基于BP 神經網絡的產品商標鑒別系統研究*
2021-03-11 03:10:02王一海
電子器件 2021年6期
王一海
(南京信息職業技術學院數字商務學院,江蘇 南京 210023)
近年來,隨著人工智能、大數據等新興技術的迅速發展,促進了電子商務產業鏈的發展,零售業的諸多環節發生了顯著變化。零售業已經成為人工智能等新興技術的典型應用場景,以深度學習為基礎的人臉識別、語音對話、商品識別等人工智能技術正在探索如何應用于刷臉支付、以圖搜圖、智能購物等場合[1-3]。
商標作為一個公司、組織、品牌、產品獨一無二的符號,商家可以通過搜索、識別相關的商標,來分析其品牌在整個市場中的發展情況以及未來的發展趨勢,同時可以幫助廣告商來檢查廣告的有效性,以及是否存在版權侵權方面的問題。然而,由于互聯網圖片、視頻數據的規模急劇增長,圖片和視頻中的產品商標的有效智能鑒別,已經成為一個不可回避的問題。
商標中包含文本、符號和圖形等元素,目前商標檢測中存在的主要難點包括:商標在圖片中的位置、角度是不確定的,由于自然場景中各種印刷、照明、遮擋、旋轉、裁剪、大小等因素,商標存在著很大變化,并且商標的類內差異比較大,類間差異有的會比較小,容易帶來誤檢。文獻[4]在商標識別中采用了一種基于Hu 修正矩的特征提取算法,該方法針對商標的多種狀態,比如旋轉、縮放或平移時,所得到的修正矩值基本保持不變,具有一定的穩定性。針對商標識別過程中資源要求過高的問題,文獻[5]研究了一種基于計算遷移的商標識別方法,該方法用于智能終端對商標的識別,將任務節點的執行位置由應用成本圖輔導決策,實現了商標識別應用過程的計算遷移,降低了終端能耗。文獻[6]針對鐳射煙標的識別問題,通過光譜反射率判斷主體顏色信息,并計算色差平均值。
本文基于BP 構建全連接前向反饋神經網絡的商標鑒別系統,對一定規模的測試集商標進行鑒別測試,構建預測模型,加載進網絡進行迭代訓練,從而對網絡的預測能力進行評估,進行對商標更準確的鑒別。
1 網絡架構
如圖1 所示,DNN 基本結構由三部分組成:輸入層、隱含層和輸出層。這些層均采用全連接神經網絡(FNN)[7],其中各層的每個神經元都與前一層的所有神經元相連。因此,前一層神經元的輸出就是下一層神經元的輸入,每個連接都有一個加權值w。每次迭代的目標是更新這些權重,以便預測結果更接近模擬數據。同一層的神經元之間沒有連接。在神經網絡的學習過程中,學習損失是向后傳播的,可以用均方誤差或線性誤差來測量。

