一種異質(zhì)信息網(wǎng)絡表示學習方法
2021-03-08 09:30:10張蝶依尹立杰
新一代信息技術 2021年24期
張蝶依,尹立杰
(河北地質(zhì)大學信息工程學院,河北 石家莊 050031)
0 引言
網(wǎng)絡數(shù)據(jù)作為表達物體間關系的一種載體,在現(xiàn)實世界中無處不在,例如生物、社交和計算機系統(tǒng)等,在這些系統(tǒng)中相互作用的組件可以抽象為信息網(wǎng)絡[1]。由此可見,信息網(wǎng)絡已經(jīng)成為我們?nèi)粘I钪兄匾M成部分,對信息網(wǎng)絡進行研究和分析已經(jīng)引起學術界眾多研究者們的廣泛關注。隨著網(wǎng)絡時代的迅猛發(fā)展,信息網(wǎng)絡所面臨的復雜性越來越高,如何有效、快速處理網(wǎng)絡中的數(shù)據(jù)成為亟待解決的問題。
采用鄰接矩陣[2]這種高維稀疏的編碼方式來表示網(wǎng)絡中的節(jié)點,很難被機器學習算法處理。網(wǎng)絡表示學習采用低維向量表示網(wǎng)絡中的節(jié)點,同時盡可能地保留網(wǎng)絡原始的結構特征。由于低維向量很容易被機器學習算法處理,因此被廣泛應用于節(jié)點分類[3-5]、聚類[6-7]、鏈接預測[8-9]和推薦[10-13]等應用場景中。
現(xiàn)在已有大量工作致力于同質(zhì)網(wǎng)絡的表示學習,相關研究工作包括 DeepWalk[14]、LINE[15]、Node2vec[16]、GraRep[17]等,但是這些算法只考慮了網(wǎng)絡的拓撲結構,使得學到的節(jié)點或邊的特征表示在后續(xù)的實驗任務中并沒有取得很好的效果。現(xiàn)實世界的網(wǎng)絡除了包含拓撲信息之外,還包含更多可利用的輔助信息,例如微博中包含用戶信息、微博內(nèi)容等屬性信息,充分利用這些異質(zhì)信息有助于學習更加準確的節(jié)點表示。將現(xiàn)實世界的信息網(wǎng)絡建模為異質(zhì)信息網(wǎng)絡,即由多種類型的節(jié)點通過多種類型的連邊形成的網(wǎng)絡,不僅保留了網(wǎng)絡中的拓撲結構信息,而且可以獲取網(wǎng)絡中豐富的語義信息,例如,學術網(wǎng)絡包含作者、論文、會議等不同類型的節(jié)點,以及作者和論文間的撰寫關系、論文和會議間的發(fā)表關系等。近年來,大量學者開始研究異質(zhì)網(wǎng)絡表示學習的相關方法,本文將從不同角度對這些表示學習方法進行介紹和總結。
1 相關定義
定義1異質(zhì)信息網(wǎng)絡
用 G = (V, E, T ,?, φ)表示一個信息網(wǎng)絡,V表示網(wǎng)絡中的節(jié)點集合,E表示網(wǎng)絡中邊的集合。T=(TV, TE),TV和TE分別代表節(jié)點和邊類型的集合。每個節(jié)點v∈V和每條邊e∈E的類型由映射函數(shù)確定,分別表示為給定的有向網(wǎng)絡G就是異質(zhì)信息網(wǎng)絡,否則為同質(zhì)網(wǎng)絡[18]。
定義2異質(zhì)網(wǎng)絡表示學習
給定一個異質(zhì)信息網(wǎng)絡 G = (V, E, T ,?, φ),V表示網(wǎng)絡中的節(jié)點集合,E表示網(wǎng)絡中邊的集合。異質(zhì)網(wǎng)絡表示學習[19]是將網(wǎng)絡中的節(jié)點v∈V投影到一個潛在低維表示空間 Rd中,學習一個映射關系,同時保留網(wǎng)絡原有的結構信息和語義關聯(lián)。
2 異質(zhì)網(wǎng)絡表示學習方法介紹
