于提供更好的搜索服務,比如當搜索籃球明星姚明時,搜索引擎不僅會出現查找人物的信息,而且旁邊還會出現他的朋友、妻子、子女等簡要信息。事實上,這種效果就是知識圖譜的功勞,可以理解為知識圖譜的簡單應用。
2 系統整體框架與知識圖譜的構建
2.1 系統的整體框架
本系統采用Flask 框架對整個項目進行交互,還包括網絡爬蟲部分、數據處理部分、知識圖譜構建部分、分詞部分和前端展示部分。
2.2 知識圖譜的構建
知識圖譜的構建首先需要大量的數據作為支撐,通過結合人工獲取與網絡爬蟲共同得到本系統需要的數據,在得到大量的數據之后,接下來需要對數據進行分類。構建知識圖譜的主要方法可以分為兩種:一是自頂向下的構建方式,二是自底向上的構建方式[4]。
目前,在構建知識圖譜時,一般采用自底向上的方式,從網絡中抽取信息[5],這種從下往上將知識進行疊加的方式便于信息的修改。但是在后期的過程中同時使用自頂向下和自底向上構建方法,并將兩種方法的優勢結合一起能夠更高效地完成這一階段的工作。
2.3 數據的爬取
由于本系統要使用眾多的人物圖片和一些相關信息,所以使用網絡爬蟲技術作為收集數據的主要方式。網絡爬蟲伴隨著大數據與人工智能時代的來臨而受到越來越多人的重視與青睞。網絡爬蟲是搜索引擎的重要組成部分[6]。通俗的講,爬蟲就是程序代替人們在網頁中獲取想要的信息,用程序替你獲取你想要的信息。
爬蟲的主要步驟分為:分析站點(目標網站)→發送請求→獲取相應的內容→解析網頁→數據保存。
2.4 知識抽取
知識抽取的過程包括分詞、實體命名識別、關系抽取以及事件抽取[7]。本系統的分詞工具直接使用的是已經比較完善的LTP,因為它集成了分詞和詞性標注等多種方法在里面。
在本系統中用到的實體關系一般是指君臣關系、兄弟關系、同僚關系等。實體命名識別主要是從互聯網或者文本中發現有用的人物節點。除了這種方式外,還有人工獲取,將數據同樣整理成三元組的形式進行存儲。之所以加入人工獲取的方式是因為在四大名著的文本中存在有二義性的詞語。但是,本系統中的數據關系來源幾乎都是人工整理所得,不存在二義性的問題。
2.5 問答系統架構
(1)數據處理部分。原始數據來源于關系數據庫,需要將數據預處理后,導入的圖數據庫Neo4j 中。本系統選擇使用Neo4j-import 將大規模的數據導入到Neo4j 數據庫中(首先將數據Excel轉換成CSV 格式,然后將CSV 格式存放在import文件夾下),最終形成想要的知識庫。
(2)問題分析部分。本系統針對用戶輸入的問題進行模式匹配,識別出實體,進行詞性分析,從而找出人名實體和親屬關系類別。
(3)查詢結果部分。主要的功能分為兩種類型:一種是查詢人物的親屬關系,另一種是查詢兩個人物之間是否存在關系。
(4)結果返回部分。如果在圖數據庫中能找到答案,就返回相應的節點和關系展示出圖譜的全貌,如果查找失敗就報錯,查詢兩個人物之間的關系時如果存在關系就會跳轉到答案的界面,沒有則顯示沒有關系,若查找成功還會出現人物對應的圖片與人物簡介。
3 知識圖譜可視化系統與功能實現