圖1 神經網絡基本架構
本文的研究中,神經網絡框架構造為多維輸入和一維輸出。當我們增加層的數量和大小時,網絡的體量就會增加,這意味著神經元可以協作來表達更復雜的功能。然而,較大的網絡雖然帶來較強的擬合能力,但也帶來了負面影響,即過擬合[8]。過擬合是指網絡對數據中的噪聲有較強的擬合能力,而沒有充分考慮數據集之間的本征關系[9]。我們采用的策略是使用正則化技術來控制過度學習同時確保大型網絡的擬合能力[10-11]。
2 基于BP 神經網絡的商標鑒別系統
根據第1 節提出的基本神經網絡架構,我們搭建了一個專用于識別判斷商標真偽信息的全連接前向反饋神經網絡,輸入為根據圖片信息提取出的128 pixel×128 pixel 灰度數據值,輸出為包含商標真偽信息的單值數據。圖2 展示了我們的商標鑒別模型的設計流程圖。

圖2 商標鑒別系統設計流程圖
本文采用的原始數據為20 個品牌的正版商標及其對應的20 個盜版商標,圖片數據格式為JPG,分辨率為400 pixel×400 pixel。我們將神經網絡的層數設為8,每一層神經元的個數配比分別為2 048,1 024,512,128,64,32,16,8,每層隱藏層的激活函數為tanh 函數,而輸出層的激活函數為softmax函數,輸出獨立編碼判斷真偽的單值。
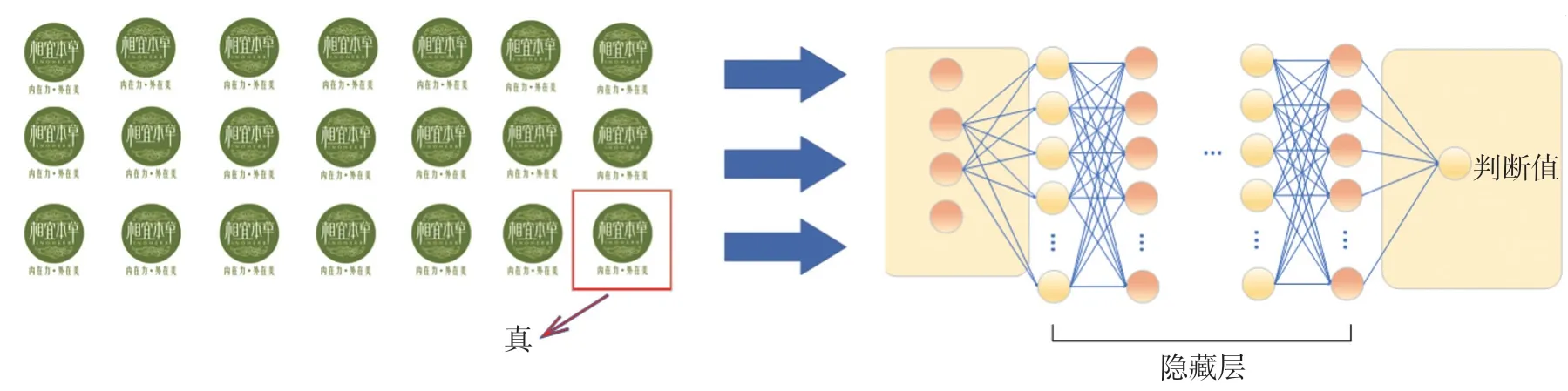
圖3 商標鑒別網絡系統流程圖
3 測試結果與分析
目前,神經網絡最常用的激活函數有Sigmoid、雙曲正切(tanh)和整流線性單元(ReLu)[12-13]。如圖4所示,我們采用8 層隱含層,每一層神經元的個數配比分別為2 048,1 024,512,128,64,32,16,8 的全連接神經網絡,研究在10 000 次的前100 次迭代中,各激活函數對網絡學習效率的影響。經過近10 000 次迭代后,各激活函數的訓練損失明顯降低,而tanh 的損失值最低。這些結果表明,tanh 更適合我們的非線性數據模型,在本文中選擇tanh 作為激活函數。