隨著現(xiàn)實世界網(wǎng)絡的復雜化和擴大化,如何充分挖掘并運用異質(zhì)網(wǎng)絡中存在的豐富信息是一項非常重要的任務。通過不同網(wǎng)絡表示學習方法得到節(jié)點的向量表示,可以將其應用到機器學習任務中,有效利用異質(zhì)網(wǎng)絡中的豐富信息。根據(jù)對異質(zhì)網(wǎng)絡表示學習模型的研究,將已有的方法分為3類:基于網(wǎng)絡分解的方法、基于隨機游走的方法和結合應用任務的方法。
2.1 基于網(wǎng)絡分解的方法
基于網(wǎng)絡分解算法的核心思想是根據(jù)節(jié)點類型的不同,將異質(zhì)信息網(wǎng)絡分解成多個簡單的網(wǎng)絡,分別對這些網(wǎng)絡進行表示學習,通過融合這些特征信息得到節(jié)點的低維表示。例如,Tang等人提出的 PTE[20]算法將異質(zhì)文本網(wǎng)絡分解為word-word,word-document,word-label三個子網(wǎng)絡(如圖1所示),分別對三個不同類型的子網(wǎng)絡進行表示學習,獲取三種不同類型節(jié)點間的相似性,得到網(wǎng)絡中節(jié)點的向量表示,將文本中所有單詞對應的向量表示取平均即為文本最終的向量表示。Shi等人提出的 HERec[21]模型根據(jù)元路徑抽取出相同類型的節(jié)點序列,對不同元路徑抽取到的同類節(jié)點分別進行表示學習,并利用融合函數(shù)將節(jié)點的不同表示進行融合,得到節(jié)點的最終表示。
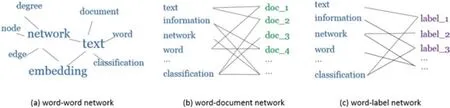
圖1 異質(zhì)文本網(wǎng)絡的三個子網(wǎng)絡Fig.1 thr ee sub-networks of heterogeneous text network
2.2 基于隨機游走的方法
隨機游走作為一種經(jīng)典的網(wǎng)絡表示學習模型,常用于刻畫網(wǎng)絡中節(jié)點間的關系,因此也被廣泛用于獲取網(wǎng)絡節(jié)點的采樣序列。基于隨機游走的方法主要是采用不同的隨機游走策略對網(wǎng)絡中的節(jié)點進行采樣,并通過預測節(jié)點間的鄰居關系得到節(jié)點的低維表示。例如,Metapath2vec[22]通過對稱的元路徑來進行隨機游走,將得到的游走序列作為神經(jīng)網(wǎng)絡skip-gram模型的輸入,通過更新參數(shù)進而得到節(jié)點的低維嵌入,但在輸出層并未將節(jié)點的類別區(qū)別開來。Metapath2vec++模型在神經(jīng)網(wǎng)絡的輸出層,針對網(wǎng)絡節(jié)點類型的不同,將異質(zhì)網(wǎng)絡分解成若干同質(zhì)網(wǎng)絡。Zhang等人在元路徑的基礎上提出metagraph2vec[23]方法,通過構建多條元路徑獲取節(jié)點間的不同語義關系。Fu等人提出了HIN2Vec[24]模型,通過隨機游走的方式選取節(jié)點序列,考慮節(jié)點及節(jié)點間不同類型的邊關系,基于神經(jīng)網(wǎng)絡學習節(jié)點和元路徑的向量表示,HIN2Vec模型的框架示意圖如圖2所示。HINE[25]通過元路徑隨機游走獲取節(jié)點的局部和全局語義信息,提高了網(wǎng)絡節(jié)點嵌入的準確性。
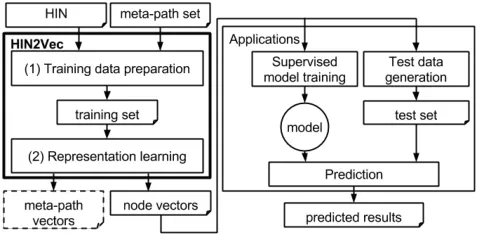
圖2 HIN2VEC 模型框架Fig.2 the framework of HIN2VEC
2.3 結合應用任務的方法