在本系統中知識圖譜的可視化主要是前端界面的整體展示,在對整體數據進行展示的過程中使用echarts 可視化平臺可以直觀地看到系統中的各類關系和實體以及數據的統計。人物檢索主要是以關鍵詞為中心,結果會將和關鍵詞有關系的節點(實體)連在一起形成一個大的知識網絡,展示在網頁中。
對Neo4j 數據庫中數據的讀取和前端HTML界面的展示依靠的是Flask框架,進而將數據庫中的所有內容進行可視化展示。可視化界面還具有搜索單個人物、知識圖譜全貌的展示、查詢人物關系等功能。
3.1 可視化界面實現
整體系統實現了:①可視化展示;②四大名著知識圖譜全貌展示;③搜索單個人物;④查詢人物之間的關系。
圖1 是可視化界面,顯示了本系統中關系和實體的總數目,中間部分的圖譜效果是由echarts實現,當點擊其中的名字會出現相應內容介紹。右側介紹了系統中的主要功能模塊。
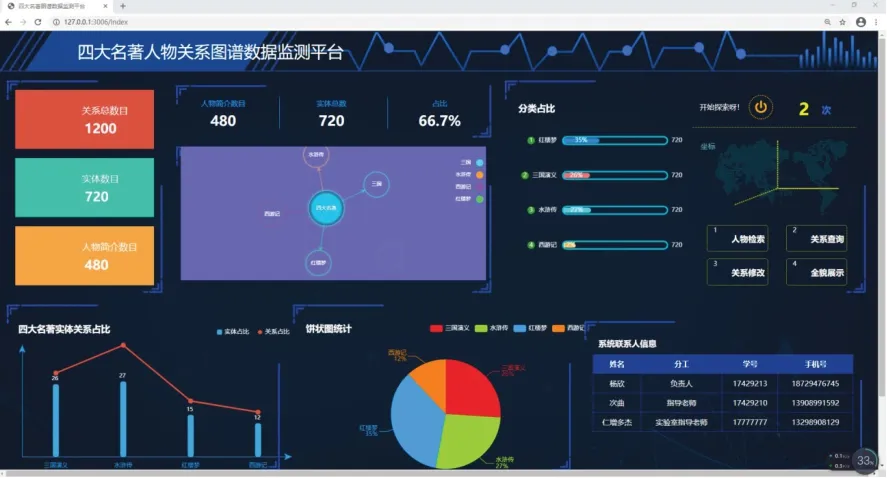
圖1 可視化界面展示
3.2 知識圖譜的實現
圖2是數據的展示界面。
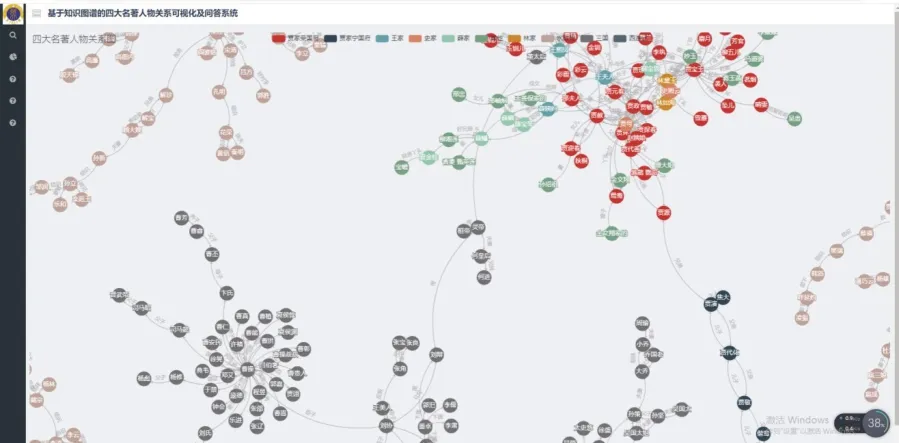
圖2 四大名著數據展示
可以看到四大名著人物關系全貌的一部分,它和在圖形數據庫Neo4j 中的效果略同,但是它在前端的展示會顯得清楚、美觀。
3.3 問答系統的實現
關于增添關系的效果,當需要添加兩個人物的關系時,在輸入框中添加兩個人物的,名字和他們之間的關系就可以成功的添加這兩個人的關系。
查找某個人的親屬關系,只要這個關系存在就會顯示親屬的關系圖譜,并且會顯示出對應人物的簡介。
除上述的功能之外,為了使系統中的內容更加充實以滿足更多的使用者,加入了四大名著中主要事件的搜索以及主要事件的視頻內容。例如:在搜索欄中搜索“武松打虎”,就會與數據庫中的內容進行匹配,然后出現對應的視頻片段。
4 結語
本文主要論述了基于四大名著的知識圖譜的構建,使用人工獲取和網絡爬蟲在互聯網上獲取相關資源后,通過對獲取的人物關系進行歸納、整合等操作后整理成三元組的形式,利用Neo4j存儲其中的人物關系,接下來使用Flask框架來實現系統中前后端的交互,最終構建了四大名著人物關系的知識圖譜。不僅有基本的人物圖譜的全部展示,而且加入了類似于大數據的前端展示,使得數據的可視化效果增強。
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
當代陜西(2020年13期)2020-08-24 08:22:02
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
制造技術與機床(2017年5期)2018-01-19 02:49:17
財經(2017年2期)2017-03-10 14:35:35
濰坊學院學報(2016年2期)2016-12-01 13:00:11
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