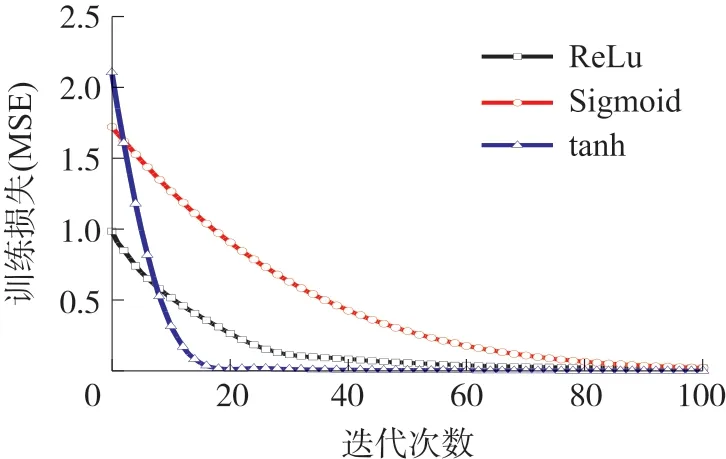
圖4 激活函數對網絡學習效率影響對比圖
訓練中使用的優化算法為梯度下降算法[14-15]。梯度下降算法中的學習速率和步長,可以用來控制權值更新的速度。我們使用變學習率的訓練方法[16-17]:在每次訓練中,學習率從0.001 開始減小,步長為0.000 5。如圖5 所示,與傳統的訓練方法相比,這種訓練模式可以幫助網絡更快地收斂到目標函數的最小值。
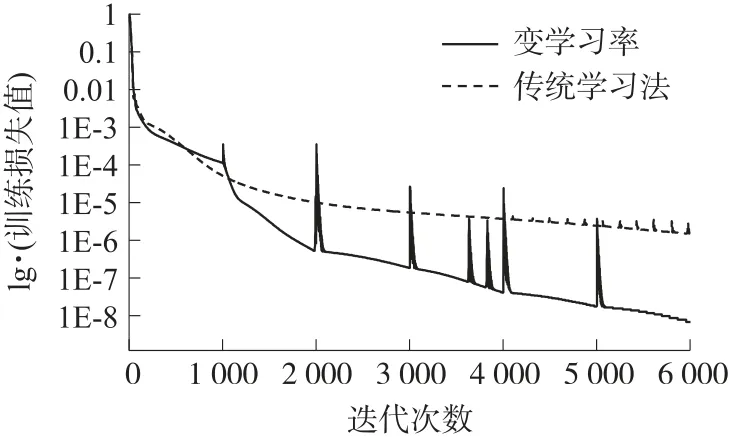
圖5 訓練方法對比圖
在系統測試中我們使用均方誤差(mean square erro,MSE)來衡量網絡的擬合能力,最終訓練結束后訓練損失的MSE 值下降到了1×10-8,證明我們的網絡能夠準確擬合出商標圖像數據和商標真偽值之間的關系式。為了驗證網絡的預測能力,我們準備了一組測試商標數據輸入網絡,如圖6 所示,網絡精確地判斷出了商標的真偽信息。
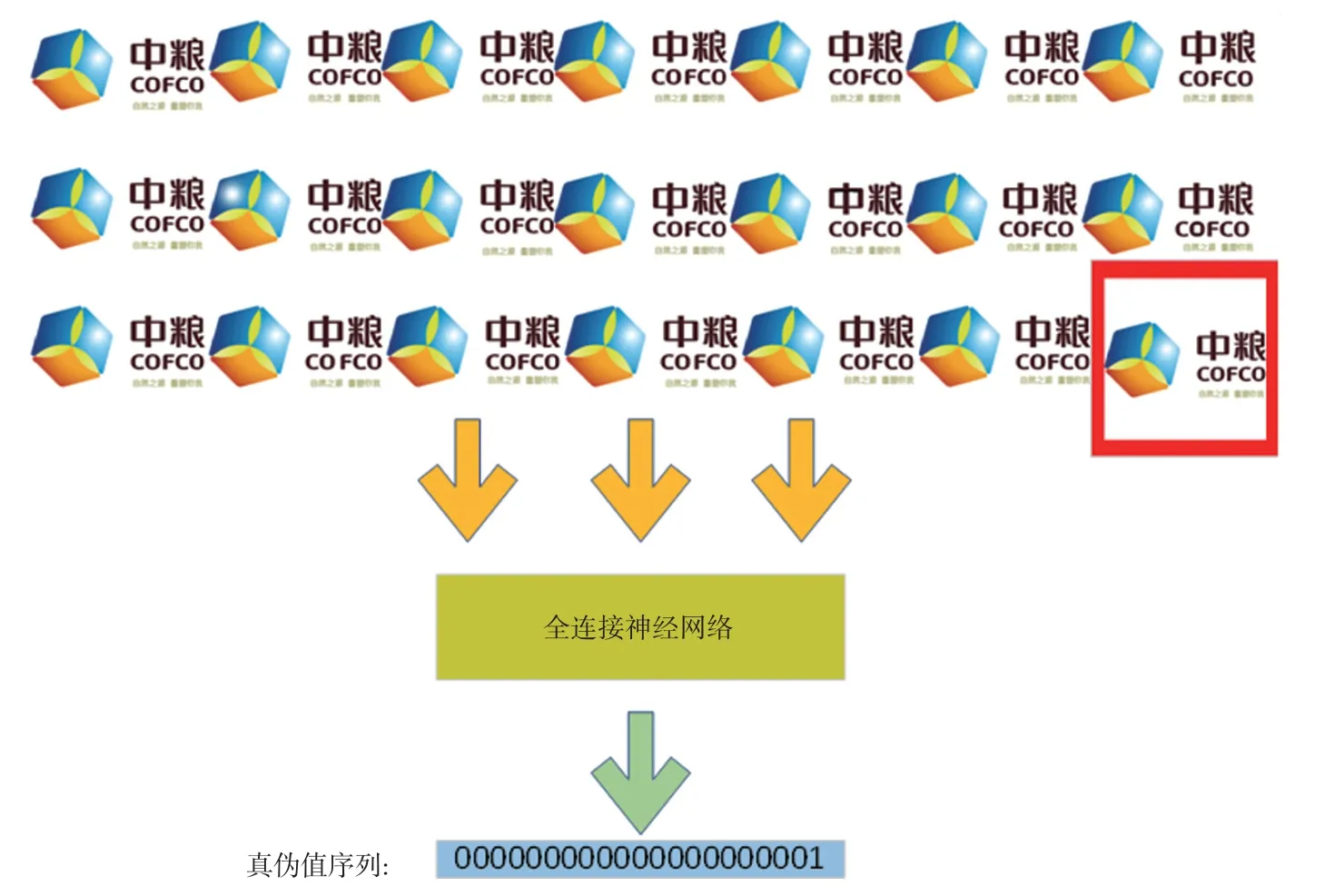
圖6 網絡預測結果測試示意圖
5 結論
新技術在零售終端、物流環節的應用,可以產生有價值的數據。將這些海量的數據進行收集、監測以及分析,可以幫助企業更加有針對性地進行店鋪運營和消費者管理。本文系統地構建了基于BP 全連接前向反饋神經網絡的商標鑒別系統。從對測試數據集的實證結果看,本系統具有較強的學習擬合能力和自適應能力,具有較高的合理性和適用性。此方法不僅可以擬合真偽商標和其像素數據值之間的關系,而且還能夠很好地避免人為鑒別過程中的不確定性,在最大程度上縮小了人為因素及模糊性的影響,提高了鑒別的可靠性,鑒別結果也更迅速準確。
當然,本文所提出的基于BP 全連接前向反饋神經網絡的商標鑒別系統在實際中也存在著一些不足,主要表現在BP 神經網絡模型要求有較多數量的學習樣本,學習樣本的數量和質量也在很大程度上影響著神經網絡模型的學習效率和最終鑒別結果;其次,指標的合理性還需要進一步證明,本文的實證部分主要針對一組測試集商標,測試集規模較小,而當運用到不同尺寸、不同分辨率的商標鑒別時,鑒別結果的合理性需要做深入探討。因此,針對上述的問題與不足還應當進一步深入研究。