Sun等人提出了一種基于元路徑的相似度算法 PathSim[26],該算法采用對稱元路徑的方式計算異質(zhì)網(wǎng)絡中相同類型頂點之間的相似度。Wang等人提出的 SHINE[27]模型將原始的 HIN劃分為三個單類型的網(wǎng)絡:情感網(wǎng)絡,社會網(wǎng)絡,信息網(wǎng)絡,針對三個網(wǎng)絡分別建立對應的自編碼器,將學到的節(jié)點表示進行融合,用于預測可能存在的情感鏈接。Yang提出一種基于元路徑的鏈接預測方法 BRLinks[28]。該模型首先剔除網(wǎng)絡中的無關節(jié)點,重新構造異質(zhì)信息網(wǎng)絡,然后采用余弦相似度計算兩兩節(jié)點間的相關性得到節(jié)點相關性矩陣,計算每條元路徑上節(jié)點的鏈接概率,最后將通過不同元路徑得到的節(jié)點概率加權求和作為待預測節(jié)點間的鏈接概率。Shi等人提出一種異構網(wǎng)絡推薦方法 HERec,該算法采用 Meta-Path的隨機游走方法生成采樣序列,通過刪除與起始節(jié)點類型不同的節(jié)點,對得到的同構節(jié)點序列進行表征學習,由于不同的 Meta-Path會得到不同的節(jié)點表示,通過設計融合函數(shù)獲取節(jié)點的唯一向量表示,將異質(zhì)信息網(wǎng)絡的表示融入到矩陣分解框架中,從而用于推薦系統(tǒng),HERec模型框架如圖3所示。MCRec[29]將基于元路徑的上下文融入到用戶-商品對的信息中,同時采用協(xié)同注意力機制增強用戶和商品的節(jié)點表示,很大程度上提高了推薦性能,并通過大量實驗驗證該模型可以緩解推薦系統(tǒng)中普遍存在的冷啟動問題。LGRec[30]將通過網(wǎng)絡拓撲結構得到的用戶與商品的直接關系作為局部信息,通過元路徑獲取到的用戶與商品的間接關系作為全局信息,將局部信息和全局信息進行融合,得到用戶和商品更準確的表示,并通過實驗驗證了該模型在推薦系統(tǒng)的有效性。

圖3 HERec模型框架Fig.3 the framework of HERec
3 應用場景
3.1 節(jié)點分類
節(jié)點分類是根據(jù)網(wǎng)絡節(jié)點擁有的共同特點將其劃分為不同的類別。比如,在社交網(wǎng)絡上,用戶可以根據(jù)個人的興趣愛好進行分類。用戶的興趣愛好作為分類的類別標簽,是對用戶進行有效分類的主要依據(jù)。然而真實數(shù)據(jù)中的類別標簽往往是十分稀疏的,所以需要根據(jù)少量節(jié)點的標簽信息以及節(jié)點間的鏈接關系,對大量未標注節(jié)點的分類情況進行標注。
3.2 節(jié)點聚類
節(jié)點聚類就是按照節(jié)點特征的差異將網(wǎng)絡節(jié)點劃分為多個簇的過程,使得同一個簇內(nèi)節(jié)點間具有相似的特征,不同簇中節(jié)點間擁有的特征盡可能不同。由于異質(zhì)網(wǎng)絡中包含豐富的語義信息,可以利用一些額外信息(如屬性信息)進行聚類分析。
3.3 鏈接預測
鏈接預測[31]是通過已知的網(wǎng)絡節(jié)點及其鏈接關系等信息預測網(wǎng)絡中丟失的邊或者未來可能會出現(xiàn)的邊,對鏈接預測的研究可以幫助我們分析網(wǎng)絡的演化過程,在現(xiàn)實生活中有廣泛的應用。例如,可以通過鏈接預測方法計算尚未產(chǎn)生關系的兩個人成為朋友的概率,實現(xiàn)社會網(wǎng)絡中的好友關系推薦。鏈接預測任務中常用的評價指標為AUC值,在進行鏈接預測時,需要把網(wǎng)絡中的樣本數(shù)據(jù)集劃分為訓練集和測試集,AUC指標就是計算測試集中連邊的分數(shù)值高于不存在的連邊分數(shù)值的概率。
3.4 推薦
推薦系統(tǒng)是通過研究用戶的信息需求、興趣愛好,將用戶可能感興趣的產(chǎn)品推薦給他們。近些年,隨著網(wǎng)絡表示學習的興起,一些研究者開始意識到異質(zhì)網(wǎng)絡推薦系統(tǒng)的重要性和必要性。傳統(tǒng)的一些推薦方法大多數(shù)是利用用戶-商品間的交互記錄為用戶推薦商品,但是這種方法往往存在冷啟動問題,即無法為新用戶推薦產(chǎn)品。隨著互聯(lián)網(wǎng)服務的快速發(fā)展,越來越多的工作[32-34]開始嘗試融合一些輔助信息實現(xiàn)更精準的推薦。例如,在電影推薦系統(tǒng)中,可以為具有相同觀影記錄的用戶推薦電影。利用用戶-用戶、商品-商品之間的關系可以提高推薦性能。
4 結論與展望
現(xiàn)實世界的網(wǎng)絡包含大量不同類型的實體和關系,將這些不同類型的網(wǎng)絡信息融合為整體,不僅可以挖掘網(wǎng)絡中豐富的結構信息和語義信息,還可以精準刻畫網(wǎng)絡實體特征。異質(zhì)網(wǎng)絡表示學習是通過設計合適的網(wǎng)絡特征學習模型,把不同類型的節(jié)點映射到同一向量空間,用低維連續(xù)的實值向量表示網(wǎng)絡中的節(jié)點,有效緩解了網(wǎng)絡數(shù)據(jù)的稀疏性問題。
本文對現(xiàn)有的異質(zhì)信息網(wǎng)絡表示學習方法進行了分類,并詳細介紹了各個類別下的一些主要研究模型及其特點。隨著大數(shù)據(jù)時代的到來,異質(zhì)網(wǎng)絡分析逐漸成為數(shù)據(jù)挖掘、網(wǎng)絡安全等領域的研究熱點,充分挖掘異質(zhì)網(wǎng)絡中存在的豐富信息具有重要意義。異質(zhì)網(wǎng)絡表示學習是一個非常有前景的研究方向,在以下幾個方面仍然面臨著巨大挑戰(zhàn):
(1)適應大規(guī)模復雜網(wǎng)絡。現(xiàn)實應用場景中的網(wǎng)絡往往是大規(guī)模的,例如,淘寶網(wǎng)絡中包含上億節(jié)點。針對大規(guī)模異質(zhì)網(wǎng)絡,在對設計好的網(wǎng)絡模型進行訓練時往往存在訓練效率太低、響應時間過長等問題,克服這些問題是異質(zhì)網(wǎng)絡表示學習真正邁向?qū)嶋H應用場景的關鍵一步。
(2)適應網(wǎng)絡的動態(tài)變化。現(xiàn)實生活中的異質(zhì)網(wǎng)絡具有動態(tài)性,大多數(shù)異質(zhì)網(wǎng)絡表示學習方法主要依賴于靜態(tài)的網(wǎng)絡拓撲結構信息進行表征學習,沒有考慮網(wǎng)絡節(jié)點(或邊)實時變化的問題。然而,隨著時間的增長,網(wǎng)絡在新增一些節(jié)點的同時,也會伴隨部分節(jié)點的消亡,同時網(wǎng)絡節(jié)點間的鏈接關系也會出現(xiàn)改變,如何從時間維度考慮網(wǎng)絡結構的動態(tài)變化是未來值得研究的一個方向。
(3)實現(xiàn)更多的實際應用。目前的異質(zhì)網(wǎng)絡表示學習方法已經(jīng)應用到一些數(shù)據(jù)挖掘任務中,并逐步與電商、網(wǎng)絡安全等應用系統(tǒng)相結合,但是還有更多針對大規(guī)模復雜網(wǎng)絡的應用場景尚未發(fā)掘,將異質(zhì)網(wǎng)絡分析付諸實踐,在更多具體應用中發(fā)揮作用是未來值得探索的方向。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
